前言
我负责的其中一个项目,接口的交互量在千万级/d,所以要存储大量的日志,为了防止日志的存储影响到系统的性能,所以在技术选型就决定了使用Kafka中间件和一个日志存储系统来负责日志的存储。
使用Kafka 的优点:
1.Kafka 是一种高吞吐量的分布式消息系统,可以支持水平扩展,非常适合存储大量的日志数据。
2.Kafka 使用数据增量的方式存储日志,并使用了 Zig-Zag 编码方式对数据进行压缩,从而极大地减少其占用的磁盘空间大小。
3.Kafka 的消息存储格式使用了 batch 方式,将一些公共信息进行提取,保证只需要存储一份,从而减少了每条消息的存储空间。
4.Kafka 的消息格式中包含了属性字段和 header,属性字段用于存储当前消息 key 和 value 的压缩方式,而 header 则供用户添加一些动态的属性,从而实现一些定制化的工作。
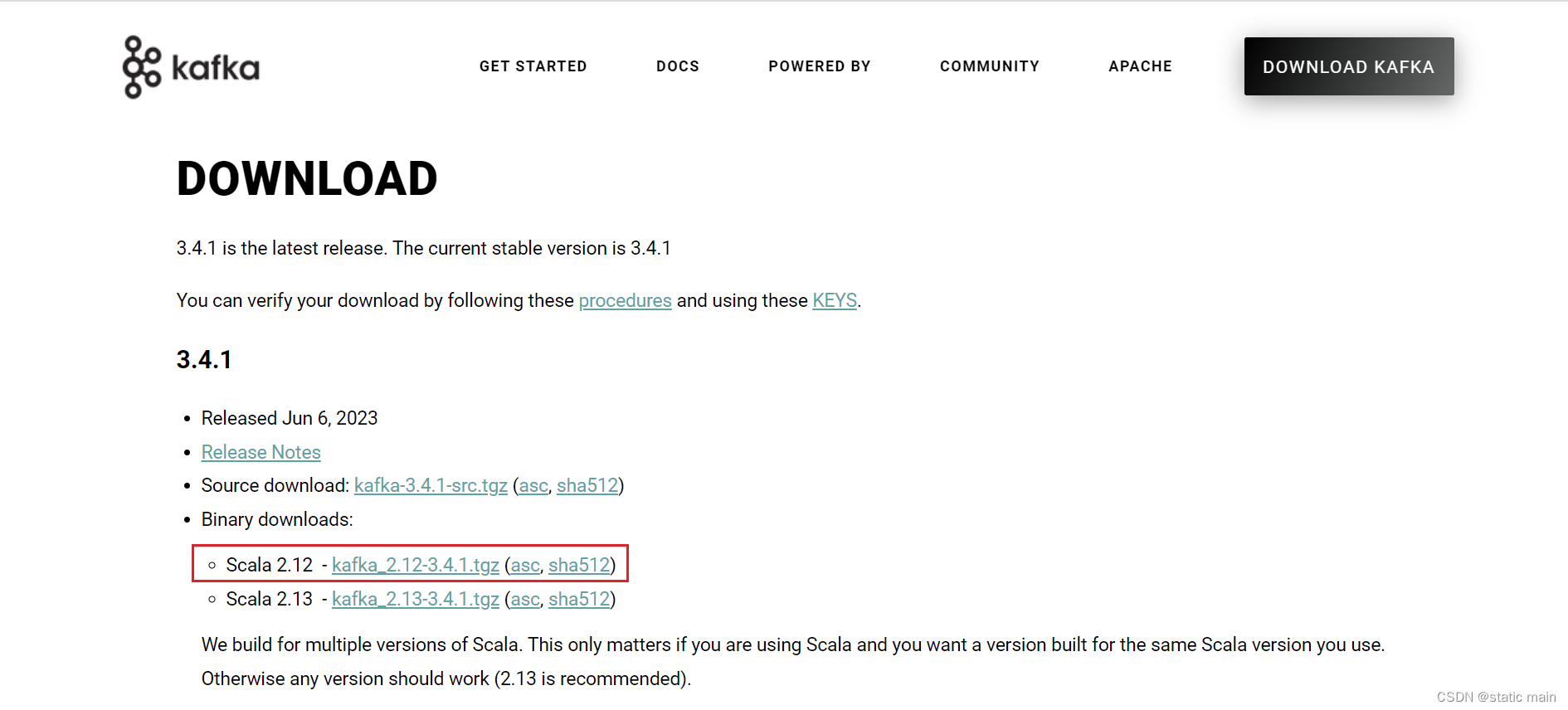
1.下载Kafka
下载地址
2.解压文件夹
3.检测Kafka是否可用
启动zookeeper
进入到bin目录下,执行cmd进入命令行
zookeeper-server-start.bat ../../config/zookeeper.properties

没报错,没退出此窗口即启动成功
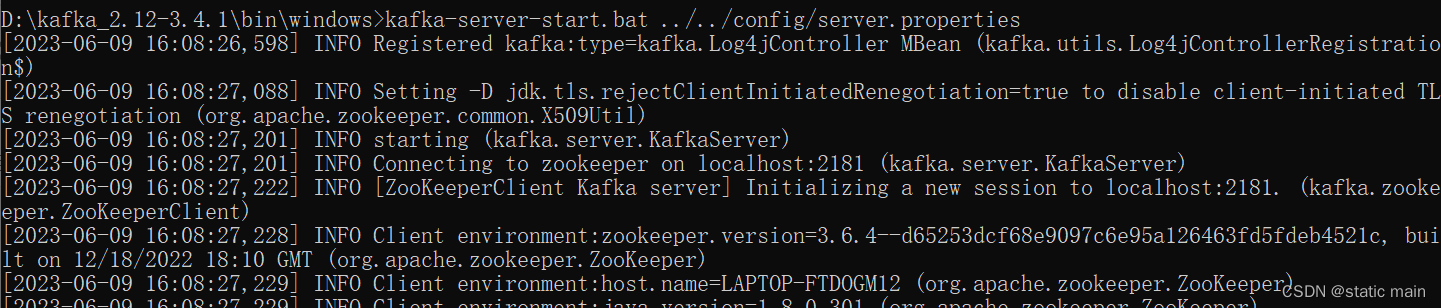
启动Kafka-server
进入到bin目录下,执行cmd进入命令行
kafka-server-start.bat ../../config/server.properties
基本操作Kafka指令
创建topic
执行下面指令创建一个名为test-mytopic的topic
kafka-topics.bat --create --topic test-mytopic --bootstrap-server localhost:9092

向topic发送数据
执行下面指令向topic发送数据
kafka-console-producer.bat --topic test-mytopic --bootstrap-server localhost:9092

订阅topic获取数据
执行下面指令订阅topic
kafka-console-consumer.bat --topic test-mytopic --from-beginning --bootstrap-server localhost:9092

4.Spring 集成 Kafka
pom文件引入依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.3.0</version></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency>
application配置
spring:kafka:// config/consumer.properties配置的bootstrap.serversbootstrap-servers: localhost:9092producer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer:key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer//这个可以和config/consumer.properties里的group.id不同group-id: test-consumer-group
向topic发送信息
模拟系统调用接口,忽略接口调用逻辑,当接口调用结束后,通过Kafka向Topic发送此次调用接口的相关消息
@RestController
public class KafkaController {@AutowiredKafkaTemplate<String, Object> kafka;@RequestMapping("OrderTrans")public String OrderTransIntf(HttpServletRequest request, @RequestBody String requestParams) {try {//处理接口逻辑} catch (Exception e) {}String serialNo = UUIDManager.generateSerialnoByUUID();JSONObject order = new JSONObject();order.put("serialNo", serialNo);order.put("sourceRequestData", requestParams);order.put("logInfo", "订单相关信息...");kafka.send("OrderLogHandlerTopic", order.toJSONString());return serialNo;}
}
订阅topic接收信息
@Configuration
public class KafkaConsumerConfig {@KafkaListener(topics = "OrderLogHandlerTopic")public void saveLog(String message) {System.out.println("接收到消息:" + message);//保存日志操作OrderLogDao.save(message);System.out.println("保存成功");}
}
到此为止,整个Kafka中间件就被我们集成到项目中并使用起来了,上述代码为我个人的精简版,中间还有各种复杂的逻辑处理,根据项目要求可以自行添加
创作不易,一键三连更开心!


![2021年中国空气净化器零售及发展趋势分析:智能家居,推动产品发展[图]](https://img-blog.csdnimg.cn/img_convert/7098c6f72b49b9e671449375877082f6.png)