pytorch使用DCN
- 前言
- 正文
前言
关于DCN可形变卷积神经网络相信大家也都不陌生,使用额外的feature map区学习offset,以此达到可形变的效果。感觉和attention比较相似?
但是网络实现的代码版本各不相同,编译环境存在很多难以协调等等的问题。而MMopenlab是一个非常不错的工具,其有着实现可形变卷积的方法,因此本文只是做一个引入,如何像正常使卷积一样的使用DCN
正文
from mmcv.ops import DeformConv2dPack
import torch
from torch import nn
from thop import profile
import timeclass Conv(nn.Module):def __init__(self,indim,outdim,kerner=3,stride=1):super(Conv, self).__init__()self.conv1 = nn.Conv2d(indim,outdim,kernel_size=kerner,stride=stride,padding=kerner//2)self.act = nn.LeakyReLU(0.1)self.bn = nn.BatchNorm2d(outdim)def forward(self,x):return self.bn(self.act(self.conv1(x)))class Dconv(nn.Module):def __init__(self, indim, outdim, kerner=3, stride=1):super(Dconv, self).__init__()self.conv1 = DeformConv2dPack(indim, outdim, kernel_size=kerner, stride=stride, padding=kerner // 2,deform_groups=2)self.act = nn.LeakyReLU(0.1)self.bn = nn.BatchNorm2d(outdim)def forward(self, x):return self.bn(self.act(self.conv1(x)))
接下来是对两个定义的结构进行测试
conv1 = Conv(128,256).cuda()
dconv1 = Dconv(128,256).cuda()
input = torch.randn(4,128,640,640).cuda()t1 = time.time()
out1 = conv1(input)
t2 = time.time()
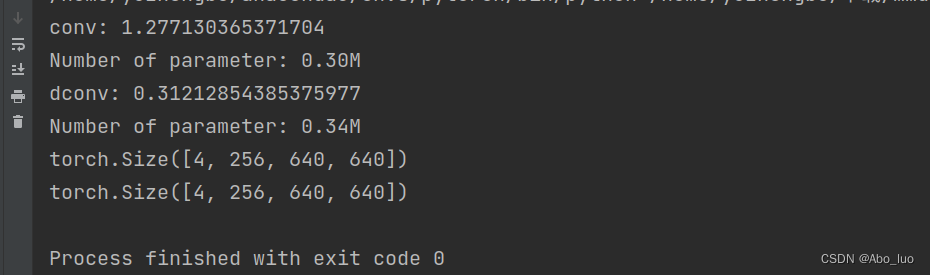
print('conv:',t2-t1)
total = sum([param.nelement() for param in conv1.parameters()])
print("Number of parameter: %.2fM" % (total / 1e6))
out2 = dconv1(input)
t3 =time.time()
print('dconv:',t3-t2)
total = sum([param.nelement() for param in dconv1.parameters()])
print("Number of parameter: %.2fM" % (total / 1e6))print(out1.shape)
print(out2.shape)相比较正常的CONV而言,DCN的参数量更大一些。