前言
其实就是利用了csv 和txt 文件转换 。

不多说,开始玩代码。
正文
本篇内容:
① 了解根本生成excel内容的CSV文件玩法
② 手动拼接文本演示
③ 项目内实战写法,从数据库到导出
④ 解决list数据过多,使用分批分页处理生成csv (EXCEL)
思路:
创建csv文件, 往里面写入符合转换成csv文件的内容 即可。
① 了解根本生成excel内容的CSV文件玩法
先看看什么原理 :
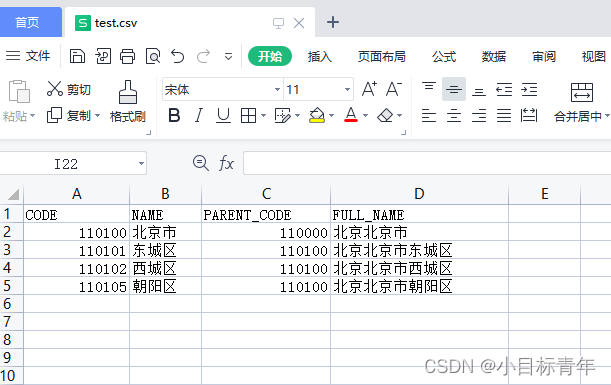
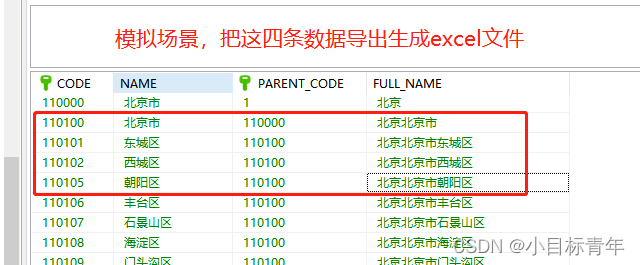
首先我们创建一个csv文件

然后打开里面填充一些数据:
然后反手把文件后缀改成.txt 看看里面是啥 :
看看里面:

② 手动拼接文本演示
工具类 :
MyCsvFileUtil.java
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.IOUtils;import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;@Slf4j
public class MyCsvFileUtil {public static final String CSV_DELIMITER = ",";public static final String CSV_TAIL = "\r\n";/*** 将字符串转成csv文件*/public static void createCsvFile(String savePath,String contextStr) throws IOException {File file = new File(savePath);//创建文件file.createNewFile();//创建文件输出流FileOutputStream fileOutputStream = new FileOutputStream(file);//将指定字节写入此文件输出流fileOutputStream.write(contextStr.getBytes("gbk"));fileOutputStream.flush();fileOutputStream.close();}/*** 写文件** @param fileName* @param content*/public static void writeFile(String fileName, String content) {FileOutputStream fos = null;OutputStreamWriter writer = null;try {fos = new FileOutputStream(fileName, true);writer = new OutputStreamWriter(fos, "GBK");writer.write(content);writer.flush();} catch (Exception e) {log.error("写文件异常|{}", e);} finally {if (fos != null) {IOUtils.closeQuietly(fos);}if (writer != null) {IOUtils.closeQuietly(writer);}}}演示拼接调用工具类生成CSV文件:
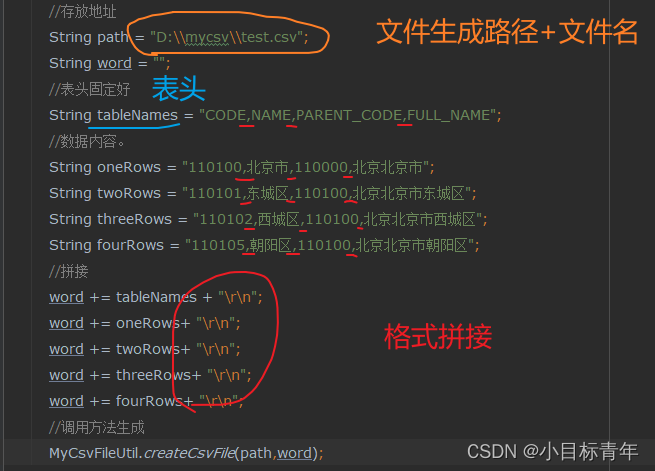
@RequestMapping("/createCsvFileTest")public void doTest() throws IOException {//存放地址String path = "D:\\mycsv\\test.csv";String word = "";//表头固定好String tableNames = "CODE,NAME,PARENT_CODE,FULL_NAME";//数据内容。String oneRows = "110100,北京市,110000,北京北京市";String twoRows = "110101,东城区,110100,北京北京市东城区";String threeRows = "110102,西城区,110100,北京北京市西城区";String fourRows = "110105,朝阳区,110100,北京北京市朝阳区";//拼接word += tableNames + "\r\n";word += oneRows+ "\r\n";word += twoRows+ "\r\n";word += threeRows+ "\r\n";word += fourRows+ "\r\n";//调用方法生成MyCsvFileUtil.createCsvFile(path,word);}代码简析:
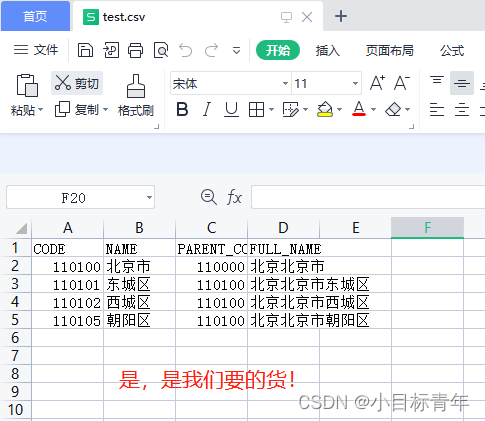
调用这个示例接口,看看效果: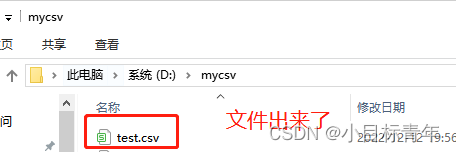
③ 项目内实战写法,从数据库到导出
接口使用写法:
@RequestMapping("/createCsvFileTest2")public void createCsvFileTest2() throws IOException {List<District> districts = districtMapper.queryByParentCodes(Arrays.asList("110100"));//存放地址&文件名String fileName = "D:\\mycsv\\test2.csv";String tableNames = "CODE,NAME,PARENT_CODE,FULL_NAME"+MyCsvFileUtil.CSV_DELIMITER;//创建文件MyCsvFileUtil.createCsvFile(fileName,tableNames);//写入数据String contentBody =buildCsvFileBody(districts);//调用方法生成MyCsvFileUtil.createCsvFile(fileName,contentBody);}解析数据list 做内容拼接处理 函数:
ps: 表头 多少个,字段就多少个, 默认值赋值啥的,格式转换啥的都可以,只要每一行数量对的上即可,每一个最后结尾的标记就是 String CSV_TAIL = "\r\n"
@RequestMapping("/createCsvFileTest2")public void createCsvFileTest2() throws IOException {List<District> districts = districtMapper.queryByParentCodes(Arrays.asList("110100"));//存放地址&文件名String fileName = "D:\\mycsv\\test2.csv";String tableNames = "CODE,NAME,PARENT_CODE,FULL_NAME"+MyCsvFileUtil.CSV_TAIL;//创建文件MyCsvFileUtil.writeFile(fileName,tableNames);//写入数据String contentBody =buildCsvFileBody(districts);//调用方法生成MyCsvFileUtil.writeFile(fileName,contentBody);}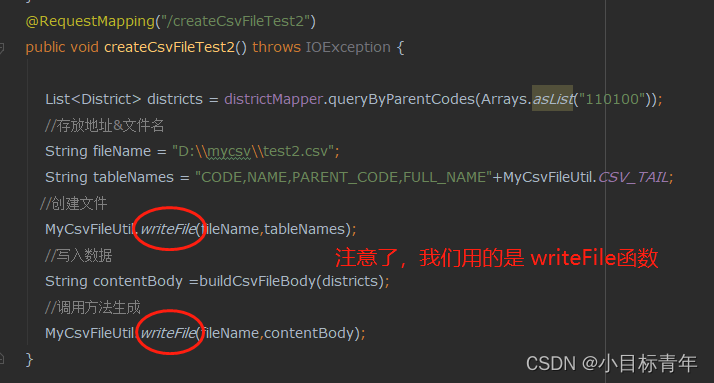
事不宜迟,看看接口调用效果:
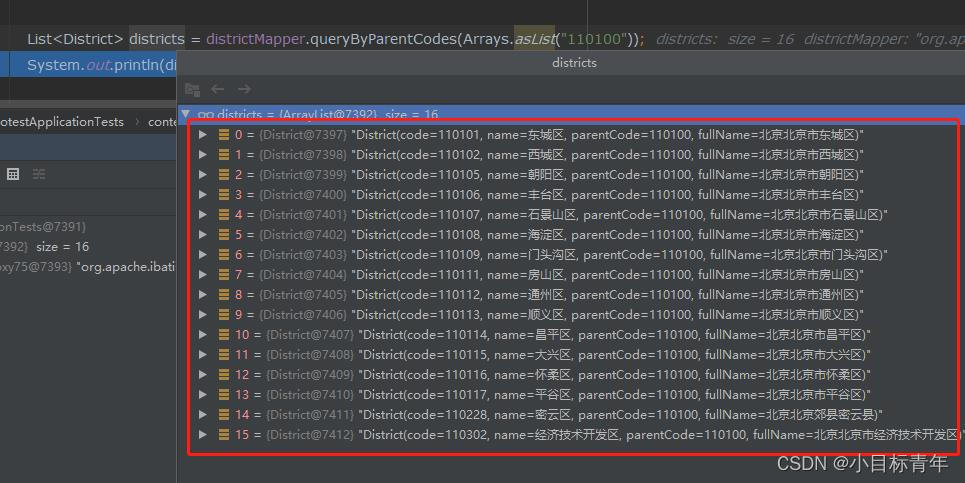
可以看到从数据量里面查出来这 16条数据,list集合:
最后转换生成文件:
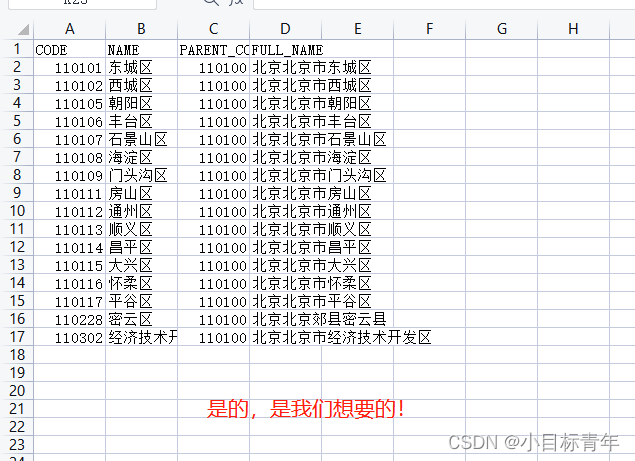
可以看到成功出货:
那么问题来了,如果我们需要导出的数据条数很多,拼接的contentBody 会非常长。
那么我们就需要考虑分批查询、分批拼接处理、分批写入,按照实际业务场景和数据长度去考量,每一批的限制。 甚至还可以实现拼接好每一批,然后慢慢再根据当前批次ID,做顺序写入。
④ 解决list数据过多,使用分批分页处理生成csv (EXCEL)
抛转引玉,给大家整个简单的分批玩法,生成csv 。
改造点 1 , 整一个分页查询。
老面孔手动分页DTO:
import lombok.Data;/*** @Author: JCccc* @Date: 2022-6-15 16:53* @Description:*/
@Data
public class PageLimitDTO {private Integer pageSize;private Integer currIndex;}
工具类 MyPageCutUtil.java
import lombok.extern.slf4j.Slf4j;import java.util.LinkedList;
import java.util.List;@Slf4j
public class MyPageCutUtil {public static List<PageLimitDTO> getPageLimitGroupList(Integer totalCount, Integer batchSizeLimit) {log.info("这一次处理的总数据条数为 ={} 条, 每一批次处理条数为 ={} 条,现在开始做分批切割处理。",totalCount,batchSizeLimit);int pageNum = totalCount / batchSizeLimit;int surplus = totalCount % batchSizeLimit;if (surplus > 0) {pageNum = pageNum + 1;}List<PageLimitDTO> pageLimitGroupList =new LinkedList<>();for(int i = 0; i < pageNum; i++){Integer currIndex = i * batchSizeLimit;PageLimitDTO pageLimitDTO=new PageLimitDTO();pageLimitDTO.setPageSize(batchSizeLimit);pageLimitDTO.setCurrIndex(currIndex);pageLimitGroupList.add(pageLimitDTO);log.info("分批切割,第={}次,每次={}条,最终会处理到={}条。",pageLimitGroupList.size(),batchSizeLimit,currIndex+batchSizeLimit);}log.info("这一次处理的总数据条数为 ={} 条, 每一批次处理条数为 ={} 条,总共切割分成了 ={} 次,一切准备就绪。",totalCount,batchSizeLimit,pageLimitGroupList.size());return pageLimitGroupList;}}老面孔手动分页统计sql :
mapper 简单打个样
/*** 统计所有符合搜索条件的数据* @param codeList* @return*/
int getCountAllList(@Param("codeList") List<String> codeList);
对应xml 的sql
<select id="getCountAllList" resultType="java.lang.Integer">SELECTCOUNT(*)FROM district_infoWHERE PARENT_CODE IN<foreach collection="codeList" item="code" open="(" separator="," close=")">#{code}</foreach></select>
老面孔手动分页查询sql:
/*** 手动分页查询* @param codeList* @param currIndex* @param pageSize* @return*/
List<District> getPageList(@Param("codeList") List<String> codeList,Integer currIndex,Integer pageSize);
sql:
<select id="getPageList" resultMap="BaseResultMap">SELECT<include refid="Base_Column_List"/>FROM district_info<where><if test="codeList != null and !codeList.isEmpty()">PARENT_CODE IN<foreach collection="codeList" item="code" open="(" separator="," close=")">#{code}</foreach></if></where>LIMIT #{currIndex} , #{pageSize}
</select>

ok接下来继续改造我们的分批查询,处理数据:
@RequestMapping("/createCsvFileTest3")public void createCsvFileTest3() throws IOException {//存放地址&文件名String fileName = "D:\\mycsv\\test3.csv";String tableNames = "地域编码,地域名称,父级编码,地域全称" + MyCsvFileUtil.CSV_TAIL;//创建文件MyCsvFileUtil.writeFile(fileName, tableNames);//获取数据总计数Integer totalCount = districtMapper.getCountAllList(null);//每批同步的数据条数Integer batchSizeLimit = 500;//分批切割处理List<PageLimitDTO> pageLimitGroupList = MyPageCutUtil.getPageLimitGroupList(totalCount, batchSizeLimit);int count = 1;//物理批次查询for (PageLimitDTO pageBatchLimit : pageLimitGroupList) {List<District> pageBatchList = districtMapper.getPageList(null, pageBatchLimit.getCurrIndex(), pageBatchLimit.getPageSize());if (!CollectionUtils.isEmpty(pageBatchList)) {//写入数据String contentBody = buildCsvFileBody(pageBatchList);//调用方法生成MyCsvFileUtil.writeFile(fileName, contentBody);}log.info("第{}批次,District数据处理结束执行", count);count = count + 1;}}代码简析: 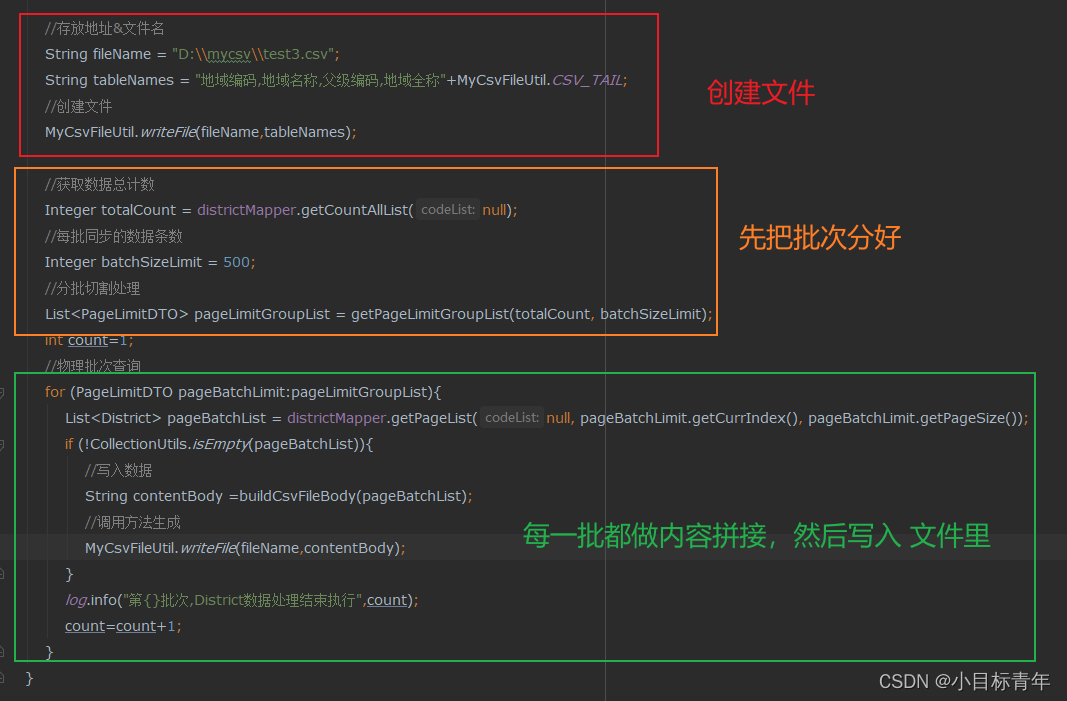
OK,调用一下接口,看看效果:
打开看看数据:
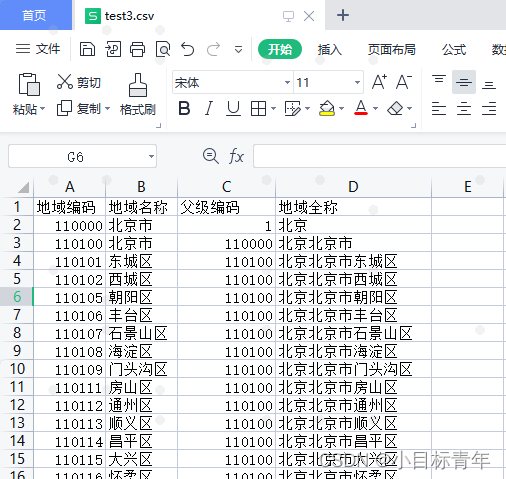
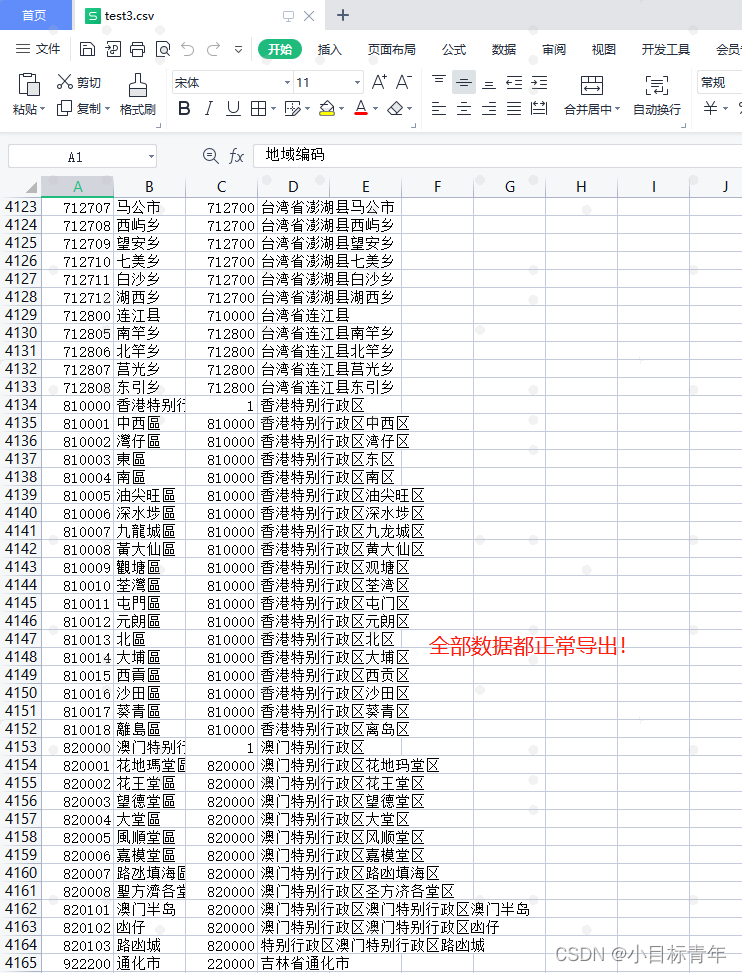
ps:还有没有优化封装余地?
有的,文中讲到了,还可以考虑加上整个大批次的ID,然后考虑并行查询,并行拼接后,再按顺序插入。
有想法的还可以写个注解,标记相关表头别名,是否参与导出,然后再拼接的时候魔改一手,反射自动拿字段属性等等。
好了该篇就到这。