点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨sixgod
来源丨 计算机视觉life
有什么用?
深度图在计算机视觉中有非常广泛的应用,比如前背景分割(用于背景虚化、美颜、重对焦等)、三维重建(用于机器人导航、3D打印、视效娱乐等)。
但是很多时候由于硬件的限制,我们不能通过深度相机获得深度图。只能利用单目相机通过相关算法来间接计算深度图。比较有名的方法就是运动恢复结构(Structure from Motion),也就是说,我们需要移动(通常需要较大的移动)单目相机从而获得不同视角的多张图片才能间接得到深度图。
从微小运动中获取深度图(depth from small motion)是其中一个比较巧妙的、用单目相机间接获得深度图的方法。该方法利用非常微小的运动来计算深度图,这个“非常微小的运动”的目的是在用户察觉不到的时间(比如手机用户寻找最佳拍摄位置时的微小移动,或者用户拿着相机按快门前的预览时间,或者类似live photo等)内得到深度图。如果该方法可以获得较高质量的深度图,就可以一定程度(静态场景下)上替代基于RGB双目立体视觉的深度相机(如手机双摄,手机双摄介绍见《为什么会出现双摄像头手机?》系列文章)的功能。
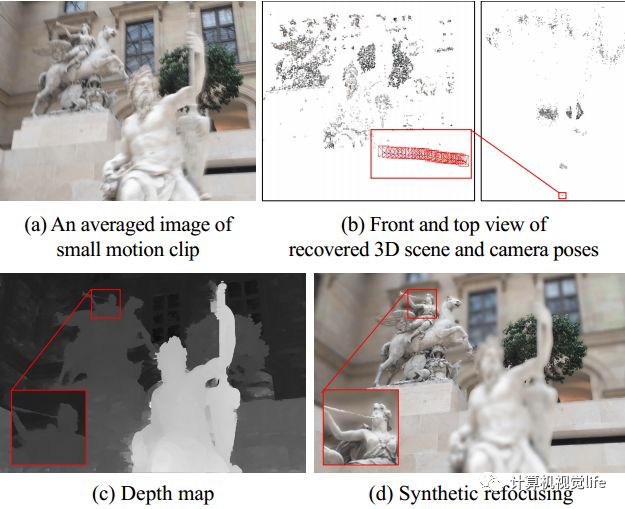
下面来介绍该技术的一个应用。如下图所示,(a) 是输入的一个微运动视频中所有帧的平均叠加图,可以看到运动真的是非常微小的。(c) 是算法计算的深度图,从放大的细节来看,边缘还是很锐利的,(d) 是利用得到的深度图进行重对焦的效果。我们看到对焦主体比较清晰,而位于主体前后景深的物体都已经虚化。
什么原理?
本文的亮点之一就是可以对未标定的相机进行深度图和内外参数同时估计。大致流程如下:
1、以第1帧作为参考帧,检测当前帧和参考帧的Harris角点,用KLT法进行特征点匹配。
2、先假设初始的相机内参和畸变参数,利用光束平差法最小化重投影误差,迭代得到相机的内外参数、特征点对应的三维空间点。其原理示意图如下所示。Uij是第i张图像相对于图像中心的第j个特征点的畸变坐标,红色点是其去畸变后的坐标。蓝色点是重投影的坐标。目标就是最小化第i帧中红色点和蓝色点的位置误差。
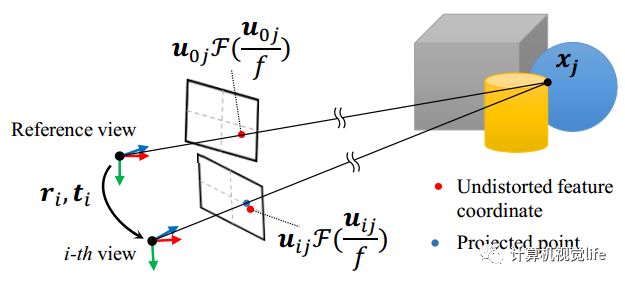
3、根据得到的内外参数用平面扫描法进行稠密立体匹配,并采用赢家通吃的策略得到粗糙的深度图。微小运动有如下优势:由于时间短,移动小,视场角变化小,可以近似认为所有帧在该时间段内的灰度值保持不变。这个假设对于可靠的稠密像素匹配很重要。
4、将彩色图作为引导图,对深度图进行精细化。获得深度图的过程如下:
(a) 用赢家通吃的策略得到一个粗糙的深度图;(b) 去除不可靠的深度值;(c) 深度图精细化后的结果;(d) 参考图像。

该算法的伪代码流程图如下所示:

效果怎么样?
该算法测试效果如下图所示。下图左侧是用iPhone 6拍摄的1s时间的微小运动连续图像的平均图,从中可以看出运动非常小。右侧是算法输出的对应深度图。

该算法和其他算法在重对焦效果上的对比如下图所示。可以看到该算法能够在背景虚化的同时保持相对锐利的边缘。

尽管该算法设计的初衷就是用于微小运动的情况,但是如果运动特别微小,估计的相机位姿就会非常不稳定。另外如果图像边缘缺乏有效的特征点,会导致径向畸变参数的估计变的不准确。上述情况会导致深度图出现较大的误差。
该算法只适合于静态场景,如果有快速移动物体,该算法会失败。另外要注意的是,该算法估计的深度图是相对深度。
运行时间:
该算法是在个人台式机上进行测试。电脑配置:Intel i7-4970K 4.0Ghz CPU,16GB RAM。对于一个分辨率为1280x720的30帧的微小运动视频,该算法(未优化)完成特征提取、跟踪、光束平差需要1分钟。稠密立体匹配阶段耗时10分钟。
有什么参考资料?
本文算法对应的文章:
Ha H, Im S, Park J, et al. High-Quality Depth from Uncalibrated Small Motion Clip[C]// Computer Vision and Pattern Recognition. IEEE, 2016:5413-5421.
源码:
https://github.com/hyowonha/DfUSMC
上述论文的优化及加速版:
Monocular Depth from Small Motion Video Accelerated,2017 International Conference on 3D Vision
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近5000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~