一、树的重要知识点
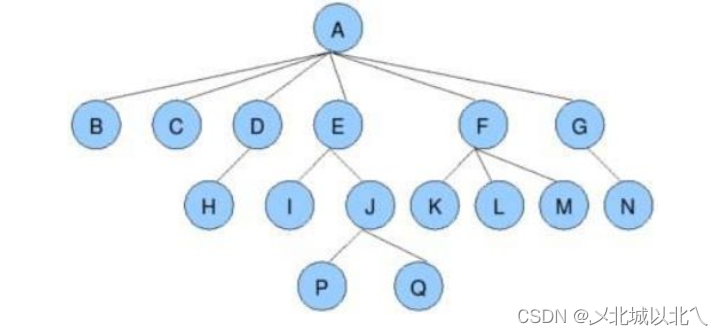
节点的度:一个节点含有的子树的个数称为该节点的度(有几个孩子)
叶节点或终端节点:度为0的节点称为叶节点;如上图:B、C、H、I...等节点为叶节点(0个孩子)
非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G...等节点为分支节点
父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 上图:A是B的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 上图:B是A的孩子节点
兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点(亲兄弟)
树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6(最多有几个孩子)
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次; 如上图:树的高度为4(H表示,从1开始)
堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
森林:由m(m>0)棵互不相交的树的集合称为森林;
二、二叉树

二叉树的度,孩子最多为2,可以是0、1、2,只有一个孩子是左/右孩子均可,上面是二叉树的所有可能组成部分。
1、完全二叉树&满二叉树

满二叉树有h层,且每层的结点都是满的。共 2^h-1个结点
完全二叉树有h层,前h-1层满,最后一层最少一个,结点n的范围是 2^(h-1)<=n<= 2^h-1
2、二叉树的性质 (几个公式)
首先,设孩子为0/1/2的结点总数分别为N0/N1/N2
可得 N0 = N2+1 该等式恒成立。 N1的数量是不确定的。
但是对于满二叉树。N1=0, 观察一下图就知道了。
对于完全二叉树,N1 = 0或1.
二叉树的深度H: H=logN(约等于),所以从上到下遍历一遍的时间复杂度为O(logN)
3、孩子与父亲的关系(互相查找)
假设将二叉树的结点,从上到下,从左到右,从0开始标记结点的个数,设孩子下标为child,父亲的下标为parent,则有以下关系
1、parent = (child-1)/ 2 左右孩子均满足
2、左孩子: child = 2*parent +1
3、右孩子: child = 2*parent +2
同时,如果结点总数为n,此时把n看作是下标,child必须<n,孩子结点才能存在,即 0~n-1
三、堆的概念
1、二叉树的顺序存储结构
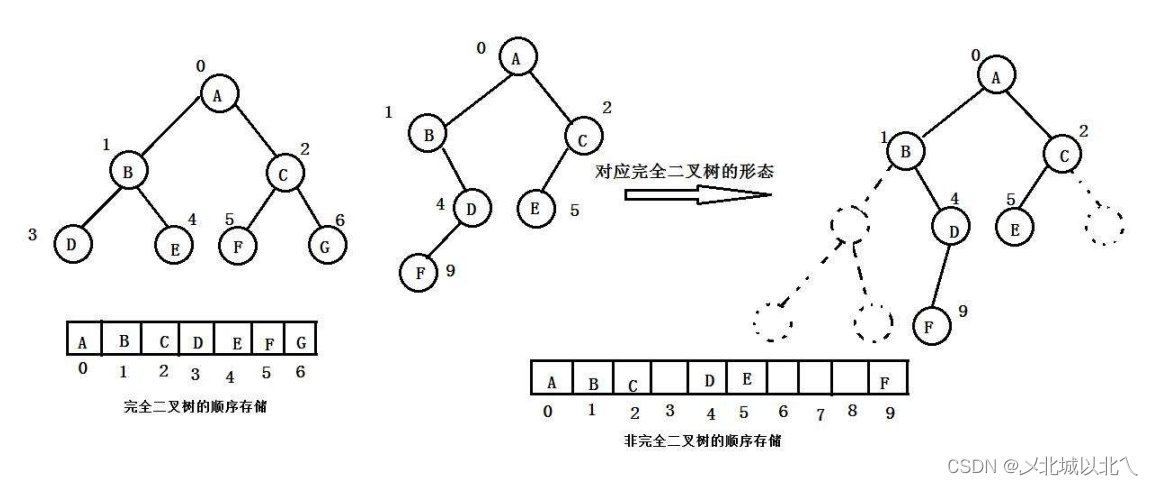
与链表类似,堆这种数据结构也是分为物理结构和逻辑结构。
逻辑结构上是一棵完全二叉树,物理结构上是顺序表。
上图中为普通二叉树的两种结构,如果不是完全二叉树,就会导致顺序表的空间浪费,例如:最下面一层如果只有最后一个结点存在,那么顺序表的一半左右大小的空间就会被浪费,而堆的产生,就是为了解决这种空间浪费的。完全二叉树的结构使其能更好的利用顺序的空间。
2、堆的分类

分为 大根堆和小根堆两种,即每个parent结点的val值的大小,都要比其child结点的val大或小。
四、堆的接口函数
typedef int HPDatatype;typedef struct Heap
{HPDatatype* a;int capacity;int size;
}HP;//堆的初始化
void HPInit(HP* php);
//堆的销毁
void HPDestroy(HP* php);
//入数据
void HPPush(HP* php, HPDatatype x);
//删除数据
void HPPop(HP* php);
//判断堆是否为空
bool HPEmpty(HP* php);
//返回堆中元素个数
int HPSize(HP* php);
//返回堆顶元素
HPDatatype HPTop(HP* php);
//交换2个数据
void Swap(HPDatatype* p1, HPDatatype* p2);
//向下调整
void AdjustDown(HPDatatype* a, int parent, int size);
//向上调整
void AdjustUp(HPDatatype* a, int child);
五、初始化
//堆的初始化
void HPInit(HP* php)
{assert(php);HPDatatype* tmp = (HPDatatype*)malloc(sizeof(HPDatatype) * 4);if (NULL == tmp){perror("malloc fail");return ;}php->a = tmp;php->capacity = 4;php->size = 0;}
堆的结构与顺序表类似,都是一个指针指向物理存储的数组,size表示现有数据的个数,capacity表示当前的容量。
malloc一段空间给指针a,然后调整size为0,capacity初始化为4个元素的大小。
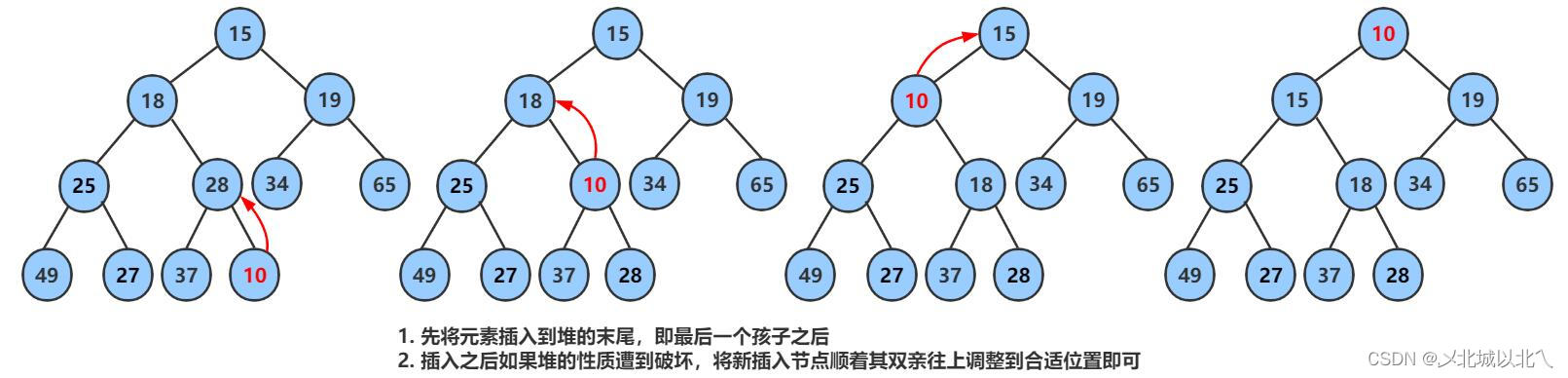
六、插入数据

先判断物理空间上的存储是否足够,不够就增容。
在size位置插入数据后,要对数据进行向上调整操作 (向上调整的原因是为了维持堆的结构,因为插入的数据的值的大小是不确定的,如果不调整就会破坏堆的结构,因此从第二个数据开始,就要不断向上调整)。
传入的参数为a指向的数组,以及刚刚插入的,要调整的数据的下标
七、向上调整函数

传入child下标,通过parent = (child-1)/2找到其父亲结点的下标位置,因为这里以大根堆为例,因此,只要a[child]>a[parent]就交换,交换完后,孩子变为原来的父亲,父亲继续找他的父亲,这样向上迭代,直到child变为0,即堆顶,它就是堆中最大的元素了,没有调整空间了。或者是不满足孩子大于父亲的条件,直接跳出了。
交换函数
只是实现简单的两个元素的数据交换,注意函数的返回值类型,以及传入的是地址。

八、删除数据

一开始的size是删除前堆中元素的总数,我这里先让size--,使其指向被删除的那个元素,然后交换堆顶元素和要删除的元素,最后对堆顶的元素进行向下调整操作。
实现时可以改变顺序,但是一定要保证前后逻辑的统一,包括下面的向下调整函数的实现。
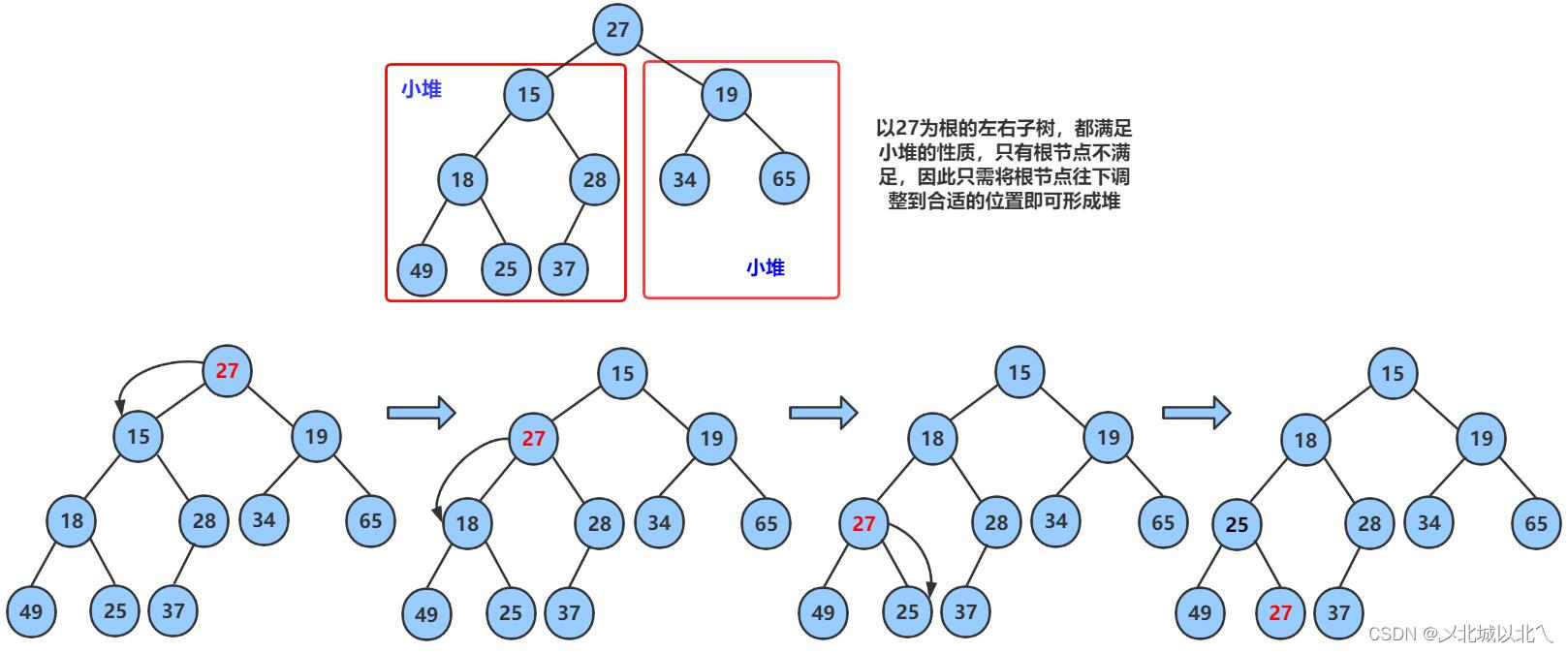
九、向下调整函数

这里的size接收的是pop函数中的size-1,即现在的size为向下调整的数据范围,共size个。
因为交换数据后,最大的数据来到数组的最后位置,我们只是通过size--来避免访问他,并没有真正的将它删除,因此原来在数组最后,现在在堆顶的那个元素,在向下调整时不能包含被删除的那个元素。
函数过程分析:parent为向下调整的那个元素,先通过 child = parent*2+1找到它的左孩子,进入循环后先判断一步,找出左右孩子中较大的那个,其中,child+1<size是为了保证右孩子也在数组范围内,如果不在,就默认为左孩子大了。
找出较大的孩子后,将其val值与parent比较,如果大于parent就交换,然后父亲变为孩子,孩子继续向下迭代找他的孩子,直到child>=size,超出数组范围。
十、返回个数、堆顶、销毁函数

这几个函数很简单,与前面的几种数据结构相似,这里不多陈述。
十一、测试结果

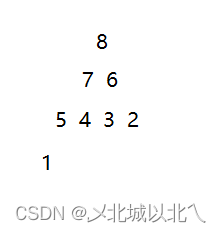
插入的结果为大堆。


由于删除后不会访问最后一个元素,所以除了原来的最大值8外,其它7个数字仍然满足大堆结构
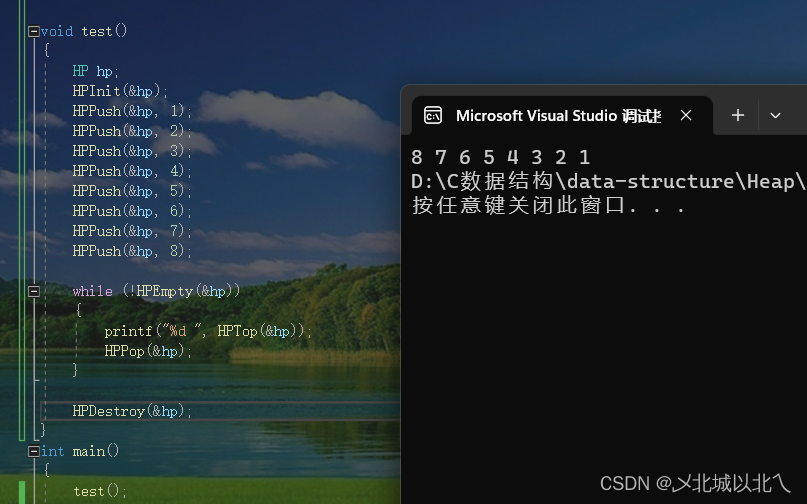
通过循环 取出堆顶元素+删除操作,可以获取所有堆顶元素。
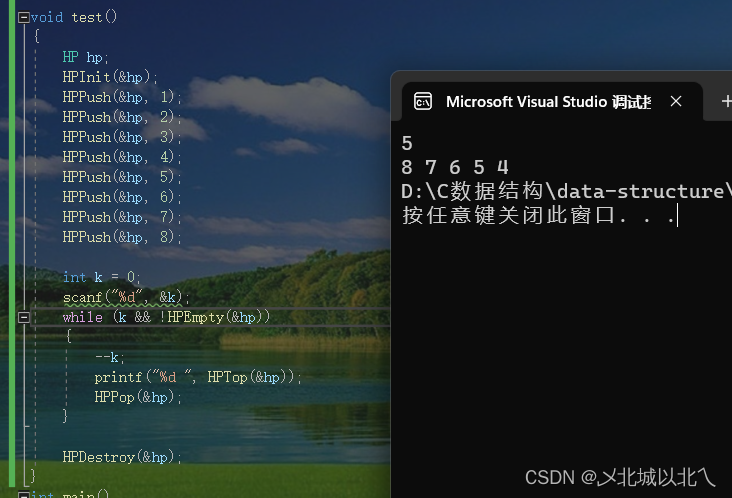 引入k变量可以取出k个堆顶元素,又因为堆顶元素都是堆中最大或最小的,因此可以解决后面的topk问题。
引入k变量可以取出k个堆顶元素,又因为堆顶元素都是堆中最大或最小的,因此可以解决后面的topk问题。
十二、函数实现具体代码
#include"Heap.h"//堆的初始化
void HPInit(HP* php)
{assert(php);HPDatatype* tmp = (HPDatatype*)malloc(sizeof(HPDatatype) * 4);if (NULL == tmp){perror("malloc fail");return ;}php->a = tmp;php->capacity = 4;php->size = 0;}//交换函数(交换父子数据)
void Swap(HPDatatype* p1, HPDatatype* p2)
{HPDatatype tmp = *p1;*p1 = *p2;*p2 = tmp;}//向上调整,任意传入一个下标,对它及其祖先进行向上调整,前提是左右子树都是 大/小堆
void AdjustUp(HPDatatype* a, int child)
{//chile 和 parent 都是下标的数字int parent = (child - 1) / 2;while (child > 0) //这里以大根堆为例(每个根都大于其子孙){if (a[child] > a[parent]){//若大于则向上调整交换Swap(&a[child], &a[parent]);//交换后,调整 父子下标,方便继续向上调整child = parent;parent = (child - 1) / 2;}else{break;}}}//入数据
void HPPush(HP* php, HPDatatype x)
{assert(php);//先判断是否需要增容,如需要则增容if (php->size == php->capacity){HPDatatype* tmp = (HPDatatype*)realloc(php->a, sizeof(HPDatatype) * 2 * (php->capacity));if (NULL == tmp){perror("realloc fail");return;}php->a = tmp;php->capacity *= 2;}//入数据 先插入到尾部,即物理存储上数组的最后,然后向上调整php->a[php->size] = x;AdjustUp(php->a,php->size);php->size++;}//判断堆是否为空
bool HPEmpty(HP* php)
{return php->size == 0;
}//向下调整,前提是左右子树都是 大/小堆
void AdjustDown(HPDatatype* a, int parent,int size)
{int child = parent * 2 + 1;while (child < size)//叶结点为止,叶节点没有孩子,即child下标超过数组范围{//先找出来2个子节点中较大的那一个,因为parent的值要和较大的比较//此时如果交换,值大的child变为parent,满足比他的兄弟大if ((child+1 < size) && a[child + 1]>a[child])//起始的child一定是左孩子,检查越界{child = child + 1;}//向下调整if (a[child] > a[parent]){Swap(&a[parent], &a[child]);parent = child;child = child * 2 + 1;//每次都从左边的节点开始}else{break;}}}//删除数据 删除堆顶的元素才有意义,根据大根堆和小根堆,可以得到top为max或min
void HPPop(HP* php)
{assert(php);assert(!HPEmpty(php));//删完之后还要保证为堆的结构//如果只是简单的向前覆盖,由于物理上是数组存储,就会导致堆的父子结构被打乱, 无法通过下标关系找父/子//无法进行后续删除,因此可以选择首尾元素交换,删除尾部后,堆顶元素向下调整php->size--;Swap(&php->a[0], &php->a[php->size]);AdjustDown(php->a, 0, php->size);}//返回堆中元素个数
int HPSize(HP* php)
{assert(php);return php->size;
}
//返回堆顶元素
HPDatatype HPTop(HP* php)
{assert(php);return php->a[0];
}//堆的销毁
void HPDestroy(HP* php)
{assert(php);php->capacity = 0;php->size = 0;free(php->a);
}//9 8 7 6 5 0 2 1 4 3今天讲的是堆的概念及其主要函数的实现,下一篇文章我将详细讲述堆的应用。如 堆排序、topk问题等,感谢各位看到最后。