这里写自定义目录标题
- 1、sql语句查询表结构信息
- (1)查询某库某表的字段、数据类型、字段注释
- (2)查询某库的所有表名、表注释
- (3)查询库下所有表名、表注释、所有字段名、数据类型、字段注释
- (4)查询某个表在哪个库
- 2、MySQL操作符
- (1)Union
- (2)having、on、where的区别
- having、where
- on、where
- (3) order by
- 3、MySQL 高级函数
- (1)IF(expr,v1,v2)
- (2)IFNULL(expression_1,expression_2)
- (3)group_concat
- (4)CAST、CONVERT
- (5)FIND_IN_SET(str,strlist)
- strlist是变量使用IN,查询不到结果
- strlist是变量使用FIND_IN_SET,能查询到结果
- (6)avg()函数
- 4、奇怪的bug记录
- (1)order by 失效
- 5、Navicat快捷键
更多参考自:https://www.runoob.com/mysql/mysql-functions.html
1、sql语句查询表结构信息
文章参考自https://blog.csdn.net/yilovexing/article/details/107068569
今天使用navicat发现当库中表的数量太大时,部分表就不会出现在下拉项中(表太多眼睛也要看花了),所以不方便查询表的结构信息。如表在哪个库,表的字段、数据类型、字段注释,表的注释等。所以学习了一下使用information_schema 系统数据库查询这些信息的sql语句。
原理:创建数据库、表、字段时,MySQL 会将其存储在 information_schema 系统数据库中,所以我们可以对任意库、任意表、任意字段进行查询。
TABLE_SCHEMA = 数据库名称
TABLE_NAME = 表名
(1)查询某库某表的字段、数据类型、字段注释
SELECTCOLUMN_NAME AS 字段名,DATA_TYPE AS 数据类型,COLUMN_COMMENT AS 字段注释
FROMINFORMATION_SCHEMA.COLUMNS
WHERETABLE_SCHEMA = 'pxk_nxmu_2022_2023_1' AND TABLE_NAME = 'expertpublishrange_task';
(2)查询某库的所有表名、表注释
SELECTTABLE_NAME AS 表名,TABLE_COMMENT AS 表注释
FROMINFORMATION_SCHEMA.TABLES
WHERETABLE_SCHEMA = 'pxk_nxmu_2022_2023_1';
(3)查询库下所有表名、表注释、所有字段名、数据类型、字段注释
SELECTt.TABLE_NAME AS 表名,t.TABLE_COMMENT AS 表注释,c.COLUMN_NAME AS 字段名,c.COLUMN_TYPE AS 数据类型,c.COLUMN_COMMENT AS 字段注释
FROMINFORMATION_SCHEMA.TABLES AS t,INFORMATION_SCHEMA.COLUMNS AS c
WHEREc.TABLE_NAME = t.TABLE_NAME AND t.TABLE_SCHEMA = 'pxk_nxmu_2022_2023_1';
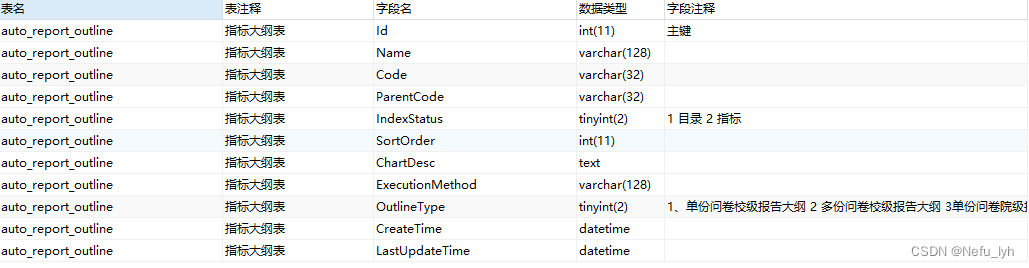
(4)查询某个表在哪个库
SELECT table_schema FROM information_schema.TABLES WHERE table_name = '表名';
2、MySQL操作符
(1)Union
可以使两张毫不相干的表的查询结果拼接在一起输出,前提是两个查询的列数要相同。
(2)having、on、where的区别
参考自:https://zhuanlan.zhihu.com/p/169737345
having、where
having是对group by之后的数据进行过滤,且having后面跟着的条件中只能使用分组后选中的字段(可以是select后的别名),having跟着的过滤条件中可以使用聚合函数,如having count(*)>5
where是对group by之前的数据进行过滤,且where跟着的过滤条件中不可以使用聚合函数,如having count(*)>5
on、where
当查询涉及多个表的关联时,我们既可以使用WHERE子句也可以使用ON子句指定连接条件和过滤条件。这两者之间的主要区别在于:
对于内连接(inner join)查询,WHERE和ON中的过滤条件等效;
对于外连接(outer join)查询,ON中的过滤条件在连接操作之前执行,WHERE中的过滤条件(逻辑上)在连接操作之后执行。
(3) order by
参考自: https://blog.csdn.net/u010757785/article/details/84619941
order by 字段名 是对按照该字段进行排序,降序desc,默认情况为升序asc
但前提是,该字段类型必须是数字类型如 int 、float、double
若为字符串类型则使用 order by cast(字段 as char)
若为字符串类型的数字则使用 order by (字段+0) 或 order by cast(字段 as unsigned) 或
3、MySQL 高级函数
(1)IF(expr,v1,v2)
如果表达式 expr 返回值为true,返回结果 v1;否则,返回结果 v2。
SELECT*,
IF( max( count )= 1, 1, 0 ) IsCanUse
FROM expertpublishrange_task
max( count ) 选取最大的count值,
IF( max( count )= 1, 1, 0 ) IsCanUse最大的count值为1则结果为1,否则为0,并将结果赋给IsCanUse字段

(2)IFNULL(expression_1,expression_2)
Where时后碰见一个这样的写法
AND ( IFNULL( maindep.TeacherAvgScore, 0 )<> 0 OR IFNULL( mainsch.AvarageScore, 0 )<> 0 )
其中
IFNULL(expression_1,expression_2);
如果expression_1不为NULL,则IFNULL函数返回expression_1; 否则返回expression_2的结果
此处expression_1为maindep.TeacherAvgScore,其值不为NULL但为0 ,所以返回0;
<>是不等于,0=0所以IFNULL( maindep.TeacherAvgScore, 0 )<> 0返回false,另一边也返回false。所以and这边的限制为false,最后是一条数据也取不到的。
Select时还可以组合这样的写法
SELECT...ifnull( t.OwnerName, '-' ) OwnerName
...
如果t.OwnerCode为null,则返回 - ,将结果返回给OnwerCode;如果不为空则正常显示数据

(3)group_concat
参考自:https://blog.csdn.net/qq_33323054/article/details/125193170
可以将查询的结果拼接为一行记录
例子1:
SELECTGROUP_CONCAT(IF( IsMaster = 1, TeacherName, NULL )) Managers
FROMteachinggroupteachers
WHERETeachingGroupId IN ( 1, 2, 3, 4 );
IF( IsMaster = 1, TeacherName, NULL ) Managers
取IsMaster字段,如果为1则将TeacherName赋值给Managers,否则将TeacherName赋值给Managers
GROUP_CONCAT(IF( IsMaster = 1, TeacherName, NULL )) Managers
在上一步的基础上将得到的多个结果以逗号为分隔符拼为字符,串赋给Managers
例子2:
在例子1的基础上组合select、ifnull得到teachinggroup的Managers字段(这里只select了Managers字段,下图只看Managers的效果)
SELECT ifnull(( SELECT GROUP_CONCAT( IF ( IsMaster = 1, TeacherName, NULL )) Managers FROM teachinggroupteachers ),'-' ) Managers;
FROMteachinggroup

(4)CAST、CONVERT
参考自:https://www.cnblogs.com/kissdodog/p/3165944.html
cast、convert都用于类型转换:
CAST('12.5' AS DECIMAL(9,2)),as后面跟着目标类型CONVERT('12.5',DECIMAL(9,2)),逗号 后面跟着目标类型
表示将12.5的类型变为decimal小数类型,(9,2)规定了(整数部分+小数部分,小数部分)的位数,精度与小数位数分别为9与2。精度是总的数字位数,而小数位数是小数点右边的位数。能够支持的最大的整数有9-2=7位,值是9999999,而最小的小数有2位,值是0.01。
在大部分情况下,两者执行同样的功能,不同的是CONVERT还提供一些特别的日期格式转换,而CAST只提供一般的日期格式转换,详见参考链接。
但CAST是ANSI兼容的,而CONVERT则不是。(这里略有不懂,后续跟进)
(5)FIND_IN_SET(str,strlist)
参考自https://blog.csdn.net/m0_37389955/article/details/78893138
FIND_IN_SET函数是IN函数的升级版,区别在于如果strlist是常量,则可以直接用IN, 否则要用FIND_IN_SET()函数
- 假如字符串str在由N个被 ‘,’ 符号分开的子链组成的字符串列表strlist 中,则返回值为str第一次出现的位置,范围在 1 到 N之间。
- 如果第一个参数是一个常数字符串,而第二个是type SET列,则FIND_IN_SET() 函数被优化,使用比特计算。
- 如果str不在strlist 或strlist 为空字符串,则返回值为 0 。如任意一个参数为NULL,则返回值为 NULL。
- 这个函数在第一个参数包含一个逗号( , )时将无法正常运行。
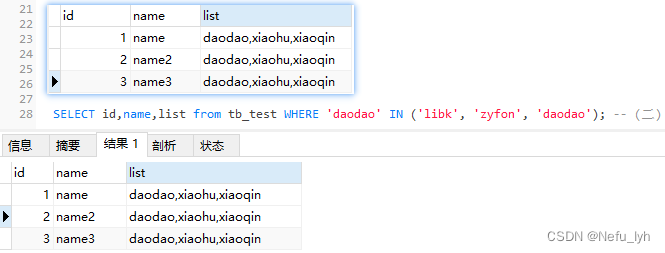
strlist是变量使用IN,查询不到结果
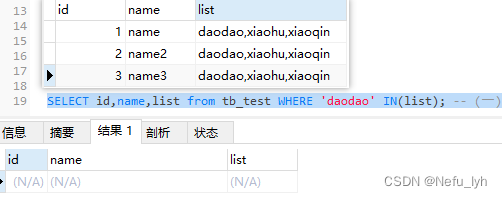
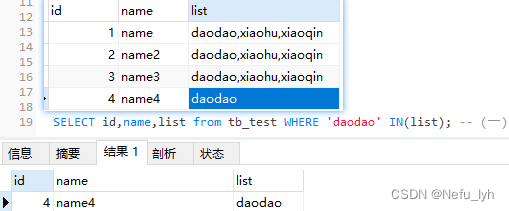
这样只有当list字段的值等于’daodao’时(和IN前面的字符串完全匹配),查询才有效(如下图)
否则都得不到结果即使’daodao’真的在list中(如上图)
strlist是变量使用FIND_IN_SET,能查询到结果
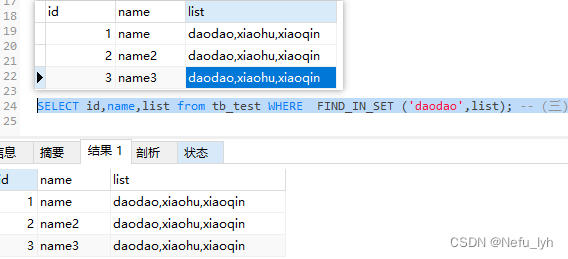
strlist是常量时,二者在查询结果上是没有区别的
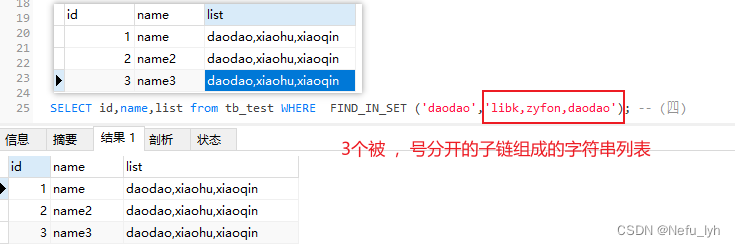
所以如果strlist是常量,则可以直接用IN, 否则要用find_in_set()函数。
二者的查询效率上请参考,扩展文章https://blog.csdn.net/ninisui/article/details/79410398
(6)avg()函数
参考文章:https://blog.csdn.net/m0_51088798/article/details/123906790
avg函数的分子为非NULL的选中字段之和,分母为非NULL的记录条数
若希望分母包含NULL,使用coalesce(price,0)会将NULL值替换为0
4、奇怪的bug记录
(1)order by 失效
我想对计分的问卷 IsScore =1 时的 Score 求平均并保留两位小数,并将结果赋值给 AvarageScore 字段
对不计分的问卷 IsScore =0 时,将 -1 赋值给 AvarageScore 字段
类似下面这样的效果

于是使用
if(IsScore>0 ,ROUND( avg( Score ),2),'-1' ) as AvarageScore -- 得分
最后跟上 order by AvarageScore desc,但是有时候会出现order by失效的情况如下,

原因是 当出现 IsScore = 0 时 AvarageScore 类型被从double转为了字符串的’-1’,导致排序出问题,所以应该将 ‘-1’ 改为 -1 ,如下
if(IsScore>0 ,ROUND( avg( Score ),2),-1 ) as AvarageScore -- 得分
5、Navicat快捷键
参考自 https://blog.csdn.net/cxyrfg/article/details/120007030
选中后运行:Ctrl+Shift+r
------ 持续更新中2022-12-14



![[附源码]Python计算机毕业设计Django海滨学院学生大创项目申报与审批系统](https://img-blog.csdnimg.cn/117ee89662be470788c51e1aec14bba9.png)
![[C语言]指针初阶](https://img-blog.csdnimg.cn/0511318ab1e94d548bed34a4335ece19.gif#pic_center)

