文章目录
- list的介绍
- list和vector的对比
- **list和vector对于排序算法速度的比较**
- **list和vector对于迭代器的比较**
- **list的模拟实现**
- **框架**
- **节点**
- **迭代器**
- **普通迭代器-普通写法**
- **const 迭代器-普通写法**
- **迭代器-高级写法**
- **链表结构**
- **关于节点的析构**
- **关于迭代器没有实现拷贝构造和赋值为什么可以用?**
list的介绍
1、list是可以在常数范围内在任意位置进行插入和删除(相比其他容器如vector、string等等效率更高)
2、list底层是带头双向链表结构,每个元素存储在互不相干的独立节点,节点之间通过指针相互联系
3、与其他容器相比,list存在的最大缺陷就是不能随机访问即不能通过【】访问(list的内存空间的不连续的)
list和vector的对比
vector
| 优点 | 缺点 |
|---|---|
| 下标随机访问 | |
| 尾插尾删效率高 | 前面部分插入删除数据效率低O(N) |
| cpu高速缓存命中高 | 扩容有损耗,还有一定的空间浪费 |
list
| 优点 | 缺点 |
|---|---|
| 按需申请释放空间,无需扩容 | 不支持下标随机访问 |
| 任意位置插入删除O(1) | cpu高速缓存命中低 |
可以看到vector和list是互补配合的!
list和vector对于排序算法速度的比较
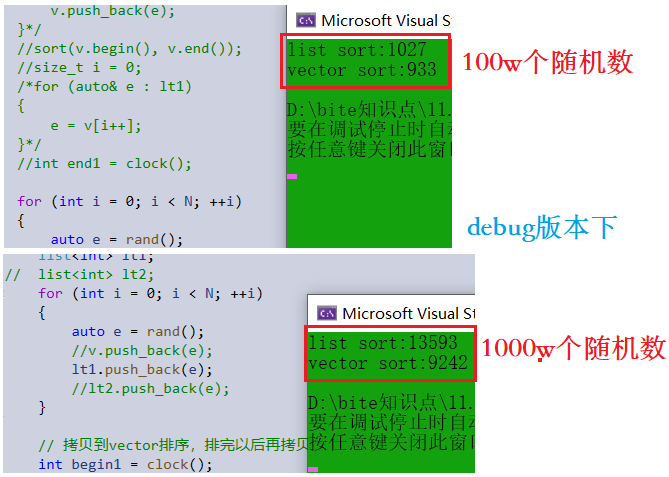
这里我创建了一个list和vector,对两者同时插入100w个和1000w个随机数,插入后记一次时间,然后进行排序,排完序再记一次时间,两次时间相差即排序的时间, 然后对两者时间比较;理论存在实践开始:
//要包含的头文件
#include<iostream>
#include<list>
#include<vector>
#include<time.h>
#include<algorithm>
using namespace std;void test_sort_time()
{srand(time(0));const int N = 1000000;//100w个随机数vector<int> v;v.reserve(N);//扩容list<int> lt1;for (int i = 0; i < N; ++i){auto e = rand();lt1.push_back(e);}int begin1 = clock();lt1.sort();int end1 = clock();//记的list排序时间for (int i = 0; i < N; ++i){auto e = rand();v.push_back(e);}int begin2 = clock();
sort(v.begin(), v.end());int end2 = clock();//记的vector排序时间printf("list sort:%d\n", end1 - begin1);//打印list排序时间
printf("vector sort:%d\n", end2 - begin2);//打印vector排序时间debug版本下,得出结论vector排序比list块,但两者差距不是很明显【可能是我这破电脑的缘故(doge】
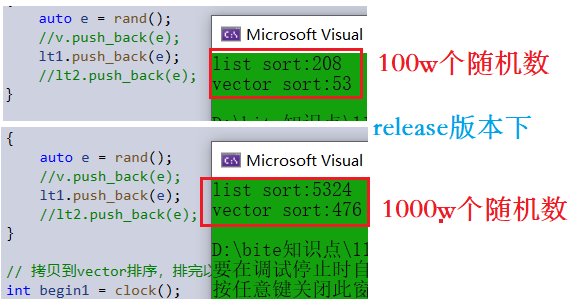
release版本下,可以看到两者差距还是非常大的,甚至把list里面的数据导入vector里排序完再导回list的时间都比本身list排序的时间短(各位彦祖们可以去尝试噢)
list和vector对于迭代器的比较
在STL中,迭代器一般有两个特点:1、内嵌类型;2、行为像指针一样
内嵌类型:1、内部类-在类里面定义的类;2、typedef出来的(typedef内置类型)
1、迭代器类型: vector的迭代器本质上是内置类型 ,但实现方式不一定是(可以用内置类型实现)—在g++底层是用内置类型实现;vs下不是内置类型实现-迭代器通过封装已经不是原生指针了。 list的迭代器底层实现是内部类
2、迭代器解引用: vector的迭代器解引用是对指针的解引用 (可以取到数据);而 list的迭代器解引用是对节点的指针解引用但这种方式取不到数据所以要用函数调用 (用的operator()函数重载)*
3、对于迭代器的判断: vector迭代器可以用>或<进行判断 —vector内存空间是连续的,连续的地址可以大小比较; list迭代器不能用>或<进行判断,只能用!=判断 —list内存空间不是连续的且是随机的
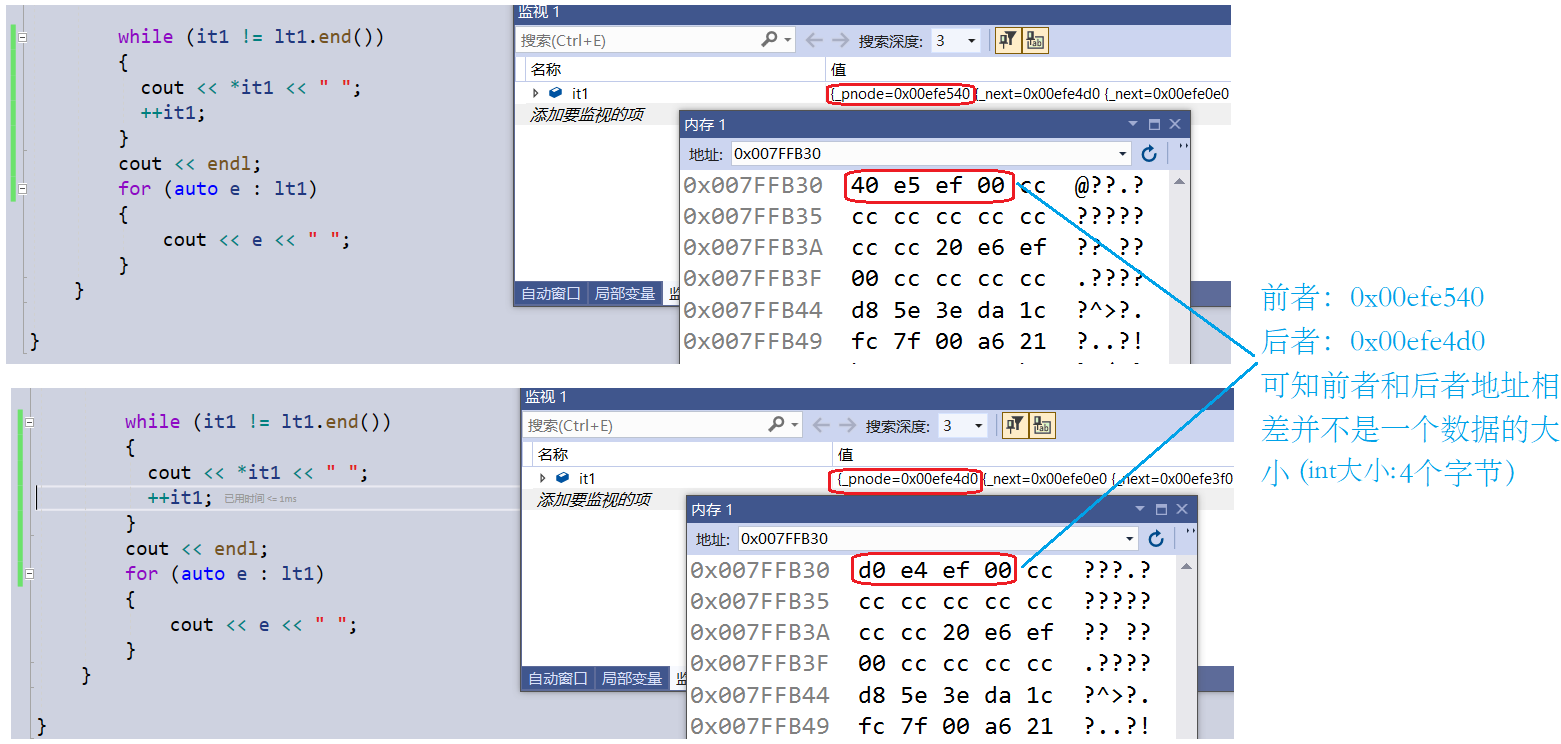
这里的实验直接或间接证明了第1点和第3点:我创建了一个vector和list,同样插入数据1234,通过对迭代器的++一个遍历打印;通过内存观察看出这里的两者迭代器的不同点
这里是vector迭代器++,++后前后地址相差为一个数据类型大小,说明vector迭代器本质是原生指针
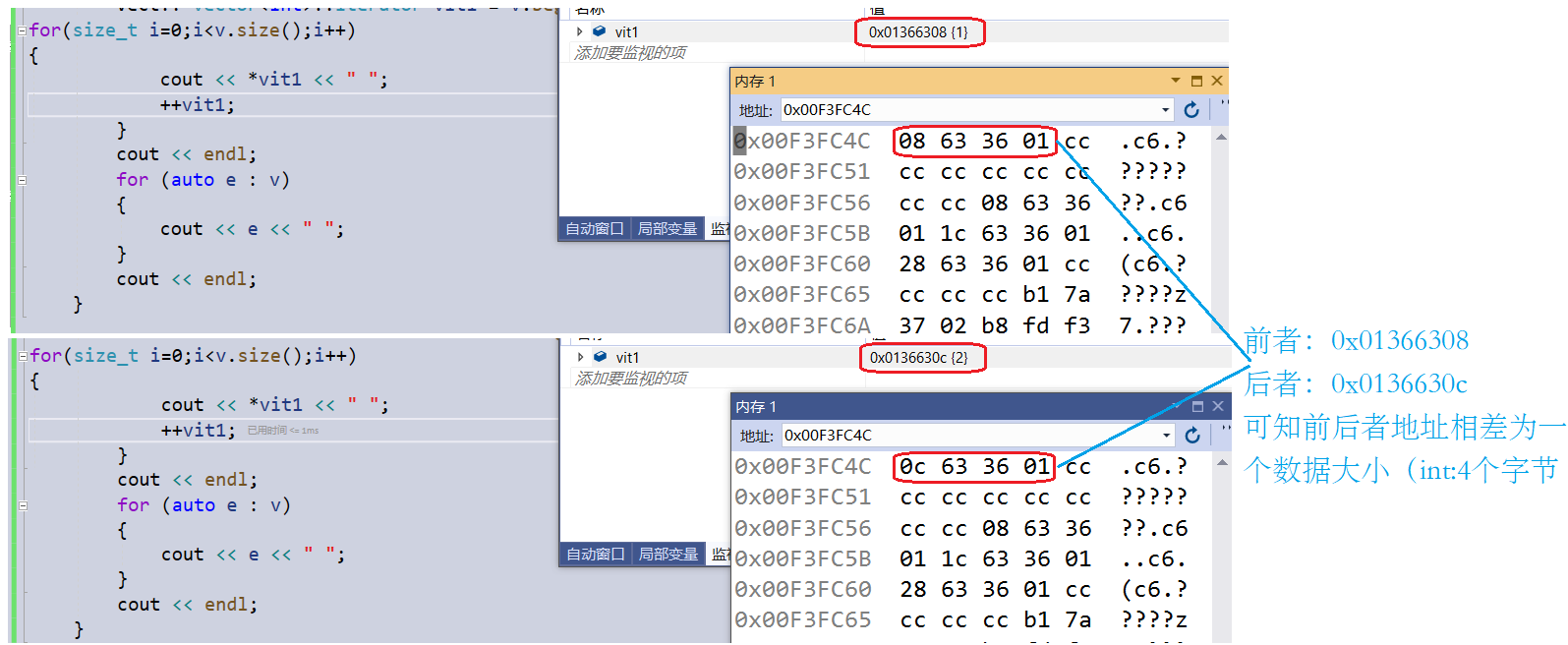
这里是list迭代器++,加加后前后地址相差并不是一个数据类型大小,说明vector迭代器本质不是原生指针,而且通过调试可知这是函数调用
迭代器的优势: 1、封装底层实现,不暴露底层实现细节 2、提供了统一的访问方式,降低了使用成本
list的模拟实现
框架
我们要用命名空间围起来
namespace listrealize()
{ //节点template<typename T>struct list_node(){list_node<T>* _next;list_node<T>* _prev;T _data;list_node(const T& val)//节点初始化:_next(nullptr),_prev(nullptr),_data(val){}};//迭代器template<typedef T>struct list_iterator{............ };//链表结构template<typename T>class list{typedef list_node<T> node;public:typedef list_iterator<T> iterator;............
};}
节点
template<typename T>struct list_node//节点初始化{list_node <T>* _next;list_node <T>* _prev;T _data;list_node(const T& val):_next(nullptr),_prev(nullptr),_data(val){}};
迭代器
由于list迭代器不是像vector那样的原生指针,所以得用类中类来写迭代器,而不是直接typedef出来,而且普通迭代器和const迭代器都要写
普通迭代器-普通写法
template<typename T>struct list_iterator{typedef list_node<T> node;node* _pnode;//成员变量---类指针list_iterator(node* p)//构造函数-迭代器:_pnode(p){}T& operator*()//引用返回{return _pnode->_data;//返回数据}list_iterator& operator++()//返回下一个节点{_pnode = _pnode->_next;return *this;}list_iterator& operator--()//返回上一个节点{_pnode = _pnode->_prev;return *this;}bool operator!=(const list_iterator& it ){return _pnode != it._pnode;}};
const 迭代器-普通写法
template<typename T>struct list_const_iterator{typedef list_node<T> node;node* _pnode;//成员变量---类指针list_const_iterator(node* p)//构造函数-迭代器:_pnode(p){}const T& operator*(){return _pnode->_data;}list_const_iterator<T>& operator++(){_pnode = _pnode->_next;return *this;}list_const_iterator<T>& operator--(){_pnode = _pnode->_prev;return *this;}bool operator!=(const list_const_iterator<T>& it){return _pnode != it._pnode;}};
迭代器-高级写法
如果我们按照上面普通写法实现迭代器的话,相当于写了两份迭代器(普通迭代器和const迭代器),而大佬是不允许发生这种情况。大佬选择给类模板和函数模板增加参数关键字来减少代码膨胀。为什么不能直接在迭代器前加const以构造const迭代器的原因是迭代器指向的内容可读可写,而const迭代器指向的内容只能读不能写。在迭代器前面加const是指迭代器这个像指针的的东西不能改变!(指针指定的方向不能改变)

而list这里的迭代器不是原生指针,迭代器和const迭代器其本质区别问题所在就是对数据的输出即解引用,所以我们通过给类模板和函数模板加参数就能实现。

template<typename T,typename ref>struct list_iterator{typedef list_node<T> node;typedef list_iterator<T, ref> self;node* _pnode;//成员变量---类指针list_iterator(node* p)//构造函数-迭代器:_pnode(p){}ref& operator*(){return _pnode->_data;}self& operator++()//前置++{_pnode = _pnode->_next;return *this;}self operator++(int)//后置++{self tmp(*this);_pnode = _pnode->_next;return tmp;//返回迭代器-不需要用引用}self& operator--()//前置--{_pnode = _pnode->_prev;return *this;}self operator--(int)//后置--{self tmp(*this);//用地址构造迭代器_pnode = _pnode->_prev;return tmp;}bool operator!=(const self& it ){return _pnode != it._pnode;}bool operator==(const self& it){return _pnode == it._pnode;}};
链表结构
template <typename T>class list//链表结构{typedef list_node<T> node;public:typedef list_iterator<T,T&> iterator;typedef list_iterator<T,const T&> const_iterator;void empty_initialize()//节点初始化{_head = new node(T());_head->_next = _head;_head->_prev = _head;_size=0;}list()//构造函数{empty_initialize();}template <class InputIterator>list(InputIterator first, InputIterator last)//迭代器区间构造{empty_initialize();while (first != last){push_back(*first);++first;}}//lt1(lt)list( const list<T>& lt)//旧时代写法{//自己初始化一份empty_initialize();for (const auto& e : lt)//这里要用引用{push_back(e);}}list(const list<T>& lt)//拷贝构造-现代写法{//自己初始化一份empty_initialize();list<T> tmp(lt.begin(), lt.end());swap(tmp);}iterator begin(){return iterator(_head->_next);}iterator end(){return iterator(_head);}const_iterator begin()const{return const_iterator(_head->_next);}const_iterator end()const{return const_iterator(_head);}size_t size() const{return _size;}bool empty()const{return _size == 0;}~list()//析构{clear();delete[] _head;_head = nullptr;}void clear(){iterator pos = begin();while (pos != end()){pos=erase(pos);}}void swap( list<T>& lt){std::swap(_head, lt._head);std::swap(_size, lt._size);}void push_back(const T& val)//传的是数据-T&{insert(end(), val);/* node* cur = new node(val);node* tail = _head->_prev;tail->_next = cur;cur->_prev = tail;cur->_next = _head;_head->_prev = cur;*/}void push_front(const T& val){insert(begin(), val);}iterator insert(iterator pos, const T& val)//在pos节点前面插入{node* newnode = new node(val);node* cur = pos._pnode;node* prev = cur->_prev;//链接newnode->_next = cur;cur->_prev = newnode;newnode->_prev = prev;prev->_next = newnode;++_size;return iterator(newnode);}iterator erase(iterator pos)//删除节点{assert(end());node* cur = pos._pnode;node* next = cur->_next;node* prev = cur->_prev;//链接next->_prev = prev;prev->_next = next;delete[] cur;--_size;return iterator(next);}void pop_back(){assert(++end());erase(_head->_next);}void pop_front(){assert(--end());erase(_head->_prev);}list<T>& operator=( const list<T><)//这里加const就报错{if (this != <){clear();for (const auto& e : lt){push_back(e);}}return *this;}private:node* _head;};
写到这,我们创建一个POS,类似坐标的类,成员变量有_row和 _col,那我们用POS来初始化list,该怎么访问到POS 里的 _row 和 _col呢?
struct POS{int _row;int _col;POS(int row = 0, int col = 0):_row(row),_col(col){}};
我们知道,在类外面访问类的公有成员可以用三种访问方式:访问限定符:: 、.、->
所以我们可以用->指针的方式访问,那么还需要在写一个->的迭代器运算符重载
ptr operator->(){return &_pnode->_data;//返回节点数据的地址,用指针接收}

加上之后就能访问了
下面是完善后的代码
//节点的实现template<typename T>struct list_node//节点初始化{list_node <T>* _next;list_node <T>* _prev;T _data;list_node(const T& val):_next(nullptr),_prev(nullptr),_data(val){}};//迭代器的实现template<typename T,typename ref,typename ptr>struct list_iterator{typedef list_node<T> node;typedef list_iterator<T, ref,ptr> self;node* _pnode;//成员变量---类指针list_iterator(node* p)//构造函数-迭代器:_pnode(p){}ptr operator->(){return &_pnode->_data;//返回节点数据的地址,用指针接收}ref& operator*(){return _pnode->_data;}self& operator++()//前置++{_pnode = _pnode->_next;return *this;}self operator++(int)//后置++{self tmp(*this);_pnode = _pnode->_next;return tmp;//返回迭代器-不需要用引用}self& operator--()//前置--{_pnode = _pnode->_prev;return *this;}self operator--(int)//后置--{self tmp(*this);//用地址构造迭代器_pnode = _pnode->_prev;return tmp;}bool operator!=(const self& it ){return _pnode != it._pnode;}bool operator==(const self& it){return _pnode == it._pnode;}};
//链表的实现
template <typename T>class list//链表结构{typedef list_node<T> node;public:typedef list_iterator<T,T&,T*> iterator;typedef list_iterator<T,const T&,const T*> const_iterator;void empty_initialize(){_head = new node(T());_head->_next = _head;_head->_prev = _head;_size = 0;}list()//构造函数{empty_initialize();}template <class InputIterator>list(InputIterator first, InputIterator last)//迭代器区间构造{empty_initialize();while (first != last){push_back(*first);++first;}}list(const list<T>& lt)//拷贝构造-现代写法{//自己初始化一份empty_initialize();list<T> tmp(lt.begin(), lt.end());swap(tmp);}iterator begin(){return iterator(_head->_next);}iterator end(){return iterator(_head);}const_iterator begin()const{return const_iterator(_head->_next);}const_iterator end()const{return const_iterator(_head);}size_t size() const{return _size;}bool empty()const{return _size == 0;}~list()//析构{clear();delete[] _head;_head = nullptr;_size = 0;}void clear(){iterator pos = begin();while (pos != end()){pos=erase(pos);}}void swap( list<T>& lt){std::swap(_head, lt._head);std::swap(_size, lt._size);}void push_back(const T& val)//传的是数据-T&{insert(end(), val);}void push_front(const T& val){insert(begin(), val);}iterator insert(iterator pos, const T& val)//在pos节点前面插入{node* newnode = new node(val);node* cur = pos._pnode;node* prev = cur->_prev;//链接newnode->_next = cur;cur->_prev = newnode;newnode->_prev = prev;prev->_next = newnode;++_size;return iterator(newnode);}iterator erase(iterator pos){assert(end());node* cur = pos._pnode;node* next = cur->_next;node* prev = cur->_prev;//链接next->_prev = prev;prev->_next = next;delete[] cur;--_size;return iterator(next);}void pop_back(){assert(++end());erase(_head->_next);}void pop_front(){assert(--end());erase(_head->_prev);}list<T>& operator=(list<T> lt){swap(lt);return *this;}private:node* _head;size_t _size;//复用-提高代码的可维护性};
关于节点的析构
我们知道,c++类的自定义类型会调用自定义类型的析构函数,没有析构函数则调用默认析构,而写了析构函数的类一般都要写拷贝构造和赋值运算符重载,那么编译器敢析构节点吗?又或者说编译器会析构头节点吗?
首先答案很明确是不会的!
1、在程序结束时会调用自定义类型的析构函数,而内置类型则不会-指针也不会,在这里若把这个头节点析构掉了则找不到后面的节点了
2、迭代器也不会把指针析构掉,这个指针是链表的,迭代器只是借用它指向数据;
关于迭代器没有实现拷贝构造和赋值为什么可以用?
首先迭代器没有实现析构函数,那么就不是必须实现拷贝构造和赋值运算符重载;其次,迭代器拷贝构造和赋值运算符重载都属于浅拷贝地址—指针指向同一块空间,因为迭代器不会把指向的数据析构,所以浅拷贝就够用!
好啦,关于list的实现和相关问题就分析到这里,制作不易,给个点赞支持支持吧~~~




![[附源码]计算机毕业设计的项目管理系统Springboot程序](https://img-blog.csdnimg.cn/1625b3d2f10e48df9a49f3079f893449.png)