1. 网站分析
本文实现的爬虫是抓取京东商城指定苹果手机的评论信息。使用 requests 抓取手机评论 API 信息,然后通过 json 模块的相应 API 将返回的 JSON 格式的字符串转换为 JSON 对象,并提取其中感兴趣的信息。读者可以点击此处打开 京东商城,如下图所示:
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
URL 是 苹果手机商品 。商品页面如下图所示:
在页面的下方是导航条,读者可以单击导航条上的数字按钮,切换到不同的页面,会发现浏览器地址栏的 URL 并没改变,这种情况一般都是通过另外的通道获取的数据,然后将数据动态显示在页面上。那么如何来寻找这个通道的 URL 呢?
在 Chrome 浏览器的开发者工具的 Network 选项中单击 XHR 按钮,再切换到其他页,并没有发现要找的 API URL,可能京东商城获取数据的方式有些特殊,不是通过 XMLHttpRequest 发送的请求。
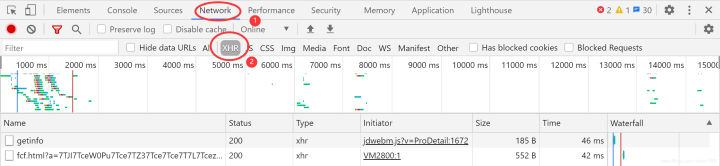
所以重新选中 All 按钮,显示所有的 URL。现在用另外一种方式寻找这个 URL,就是 Filter。通过左上角的 Filter 输入框,可以通过关键字搜索 URL,由于本文是抓取评论数据,所以可以尝试输入 comments,在左下角的列表中会出现如下图所示的内容。
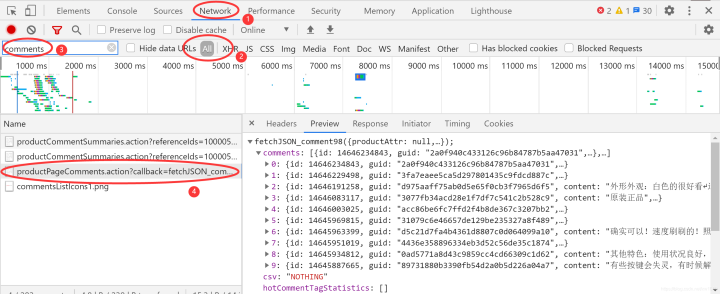
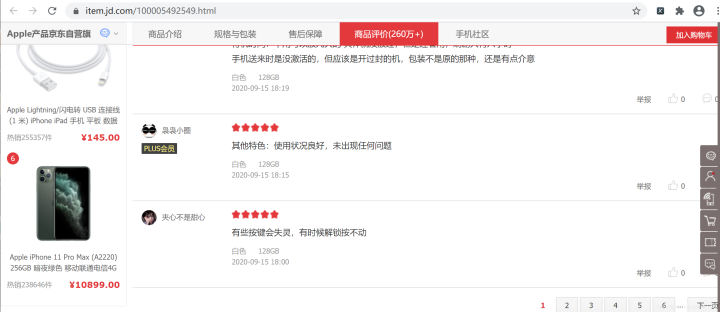
在搜索结果中会看到 1个名为 productPageComments.action 的 URL ,单机这个 URL,在右侧切换到 Preview 选项卡,会看到如上图所示的内容,很明显,这是 JSON 格式的数据,展开 comments ,会看到有 10 项 ,这是返回的 10 条评论。在展开某一条评论,如下图所示:
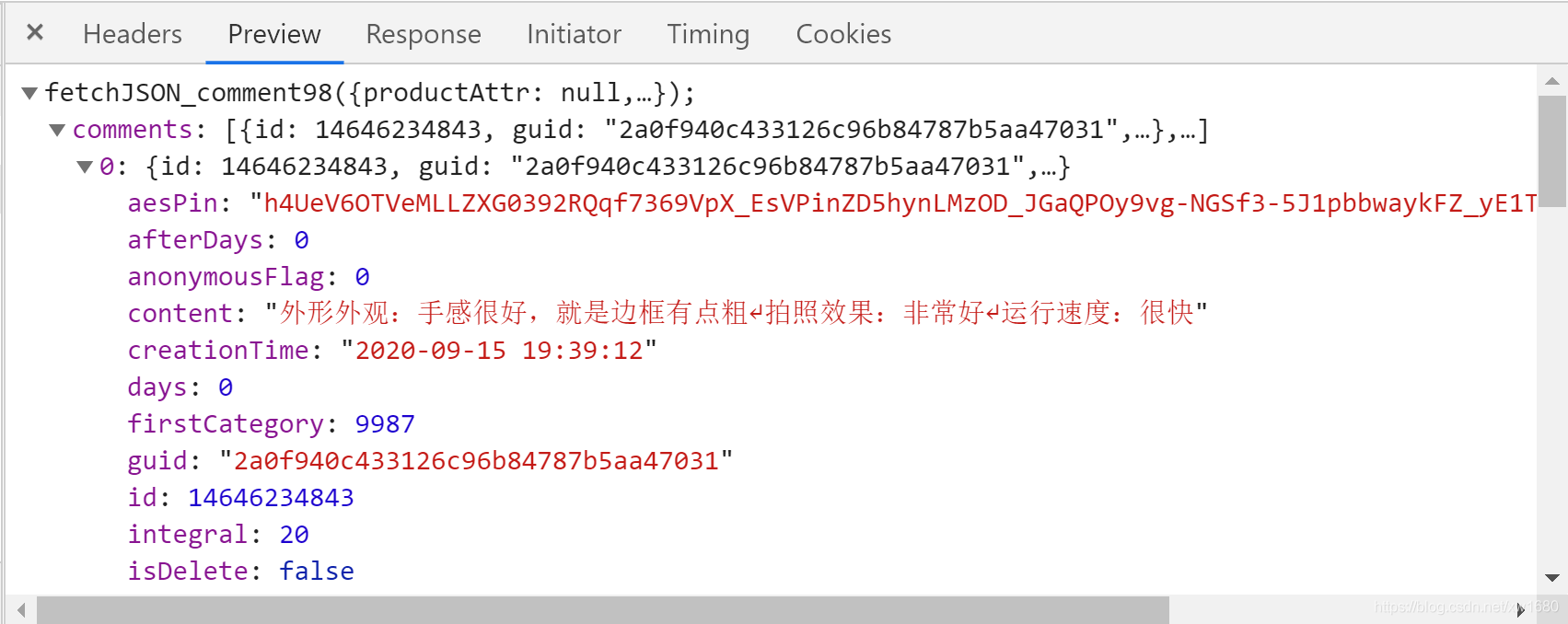
从属性的内容可以看出,content 属性是评论内容,creationTime 是评论时间,days 是购买多长时间后才来评论的。通过 Headers 选项卡可以得到如下完整的 URL 。
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100005492549&score=0&sortType=5&page=0&pageSize=10&isShadowSku=100008348530&fold=1
从这个 URL 可以看出,page 参数表示页数,从 0 开始,pageSize 参数表示每页获取的评论数,默认是 10,这个参数可以保留默认值,只改变 page 参数即可。
2. 示例代码
根据前面的描述实现抓取苹果手机评论信息的爬虫,通过 fetch_comment_count 变量可以控制抓取的评论条数。最后将抓取的结果显示在控制台中。示例代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:4.抓取京东苹果手机评论.py
@time:2020/09/15
"""
import requests
import jsonheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}fetch_comment_count = 1000 # 限定抓取的评论数
index = 0 # 用于记录爬取到第几条评论
page_index = 0 # 页码
flag = True # 用于控制循环是否退出while flag:url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100005492549&score=0&sortType=6&page={}&pageSize=10&isShadowSku=100008348530&rid=0&fold=1'.format(page_index)page_index += 1res = requests.get(url=url, headers=headers)text = res.text# 下面的代码替换返回数据的部分内容,因为返回的数据并不是标准的 JSON 格式json_str = text.replace('fetchJSON_comment98(', '')[:-2]json_obj = json.loads(json_str) # 将字符串转换为字典对象comments_list = json_obj['comments']comments_list_length = len(comments_list)# 循环输出评论数据for i in range(comments_list_length):comments = comments_list[i]['content']print(f'< {index + 1} > {comments}')creation_time = comments_list[i]['creationTime'] # 获取评论时间nickname = comments_list[i]['nickname'] # 获取昵称print(creation_time)print(nickname)print("-" * 20)index += 1if index == fetch_comment_count:flag = Falsebreak
程序运行结果如下图所示:
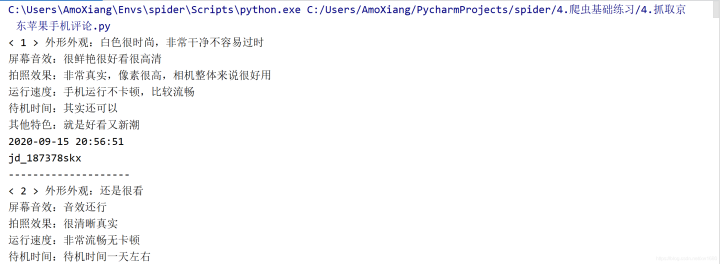
3. 注意事项
-
京东商城如果频繁使用同一个 IP 发起大量请求,服务端会临时性封锁 IP,可以使用一些免费的代理。
-
API URL 返回的数据并不是标准的 JSON,里面还有一些杂质,需要在本地将其删除。 本例有一个前缀是 fetchJSON_comment98 ,这个前缀是通过 URL 的 callback 参数指定的,根据参数名应该是个回调函数,具体是什么不需要管,总之,需要按照 callback参数的值将返回数据的前缀去掉。
-
原文地址:Python爬虫实战(二):抓取京东苹果手机评价_Amo Xiang的博客-CSDN博客




