Pytorch中四种归一化层的原理和代码使用
- 前言
- 1 Batch Normalization(2015年提出)
- Pytorch官网解释
- 原理
- Pytorch代码
- 示例
- 2 Layer Normalization(2016年提出)
- Pytorch官网解释
- 原理
- Pytorch代码
- 示例
- 3 Instance Normalization(2017年提出)
- Pytorch官方解释
- 原理
- Pytorch代码
- 示例
- 4 Group Normalization(2018年提出)
- Pytorch官方解释
- 原理
- Pytorch代码
- 示例
前言
在训练神经网络时,往往需要标准化(Normalization)输入数据,使得网络的训练更加快速和有效,然而SGD等学习算法会在训练中不断改变网络的参数,隐含层的激活值的分布会因此发生变化,而这一种变化就称为内协变量偏移(Internal Covariate Shift,ICS)。
为了减轻ICS问题,Nomalization固定激活函数的输入变量的均值和方差(Nomalization后接激活函数),使得网络的训练更快。其计算方式大白话如下:将输入的数据,按照一定维度进行统计,得到数据的均值和方差,然后对数据结合均值和方差进行计算,将其变化为服从均值为0,方差为1的高斯分布,这样有助于加快网络训练速度。同时为了降低由于数据变化导致降低模型的表达能力,Nomalization提供了两个参数,用来对数据进行仿射变换,让这些数据靠近原始数据(最极限情况是这两个参数又将变换后的数据变为原来的数据)。
以下图片清晰的给出了不同归一化层的区别:
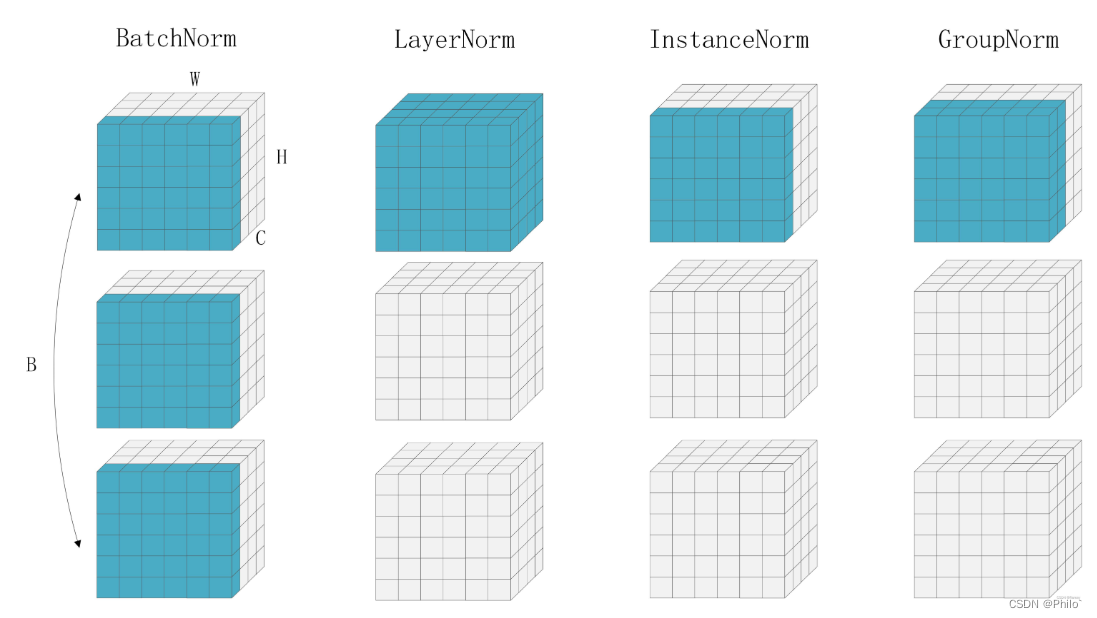
我当时见过另外一种图,较为抽象,一直没太看懂,当时看到这个图,醍醐灌顶,一下就都通了。
1 Batch Normalization(2015年提出)
Pytorch官网解释
BatchNorm2d
原理
针对输入到BN层的数据X,对所有 batch的单个通道做归一化,每个通道都分别做一次,公式如下:
y=x−E[x]Var[x]+ϵ∗γ+β\mathrm{y}=\frac{\mathrm{x}-\mathrm{E}[\mathrm{x}]}{\sqrt{\mathrm{Var}[\mathrm{x}]+\epsilon}} * \gamma+\beta y=Var[x]+ϵx−E[x]∗γ+β
其中:
- E[x]\mathrm{E}[\mathrm{x}]E[x] 是向量x的均值
- Var[x]\mathrm{Var}[\mathrm{x}]Var[x] 是向量x的方差
- ϵ\epsilonϵ 为很小的常数,通常为0.00001,防止分母为0
- γ\gammaγ 为仿射变换参数,模型可学习
- β\betaβ 为放射变换参数,模型可学习
公式中gama之前的数据就是标准化后的数据,满足均值为0,方差为1的高斯分布,便于加快网络训练速度。
但是标准化有可能会降低模型的表达能力,因为网络中的某些隐藏层很有可能就是血需要输入数据是非标准分布的,因此提供gama和beta进行学习,用于恢复网络的表达能力。
Pytorch代码
torch.nn.BatchNorm2d(num_features, eps=1e-5, momentum=0.1, affine=True, track_running_stats=True)
- num_features: 传入的通道数
- eps:常数ϵ\epsilonϵ, 默认为0.00001
- monentum:动量参数,用来控制均值和方差的更新
- affine:仿射变换的开关:默认打开
- 如果 affine=False,则γ\gammaγ=1, β\betaβ=0,参数不能学习
- 如果 affine=True, 则γ\gammaγ,β\betaβ可学习
- track_running_stats: 如果为 True,则统计跟踪 batch 的个数,记录在 num_batches_tracked 中,一般不用管。
示例
import torch
import torch.nn as nninput = torch.randn(20, 6, 10, 10)
m = nn.BatchNorm2d(6) y = m(input)
print(y.shape)out:
torch.Size([20, 6, 10, 10])
本文介绍的四种归一化层都不改变输入数据的维度大小!!
2 Layer Normalization(2016年提出)
Pytorch官网解释
LayerNorm
原理
针对输入到LN层的数据X,对单个Batch中的所有通道数据做归一化,然后每个batch都单独做一次,公式如下:
y=x−E[x]Var[x]+ϵ∗γ+β\mathrm{y}=\frac{\mathrm{x}-\mathrm{E}[\mathrm{x}]}{\sqrt{\mathrm{Var}[\mathrm{x}]+\epsilon}} * \gamma+\beta y=Var[x]+ϵx−E[x]∗γ+β
参照Batch Normalization公式和最上面的图进行理解,就是针对不同维度的数据进行标准化,其他的没变。Transformer中使用的就是LayerNorm。
Pytorch代码
torch.nn.LayerNorm(normalized_shape, eps=1e-5, elementwise_affine=True)
- normalized_shape: 输入数据的维度(除了batch维度),例:数据维度【16, 64, 256, 256】 传入的normalized_shape维度为【64, 256, 256】。
- eps: 常数,默认值为0.00001
- elementwise_affine:仿射变换的开关:默认打开
- 如果 elementwise_affine=False,则γ\gammaγ=1, β\betaβ=0,参数不能学习
- 如果 elementwise_affine=True, 则γ\gammaγ,β\betaβ可学习
示例
import torch
import torch.nn as nnln = nn.LayerNorm([64, 256, 256])
x = torch.randn(16, 64, 256, 256)
y = ln(x)
print(y.shape)out:
torch.Size([16, 64, 256, 256])
我也是最近才用了这个,因为要事先传入维度大小(C,H,W),所以使用的时候没有BN那么方便,如果想用,需要提前自己计算一下数据到LN这里的维度是多少,然后进行实例化才可以。
3 Instance Normalization(2017年提出)
Pytorch官方解释
InstanceNorm2d
原理
针对输入到IN层的数据X,对单个Batch中的单个通道数据做归一化,然后每个batch的每个通道单独做一次,公式如下:
y=x−E[x]Var[x]+ϵ∗γ+β\mathrm{y}=\frac{\mathrm{x}-\mathrm{E}[\mathrm{x}]}{\sqrt{\mathrm{Var}[\mathrm{x}]+\epsilon}} * \gamma+\beta y=Var[x]+ϵx−E[x]∗γ+β
公式还是那个公式,理解还是那个理解,请看明白最上面的那种图,就清楚了。
Pytorch代码
torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
- num_features: 是通道数
- eps:常数ϵ\epsilonϵ, 默认为0.00001
- monentum:动量参数,用来控制均值和方差的更新
- affine:仿射变换的开关:默认关闭
- 如果 affine=False,则γ\gammaγ=1, β\betaβ=0,参数不能学习
- 如果affine=True, 则γ\gammaγ,β\betaβ可学习
示例
# Without Learnable Parameters
m = nn.InstanceNorm2d(100)
# With Learnable Parameters
m = nn.InstanceNorm2d(100, affine=True)
input = torch.randn(20, 100, 35, 45)
output = m(input)
print(output.shape)out:
torch.Size([20, 100, 35, 45])
这个初始化只需要传入通道数即可,和BN的实例化方法一样,便于使用!
4 Group Normalization(2018年提出)
Pytorch官方解释
GroupNoem
原理
针对输入到GN层的数据X,对单个Batch中的多个通道数据(一组数据)做归一化,然后每个batch的每组数据单独做一次,公式如下:
y=x−E[x]Var[x]+ϵ∗γ+β\mathrm{y}=\frac{\mathrm{x}-\mathrm{E}[\mathrm{x}]}{\sqrt{\mathrm{Var}[\mathrm{x}]+\epsilon}} * \gamma+\beta y=Var[x]+ϵx−E[x]∗γ+β
公式还是那个公式,理解还是那个理解,请看明白最上面的那种图,就清楚了。
不是我偷懒,实际情况是,Pytorch官网给出的四个公式也就是一样的!
Pytorch代码
torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)
- num_groups: 需要将Batch中的通道分为几组
- num_channels: 传入的数据通道数
- eps:常数ϵ\epsilonϵ, 默认为0.00001
- affine:仿射变换的开关:默认打开
- 如果 affine=False,则γ\gammaγ=1, β\betaβ=0,参数不能学习
- 如果affine=True, 则γ\gammaγ,β\betaβ可学习
示例
import torch
import torch.nn as nninput = torch.randn(20, 6, 10, 10)m3 = nn.GroupNorm(3, 6) # 分成3组
m6 = nn.GroupNorm(6, 6) # 分成6组,这个就和IN一样了
m1 = nn.GroupNorm(1, 6) # 分成1组,这个就和LN一样了y1 = m1(input)
y3 = m3(input)
y6 = m6(input)
print(y1.shape)
print(y3.shape)
print(y6.shape)out:
torch.Size([20, 6, 10, 10])
torch.Size([20, 6, 10, 10])
torch.Size([20, 6, 10, 10])
参考:
https://blog.csdn.net/qq_33236581/article/details/124016573
https://zhuanlan.zhihu.com/p/470260895
如果感觉有用,就及时
收藏点赞,否则后期又要翻找,跟着我,一步一步学CV