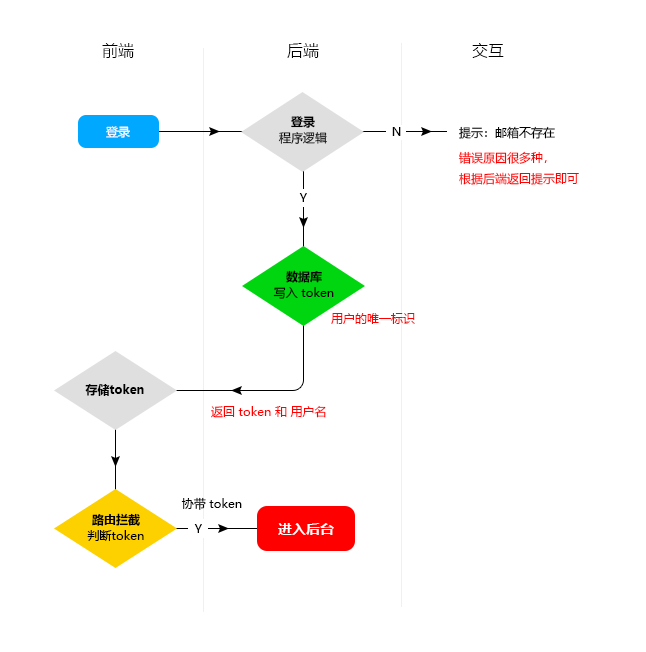
Kaggle实战入门:泰坦尼克号生生还预测
- 1. 加载数据
- 2. 特征工程
- 3. 模型训练
- 4. 模型部署
泰坦尼克号(Titanic),又称铁达尼号,是当时世界上体积最庞大、内部设施最豪华的客运轮船,有“永不沉没”的美誉,被称为“世界工业史上的奇迹”。1912年4月10日,她在从英国南安普敦出发,驶往美国纽约的首次处女航行中,不幸与一座冰山相撞,1912年4月15日凌晨2时20分左右,船体断裂成两截,永久沉入大西洋底3700米处,2224名船员及乘客中,逾1500人丧生。
而以此事件为背景的《泰坦尼克号》则是成为了电影史上的传奇,该片由詹姆斯•卡梅隆执导,莱昂纳多•迪卡普里奥、凯特•温斯莱特领衔主演。在中国大陆上映的时间是1998年4月,虽然时隔25年,泰坦尼克号也已沉没111年,但每当影片主题曲my heart will go on中悠扬的苏格兰风笛声响起时,每个人都会再次被带回那艘奥林匹克级的豪华邮轮。
机器学习领域,著名的数据科学竞赛平台kaggle的入门经典也是以泰坦尼克号事件为背景。该问题通过训练数据(train.csv)给出891名乘客的基本信息以及生还情况,通过训练数据生成合适的模型,并根据另外418名乘客的基本信息(test.csv)预测其生还情况,并将生还情况以要求的格式(gender_submission.csv)提交,kaggle会根据你的提交情况给出评分与排名。
1. 加载数据
import pandas as pd
file = r'datasets/train.csv'
data = pd.read_csv(file)
加载数据完成后,可使用内置方法对数据进行探查,初步认识数据。
data.head(5) #查看前5行数据:data.iloc[:5] 或者 data.loc[:5]
输出

data.info() #查看整体信息
输出
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
可以看出,数据共有11个字段,其中Age有714个非空值,而Cabin仅有204个非空值。每个字段含义如下:
| 字段名 | 字段含义 |
|---|---|
| PassengerId | 乘客ID |
| Pclass | 客舱等级 |
| Name | 乘客姓名 |
| Sex | 性别 |
| Age | 年龄 |
| SibSp | 兄弟姐妹、配偶 |
| Parch | 父母与子女 |
| Ticket | 船票编号 |
| Fare | 票价 |
| Cabin | 客舱号 |
| Embarked | 登船港口 |
data.Pclass.unique() #查看字段的取值情况
输出
array([3, 1, 2])
data.Pclass.value_counts() #查看字段取值的统计值
输出
3 491
1 216
2 184
Name: Pclass, dtype: int64
2. 特征工程
特征工程(Feature Engineering)极其重要,特征的选择与处理直接影响到模型效果。实际中,特征工程很多时候是依赖业务经验的。
通过数据探查,可以发现该数据包含以下几类属性
- 标称属性(Nominal attribute):Sex(性别)、Embarked(登船港口)
- 标称属性(Ordinal attribute):Pclass(客舱等级)
- 数值属性(Numeric attribute):Age(年龄)、SibSp(兄弟姐妹、配偶)、Parch(父母与子女)、Fare(票价)
- 其他:Name(乘客姓名)、Ticket(船票编号)、Cabin(客舱号)
(1)统计分析各属性与生还结果的相关性
针对Sex、Pclass、Embarkd与Survived的关系,可使用crosstab函数(或groupby函数)分别进行聚合统计,计算相应的百分比以实现归一化,并做图。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] #Mac系统设置中文显示
plt.rcParams['axes.unicode_minus'] = Falsefig = plt.figure()
fig.set(alpha=0.65) # 设置图像透明度
ax1=fig.add_subplot(131)
ax2=fig.add_subplot(132)
ax3=fig.add_subplot(133)cou_Sex = pd.crosstab(data.Sex,data.Survived)
#或者用counts_Sex = data.groupby(['Sex','Survived']).size().unstack
cou_Sex.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
cou_Sex.rename({'female':'F','male':'M'},inplace=True)
pct_Sex = cou_Sex.div(cou_Sex.sum(1).astype(float),axis=0) #归一化
pct_Sex.plot(kind='bar',stacked=True,title=u'不同性别的生还情况',ax=ax1)cou_Pclass = pd.crosstab(data.Pclass,data.Survived)
cou_Pclass.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Pclass = cou_Pclass.div(cou_Pclass.sum(1).astype(float),axis=0)
pct_Pclass.plot(kind='bar',stacked=True,title=u'不同等级的生还情况',ax=ax2,sharey=ax1)cou_Embarked = pd.crosstab(data.Embarked,data.Survived)
cou_Embarked.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Embarked = cou_Embarked.div(cou_Embarked.sum(1).astype(float),axis=0)
pct_Embarked.plot(kind='bar',stacked=True,title=u'不同登录点生还情况',ax=ax3,sharey=ax1)
输出

可直观的看出生还情况受性别(女性乘客生还概率较高)、客舱等级(一等舱乘客生还概率较高)、登船港口(C港口登船乘客生还概率较高)的影响。
针对数值属性的Age、Fare,可使用cut函数将其离散化后,再进行统计分析。
fig = plt.figure()
fig.set(alpha=0.65) # 设置图像透明度
ax1=fig.add_subplot(121)
ax2=fig.add_subplot(122)bins=[0,14,30,45,60,80]
cats=pd.cut(data.Age.as_matrix(),bins) #Age离散化
data.Age=cats.codescou_Age = pd.crosstab(data.Age,data.Survived)
cou_Age.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Age = cou_Age.div(cou_Age.sum(1).astype(float),axis=0)
pct_Age.plot(kind='bar',stacked=True,title=u'不同年龄的生还情况',ax=ax1)bins=[0,15,30,45,60,300]
cats=pd.cut(data.Fare.as_matrix(),bins) #Fare离散化
data.Fare=cats.codescou_Fare = pd.crosstab(data.Fare,data.Survived)
cou_Fare.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
pct_Fare = cou_Fare.div(cou_Fare.sum(1).astype(float),axis=0)
pct_Fare.plot(kind='bar',stacked=True,title=u'不同票价的生还情况',ax=ax2,sharey=ax1)

可直观的看出年龄越小生还概率越高、票价越高生活概率越高(-1表示缺失值)。
(2)计算相关系数分析各属性与生还结果的相关性
使用corr函数计算属性aaa和bbb之间的相关性r(a,b)r(a,b)r(a,b),corr函数默认使用Person系数,取值在[−1,1][-1,1][−1,1]之间。
- r(a,b)>0r(a,b)>0r(a,b)>0表示属性aaa和bbb正相关
- r(a,b)<0r(a,b)<0r(a,b)<0表示属性aaa和bbb负相关
- r(a,b)=0r(a,b)=0r(a,b)=0表示属性aaa和bbb相互独立。
def dataProcess(data):mapTrans={'female':0,'male':1,'S':0,'C':1,'Q':2} #属性值转换data.Sex=data.Sex.map(mapTrans)data.Embarked=data.Embarked.map(mapTrans)data.Embarked=data.Embarked.fillna(data.Embarked.mode()[0]) #使用众数填充data.Age=data.Age.fillna(data.Age.mean()) #均值填充缺失年龄data.Fare=data.Fare.fillna(data.Fare.mean()) #均值填充缺失Farereturn datadata = data = pd.read_csv(file)#重新载入数据
data = dataProcess(data)
data.iloc[:,1:].corr()['Survived']
输出
Survived 1.000000
Pclass -0.338481
Sex -0.543351
Age -0.069809
SibSp -0.035322
Parch 0.081629
Fare 0.257307
Embarked 0.106811
Name: Survived, dtype: float64
可以看出Survived与Pclass、Sex、Fare、Embarked相关性较大。
使用seaborn库的热力图可视化展示:
import seaborn as sns #导入seaborn绘图库
sns.set(style='white', context='notebook', palette='deep')
sns.heatmap(data.iloc[:,1:].corr(),annot=True, fmt = ".2f", cmap = "coolwarm")
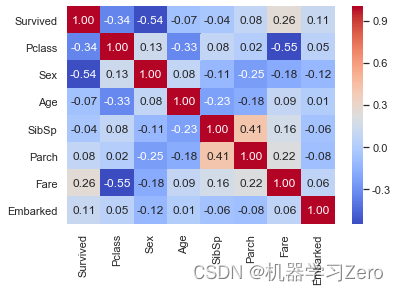
通过上述分析,选择[‘Pclass’, ‘Sex’, ‘Age’, ‘Fare’, ‘Embarked’]作为特征,其中使用map方法将Sex、Embarked映射为数值,并用fillna方法填充Embark、Age、Fare的缺失值。
3. 模型训练
构建决策树模型,并使用fit方法完成模型的训练。
feature =['Pclass','Sex','Age','Fare','Embarked']
X = data[feature] #选择特征
y = data.Survived #标签from sklearn.tree import DecisionTreeClassifier as DT
clf = DT() #建立模型
clf.fit(X,y) #训练模型
可使用准确率(score方法)和混淆矩阵(metrics.confusion_matrix方法)对模型进行评估。
print('%.3f' %(clf.score(X,y))) #准确率
输出
0.980
from sklearn import metrics
metrics.confusion_matrix(y, clf.predict(X)) #混淆矩阵
输出
array([[546, 3],
[ 15, 327]])
4. 模型部署
加载test.csv文件的数据,进行处理,并使用predict方法预测,将生成的结果文件在Kaggle页面点击Submit Predictions进行提交,Kaggle会给出准确率和排名。
data_sub = pd.read_csv(r'datasets/test.csv') #加载测试数据
data_sub = dataProcess(data_sub) #处理测试数据
X_sub = data_sub[feature] #提取测试数据特征
y_sub = clf.predict(X_sub) #使用模型预测数据标签
result = pd.DataFrame({'PassengerId':data_sub['PassengerId'].as_matrix(), 'Survived':y_sub}) #形成要求格式
result.to_csv(r'D:\[DataSet]\1_Titanic\submission.csv', index=False) #输出至文件