文章目录
- 前言:
- 一、相关概念
- 二、实现过程
- 三、总结
前言:
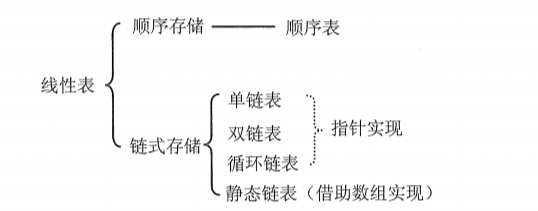
线性表是我们最常用的一种数据结构,线性表包含顺序表和链表,顺序表典型应用就是我们常用的ArrayList,链表的典型应用其中就有我们常用的LinkedList。LinkedList他的底层就是使用链表来存储数据元素的。
这篇文章用以总结链表中的双向循环链表,为单链表的结点增加一个指向前驱的指针域,单链表就变成了双链表,将双链表的头尾相连,双链表就成了双向循环链表。
一、相关概念
第一部分主要介绍下和链表有关的相关概念,这里给出的概念都是书本上的官方定义,并不是作者胡诌的,为什么给出这些官方的定义呢 ?因为笔者认为官方给出的定义,是对一个概念最本质的解释,它的解释经过了时间的考验,被认为是解释的最合理深入简明扼要的。
-
什么是线性表
线性表是由n个数据元素构成的有限序列,n为线性表的表长,当n为0时表示当前线性表是空表。线性表有且仅有一个开始结点和终端节点。且开始结点没有前驱,终端节点没有后继,其余节点有且仅有一个前驱和后继。线性表一般分为顺序表和链表。 -
什么是顺序表
采用顺序存储结构存储数据元素的线性表被称为顺序表,顺序表,要求逻辑上相邻的数据元素在物理内存的存储上也是相邻的,当在顺序表的第i(0<=i<=n)插入一个数据元素时,需要后移n-i+1个数据元素,当删除第i个元素时需要移动n-i个数据元素。java实现顺序表 -
什么是链表
采用链式存储结构存储数据元素的线性表被称为链表,链表不要求逻辑上相邻的数据元素内存上必须相邻,链表的每个节点都包含两部分,一部分是数据域用以存储数据,一部分是指针域用以存储指向相邻结点的指针或者引用。链表通过每个节点的指针域将一串数据串联成链。当结点只有一个指针域时,被称为单链表。单链表-含头结点、单链表-不含头结点 -
单链表、双链表、循环单链表、循环双链表
当链表的结点只有一个指针域时被称为单链表,循环单链表是单链表的一种特殊变化,只是将尾结点又指向了头结点(也可能是首结点)。
当链表的结点有两个时,一个指向前驱,一个指向后继这种链表便是双链表,循环双链表是双链表的一种特殊变化,只是将尾结点又指向了头结点(也可能是首结点)。
所有的链表的实现均有两种方式,一种是带有头结点,一种是不带有头结点的实现方式,两种实现略有区别。 -
为什么需要循环链表?
循环链表一般就是指循环单链表,不特殊指明是双向循环链表,那么该名称描述的就是单项循环链表,之所以需要循环链表是因为在操作系统中,循环链表有特定的应用场景,在一些场景中,链表中的元素需要循环的执行,但是在实际的开发中应用最多的还是双向循环链表。 -
为什么需要双向链表?
若是给定了一个结点,根据当前结点获取该结点的上一个结点,那么我们是没有办法直接获取的,只能是遍历链表,但若是使用了双向链表,我们则可以直接获取到该元素的上一个结点,时间复杂度就变成了O(1)。所以双向链表的实际应用意义更强,将双向链表的首尾相连就成了双向循环链表,双向循环链表的应用最常见的就是LinkedList。 -
头结点和首结点
首节点:真正存储第一个数据元素的结点被称为首节点。
头结点:当链表采用带头结点方式实现时,会创建一个数据域为null的节点,该节点的指针域存储的指针指向首节点的指针,他的唯一作用是标识链表的开始,带有头结点的链表更易于操作。 -
常见的栈和队列与线性表的关系
栈和队列也是常见的数据结构,但是栈和队列并不是线性表的一种,线性表只包含了顺序表和链表。不过我们可以将栈和队列看成是特殊的线性表。怎么特殊呢,栈是被限制了只能在一端进行插入和删除操作的线性表,所以栈的特性是先入后出,队列是被限制了只能在一端插入另一端删除的线性表,所以队列的特性是先入先出。既然栈和队列都是特殊的线性表,那么栈和队列自然就可以使用线性表来实现了,通常可以使用线性表中的顺序表和队列来实现栈和队列。
二、实现过程
上面是两种单链表的实现方式,其实无论是双链表还是双向循环链表他的实现方式都是类似的,区别都很有限,上面两篇文章里详细实现了单链表的各种常用方法,因此在该文章里只会总结必须用到的几个方法,比如插入、删除、清空、长度、判空、根据下标获取等,其他方法的实现都不难,就不一一展示了。
- 提供节点类:DupNode
双向循环链表的实现,我们首先必须为其提供一个结点类,该类需要有三个属性,一个数据域,一个指向前驱的指针域,还有一个指向后继的指针域,然后提供必要的构造方法即可,如下:
/*** 该类是双向链表的结点类* 该类包含了数据域,后继指针域、前驱指针域三个属性。*/
public class DupNode {Object object;DupNode prior;//前驱指针域DupNode next;//后继指针域public DupNode(){this(null);}public DupNode(Object object){this(object,null,null);}public DupNode(Object object,DupNode prior,DupNode next){this.object = object;this.prior = prior;this.next = next;}
}
- 提供双向循环链表的实现类:DoubleLinkedTable
采用带有头结点的方式实现双向循环链表,因此我们需要定义一个头结点。然后提供初始化它的构造器。值得注意的是,在初始化头结点时,我们必须将他的前驱和后继都声明为自己,这样才是一个空的双向循环链表。
public class DoubleLinkedTable {//头结点DupNode head;public DoubleLinkedTable(){head = new DupNode();head.prior = head;head.next = head;}
}
- 提供长度(length)、打印(display)、清空(clear)等方法
这些方法的实现原理都很简单,求链表长就是遍历链表计数即可,打印也是遍历链表,清空则是将头结点的前驱和后继都声明为自己,下面是三个方法的实现:
//长度public int length(){DupNode node = head.next;int j = 0;while(!node.equals(head)){j++;node = node.next;}return j;}//打印public void display(){DupNode node = head.next;while(!node.equals(head)){System.out.println(node.object);node = node.next;}}//清空public void clear(){head.next = head;head.prior = head;}
- 提供根据下标插入方法:insert(int i,Object object)
学习双向循环链表建议还是先学习单链表,会了单链表双向循环链表就是窗户纸,一桶就破,因为他们的实现思路都是一样的,只是稍微的变化而已。单链表的遍历我们的退出条件是找到尾结点就退出(node.next == null),循环链表肯定没有尾结点了,退出循环的条件就成了碰到头结点再退出(node ==head),另外一点区别就是双向循环链表的赋值问题,我们需要为新结点的前驱指针和后继指针赋值,同时需要为新结点的上一个节点的后继后继指针从新赋值,还需要为新节点的后继结点的前驱指针重新赋值,代码实现如下:
/*** 思路:* 1.寻找下标为i-1的数据元素,注意退出循环的条件应该是node!=head* 2.赋值即可,循环链表的核心就是空表也会有循环体系* 3,赋值时,i+1位置的元素应该是node.next 所以,应为node.next最后赋值* @param i* @param object* @throws Exception*/public void insert(int i,Object object) throws Exception{if(i<0 || i>length())throw new Exception("下标不合法");DupNode node = head;int j = 0;while(!node.next.equals(head) && j<i){j++;node = node.next;}
// DupNode newNode = new DupNode(object);
// node.next.prior = newNode;
// newNode.prior = node;
// newNode.next = node.next;
// node.next = newNode;//写成以下这种和上面注释的部分,效果一样,无区别DupNode newNode = new DupNode(object,node,node.next);node.next.prior = newNode;node.next = newNode;}
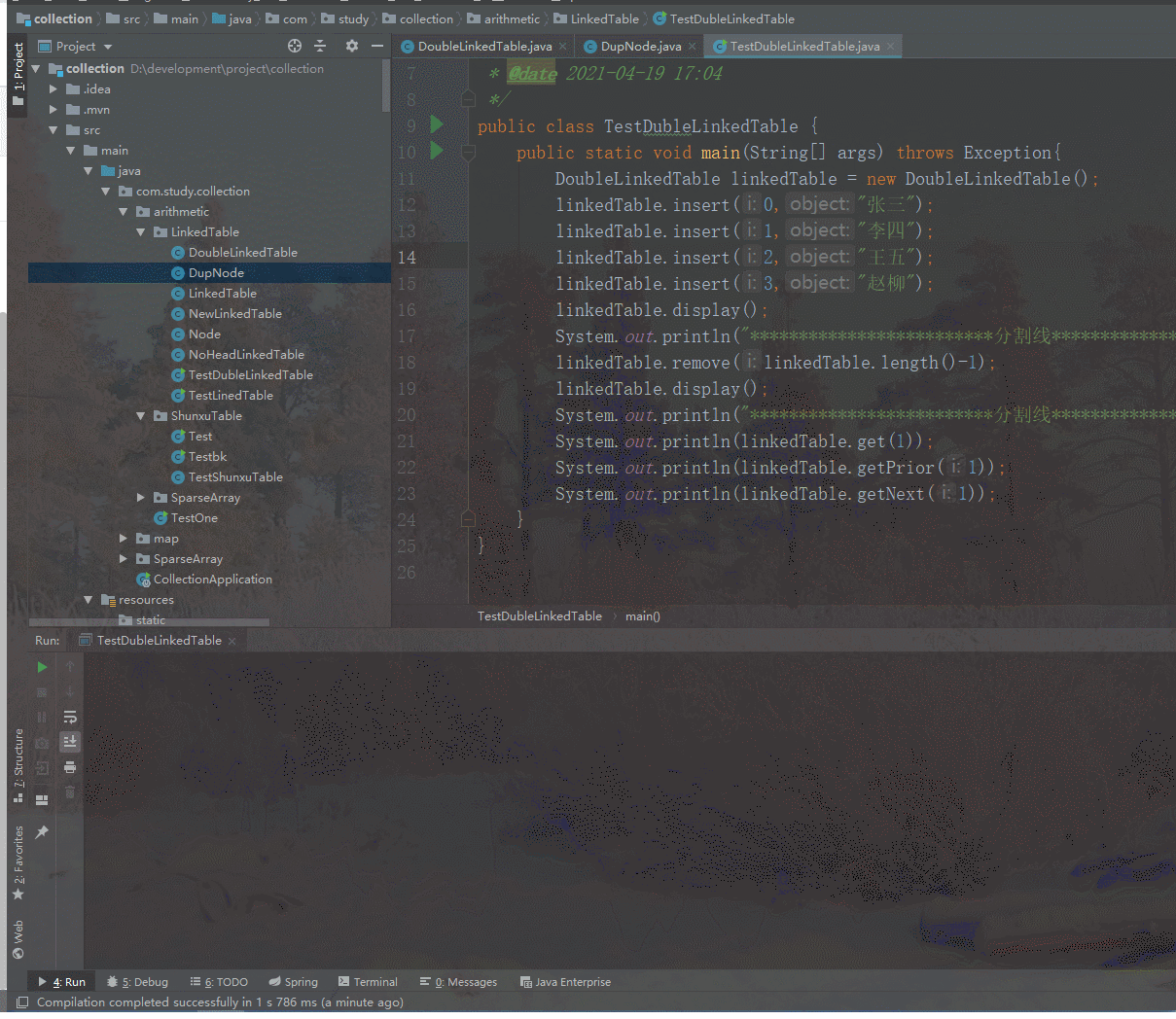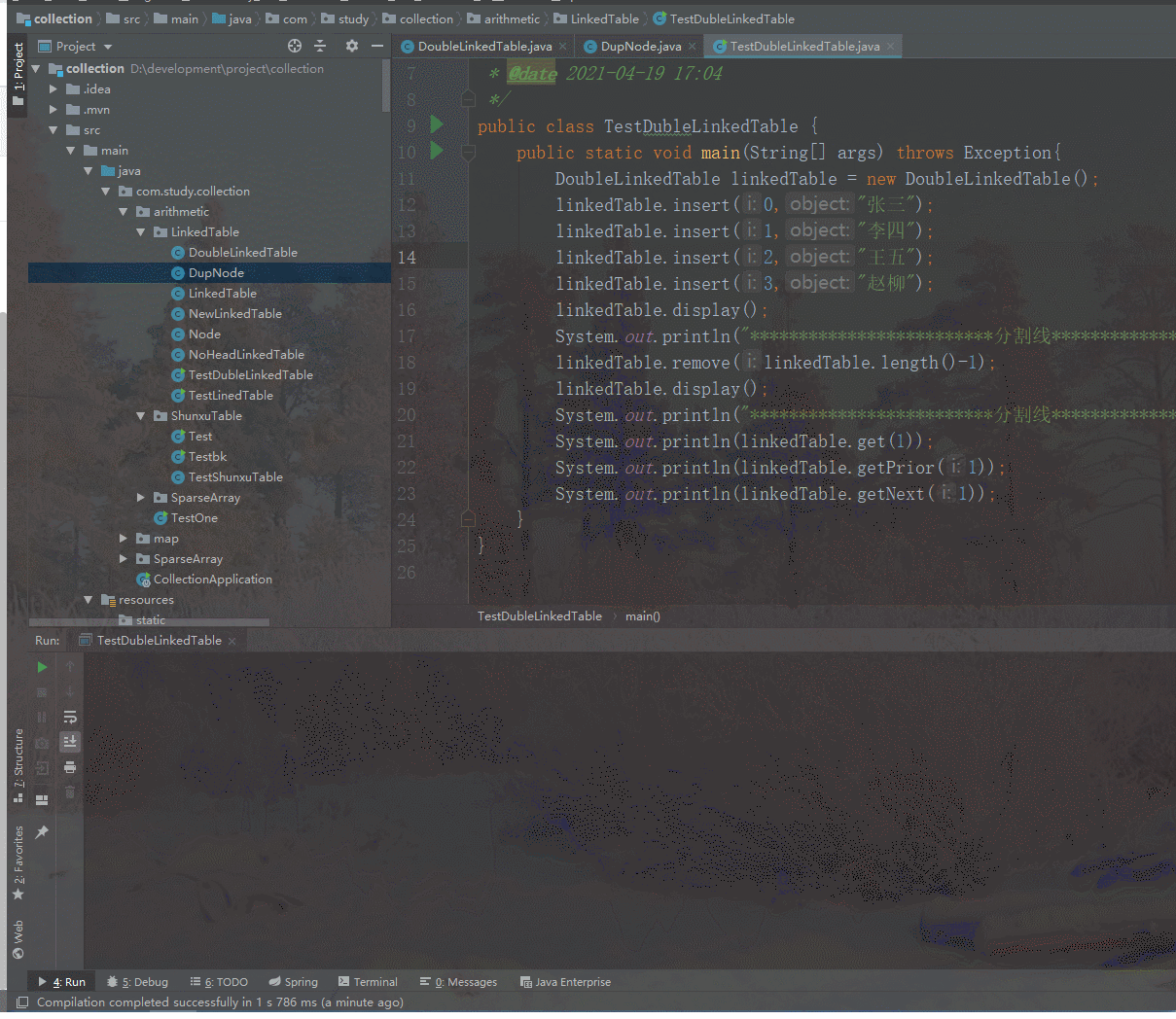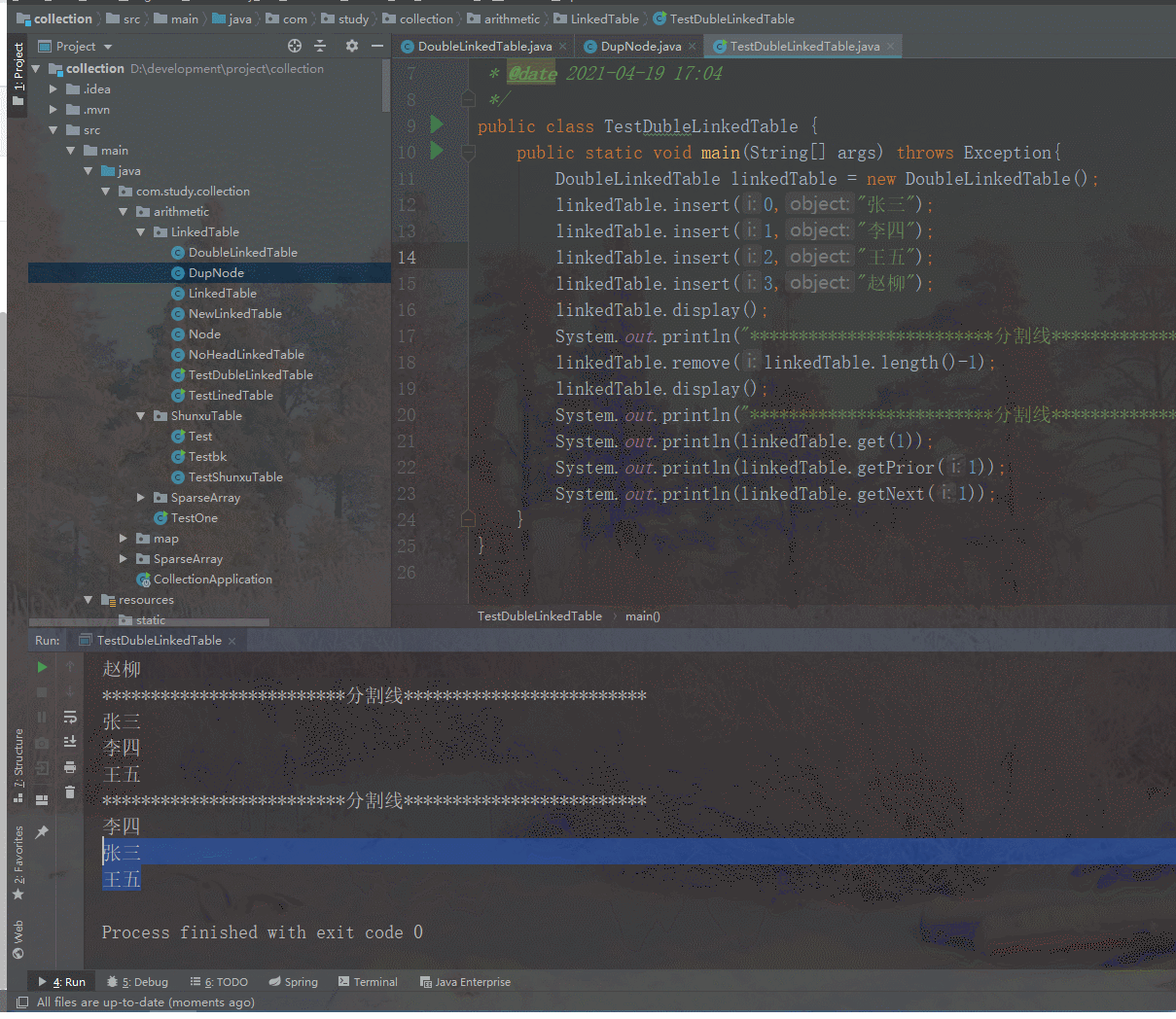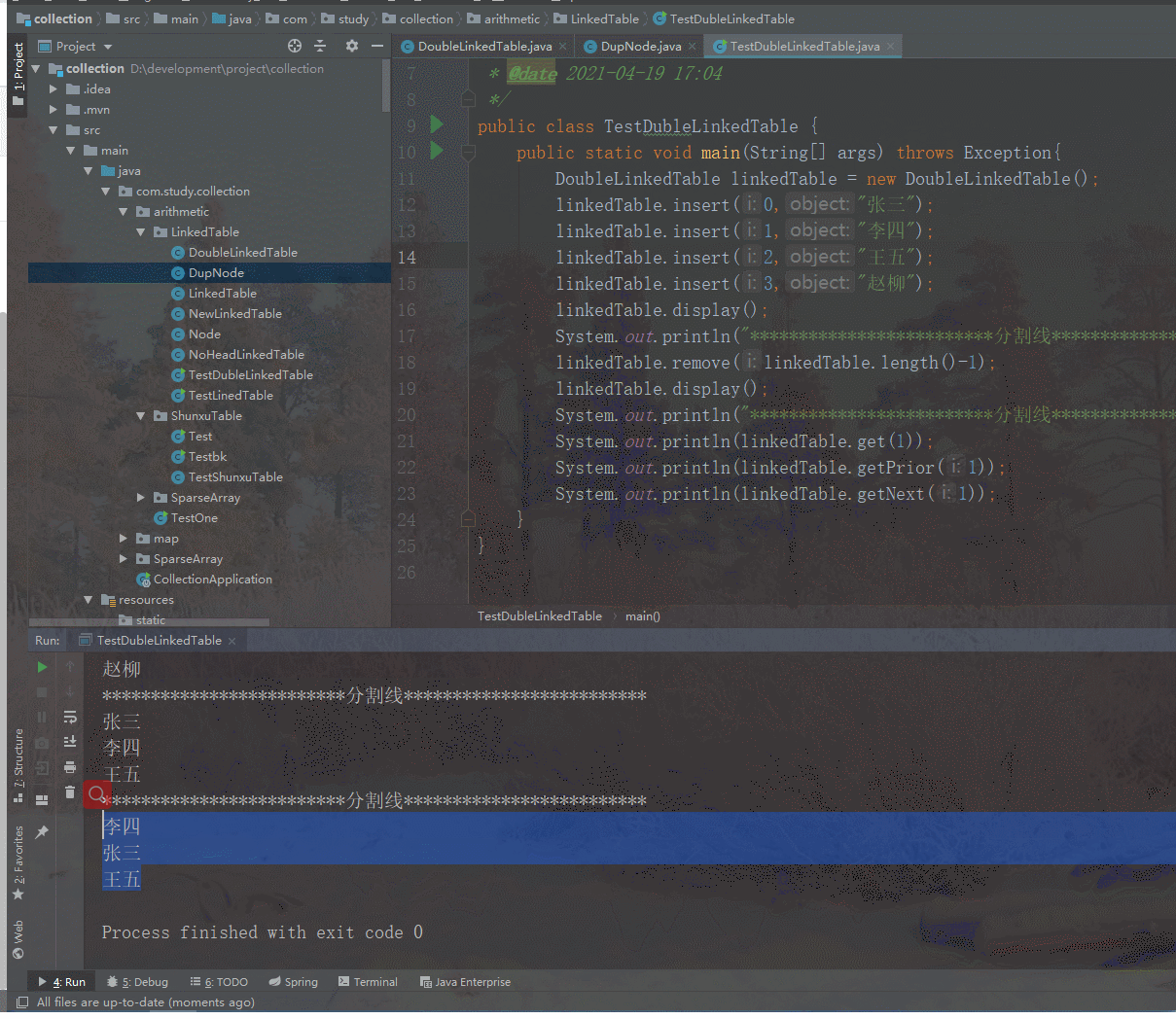
到了这里,我们就可以初步测试下,双向链表的插入是否有效了,下面创建一个测试类测试下,如下图所示,将几个元素插入到了双向循环链表中,然后输出结果正常,说明插入方法实现无误。有了这些头插法、尾插法直接根据下标即可轻松实现,这里不展示了。

- 提供根据下标删除的方法:remove(int i)
实现思路其实和单链表的删除是没有区别的:寻找到下标为i-1的数据元素,然后将他的后继更改为i+1的数据元素,然后将下标为i+1的数据元素的前驱更改为,下标为i-1的数据元素即可,实现如下:
//删除
public void remove(int i) throws Exception{if(i<0 || i>length()-1)throw new Exception("下标不合法");DupNode node = head;int j = 0;while(!node.next.equals(head) && j<i){j++;node = node.next;}node.next = node.next.next;node.next.prior = node;
}
然后来测试下删除方法,就测试下删除下标为2的元素吧,理论上删除后,输出的应该是:张三、李四、赵柳,如下图可见,输出无误,可见删除方法实现时无误的。

- 提供根据下标获取方法(get(int i))、根据指定结点获取前一个结点方法(getPrior)、根据指定结点获取后一个结点信息方法(getNext)
上面也说过,双向链表解决的问题就是在获取指定结点的上一个结点时是无需遍历链表的,这样大大节省了时间成本,这里就测试下该方法的实现。三个方法的实现如下所示:
//根据下标获取public Object get(int i) throws Exception{return getNode(i).object;}//根据下标获取其前一个元素public Object getPrior(int i) throws Exception{return getNode(i).prior.object;}//根据下标获取其后一个元素public Object getNext(int i) throws Exception{return getNode(i).next.object;}public DupNode getNode(int i) throws Exception{if(i<0 || i>length())throw new Exception("下标不合法");DupNode node = head.next;int j =0;while(node.equals(head) && j<i){j++;node = node.next;}return node;}
下面我们来测试下这三个方法是否正确,使用李四所在结点来进行测试,李四的下标应该是1,传入1分别运行三个方法,若是正确应该输出的是:李四、张三、王五,如下图可见结果正确。
三、总结
-
链表的缺点
线性表的两种实现顺序表、链表。相比于顺序表,链表的缺点就是查找元素比较慢,查找元素的时间复杂度是O(n),而顺序表的时间复杂度是O(1),在查找上顺序表要优于链表,链表查找慢,就是它的缺点了,但是双向循环链表在一定程度上减少了查找时的时间复杂度,但是依然是不及顺序表的查找效率的,所以具体的使用场景还是静态数据适合使用顺序表,动态数据适合使用链表。 -
链表的优点
顺序表在指定下标x位置插入元素,组需要后移n-x+1个元素,若是删除下标为x的数据元素,则需要向前移动n-x个数据元素,但是链表则不需要移动任何元素,链表需要做的只是找到对应的元素将指针域中的指针进行更新即可。链表的插入和删除的时间复杂度可以看成O(1),而顺序表插入和删除操作的都是O(n).所以链表的优点就是插入和删除比较快。 -
如何使用链表
所以综合链表的优点与缺点我们可以发现,顺序表更适合存储“静态”型数据,而链表更适合存储“动态”型数据,何为动态型呢,就是那些插入、删除操作比较频繁的数据。这类数据更适合使用链表存储。而数据结构不易改变的数据使用顺序表存储更合适。顺序表可类比java中的ArrayList,链表可类比java中的LinkedList。这两者都是顺序表与链表的典型应用。

![[前端笔记037]vue2之vuex](https://img-blog.csdnimg.cn/img_convert/11a966479bad6de2bc521d30b90d391f.png)