前言
大家早好、午好、晚好吖~

相信不少小伙伴都知道这个网站,特别是中二期得时候
博主我就看过,哈哈哈哈
今天我的得目的就是这个,咋来采集一下它
目录标题
- 前言
- 代码展示
- 效果展示
- 尾语 💝
代码展示
# 导入数据请求模块 --> 第三方模块 需要 pip install requests
import requests
# 导入数据解析模块 --> 第三方模块 需要 pip install parsel
import parsel
# 导入正则模块 --> 内置模块 不需要安装
import re
from show import get_content
请求目录页url <复制>

本文只是大致展示,完整代码和视频教程点击下方蓝字
点击 蓝色字体 自取,我都放在这里了。
模拟浏览器对于 本子 目录页面url地址 发送请求
模拟浏览器 headers 请求头 字典数据类型 <复制>
headers = {# Cookie 用户信息, 检测是否有登陆账号 <登陆与否都是有cookie>'Cookie': '',# User-Agent 用户代理 表示浏览器基本身份信息'User-Agent': ''
}
发送请求
requests模块 get模块里面方法
response = requests.get(url=url, headers=headers)
print(response)
<Response [200]> 表示请求成功
“”"
2. 获取数据: 获取服务器返回响应数据
开发者工具 --> response
response.text获取响应文本数据 网页源代码
3. 解析数据: 提取我们想要数据内容
提取本子名字 / 本子章节标题 / 本子章节url
解析数据方法:
-
xpath
-
css
-
re: 对于字符串数据直接提取的话
-
css选择器: 根据标签属性提取数据内容
转换数据类型
获取下来 response.text html字符串数据类型
get() 获取一个 返回字符串
getall() 获取多个 返回列表
“”"
转换数据类型, 可解析对象 <Selector xpath=None data='<html xmlns="http://www.w3.org/1999/x...'>
selector = parsel.Selector(response.text)
提取本子名字
name = selector.css('#novelName::text').get()
提取本子章节名字
titles = selector.css('.DivTd a::text').getall()
提取本子章节url
href = selector.css('.DivTd a::attr(href)').getall()
for循环遍历, 把列表里面元素一个一个提取出来
for link, title in list(zip(href, titles))[58:]:# https://b.faloo.com/631781_1.htmllink_url = 'https:' + linkprint(link_url, title)
“”"
4 / 5 发送请求, 获取数据
“”"
html_data = requests.get(url=link_url, headers=headers).text
通过css提取数据 转换数据 可解析对象
selector_1 = parsel.Selector(html_data)
提取本子内容
content_list = selector_1.css('.noveContent p::text').getall()# join 是干嘛的?content = '\n'.join(content_list)
len() 统计元素个数 如果是付费章节, 里面数据只有
if len(content) < 30:
“”"
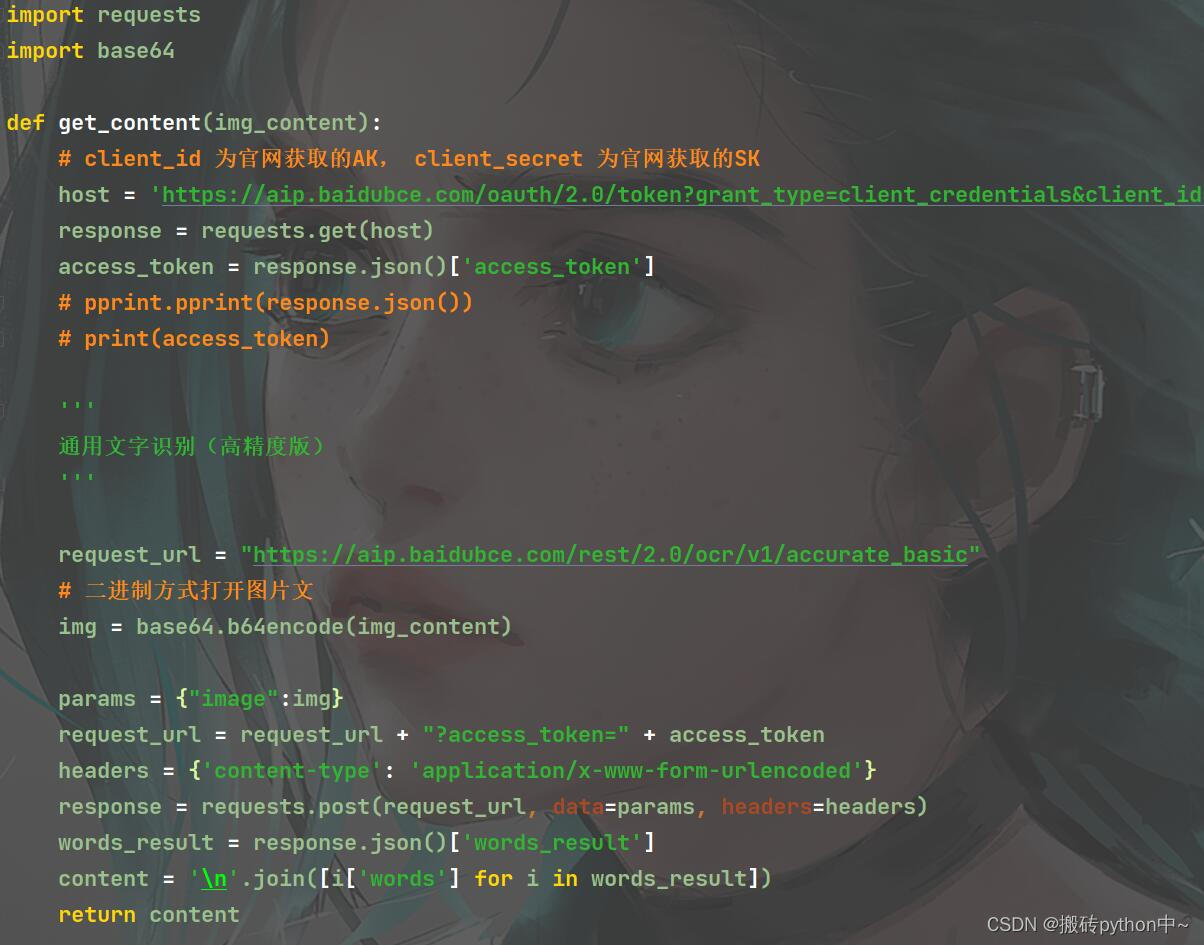
关于某本子网站VIP章节内容 —> 图片形式
-
从章节url里面获取图片请求参数
-
保存图片二进制数据
-
通过百度云API接口 做一个文字识别, 读取图片的文字内容
-
保存数据
re.findall(‘匹配什么数据’, ‘从什么地方匹配’) 找到所有我们想要数据内容
从什么地方 去匹配什么数据
从 html_data 里面 去匹配 image_do3\((.*?)\) 其中 (.*?) 表示我们想要数据内容
- \ 转义字符, 把含有特殊含义字符, 转成除了本身字符以外不含有任何其他的意思
() 在正则里面表示精确匹配
- 批量替换
-
选中替换内容
ctrl + R -
勾选上
.*正则 -
输入正则命令匹配数据替换
-
(.*?): (.*)
'$1': '$2',
“”"
通过正则匹配请求参数
info = re.findall('image_do3\((.*?)\)', html_data)[0].split(',')

本文只是大致展示,完整代码和视频教程点击下方蓝字
点击 蓝色字体 自取,我都放在这里了。
print(info)data = {'num': '0','o': '3','id': '631781','n': info[3],'ct': '1','en': info[4],'t': '0','font_size': '16','font_color': '666666','FontFamilyType': '1','backgroundtype': '0','u': '15576696742','time': '','k': info[6].replace("'", ''),}print(info[6].replace("'", ''))print(info[6].replace('"', ''))
发送请求获取图片二进制数据
img_content = requests.get(url=vip_url, params=data, headers=headers).contentcontent = get_content(img_content)
7. 保存本子内容
with open(name + '.txt', mode='a', encoding='utf-8') as f:"""第一章 章节名小说内容第二章 章节名小说内容"""# 写入章节名f.write(title)# 回车 换一行f.write('\n')# 写入小说内容f.write(content)# 回车 换一行f.write('\n')print(content)
效果展示

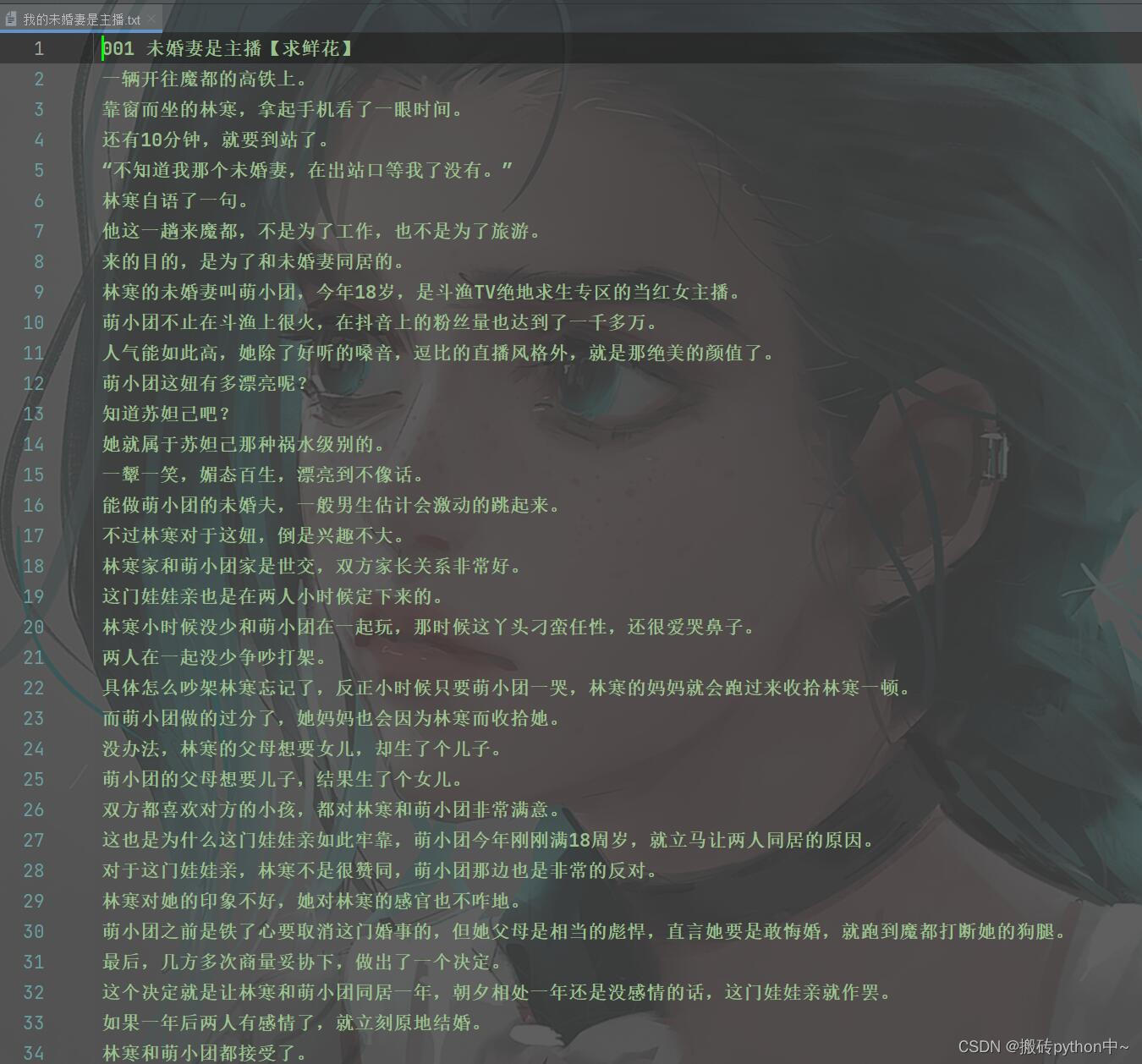
文章看不懂,我专门录了对应的视频讲解,本文只是大致展示,完整代码和视频教程点击下方蓝字
点击 蓝色字体 自取,我都放在这里了。
宁外给大家推荐一个好的教程:
【48小时搞定全套教程!你和大佬只有一步之遥【python教程】
尾语 💝
好了,我的这篇文章写到这里就结束啦!
有更多建议或问题可以评论区或私信我哦!一起加油努力叭(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!