数据压缩
浏览器在发送请求时都会带着 Accept-Encoding 头字段,里面是浏览器支持的压缩格式列表,例如 gzip、deflate、br 等,这样服务器就可以从中选择一种压缩算法,放进 Content-Encoding 响应头里,再把原数据压缩后发给浏览器。
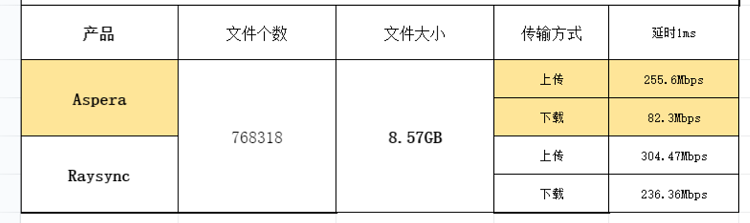
如果压缩率有 50%,那么 100k 的数据压完之后只剩 50k,相当于在带宽不变的情况下网速快了一倍。
这些压缩算法有一个缺点,通常只对文本文件有较好的压缩率,像图片、音频、视频等多媒体数据本身就已经是高度压缩的,再压缩不仅不会变小,还有可能变大。
分块传输
除了压缩文件之外,另一种办法就是分块传输。它们的原理差不多,都是把大文件变小传输。分块传输会把一个大文件切成很多小块,把这些小块依次发给浏览器,浏览器收到之后再组装复原。这样浏览器和服务器都不用在内存中保存全部文件,每次只收发一小部分,网络也不会被大文件长时间占用,内存、带宽等资源也就节省下来了。
具体实现是在 response 响应报文里用头字段 Transfer-Encoding: chunked 来表示,表示报文里的 body 部分不是一次性发过来的,而是分成了许多的块(chunk)逐个发送。当 chunk 为 0 时说明是最后一个,传输结束。
Transfer-Encoding 和 Content-Length 两个字段是互斥的,不能同时出现。一个响应报文的长度要么是已知的,要么是未知的。
范围请求
为什么会有范围请求?
你看电影时,想跳过开头直接看正片,这实际上是想获取一个大文件其中的片段数据,而分块传输没有这个能力。
HTTP 协议为了满足这种需求,提出了「范围请求」的概念,允许客户端在请求头里使用专用字段来表示只获取文件的一部分。
范围请求不是 Web 服务器必须实现的功能,所以服务器必须在响应头里使用字段 「Accept-Ranges: bytes 」明确告知客户端自己支持范围请求。如果不支持的话,服务器就会发送「Accept-Ranges:none」或者不发送此字段。这样客户端就只能收发整块文件了。
请求头 Range 是 HTTP 范围请求的专用字段,格式是“bytes=x-y”,其中的 x 和 y 是以字节为单位的数据范围。要注意 x、y 表示的是“偏移量”,范围必须从 0 计数,例如前 10 个字节表示为“0-9”,第二个 10 字节表示为“10-19”,而“0-10”实际上是前 11 个字节。
Range 的格式也很灵活,起点 x 和终点 y 可以省略,能够很方便地表示正数或者倒数的范围。假设文件是 100 个字节,那么:
“0-”表示从文档起点到文档终点,相当于“0-99”,即整个文件;
“10-”是从第 10 个字节开始到文档末尾,相当于“10-99”;
“-1”是文档的最后一个字节,相当于“99-99”;
“-10”是从文档末尾倒数 10 个字节,相当于“90-99”。
服务器收到 Range 字段后,需要做四件事。
第一,它必须检查范围是否合法,比如文件只有 100 个字节,但请求“200-300”,这就是范围越界了。服务器就会返回状态码 416,表示范围请求有误,无法处理。
第二,如果范围正确,服务器就可以根据 Range 头计算偏移量,读取文件的片段了,返回状态码 206 Partial Content,表示 body 只是原数据的一部分。
第三,服务器要添加一个响应头字段 Content-Range,告诉片段的实际偏移量和资源的总大小,格式是 「bytes x-y/length」,与 Range 头区别在没有“=”,范围后多了总长度。例如,对于“0-10”的范围请求,值就是“bytes 0-10/100”。
最后剩下的就是发送数据了,直接把片段用 TCP 发给客户端,一个范围请求就算是处理完了。
常用的下载工具里的多段下载、断点续传也是基于它实现的,要点是:
先发个 HEAD,看服务器是否支持范围请求,同时获取文件的大小;
开 N 个线程,每个线程使用 Range 字段划分出各自负责下载的片段,发请求传输数据;
下载意外中断不必重头再来一遍,只要根据上次的下载记录,用 Range 请求剩下的那一部分就可以了。