1.对于路由配置的正则化补充(re_path的正则匹配)
对于第一天学习的path转换器过于暴力,对于需要匹配的内容不能很精准的进行转换。为了实现精准的字符串匹配规则,因此引入了re_path(reg,view,name=xxx)进行路由规则的精确匹配。
正则表达式为命名分组模式(?Ppattern);匹配提取参数后用关键字传参的方式传递给视图函数。
样例:
#可匹配 http://127.0.0.1:8000/20/mul/40
#不可匹配 http://127.0.0.1:8000/200/mul/400
Urlpatterns = [Path(‘admin/’,admin.site.urls),re_path(r‘^(?P<x>\d{1,2})/(?P<op>\w+)/(?P(y)\d{1,2})$’,views.cal_view)
]
例如需要匹配的路径为/birthday/年/月/日或 /birthday/日/月/年
则正则表达式的re_path编写内容为:
re_path(r'^birthday/(?P<year>\d{4})/(?P<month>\d{1,2})/(?P<day>\d{1,2})$', views.calc_birthday),
re_path(r'^birthday/(?P<day>\d{1,2})/(?P<month>\d{1,2})/(?P<year>\d{4})$', views.calc_birthday),
视图函数的内容为:
def calc_birthday(request,year,month,day):html = "生日为%s年%s月%s日" % (year, month, day)return HttpResponse(html)
2.请求和响应
请求是指客户端通过http协议向服务器发起的请求。
而应答就是在views.py中定义的视图函数的HttpResponse,也就是服务器对客户端返回的响应response。
在HTTP请求中,常用的有三种方法:
1.GET请求。请求指定的页面,并返回实体主体。
2.HEAD请求。类似与get请求,但是HEAD请求主要获得该页面支持的请求头类型。
3.POST请求。向指定的资源提交数据并进行请求处理。
4.PUT请求。用于传送指定的文档到服务器中。
5.DELETE请求。用于请求删除服务器的指定页面内容。
6.CONNECT请求。HTTP/1.1协议中预留的能够将连接改为管道方式的代理服务器。
7.OPTIONS,允许客户端查看服务器的性能。
8.TRACE。回显服务器收到的请求,用于测试和诊断。
请求在django中就是视图函数的第一个参数,即HttpRequest对象。
Django接收到HTTP协议的请求后,会根据请求数据报文创建HttpRequest对象。
HttpRequest对象通过属性描述请求的所有相关信息。
因此,在视图函数中,函数的第一个参数request其实就包含了客户端请求的各类的信息。那么就可以调出请求中的相关信息。
因此,对于GET请求和POST请求中的处理主要就是对requests参数的处理。从客户端的请求中获取相关的信息。
Request参数对象所拥有的一些属性。
1.path_info,URL字符串。
2.Method,字符串,表示HTTP的请求方法。
3.GET,QueryDict查询的字典的对象,包含get请求方式获得的所有数据。
4.POST,QueryDict查询的字典的对象,包含post请求方式获得的所有数据。
5.FILES,是一个类似于字典的对象,包含了所有上传的文件的信息。
6.COOKIES
7.session
8.META类似于PHP的$_SERVER.
方法:
get_full_path()获取完整路径
3.GET请求和POST请求
由于在request中get和post都是通过GET和POST属性进行保存的,那么通过输出request中的GET和POST属性能够发现,输出的GET和POST信息都是字典信息。如下图所示:
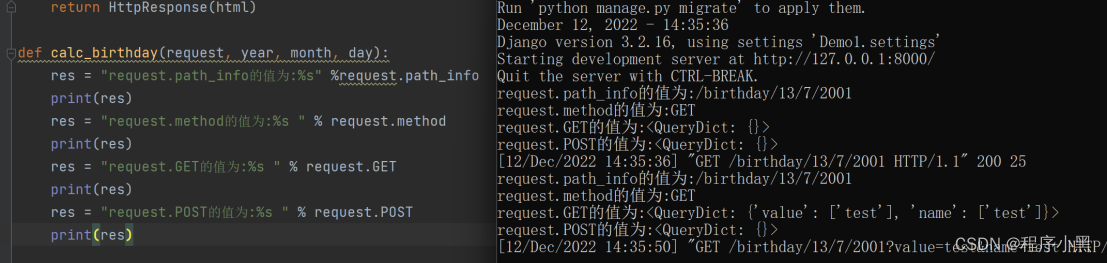
那么在这种情况下,我们能够发现,如果需要对用户的GET和POST请求进行分析,这是一个QueryDict的字典格式的数据,和正常的字典数据类型还不太相同。
因此,对于QueryDict数据格式进行分析,可以知道可以通过dict()方法对QueryDict数据格式进行转换,将其转换为dict格式的数据类型。
当然,QueryDict数据类型兼容一部分字典的操作,因此也可以直接通过字典的方法去访问QueryDict的数据类型。

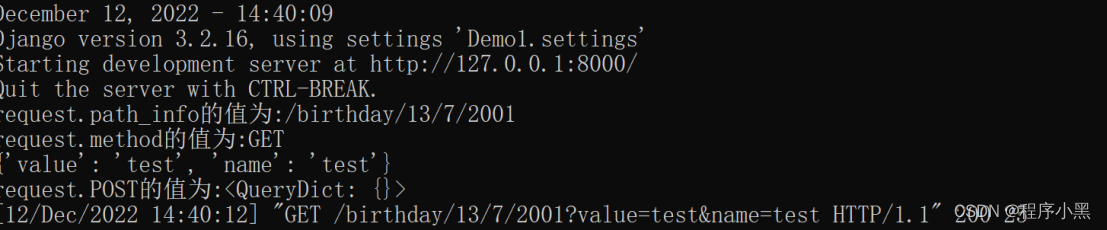 那么,获取key和value的时候只需要对字典类型的数据进行处理即可。
那么,获取key和value的时候只需要对字典类型的数据进行处理即可。
如果传递的参数内容是一个列表,那么需要对GET属性使用getlist(‘参数名’)来获取参数列表。
对于GET属性,存在get方法,get方法为get(key,value)。意思是:如果GET中存在KEY,则使用通过GET请求获得的KEY的值,否则KEY的默认值被置为value,并返回value信息。
如果在GET请求中出现了同名参数,那么该参数会变成一个字典。但是如果仅仅通过get参数去获取,那么只能获得最后一个参数。同样的,通过dict方法进行获取的话,也只能获得最后一个参数。这也算是QueryDict和Dict的一个区别。
因此,在实际使用过程中,如果实际的值有多个,例如html存在复选框的情况,一般使用getlist方法来获取多个值的数据。
而对于POSt请求,一般是提交大量数据或者是提交隐私数据的时候,一般使用POST请求。
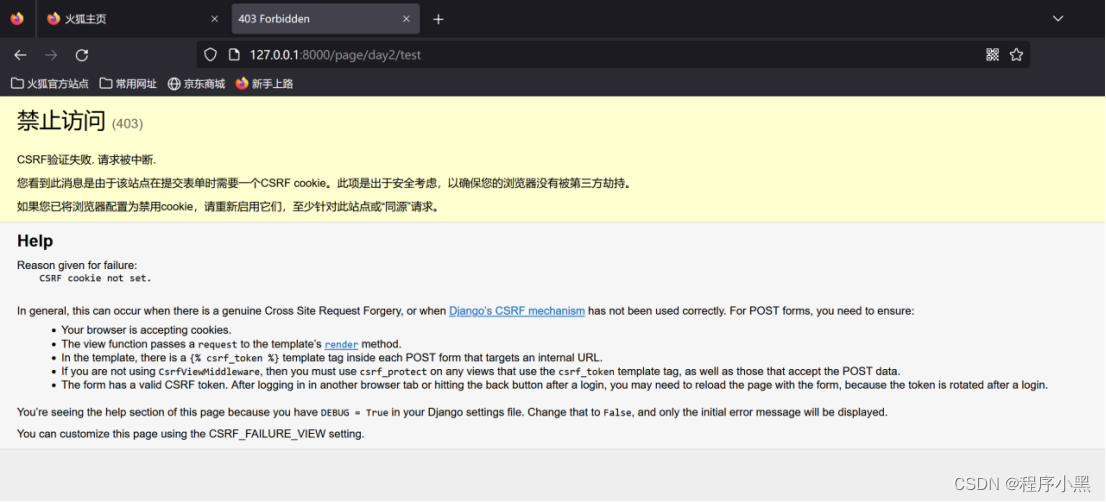 如果在本地使用POST进行测试发现出现CSRF攻击检测问题导致的403访问被拒绝,那么新手可以尝试通过暂时关闭csrf校验来跳过这个问题。
如果在本地使用POST进行测试发现出现CSRF攻击检测问题导致的403访问被拒绝,那么新手可以尝试通过暂时关闭csrf校验来跳过这个问题。
在settings.py文件中,通过找django.middleware.csrf.CsrfViewMiddleware的内容,并注释该行,就能暂时关闭csrf校验。
在后期,可以分安全策略来对csrf校验的具体内容再做具体分析。
对于HttpResponse函数的具体返回内容:
HttpResponse(content=响应体,content_type=响应体数据类型,status=状态码)
如果在返回时不对status进行修正,那么默认返回code将会为200
常用的Content-type类型:
1.text/html
2.text/plain
3.text/css
4.text/javascript
5.application/json
6.applicaion/xml
关于HttpResponse的子类:
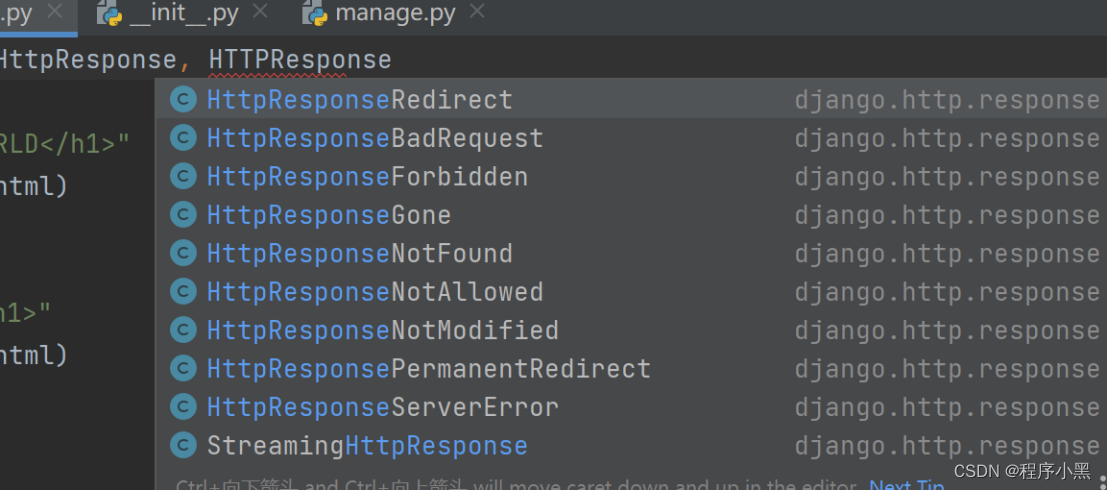 因此,可以考虑通过默认的子类来返回特定的内容。
因此,可以考虑通过默认的子类来返回特定的内容。

例如直接使用HttpResponseRedirect方法直接强制跳转到百度。
关于GET和POST请求而言,无论是何种请求方式,全部通过视图函数进行接收。但是需要通过判断request.method方法优先区分具体的请求动作。
例如:
If requst.method == 'GET':处理get请求的数据
If request.method == 'POST':处理post请求的业务逻辑
4.Django的设计模式和模板层
设计模式:
1.MVC,主要用于降低模块耦合度
M 模型层,主要用于对数据库层的封装
V 视图层,用于向用户展示结果
C 控制器,用于处理请求,获取数据并返回结果
2.MTV模式(Django专用)
M 模型层,负责和数据库的交互
T 模板层,负责呈现内容到浏览器
V 视图层,核心层,也就是负责接受请求,获取数据和结果。类似于MVC的C层,但是实际上C层在主路由文件中,利用路由模式定义的转发规则,来使用控制器来转发请求到视图层。
但是其实我本人觉得,这种方案和MVC并没有什么区别。
1.模板本身就是HTML。模板可以根据字典数据动态变化,生成不同的html网页。
2.模板本身根据视图中传递的字典数据动态生成html页面。
模板配置
1.创建模板文件夹,项目名下创建templates文件夹。
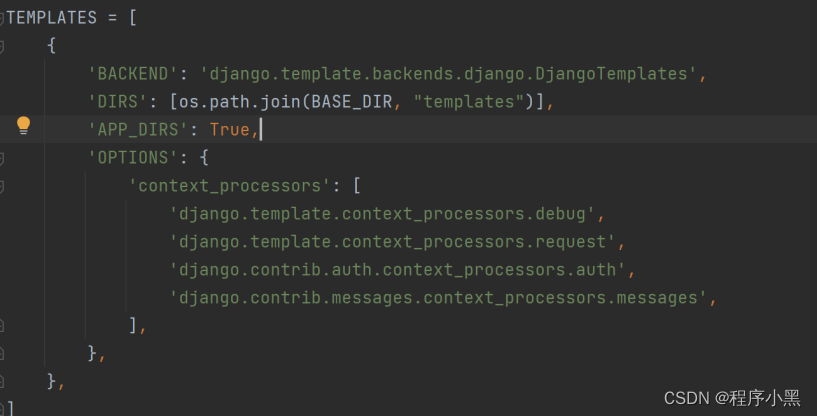
2.在settings.py中配置TEMPLATES配置项。
配置项一:BACKEND,指定模板的引擎
配置项二:DIRS,模板的搜索目录
配置项三:APP_DIRS,是否要在应用中的templates文件夹中的搜索文件
配置项四:OPTIONS,有关模板的选项。
通过配置settings.py文件下的templates文件夹的DIRS,如下图所示:
 例如在templates文件夹中增加html文件内容:
例如在templates文件夹中增加html文件内容:
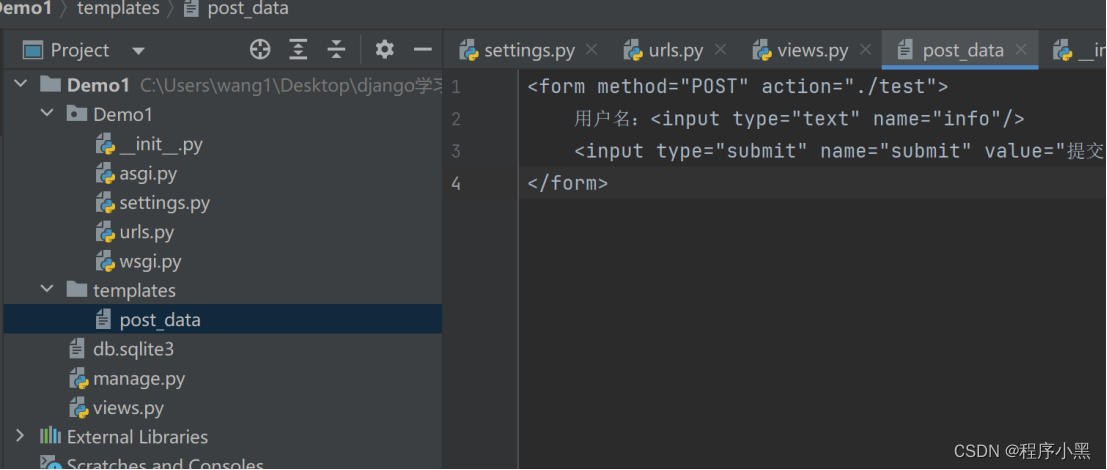
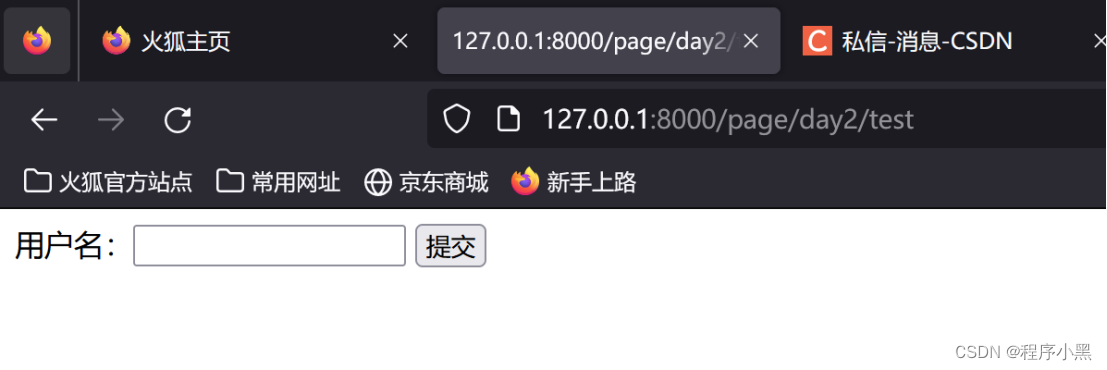
通过增加该文件内容到post_data文件后,在views.py文件中,从django.template中引入loader方法。
from django.template import loader
随后从post_data文件中读取该文件并通过HttpResponse文件返回给用户。
t = loader.get_template("post_data")html = t.render()Return HttpResponse(html)
即可成功从模板文件中加载最终页面。
方法2:直接载入render方法。
注意,需要载入shortcut包。
From django.shortcut import render
在视图层采用return render(request,’模板文件名’,’字典数据’)即可返回网页模板内容。
如果需要和模板层进行数据层面上的交互,那么可以尝试在页面中通过{{变量名}}进行对变量的定义,然后在视图层中对模板层的数据进行动态更新。
例如,在模板层中,可以尝试通过如下方式编写代码:
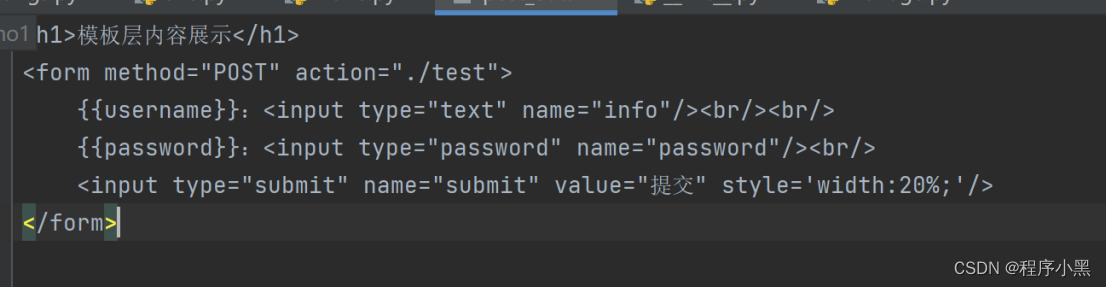
因此,在视图层中,可以通过如下方式进行数据的绑定。
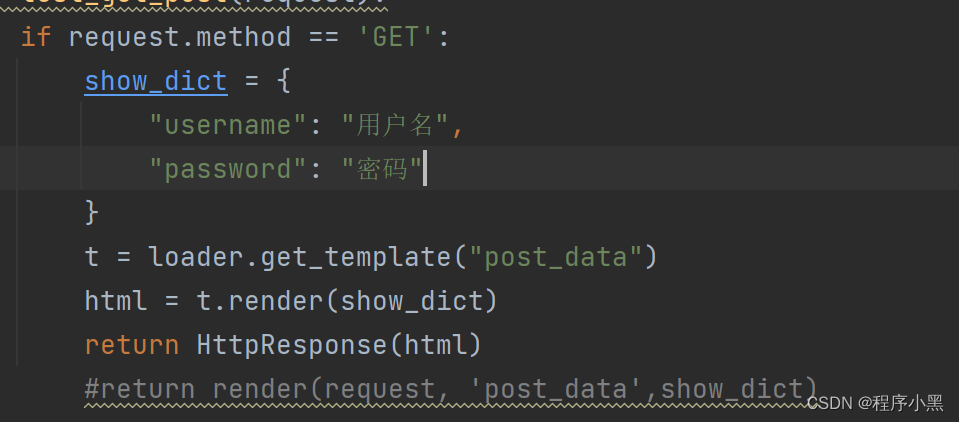
这种方式能够很好的实现模板层和视图层的数据交互,让数据的交互更加的便捷。





![[附源码]Node.js计算机毕业设计房屋中介管理信息系统Express](https://img-blog.csdnimg.cn/8092944f6c614d5f971e16fdfcfa6e56.png)