软件测试面试大全
- 一、软件测试基础部分
- 1、软件项目成员有哪些?
- 2、软件的概念是什么?
- 3、你对软件测试的定义是怎么的?
- 4、你对软件Bug的概念是怎样的?
- 5、软件Bug级别有几种?
- 6、软件Bug状态有哪些?
- 7、你对软件质量是怎样定义的?
- 8、软件质量的特性有哪些?
- 9、软件生命周期概念是什么?
- 10、软件测试目的是什么?
- 11、软件测试原则是什么?
- 12、测试分为哪几个阶段?
- 13、如何做好测试计划
- 14、软件测试流程
- 15、了解测试流程吗?
- 16、了解 bug 处理流程吗?
- 17、你工作中的沟通对象一般都是哪些人?
- 18、常用的测试工具有哪些?
- 19、工作效率如何?都有哪些成果?
- 20、测试执行步骤是怎么样的?
- 21、软件测试模型有哪些?
- 22、测试用例是怎么设计的?
- 23、测试计划包含哪一些内容?
- 24、测试报告包含有哪些内容?
- 25、一条bug记录包含哪些内容?
- 26、Alpha测试与Beta测试的区别?
- 27、软件测试分类
- 28、软件测试风险
- 29、TDD(测试驱动开发,Test Driver Developer)
- 30、各种测试名词解释
- 二、网络基础知识
- 1、linux 常用命令 — 基础命令
- 2、http/https协议
- 3、TCP/IP协议
- 4、tcp 和 udp 的区别?
- 5、socket建立连接的过程?
- 三、自动化测试
- 1、如何分层自动化测试?
- 2、如何降低自动化维护成本
- 3、如何保证脚本的有效性?
- 4、什么是进程、线程、协程?
- 5、常见测试覆盖类型
- 6、说一下面向对象的概念?
- 7、python 笔试题
- 1. 统计
- 2. 字符串切片
- 3. 字符串切割
- 4. 格式化输出
- 5. 队列
- 6. 交换
- 7. 水仙花:指一个 3 位数,它的每个位上的数字的 3次幂之和等于它本身(例如:1^3 + 5^3+ 3^3 = 153)
- 8. 完全数
- 9. 排序
- 10. sort排序
- 11. 计算n的阶乘
- 12. 斐波那契数列
- 13. 汉诺塔问题
- 8、selenium面试题
- 四、性能测试
- 五、接口测试
- 1、接口测试常规面试题
- 2、接口自动化面试题
- 六、APP测试
- 1、什么是activity?
- 2、Activity生命周期?
- 3、Android四大组件
- 4、app测试和web测试有什么区别?
- 5、android和ios测试区别?
- 6、app出现ANR,是什么原因导致的?
- 7、App出现crash原因有哪些?
- 8、app对于不稳定偶然出现anr和crash时候你是怎么处理的?
- 9、app的日志如何抓取?
- 10、logcat查看日志步骤
- 11、你平常会看日志吗, 一般会出现哪些异常
- 七、数据库
- 1、sql查询
- 2、sql链接查询
- 3、做成函数调用
- 八、安全/渗透测试
- 九、开放性思维题
- 1、搜索输入框测试用例设计
- 2、对电梯进行测试用例设计
- 3、对杯子进行测试用例设计
- 4、对桌子进行测试用例设计
- 5、对洗衣机进行测试用例设计
- 6、购物车功能设计测试用例
- 7、支付功能设计测试用例
一、软件测试基础部分
该部分主要围绕测试基础知识,测试理论、测试方法、测试周期等方面汇总的面试问题。
1、软件项目成员有哪些?
- 项目经理: 驱动整个项目的运转,负责制定计划,安排人力,管理进度,协调团队,进行重大决策。
- 产品经理(需求开发人员): 和客户沟通需求,并制定产品需求
- 架构师 / 系统工程师: 技术专家,经验丰富,负责整个系统的体系架构的设计以及关键模块的设计。
- 程序员 / 开发人员: 设计、编写软件,并修复软件中的缺陷。
- 测试工程师: 负责找出软件产品存在的问题并报告。
2、软件的概念是什么?
- 定义:计算机系统中与硬件相互依存的一部分,它是包括程序,数据及其相关文档的完整集合
- 程序:按事先设计的功能和性能要求执行的指令序列
- 数据:使程序能正常操纵信息的数据结构
- 文档:与程序开发、维护和使用有关的图文资料
3、你对软件测试的定义是怎么的?
- 定义:软件质量保证的一种手段
- 概念:是软件工程中的一个非常重要的环节,是开发项目整体的一部分。是有计划有组织的,是伴随软件工程的诞生而诞生的,软件测试不是万能的,不可能发现全部缺陷,软件测试是有局限性的。
- 目的:验证被测对象是否实现用户需求
- 弄清:实际结果与预期结果之间的差异
4、你对软件Bug的概念是怎样的?
1. 你怎么定义是不是Bug?
- 软件没有实现产品的说明书所描述的功能。
- 软件实现了产品说明书描述不应有的功能。
- 软件执行了产品说明书没讲的操作。
- 软件没有实现产品说明书没描述但应该实现的功能(用户体验相关)。
- 从软件测试员的角度来看,软件难以理解、不易使用、运行缓慢,或者最终用户认为不对。
2. bug的类型都有哪些?
- Bug有代码编写错误导致的功能问题
- Defect缺,实现与需求不一致
- Fault即故障,由于环境系统问题引起运行失败
- Error即错误,语法错误,逻辑错误,不易发现
5、软件Bug级别有几种?
-
微小的==》一些小问题
如:错字,文字排版不整齐等,对功能几乎没有影响,软件产品仍可使用。 -
一般的==》不太严重的错误
如:主要功能模块部分丧失、提示信息不够准确、用户界面差和操作运行时间长等。 -
严重的==》严重错误
指功能模块和特性没有实现,主要功能部分丧失,次要功能全部丧失。 -
致命的==》严重的致命的错误
造成系统崩溃,四级,或造成数据丢失、主要功能完全丧失等。
如:死机、宕机、黑白屏无法使用、完全卡死
6、软件Bug状态有哪些?
-
激活状态==》问题没解决
测试人员新报告的缺陷或者验证后缺陷仍存在。 -
已修正状态==》开发人员针对缺陷
修正软件后已解决问题或已通过单元测试 。 -
关闭状态==》测试人员经过验证后,确认缺陷不存在之后的状态 。
-
遗留状态==》此次版本升级不修改,遗留到下一版本修改。
-
非错状态==》就是此问题不是一个Bug,开发可以直接置为关闭
7、你对软件质量是怎样定义的?
- 软件质量就是“软件与明确的和隐含的定义的需求相一致的程度”;
- 明确的需求指:软件符合明确叙述的功能和性能需求、文档中明确描述的开发标准;
- 隐含的需求指:所有专业开发的软件都应具有的隐含特征的程度,比如:符合行业标准。
- 内部质量:软件内部的设计和静态测试是否合格
- 过程质量:关注软件的整个生产流程是否规范是否合理
- 外部质量:关注软件产品本身的功能和性能表现
- 使用质量:关注软件在使用过程中易用性满意度的表现
8、软件质量的特性有哪些?
- 件质量的六大特性是什么?
1.功能性
定义:软件在指定的使用环境下,满足用户显性或隐性需求的能力
适合性:软件为指定的任务和用户目标提供一组合适功能的能力
准确性:软件提供具有所需精确度的正确或相符的結果或效果的能力
互操作性:软件与一个或更多个的规定系统进行交互的能力
2.可靠性
定义:软件在指定的条件下使用,维持规定的性能级别的能力
成熟性:软件为避免由软件中错误而导致失控的能力,
容错性:在软件出现故障或违反指定接口的情况下,软件维持规定性能级别的能力,
易恢复性:在失效发生的情况下软件里重建规定的件能级别并恢复受直接影响的数据的能力
可靠性依从性:软件遵循与可靠件相关的标准,约定以及法律法规的能力
3.效率
定义:在规定的条件下,相对于所用资源的数量,软件提供适当性能的能力
时间特性:在规定的条件下软件执行其功能时,提供适当的响应和处理时间以及吞吐率的能力
资源利用性:在规定的条件下软件执行其能力时,使用合适的资源数量和类别的能力
效率依从件:软件遵循与效率相关的标准和约定的能力
4.易用性
定义:在指定的条件下使用时,软件被学习,理解,使用和吸引用户的能力
易理解性:软件的使用,用户能理解软件是否合适,以及如何将软件用于特定的任务和使用环境的能力
易学习:软件使用户能学习其应用的能力易操作性:软件使用用户操作和控制它的能力
吸引性:软件吸引用户的能力
易用性依从性:遭循与易用性相关的标准、约定风格指南或法规的能力
5.可维护
定义:软件可被修改的能力,修改可能包括修正、改进或软件对环境、需求和功能规格说明变化的适应性
易分析性:软件诊断软件的缺陷,失效原因或识别待修改部分的能力,
易改变性:软件指定的修改可以被实现的能力
稳定性:软件避免由于软件修改而造成意外结果的能力,
易测试性:软件使已修改软件能被确认的能力
可维护依从性:遵循与维护相关标准和约定的能力
6.可移植
定义:软件从一种环境迁移到另一种环境的能力
适用性:软件能适用于不同的环境的能力
易安装性:软件在指定环境中被安装的能力
共存性:软件在公共环境中同与其分享公共资源的其他独立软件共存的能力
易替换性:软件在同样的环境下,替代另一个相同用途的指定软件产品的能力
可移植性依从性:软件遵循可移植性相关的标准和约定的能力
9、软件生命周期概念是什么?
需求分析 —》可行性分析 —》概要设计 —》详细设计 —》编码实现 —》调试和测试 —》软件验收与应用 —》维护升级 —》废弃
10、软件测试目的是什么?
测试的目的不仅仅是为了发现软件缺陷与错误,而且也是对软件质量进行度量和评估,以提高软件的质量。
- 发现:被测对象与用户需求之间的差异
- 增加:用户对被测对象的质量信息
- 获取被测对象信息,为决策提供依据
- 为软件质量的可持续运行提供保障
- 预防Bug,降低风险
11、软件测试原则是什么?
基于测试是为了寻找软件的错误与缺陷,评估与提高软件质量,因此我们提出了这样的一组测试原则,如下所示。
- 所有的软件测试都应追溯到用户需求。
- 应当把“尽早地和不断地进行软件测试”作为软件测试者的座右铭。
- 完全测试是不可能的,测试需要终止。
- 测试无法显示软件潜在的缺陷。
- 充分注意测试中的群集现象。
- 程序员应避免检查自己的程序。
- 尽量避免测试的随意性
12、测试分为哪几个阶段?
- 单元测试
- 集成测试
- 系统测试
- 验收测试
13、如何做好测试计划
5W原则:
- What (明确测试什么)
- Why(明确测试目标)
- When(明确项目开始时间、结束时间)
- How(明确测试方案)
- Where(明确资料的位置)
14、软件测试流程
-
第一步:
对要执行测试的产品/项目进行需求分析,确定测试策略,制定测试计划。该计划被审核批准后转向第二步。测试工作启动前一定要确定正确的测试策略和指导方针,这些是后期开展工作的基础。只有将本次的测试目标和要求分析清楚,才能决定测试资源的投入。 -
第二步:
设计测试用例。设计测试用例要根据测试需求和测试策略来进行,进度压力不大时,应该设计的详细,如果进度、成本压力较大,则应该保证测试用例覆盖到关键性的测试需求。该用例被批准后转向第三步。 -
第三步:
如果满足“启动准则”(EntryCriteria),那么执行测试。执行测试主要是搭建测试环境,执行测试用例。执行测试时要进行进度控制、项目协调等工作。 -
第四步:
提交缺陷。这里要进行缺陷审核和验证等工作。 -
第五步:
消除软件缺陷。通常情况下,开发经理需要审核缺陷,并进行缺陷分配。程序员修改自己负责的缺陷。在程序员修改完成后,进入到回归测试阶段。如果满足“完成准则”(ExitCriteria),那么正常结束测试。 -
第六步:
撰写测试报告。对测试进行分析,总结本次的经验教训,在下一次的工作中改。
软件测试过程管理,主要包括软件测试是什么样的过程,如何评价一个软件测试过程,如何进行配置管理和测试风险分析以及测试成本的管理。
15、了解测试流程吗?
- 需求分析【需求沟通,确定需求,功能点含义,】
- 需求评审【制定测试方案】
- 设计测试用例
- 用例评审
- 测试计划
- 搭建测试环境
- 测试执行
- bug 处理
- 回归测试
- 测试报告
- 跟进上线
16、了解 bug 处理流程吗?

bug分级;优先级(高中低)、严重程度(高中低)
bug分类:UI、系统、接口
bug状态:新建、待修改、待验证、已验证、遗留、关闭
17、你工作中的沟通对象一般都是哪些人?
- 产品、开发、UED
- 市场、运维、运营
- 领导、下属
18、常用的测试工具有哪些?
- 网络调试工具:Fiddler
- 页面调试工具: Chrome Inspector firebug
- WEB自动化工具:QTP、Selenium
- 移动端工具: ADB,Monkey, MonkeyRunner
- 移动端自动化框架:Appium 、Robotium 、Android、selendroid
- 平台知识:windows、mac、android、Linux
- 服务端压力工具Loadrunner、JMter
- mysql 可视化工具
19、工作效率如何?都有哪些成果?
- 如何安排任务的,如何提高测试效率?
- 工作中的成果都有哪些?
- 如何团队间协调工作的?
20、测试执行步骤是怎么样的?
- 部署测试环境
- 对测试用例进行分类
- 执行测试用例
- 记录测试结果,对缺陷进行分级分类
- 反馈缺陷并跟踪直至缺陷关闭
21、软件测试模型有哪些?
-
瀑布流
计划—>需求分析—>设计—>编码—>测试—>运行维护
瀑布模型是最正宗最规范的流程。
特点:
1.软件开发的各项活动严格按照线性方式进行。
2.当前活动接受上一项活动的工作结果。
3.当前活动的工作结果需要进行验证。
缺点:
1.由于开发模型是线性的,增加了开发的风险。
2.早期的错误可能要等到开发后期的阶段才能发现 -
V字形
-
W字型(双V)
-
螺旋型
制定计划—>风险分析—>实施工程(需求确认、软件需求、软件产品设计、设计确认与认证、详细设计、开发、测试)—>客户评估。
特点:
1.螺旋模型是将瀑布模型与快速原型模型结合起来
2.强调了其他模型所忽视的风险分析
3.每一次螺旋包括4个步骤:制定计划、风险分析、实施工程、客户评估 -
敏捷
特点:
1.短周期开发
2.增量开发
3.由程序员和测试人员编写的自动化测试来监控开发进度
4.通过口头沟通、测试和源代码来交流系统的结构和意图
5.编写代码之前先写测试代码,也叫做测试先行
缺点:
1.团队的组建较难,人员素质要求较高
2.对测试员要求完全掌握各种脚本语言编程,能执行单元测试、自动化测试 -
X模型
-
H模型
-
原型模型
客户与开发公司紧密联系,开发周期长。开发会受到需求变更的影响
特点:
1.实现客户与系统的交互。
2.进一步细化待开发软件需求。
3.开发人员可以确定客户的真正需求是什么
22、测试用例是怎么设计的?
用例设计:
- 对需求进行模块化分解;
- 使用科学有效的设计方法;
测试用例都有哪些设计方法
6种黑盒测试方法,如下:
- 等价类划分法 (有效、无效)
- 边界值分析法 (+1,-1)
- 因果图表法 ()
- 判定表方法
- 状态迁移法
- 正交实验法 (多组合交互组合测试)
- 错误推错法 (经验)
- 场景法 (登陆成功,成功后购买成功、登陆成功,成功后购买失败,登陆失败)
测试用例覆盖类型:
- UI界面检查
- 功能逻辑
- 流程验证
- 网络问题
网络不通
2G/3G/4G网络切换
飞行模式 - 数据升级
- 适配
- 版本兼容和系统兼容
23、测试计划包含哪一些内容?
- 概述
- 测试目的
- 项目背景
- 测试要求与范围
- 预期读者
- 参考资料
- 测试环境
- 系统架构
- 软硬件环境要求
- 测试环境部署图
- 测试规划
- 测试范围
- 测试工具
- 人员、角色及职责
- 测试策略
- 系统框架测试
- 业务流程测试
- 功能点测试
- UI界面测试
- 性能测试
- 兼容性测试
- 安全测试
- 测试进度安排
- 测试风险分析
- 风险规避
24、测试报告包含有哪些内容?
- 测试背景说明
- 测试范围说明
- 测试环境说明
- 测试方法说明
- 测试结果结论
- 质量或风险评估
- 附录缺陷列表
25、一条bug记录包含哪些内容?
-
测试工程师、开发人员、bug日期
-
bug标题, bug正文, bug附件
-
bug优先级、bug严重等级
-
bug所属模块
-
bug状态(新建、已修复、已验证、遗留等)
-
bug处理记录
26、Alpha测试与Beta测试的区别?
-
Alpha测试是由一个用户在开发环境下进行的测试
-
Beta测试在用户真实环境测试,通过后进入发布阶段
27、软件测试分类
-
按照开发阶段划分软件测试:单元测试、集成测试、系统测试、验收测试。
-
按照测试实施组织划分软件测试:开发方测试、用户测试(alpha测试,Beta测试)、第三方测试。
-
按照测试技术划分:白盒测试、灰盒测试、黑盒测试。
软件测试方法和技术的分类与软件开发过程相关联,它贯穿了整个软件生命周期。
28、软件测试风险
-
软件测试中的软件风险分析是根据预测软件将出现的风险,制定软件测试计划并排列优先等级,风险分析是对软件中潜在的问题进行识别、估计和评价的过程。
-
风险也包括进度风险、质量风险、人员风险、变更风险、成本风险等
29、TDD(测试驱动开发,Test Driver Developer)
测试驱动开发的基本思想就是在开发功能代码之前,先编写测试用例。也就是说在明确要开发某个功能后,首先思考如何对这个功能进行测试,并完成测试代码的编写,然后编写相关的代码满足这些测试用例。然后循环进行添加其他功能,直到完成全部功能的开发。
30、各种测试名词解释
- 什么是单元测试(Unit Testing)
- 单元测试是指对软件中的最小可测试单元进行检查和验证。
- 对于单元测试中单元的含义,一般来说,要根据实际情况去判定其具体含义,如C语言中单元指一个函数,Java里单元指一个类,图形化的软件中可以指一个窗口或一个菜单等。
- 总的来说,单元就是人为规定的最小的被测功能模块。单元测试是在软件开发过程中要进行的最低级别的测试活动,软件的独立单元将在与程序的其他部分相隔离的情况下进行测试。
- 什么是集成测试(Integration Test)
- 集成测试,也叫组装测试或联合测试。
- 在单元测试的基础上,将所有模块按照设计要求(如根据结构图〕组装成为子系统或系统,进行集成测试。
- 实践表明,一些模块虽然能够单独地工作,但并不能保证连接起来也能正常的工作。程序在某些局部反映不出来的问题,在全局上很可能暴露出来,影响功能的实现。
-
集成测试的关注点:
1.在把各个模块连接起来时,穿越模块接口的数据是否会丢失。
2.各个子功能组合起来,能否达到预期的要求。
3.一个模块的功能是否会对另一个模块的功能产生不利的影响。 -
集成测试可以划分成3个级别:
- 模块内集成测试。
- 子系统内集成测试。
- 系统间集成测试。
- 什么是系统测试(System Testing)
- 将已经确认的软件、计算机硬件、外设、网络等其他元素结合在一起,进行信息系统的各种组装测试和确认测试.
- 系统测试是针对整个产品系统进行的测试
- 目的是验证系统是否满足了需求规格的定义,找出与需求规格不符或与之矛盾的地方,从而提出更加完善的方案
- 系统测试发现问题之后要经过调试找出错误原因和位置,然后进行改正。是基于系统整体需求说明书的黑盒类测试,应覆盖系统所有联合的部件。
- 对象不仅仅包括需测试的软件,还要包含软件所依赖的硬件、外设甚至包括某些数据、某些支持软件及其接口等。
- 系统测试范围/策略
功能测试、性能测试、压力测试、容量测试、安全性测试、GUI测试、安装测试、配置测试、异常测试、备份测试、健壮性测试、文档测试、在线帮助测试、网络测试、稳定性测试 - 什么是验收测试(Acceptance Test)
- 它是一项确定产品是否能够满足合同或用户所规定需求的测试。这是管理性和防御性控制
- 主要确认软件是否按合同要求进行工作,既是否满足软件需求规格说明书中的要求。
- 验收测试分类:
- 非正式的验收测试
а测试(alpha)
软件开发公司组织内部人员模拟各类用户行为对即将上市的产品进行测试。
ß测试(beta)
软件开发公司组织各方面的典型客户在日常工作中实际使用,并要求用户报告异常情况、提出改进意见,然后公司再进行完善。 - 正式的验收测试
有正规的测试过程,需要制定测试计划、定义测试方案、选择测试用例,进行测试,结果提交。着重考虑软件是否满足合同规定的所有功能和性能,文档资料是否完整、准确,人机界面和其他方面。
-
静态测试(Static Testing)

-
动态测试(Execution-Based Testing)
实际运行被测试的软件,输入相应的测试数据,检查界面的输出结果是否和预期结果相一致的过程。 -
黑盒测试(Black box)
把软件看成一个黑盒子,不管内部逻辑和内部特性,只依据规格说明书检查程序的功能是否符合功能说明 -
白盒测试(White box)
又称为结构测试。着重于程序内部结构和算法,不关心功能和性能指标。 -
灰盒测试(Gray box)
介于白盒和黑盒测试之间,基于程序运行时刻的外部表现同时又结合程序内部逻辑结构来设计用例,执行程序并采集程序路径执行信息和外部用户接口结果的测试技术。 -
灰盒测试有啥缺点?
当然,凡事都有优点和缺点,灰盒测试自然也不例外。下面列举它的主要缺点。
- 不适用于简单的系统
所谓的简单系统,就是简单到总共只有一个模块。由于灰盒测试关注于系统内部模块之间的交互。如果某个系统简单到只有一个模块,那就没必要进行灰盒测试了。 - 对测试人员的要求比黑盒测试高
从上面的介绍来看,灰盒测试要求测试人员清楚系统内部由哪些模块构成,模块之间如何协作。因此,对测试的要求就提高了。因此,会带来一定的培训成本。不过捏,依照俺的经验,培训难度不大。稍微有点基础的测试人员,都可以在短期培训之后胜任。 - 不如白盒测试深入
显然,灰盒不如白盒那么深入。不过捏,考虑到灰盒测试相比白盒测试有显著的成本优势,该缺点不是太明显。
-
回归测试(Regression Testing )
对软件的新版本测试时,重复执行上一个版本测试时使用的测试用例。防止出现“以前应用没有的问题现在出问题了” 。 -
冒烟测试(BVT测试(Build Verification Test ))
冒烟测试的对象是每一个新编译需要正式测试的版本,目的是确认软件基本功能正常,可以进行后续的正式测试工作。冒烟测试,也叫预测试。 -
随机测试(又名猴子测试,探索性测试)
测试数据是随机产生的,在测试用例之外。只能作为一个测试的补充。 -
敏捷测试(敏捷开发引起)
首先敏捷测试(Agile testing)是测试的一种,原有测试定义中通过执行被测系统发现问题,通过测试这种活动能够提供对被测系统提供度量等概念还是适用的。 -
TDD(测试驱动开发,Test Driver Developer)
测试驱动开发的基本思想就是在开发功能代码之前,先编写测试用例。也就是说在明确要开发某个功能后,首先思考如何对这个功能进行测试,并完成测试代码的编写,然后编写相关的代码满足这些测试用例。然后循环进行添加其他功能,直到完成全部功能的开发。
二、网络基础知识
本篇收集了几个被问的频率较高的linux面试题
1、linux 常用命令 — 基础命令
- cd
语法:cd [路径]
功能:切换目录
进入home目录:cd /home
cd . :进入当前目录
cd … :进入上一级目录
cd - :进入上次的目录
cd :进入当前目录的home目录
cd ~ :进入当前目录的home目录
cd / :进入到根目录 - ls
语法:ls [选项] [路径]
功能:显示文件以及目录
-a 显示所有文件以及目录。
-l 列出文件名称外,还将文件形态、权限、拥有者、文件大小等详细信息列出。
例:
1.ls:显示当前目录下的所有文件及目录
2.ls /home:显示home目录下的所有文件及目录 - cp
语法:cp [选项] 源文件或目录 目标文件或目录
功能:拷贝文件
-p:除复制文件的内容外,还把修改时间和访问权限也复制到新文件中。
-r:若给出的源文件是一个目录文件,此时将复制该目录下所有的子目录和文件。
例:cp /home/test1.txt /data
将home目录下的test1.txt文件复制到data目录下 - mkdir
语法:mkdir [文件夹名]
功能:新建一个目录
例:mkdir /user_tool
建立一个名字为“user_tool”的文件夹 - rmdir
语法:rmdir [选项] [文件夹名]
功能:删除目录
- p 递归删除目录dirname,当子目录删除后其父目录为空时,也一同被删除。
例:rmdir /user_tool
删除一个名字为“user_tool”的文件夹 - rm
语法:rm [选项] [文件以及文件夹]
功能:删除档案及目录
-r是递归处理,就是一层一层的删;将目录及以下之档案亦逐一删除。
-f是强制删除。
例:rm -r homework
删除homework目录及其下的所有文件及子目录
rm -r *
删除当前目录下的所有文件及目录 - tar
压缩和解压命令
语法:tar [选项] [文件目录列表]
功能:对文件目录进行打包备份
tar -cvf log.tar log2012.log 仅打包,不压缩!
tar -zcvf log.tar.gz log2012.log 打包后,以 gzip 压缩
tar -jcvf log.tar.bz2 log2012.log 打包后,以 bzip2 压缩
tar –xvf file.tar 解压 tar包
tar -xzvf file.tar.gz 解压tar.gz
tar -xjvf file.tar.bz2 解压 tar.bz2
tar –xZvf file.tar.Z 解压tar.Z - mv
修改文件或文件夹名
mv [options] 源文件或目录 目标文件或目录。
例:
mv test.txt wbk.txt
mv file1 file2
把当前目录下的file1文件名改成file2,如果该目录下有file2,则覆盖以前的file2文件。 - pwd
语法:pwd
显示当前工作目录的绝对路径 - clear
语法:clear
功能:清屏 - cat
查看文件
例:
cat /proc/version
查看linux内核版本 - chmod
语法格式为:chmod [who] [opt] [mode] 文件/目录名
功能:修改文件的写读执行权限
参数分别表示User、Group、及Other的权限。
r=4,w=2,x=1
若要rwx属性则4+2+1=7;
若要rw-属性则4+2=6;
若要r-x属性则4+1=5。
例:chmod 777 a.txt - find
语法:find [文件及路径]
功能:查找指定的文件
find . -name “*.c”
将目前目录及其子目录下所有扩展名是c的文件列出来。 - vi
语法:vi/vim 文件名
功能:编辑文件 - locate
语法:cp [选项][文件目录]
功能:查找文件或目录
例:
locate /etc/my
/etc/my.cnf
搜索etc目录下所有以my开头的文件 - grep
语法:grep [选项] ”模式“ [文件]
功能:搜索字符串得 grep 命令
例:grep test *file
在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件 - ps
语法:ps [options] [–help]
功能:显示当前进程 (process) 的状态
例:ps -a
列出所有的进程 - kill
语法:kill [进程名]
功能:杀死进程
例:
kill 12345
将进程12345结束
注意:可以先用ps 或 top命令查看进程的id,然后再用kill命令杀死进程 - tree
功能:以树状图列出文件目录结构
注意:如果tree安装包没有安装,请执行:sudo apt install tree - tail
查看文件的后几行
-n 后面接数字,表示查看几行(也可以不加, 默认查看文件后10 行 )
例:tail -5 /etc/passwd
查看后5行内容 - top
用于动态地监视进程活动与系统负载等信息,其格式为top,按q退出。
PID:当前运行进程的ID USER:进程属主 PR:每个进程的优先级别
NInice:反应一个进程“优先级”状态的值,其取值范围是-20至19,一共40个级别。这个值越小,表示进程”优先级”越高,而值越大“优先级”越低。一般会把nice值叫做静态优先级
VIRT:进程占用的虚拟内存
RES:进程占用的物理内存
SHR:进程使用的共享内存
S:进程的状态。S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值为负数
%CPU:进程占用CPU的使用率 %MEM:进程使用的物理内存和总内存的百分比
TIME+:该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。
COMMAND:进程启动命令名称 - free查看内存
total : 总计物理内存的大小。
used : 已使用多大。
free : 可用有多少。
Shared : 多个进程共享的内存总额。
Buffers/cached : 磁盘缓存的大小。
available:可用有多少。
Swap:用于临时内存,当系统的真实内存不够用时,可以临时使用磁盘空间来充当内存。 - cat /proc/meminfo查看内存

2、http/https协议
-
浏览器输入url按回车背后经历了哪些?
(1)进行DNS解析(域名解析),获取Web服务器的IP地址。
(2)建立TCP连接。
三次握手过程:
第一次握手:客户端向服务器端发送请求,等待服务器确认。
第二次握手:服务器收到请求并确认,回复一个指令。
第三次握手:客户端收到服务器的回复指令并返回确认。
(3)向Web服务器发送HTTP请求。
(4)Web服务器接收到请求并处理。
(5)Web服务器返回响应。
(6)浏览器对响应进行解码,并显示数据。
(7)页面显示完成后,浏览器发送异步请求。
(9)关闭TCP连接。 -
get和post的区别?
(1).GET在浏览器回退时是无害的,而POST会再次提交请求。
(2).GET产生的URL地址可以被Bookmark,而POST不可以。
(3).GET请求会被浏览器主动cache,而POST不会,除非手动设置。
(4).GET请求只能进行url编码,而POST支持多种编码方式。
(5).GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
(6).get方式提交数据的大小(一般来说1024字节),http协议并没有硬性限制,而是与浏览器、服务器、操作系统有关,而POST理论上来说没有大小限制,http协议规范也没有进行大小限制,但实际上post所能传递的数据量根据取决于服务器的设置和内存大小。
(7).对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
(8).GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
(9).GET参数通过URL传递,POST放在Request body中。 -
cookies机制和session机制的区别
具体来说cookie机制采用的是在客户端保持状态的方案,而session机制采用的是在服务器端保持状态的方案。
同时我们也看到,由于采用服务器端保持状态的方案在客户端也需要保存一个标识,所以session机制可能需要借助于cookie机制来达到保存标识的目的,但实际上还有其他选择。 -
常见的HTTP状态码有哪些?
- 2xx(3种)
200 OK:表示从客户端发送给服务器的请求被正常处理并返回;
204 No Content:表示客户端发送给客户端的请求得到了成功处理,但在返回的响应报文中不含实体的主体部分(没有资源可以返回);
206 Patial Content:表示客户端进行了范围请求,并且服务器成功执行了这部分的GET请求,响应报文中包含由Content-Range指定范围的实体内容。 - 3xx(5种)
301 Moved Permanently:永久性重定向,表示请求的资源被分配了新的URL,之后应使用更改的URL;
302 Found:临时性重定向,表示请求的资源被分配了新的URL,希望本次访问使用新的URL;
301与302的区别:前者是永久移动,后者是临时移动(之后可能还会更改URL)
303 See Other:表示请求的资源被分配了新的URL,应使用GET方法定向获取请求的资源;
302与303的区别:后者明确表示客户端应当采用GET方式获取资源
304 Not Modified:表示客户端发送附带条件(是指采用GET方法的请求报文中包含if-Match、If-Modified-Since、If-None-Match、If-Range、If-Unmodified-Since中任一首部)的请求时,服务器端允许访问资源,但是请求为满足条件的情况下返回改状态码;
307 Temporary Redirect:临时重定向,与303有着相同的含义,307会遵照浏览器标准不会从POST变成GET;(不同浏览器可能会出现不同的情况); - 4xx(4种)
400 Bad Request:表示请求报文中存在语法错误;
401 Unauthorized:未经许可,需要通过HTTP认证;
403 Forbidden:服务器拒绝该次访问(访问权限出现问题)
404 Not Found:表示服务器上无法找到请求的资源,除此之外,也可以在服务器拒绝请求但不想给拒绝原因时使用; - 5xx(2种)
500 Inter Server Error:表示服务器在执行请求时发生了错误,也有可能是web应用存在的bug或某些临时的错误时;
503 Server Unavailable:表示服务器暂时处于超负载或正在进行停机维护,无法处理请求;
- 2xx(3种)
-
http协议有哪几种请求方式?
Get:请求指定的页面信息,并返回实体主体
Post:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中,post请求可能会导致新的资源的建立和/或已有资源的修改
Head:类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
Options:允许客户端查看服务器的性能
Put:从客户端向服务器传送的数据取代指定的文档的内容
Delete:请求服务器删除指定的页面
Trace:回显服务器收到的请求,主要用于测试或诊断
Connect:http/1.1协议中预留给能够将连接改为管道方式的代理服务器 -
http和https区别?
- https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
- http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
- http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
-
http报文格式是怎样的?
http的请求报文和响应报文的格式基本一样,主要分为三部分:- 起始行(start line): 描述请求或响应的状态
- 头部字段(header): 以 key:value 的形式展示
- 数据实体(entity/ body) :实际要传输的数据,可以是文本,也可以是图片、文件、视频等二进制数据
-
常见的 POST 提交数据方式
- application/x-www-form-urlencoded:在发送前编码所有字符(默认),提交的数据按照 key1=val1&key2=val2 的方式进行编码,key 和 val 都进行了 URL 转码。
- multipart/form-data:不对字符编码。在使用包含文件上传控件的表单时,必须使用该值。
- text/xml:空格转换为 “+” 加号,但不对特殊字符编码。使用 HTTP 作为传输协议,XML 作为编码方式的远程调用规范。
- application/json:JSON 格式支持比键值对复杂得多的结构化数据。
-
什么是DNS?
DNS是一个域名系统,是万维网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串,DNS就是进行域名解析的服务器。。 -
什么是Http协议无状态协议?怎么解决Http协议无状态协议?
无状态协议:- 协议对于事务处理没有记忆能力【事物处理】【记忆能力】
- 对同一个url请求没有上下文关系【上下文关系】
- 每次的请求都是独立的,它的执行情况和结果与前面的请求和之后的请求是无直接关系的,它不会受前面的请求应答情况直接影响,也不会直接影响后面的请求应答情况【无直接联系】【受直接影响】
- 服务器中没有保存客户端的状态,客户端必须每次带上自己的状态去请求服务器【状态】
解决办法:
加入cookie、session等机制实现有状态的web。
3、TCP/IP协议
- 模型
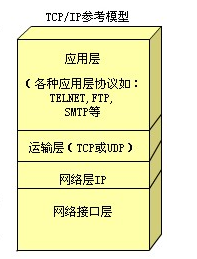
- 各层释义
应用层:
向用户提供一组常用的应用程序,比如电子邮件、文件传输访问、远程登录等。远程登录TELNET使用TELNET协议提供在网络其它主机上注册的接口。TELNET会话提供了基于字符的虚拟终端。文件传输访问FTP使用FTP协议来提供网络内机器间的文件拷贝功能。
传输层:
提供应用程序间的通信。其功能包括:一、格式化信息流;二、提供可靠传输。为实现后者,传输层协议规定接收端必须发回确认,并且假如分组丢失,必须重新发送。
网络层 :
负责相邻计算机之间的通信。其功能包括三方面。
一、处理来自传输层的分组发送请求,收到请求后,将分组装入IP数据报,填充报头,选择去往信宿机的路径,然后将数据报发往适当的网络接口。
二、处理输入数据报:首先检查其合法性,然后进行寻径–假如该数据报已到达信宿机,则去掉报头,将剩下部分交给适当的传输协议;假如该数据报尚未到达信宿,则转发该数据报。
三、处理路径、流控、拥塞等问题。
网络接口层:
这是TCP/IP软件的最低层,负责接收IP数据报并通过网络发送之,或者从网络上接收物理帧,抽出IP数据报,交给IP层。
4、tcp 和 udp 的区别?
- TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
- TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
- TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的,UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
- 每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
- TCP首部开销20字节;UDP的首部开销小,只有8个字节
- TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
常见使用TCP协议的应用如下: 浏览器,用的HTTP FlashFXP,用的FTP Outlook,用的POP、SMTP Putty,用的Telnet、SSH QQ文件传输
常见使用UDP协议的应用如下: QQ语音 QQ视频 TFTP(当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快)
5、socket建立连接的过程?
- TCP的三次握手建立连接过程:

第一次握手:客户主动(active open)去connect服务器,并且发送SYN 假设序列号为J,服务器是被动打开(passive open)
第二次握手:服务器在收到SYN后,它会发送一个SYN以及一个ACK(应答)给客户,ACK的序列号是 J+1表示是给SYN J的应答,新发送的SYN K 序列号是K
第三次握手:客户在收到新SYN K, ACK J+1 后,也回应ACK K+1 以表示收到了,然后两边就可以开始数据发送数据了 - TCP的四次挥手断开连接过程:

第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。
三、自动化测试
1、如何分层自动化测试?
- UI自动化回归
- 接口自动化
- 单元测试-白盒测试
2、如何降低自动化维护成本
-
在选取将用例自动化时就要注意,尽可能的选取比较稳定的接口/内容做自动化测试;
-
测试人员在编写测试脚本时对脚本质量的要求,重用性,复用性,搭建高质量的测试框架;
-
测试工具的选取使用(比如选取专业的/商业话的测试软件工具),以及硬件服务的配套使用;
-
加强提高测试人员的编码开发实力,这样能够创造出更多有用的测试工具。
3、如何保证脚本的有效性?
-
元素定位有效:元素单独封装
-
业务流程有效:封装独立方法
-
测试数据有效:保证数据库环境稳定,备份恢复,脚本灵活,实时提取数据,随机数。
4、什么是进程、线程、协程?
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。
线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。
协程是一种基于线程之上,但又比线程更加轻量级的存在,这种由程序员自己写程序来管理的轻量级线程叫做『用户空间线程』,具有对内核来说不可见的特性。

进程与线程的区别:
- 线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
- 一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线;
- 进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;
- 调度和切换:线程上下文切换比进程上下文切换要快得多。
协程的特点:
- 线程的切换由操作系统负责调度,协程由用户自己进行调度,因此减少了上下文切换,提高了效率。
- 线程的默认Stack大小是1M,而协程更轻量,接近1K。因此可以在相同的内存中开启更多的协程。
- 由于在同一个线程上,因此可以避免竞争关系而使用锁。
- 适用于被阻塞的,且需要大量并发的场景。但不适用于大量计算的多线程,遇到此种情况,更好是用线程去解决。
5、常见测试覆盖类型
-
语句覆盖:语句覆盖就是设计若干个测试用例,运行被测试程序,使得每一条可执行语句至少执行一次。
-
判定覆盖(也叫分支覆盖):设计若干个测试用例,运行所测程序,使程序中每个判断的取真分支和取假分支至少执行一次。
-
条件覆盖:设计足够的测试用例,运行所测程序,使程序中每个判断的每个条件的每个可能取值至少执行一次。
-
判定、条件覆盖:设计足够的测试用例,运行所测程序,使程序中每个判断的每个条件的每个可能取值至少执行一次,并且每个可能的判断结果也至少执行一次。
-
条件组合测试:设计足够的测试用例,运行所测程序,使程序中每个判断的所有条件取值组合至少执行一次。
-
路径测试:设计足够的测试用例,运行所测程序,要覆盖程序中所有可能的路径。
6、说一下面向对象的概念?
面向对象的方法就是利用抽象、封装等机制,借助于对象、类、继承、消息传递等概念进行软件系统构造的软件开发方法。
对象:对象是类的一个实例,有状态和行为。例如,一条狗是一个对象,它的状态有:颜色、名字、品种;行为有:摇尾巴、叫、吃等。
类:类是一个模板,它描述一类对象的行为和状态。
面向对象三大主要特征:封装、继承、多态
详细解释请查看转载:https://blog.csdn.net/sugar_no1/article/details/86366714
7、python 笔试题
1. 统计
统计在一个队列中的数字,有多少个正数,多少个负数,如[1,3,5,7,0,-1,-9,-4,-5,8]
a = [1,3,5,7,0,-1,-9,-4,-5,8]
m = [i for i in a if i > 0]
n = [i for i in a if i < 0]
print("正数的个数:{}".format(len(m)))
print("负数的个数:{}".format(len(n)))
2. 字符串切片
字符串“axbyczdj”,如果得到结果“abcd”
a = "axbyczdj"
print(a[::2])
3. 字符串切割
已知一个字符串为“hello_world_yoyo”,如何得到一个队列[“hello”,“world”,“yoyo”]
a = "hello_world_yoyo"
b = a.split("_")
4. 格式化输出
已知一个数字为1,如何输出"0001"
%和format方法大全汇总:https://www.cnblogs.com/qinchao0317/p/10699717.html
a = 1
print("%04d"%a)
#print('{:0=4}'.format(a))
5. 队列
已知一个队列,如:[1,3,5,7],如何把第一个数字,放在第三个位置,得到:[3,5,1,7]
a = [1,3,5,7]
a.insert(3,a[0])
print(a[1:])
6. 交换
已知a=9,b=8,如何交换a和b的值,得到a的值为8,b的值为9
a = 9
b = 8
a,b = b,a
print(a,b)
7. 水仙花:指一个 3 位数,它的每个位上的数字的 3次幂之和等于它本身(例如:1^3 + 5^3+ 3^3 = 153)
#判断是否是水仙花数
while True:num = input("请输入一个数字:")num = int(num)if 100<=num<=999:a = num // 100b = num % 100 // 10c = num %10result = a**3+b**3+c**3if result == num:print("{:d}是水仙花数".format(result))else:print("{:d}不是水仙花数".format(result))else:print("输入的非3位数的数值")
8. 完全数
求出1000以内的完全数
a=[]
for i in range(1,1000):sum=0for j in range(1,j):if i%j==0 and j<i:sum+=jif sum==i:a.append(i)
print(a)
9. 排序
用python写个冒泡排序
def bubble_sort(alist):n = len(alist)for i in range(n-1):for j in range(n-i-1):if alist[j]>alist[j+1]:alist[j],alist[j+1] = alist[j+1],alist[j]return alist
10. sort排序
已知一个队列[1,3,6,9,7,3,4,6]
#列表排序
a = [1,3,6,9,7,3,4,6]
a.sort()
a.sort(reverse=True)
b = list(set(a))#去重后排序
b.sort(key=a.index)#去重后不改变原顺序
#字典排序
dic = {'a':1 , 'b':2 , 'c': 3}
a = sorted(dic.items(),key=lambda asd:asd[0],reverse=False)#按key值排序
b = sorted(dic.items(),key=lambda asd:asd[1],reverse=False)#按value值排序
11. 计算n的阶乘
def digui(n):if n==1:return nelse:return n*digui(n-1)
print(5)
12. 斐波那契数列
a,b=0,1
list=[]
maxnum=100
while a<maxnum:list.append(a)a,b=b,a+b
print(list)
#[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
13. 汉诺塔问题
def move(n, a, b, c):if(n == 1):print(a,"->",c)returnmove(n-1, a, c, b)move(1, a, b, c)move(n-1, b, a, c)
move(3, "a", "b", "c")
8、selenium面试题
-
如何判断一个页面上元素是否存在?
方法一:try-exceptdef is_element_exsist(driver, locator):'''判断元素是否存在,存在返回True,不存返回False:param locator: locator为元组类型,如("id", "yoyo"):return: bool值,True or False'''try:driver.find_element(*locator)return Trueexcept Exception as msg:print("元素%s找不到:%s" % (locator, msg))return Falseif __name__ == '__main__':loc1 = ("id", "yoyo") # 元素1print(is_element_exsist(driver, loc1))方法二:用elements定义一组元素方法
def is_element_exsist1(driver, locator):'''判断元素是否存在,存在返回True,不存返回False:param locator: locator为元组类型,如("id", "yoyo"):return: bool值,True or False'''eles = driver.find_elements(*locator)if len(eles) < 1:return Falseelse:return Trueif __name__ == '__main__':loc1 = ("id", "yoyo") # 元素1print(is_element_exsist1(driver, loc1))方法三:结合WebDriverWait和expected_conditions判断
from selenium import webdriver from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.ui import WebDriverWait def is_element_exsist2(driver, locator):'''结合WebDriverWait和expected_conditions判断元素是否存在,每间隔1秒判断一次,30s超时,存在返回True,不存返回False:param locator: locator为元组类型,如("id", "yoyo"):return: bool值,True or False'''try:WebDriverWait(driver, 30, 1).until(EC.presence_of_element_located(locator))return Trueexcept:return False if __name__ == '__main__':loc1 = ("id", "yoyo") # 元素1print(is_element_exsist2(driver, loc1)) -
如何提高脚本的稳定性?
- 使用分层结构实现业务逻辑、脚本、数据分离。
- 使用PO设计模式,将一个页面用到的元素和操作步骤封装在一个页面类中。如果一个元素定位发生了改变,我们只用修改这个页面的元素属性。
- 对于页面类的方法,我们尽量从客户的正向逻辑去分析,方法中是一个独立场景,例如:登录到退出,而且不要想着把所有的步骤都封装在一个方法中。
- 测试用例设计中,减少测试用例之间的耦合度。
- 元素定位时,使用稳定的相对路径来定位,优先选择id,避免使用绝对路径。
-
如何定位动态元素?
属性动态变化是指该element没有固定的属性值,所以只能通过相对位置定位
比如通过xpath的轴, parent/following-sibling/precent-sibling等
另外也可以尝试findbyelements遍历 -
如何通过子元素定位父元素?
通过获取文本的内容进行定位向上找 (//…) 这个是上一级driver.find_element_by_xpath('xpath', '//*[text()="北京分公司"]//..//../span') -
如何截取某一个元素的图片,不要截取全部图片
#selenium截全屏 driver.get_screenshot_as_file('D:\\baidu.png') # 把截取的图片存放在D盘 #截取某元素的图片 #安装pillow库 #pip install pillow from selenium import webdriver from PIL import Image driver = webdriver.Chrome() driver.get('http://www.baidu.com/')driver.save_screenshot('button.png') element = driver.find_element_by_id("su") print(element.location) # 打印元素坐标 print(element.size) # 打印元素大小left = element.location['x'] top = element.location['y'] right = element.location['x'] + element.size['width'] bottom = element.location['y'] + element.size['height']im = Image.open('button.png') im = im.crop((left, top, right, bottom)) im.save('button.png') -
平常遇到过哪些问题?如何解决的
iframe、等待时间等 -
一个元素明明定位到了,点击无效(也没报错),如果解决?
# js点击hidden元素 js = 'document.getElementById("baidu").click()' driver.execute_script(js) -
selenium中隐藏元素如何定位?(hidden、display: none)
# js点击hidden元素 js = 'document.getElementById("baidu").click()' driver.execute_script(js)
四、性能测试
找到一篇比较全面的整理,工具是jmeter方向的:https://my.oschina.net/u/3519247/blog/4448738
五、接口测试
1、接口测试常规面试题
-
为什么要做接口测试?
- 可以发现很多在页面上操作发现不了的bug
- 检查系统的异常处理能力
- 检查系统的安全性、稳定性
- 前端随便变,接口测好了,后端不用变
- 可以测试并发情况,一个账号,同时(大于2个请求)对最后一个商品下单,或不同账号,对最后一个商品下单
- 可以修改请求参数,突破前端页面输入限制(如金额)
-
你平常做接口测试的过程中发现过哪些bug?
-
平常你是怎么测试接口的?
通过性验证:正常的通过性测试
入参必填验证:参数是否必填
入参格式验证:参数的格式进行边界值、等价类测试
入参场景验证:正常业务功能、异常业务功能场景
接口权限验证:绕过身份授权(接口权限、数据权限的测试)、参数是否加密
接口性能验证:接口并发、响应时间等 -
平常用什么工具测接口的
postman、jmeter -
webService接口是如何测试的
webService接口用SoapUI

-
没有接口文档,如果做接口测试?
1.没有接口文档,那就需要先跟开发沟通,然后整理接口文档。
2.没有接口文档,可以抓包看接口请求参数,然后不懂的跟开发沟通。 -
在手工接口测试或者自动化接口测试的过程中,上下游接口有数据依赖如何处理?
用一个全局变量来处理依赖的数据,比如登录后返回token,其它接口都需要这个token,那就用全局变量来传token参数 -
依赖于第三方数据的接口如何进行测试?
mock
搭建mock服务:https://www.cnblogs.com/yoyoketang/p/9348552.html -
当一个接口出现异常时候,你是如何分析异常的?
1.抓包,用fiddler工具抓包,或者浏览器上f12,app上的话,那就用fiddler设置代理,去看请求报文和返回报文了
2.查看后端日志,xhell连上服务器,查看日志
3.查数据库 -
如何模拟弱网测试
fiddler和charles都可以模拟弱网测试,设置模拟丢包 -
如何分析一个bug是前端还是后端的?
抓包确认请求报文与接口文档定义是否一致,如果有问题可能是前端发送的数据不对,如果一致则继续确认返回报文是否与页面表现一致,如果有问题可能是后端返回的数据不正确。
2、接口自动化面试题
-
json和字典dict的区别?
dict是python种的基础数据类型之一
json本质上是字符串类型,是按key:value键值对的格式存储的字符串import json # a是字典dict a = {"a": 1, "b": 2, "c": True} # b是json b = '{"a": 1, "b": 2, "c": true}' print(type(a)) print(json.dumps(a)) # a转json#结果 <class 'dict'> {"a": 1, "b": 2, "c": true} <class 'str'> {'a': 1, 'b': 2, 'c': True} -
测试的数据你放在哪?
- 对于账号密码,这种管全局的参数,可以用命令行参数,单独抽出来,写的配置文件里(如ini)
- 对于一些一次性消耗的数据,比如注册,每次注册不一样的数,可以用随机函数生成
- 对于一个接口有多组测试的参数,可以参数化,数据放yaml,text,json,excel都可以
- 对于可以反复使用的数据,比如订单的各种状态需要造数据的情况,可以放到数据库,每次数据初始化,用完后再清理
- 对于邮箱配置的一些参数,可以用ini配置文件
- 对于全部是独立的接口项目,可以用数据驱动方式,用excel/csv管理测试的接口数据
- 对于少量的静态数据,比如一个接口的测试数据,也就2-3组,可以写到py脚本的开头,十年八年都不会变更的
-
什么是数据驱动,如何参数化?
数化的思想是代码用例写好了后,不需要改代码,只需维护测试数据就可以了,并且根据不同的测试数据生成多个用例
unittest的ddt、pytest的pytest.mark.parametrize -
下个接口请求参数依赖上个接口的返回数据
存变量、添加到临时文件、存excel、缓存等。 -
依赖于登录的接口如何处理?
token登录可以登录后把token存到配置文件
如果是cookies登录,使用requests.session自动关联 -
依赖第三方的接口如何处理
mock
搭建mock服务:https://www.cnblogs.com/yoyoketang/p/9348552.html -
不可逆的操作,如何处理,比如删除一个订单这种接口如何测试
造数据,直接测试环境数据库修改或者使用python连接修改 -
接口产生的垃圾数据如何清理
创建的时候最好用固定命名标识一下,比如autotestXXX等明显是测试数据标识,之后数据库清理比较好处理。
使用setUp做数据初始化,使用setDown做数据清理,如果不允许操作数据库可以直接掉删除接口清理。 -
一个订单的几种状态如何全部测到,如:未处理,处理中,处理失败,处理成功
造数据 -
python如何连接数据库操作?
# 1.安装 pip install pymysql import pymysql try:# 1.链接 数据库 链接对象 connection()conn = pymysql.Connect(host="localhost",port=3306,db='animal',user='root',passwd="mysql",charset='utf8')# 2. 创建 游标对象 cursor()cur = conn.cursor()# 增加一条数据 科目表--GO语言# insert_sub = 'insert into subjects values(0,"GO语言")'# result = cur.execute(insert_sub)# 修改# update_sub = 'update subjects set title="区块链" where id=7'# result = cur.execute(update_sub)# 删除# delete_sub = 'delete from stu where id=8'# result = cur.execute(delete_sub)delete_sub = 'select * from subjects where id=1'cur.execute(delete_sub)# result = cur.fetchall()result = cur.fetchone()print(result)# for res in result:## print(result)# 提交事务conn.commit()# 关闭游标cur.close()# 关闭链接conn.close() except Exception as e:print(e)
六、APP测试
1、什么是activity?
Activity一个应用程序的组件,它提供一个屏幕来与用户交互,以便做一些诸如打电话、发邮件和看地图之类的事情。
2、Activity生命周期?
-
运行(Active/Running):Activity处于活动状态,此时Activity处于栈顶,是可见状态,可以与用户进行交互
-
暂停(Paused):当Activity失去焦点时,或被一个新的非全面屏的Activity,或被一个透明的Activity放置在栈顶时,Activity就转化为Paused状态。此刻并不会被销毁,只是失去了与用户交互的能力,其所有的状态信息及其成员变量都还在,只有在系统内存紧张的情况下,才有可能被系统回收掉
-
停止(Stopped):当Activity被系统完全覆盖时,被覆盖的Activity就会进入Stopped状态,此时已不在可见,但是资源还是没有被收回
-
系统回收(Killed):当Activity被系统回收掉,Activity就处于Killed状态
3、Android四大组件
Android四大基本组件:Activity、BroadcastReceiver广播接收器、ContentProvider内容提供者、Service服务。
-
Activity:
应用程序中,一个Activity就相当于手机屏幕,它是一种可以包含用户界面的组件,主要用于和用户进行交互。一个应用程序可以包含许多活动,比如事件的点击,一般都会触发一个新的Activity。 -
BroadcastReceiver广播接收器:
应用可以使用它对外部事件进行过滤只对感兴趣的外部事件(如当电话呼入时,或者数据网络可用时)进行接收并做出响应。广播接收器没有用户界面。然而,它们可以启动一个activity或serice 来响应它们收到的信息,或者用NotificationManager来通知用户。通知可以用很多种方式来吸引用户的注意力──闪动背灯、震动、播放声音等。一般来说是在状态栏上放一个持久的图标,用户可以打开它并获取消息。 -
ContentProvider内容提供者:
内容提供者主要用于在不同应用程序之间实现数据共享的功能,它提供了一套完整的机制,允许一个程序访问另一个程序中的数据,同时还能保证被访问数据的安全性。只有需要在多个应用程序间共享数据时才需要内容提供者。例如:通讯录数据被多个应用程序使用,且必须存储在一个内容提供者中。它的好处:统一数据访问方式。 -
Service服务:
是Android中实现程序后台运行的解决方案,它非常适合去执行那些不需要和用户交互而且还要长期运行的任务(一边打电话,后台挂着QQ)。服务的运行不依赖于任何用户界面,即使程序被切换到后台,或者用户打开了另一个应用程序,服务扔然能够保持正常运行,不过服务并不是运行在一个独立的进程当中,而是依赖于创建服务时所在的应用程序进程。当某个应用程序进程被杀掉后,所有依赖于该进程的服务也会停止运行(正在听音乐,然后把音乐程序退出)。
原文:https://blog.csdn.net/m0_37989980/article/details/78681367
4、app测试和web测试有什么区别?
WEB测试和App测试从流程上来说,没有区别。
都需要经历测试计划方案,用例设计,测试执行,缺陷管理,测试报告等相关活动。
从技术上来说,WEB测试和APP测试其测试类型也基本相似,都需要进行功能测试、性能测试、安全性测试、GUI测试等测试类型。
他们的主要区别在于具体测试的细节和方法有区别,比如:性能测试,在WEB测试只需要测试响应时间这个要素,在App测试中还需要考虑流量测试和耗电量测试。
-
兼容性测试:在WEB端是兼容浏览器,在App端兼容的是手机设备。而且相对应的兼容性测试工具也不相同,WEB因为是测试兼容浏览器,所以需要使用不同的浏览器进行兼容性测试(常见的是兼容IE6,IE8,chrome,firefox)如果是手机端,那么就需要兼容不同品牌,不同分辨率,不同android版本甚至不同操作系统的兼容。(常见的兼容方式是兼容市场占用率前N位的手机即可),有时候也可以使用到兼容性测试工具,但WEB兼容性工具多用IETester等工具,而App兼容性测试会使用Testin这样的商业工具也可以做测试。
-
安装测试:WEB测试基本上没有客户端层面的安装测试,但是App测试是存在客户端层面的安装测试,那么就具备相关的测试点。
还有,App测试基于手机设备,还有一些手机设备的专项测试。如交叉事件测试,操作类型测试,网络测试(弱网测试,网络切换) -
交叉事件测试:就是在操作某个软件的时候,来电话、来短信,电量不足提示等外部事件。
-
操作类型测试:如横屏测试,手势测试
-
网络测试:包含弱网和网络切换测试。需要测试弱网所造成的用户体验,重点要考虑回退和刷新是否会造成二次提交。弱网络的模拟,据说可以用360wifi实现设置。
-
从系统架构的层面,WEB测试只要更新了服务器端,客户端就会同步会更新。而且客户端是可以保证每一个用户的客户端完全一致的。但是APP端是不能够保证完全一致的,除非用户更新客户端。如果是APP下修改了服务器端,意味着客户端用户所使用的核心版本都需要进行回归测试一遍。
-
还有升级测试:升级测试的提醒机制,升级取消是否会影响原有功能的使用,升级后用户数据是否被清除了。
原文地址:https://www.cnblogs.com/laoluoits/p/5673291.html
5、android和ios测试区别?
App测试中ios和Android有哪些区别呢?
- Android长按home键呼出应用列表和切换应用,然后右滑则终止应用;
- 多分辨率测试,Android端20多种,ios较少;
- 手机操作系统,Android较多,ios较少且不能降级,只能单向升级;新的ios系统中的资源库不能完全兼容低版本中的ios系统中的应用,低版本ios系统中的应用调用了新的资源库,会直接导致闪退(Crash);
- 操作习惯:Android,Back键是否被重写,测试点击Back键后的反馈是否正确;应用数据从内存移动到SD卡后能否正常运行等;
- push测试:Android:点击home键,程序后台运行时,此时接收到push,点击后唤醒应用,此时是否可以正确跳转;ios,点击home键关闭程序和屏幕锁屏的情况(红点的显示);
- 安装卸载测试:Android的下载和安装的平台和工具和渠道比较多,ios主要有app store,iTunes和testflight下载;
- 升级测试:可以被升级的必要条件:新旧版本具有相同的签名;新旧版本具有相同的包名;有一个标示符区分新旧版本(如版本号),
对于Android若有内置的应用需检查升级之后内置文件是否匹配(如内置的输入法)
另外:对于测试还需要注意一下几点:
-
并发(中断)测试:闹铃弹出框提示,另一个应用的启动、视频音频的播放,来电、用户正在输入等,语音、录音等的播放时强制其他正在播放的要暂停;
-
数据来源的测试:输入,选择、复制、语音输入,安装不同输入法输入等;
-
push(推送)测试:在开关机、待机状态下执行推送,消息先死及其推送跳转的正确性;
应用在开发、未打开状态、应用启动且在后台运行的情况下是push显示和跳转否正确;
推送消息阅读前后数字的变化是否正确;
多条推送的合集的显示和跳转是否正确; -
分享跳转:分享后的文案是否正确;分享后跳转是否正确,显示的消息来源是否正确;
-
触屏测试:同时触摸不同的位置或者同时进行不同操作,查看客户端的处理情况,是否会crash等
原文链接:https://www.jianshu.com/p/91d7acfb036e
6、app出现ANR,是什么原因导致的?
那么导致ANR的根本原因是什么呢?简单的总结有以下两点:
- 主线程执行了耗时操作,比如数据库操作或网络编程
- 其他进程(就是其他程序)占用CPU导致本进程得不到CPU时间片,比如其他进程的频繁读写操作可能会导致这个问题。
细分的话,导致ANR的原因有如下几点:
- 耗时的网络访问
- 大量的数据读写
- 数据库操作
- 硬件操作(比如camera)
- 调用thread的join()方法、sleep()方法、wait()方法或者等待线程锁的时候
- service binder的数量达到上限
- system server中发生WatchDog ANR
- service忙导致超时无响应
- 其他线程持有锁,导致主线程等待超时
- 其它线程终止或崩溃导致主线程一直等待。
原文:https://blog.csdn.net/jaychou_maple/article/details/78782822
7、App出现crash原因有哪些?
- 内存管理错误:可能是可用内存过低,app所需的内存超过设备的限制,app跑不起来导致App crash。
或是内存泄露,程序运行的时间越长,所占用的内存越大,最终用尽全部内存,导致整个系统崩溃。
亦或非授权的内存位置的使用也可能会导致App crash。 - 程序逻辑错误:数组越界、堆栈溢出、并发操作、逻辑错误。
e.g. app新添加一个未经测试的新功能,调用了一个已释放的指针,运行的时候就会crash。 - 设备兼容:由于设备多样性,app在不同的设备上可能会有不同的表现。
- 网络因素:可能是网速欠佳,无法达到app所需的快速响应时间,导致app crash。或者是不同网络的切换也可能会影响app的稳定性。
原文:https://blog.csdn.net/yangtuxiaojie/article/details/47123243
8、app对于不稳定偶然出现anr和crash时候你是怎么处理的?
-
方法一:app开发保存错误日志到本地
一般app开发在debug版本,出现anr和crash的时候会自动把日志保存到本地实际的sd卡上,去对应的app目录取出来就可以了 -
方法二:实时抓取
当出现偶然的crash时候,这时候可以把手机拉到你们app开发那,手机连上他的开发代码的环境,有ddms会抓日志,这时候出现crash就会记录下来日志。
尽量重复操作让bug复现就可以了
也可以自己开着logcat,保存日志到电脑本地,参考这篇:https://www.cnblogs.com/yoyoketang/p/9101365.html
adb logcat | find "com.sankuai.meituan" >d:\hello.txt -
方法三:第三方sdk统计工具
一般接入了第三方统计sdk,比如友盟统计,在友盟的后台会抓到报错的日志
9、app的日志如何抓取?
-
app本身的日志,可以用logcat抓取,参考这篇:https://www.cnblogs.com/yoyoketang/p/9101365.html
adb logcat | find "com.sankuai.meituan" >d:\hello.txt -
也可以用ddms抓取,手机连上电脑,打开ddms工具,或者在Android Studio开发工具中,打开DDMS
关于ddms更多的功能,参考这篇:https://www.cnblogs.com/gaobig/p/5029381.html
10、logcat查看日志步骤
以下操作是基于windows平台的操作:adb logcat | find
linux平台的操作可以把find改成grep: adb logcat | grep
windows上的dos里面是没grep指令的
-
logcat输出日志
1.把日志存入手机sdcard某个目录(前提是这个目录要是存在的)
adb logcat -f /sdcard/xx/xxx.txt
备注:-f将日志输出到文件
上面这个指令在真机上(未root)是会报错的,提示没操作权限,在模拟器上可以执行
2.把日志存入电脑的某个目录,如d:\debug
adb logcat >d:debug\yoyo.txt -
find过滤包名
1.如果直接用adb logcat抓日志的话,会把系统的一些其他无关紧要的都抓出来,如果只想抓取被测app的日志,那就根据包名过滤
adb logcat | find "com.sankuai.meituan" >d:\hello.txt -
结束logcat
1.结束logcat抓包,可以用ctr+c快捷键结束, 这个是通过手工的快捷键操作完成
2.也可以先查询到logcat的pip,再kill掉
adb shell ps | findstr logcat
adb shell kill -9 [logcatpid]
注意:kill操作在模拟器上是可以的,真机上没权限
11、你平常会看日志吗, 一般会出现哪些异常
常见的几种如下:
- NullPointerException - 空指针引用异常
- ClassCastException - 类型强制转换异常。
- IllegalArgumentException - 传递非法参数异常。
- ArithmeticException - 算术运算异常
- ArrayStoreException - 向数组中存放与声明类型不兼容对象异常
- IndexOutOfBoundsException - 下标越界异常
- NegativeArraySizeException - 创建一个大小为负数的数组错误异常
- NumberFormatException - 数字格式异常
- SecurityException - 安全异常
- UnsupportedOperationException - 不支持的操作异常
七、数据库
1、sql查询
1. 排序order by
查询所有学生的数学成绩,显示学生姓名name, 分数, 由高到低
SELECT a.name, b.score
FROM student a, grade b
WHERE a.id = b.id
AND kemu = '数学'
ORDER BY score
DESC
2. 统计总成绩sum
统计每个学生的总成绩,显示字段:姓名,总成绩
SELECT a.name, sum(b.score) as sum_score
FROM student a, grade b
WHERE a.id = b.id
GROUP BY name
DESC
3. 统计总成绩
统计每个学生的总成绩(由于学生可能有重复名字),显示字段:学生id,姓名,总成绩
SELECT a.id, a.name, c.sum_score
from student a,
(SELECT b.id, sum(b.score) as sum_score
FROM grade b
GROUP BY id
) c
WHERE a.id = c.id
ORDER BY sum_score
DESC
4. 统计单科最好成绩
列出各门课程成绩最好的学生, 要求显示字段: 学号,姓名,科目,成绩
SELECT c.id , a.name, c.kemu, c.score
FROM grade c, student a,
(SELECT b.kemu, MAX(b.score) as max_score
FROM grade b
GROUP BY kemu) t
WHERE c.kemu = t.kemu
AND c.score = t.max_score
AND a.id = c.id
5.各门课程成绩最好的2位学生
列出各门课程成绩最好的2位学生, 要求显示字段: 学号,姓名, 科目,成绩
SELECT t1.id, a.name, t1.kemu,t1.score
FROM grade t1, student a
WHERE(SELECT count(*) FROM grade t2 WHERE t1.kemu=t2.kemu AND t2.score>t1.score)<=2
and a.id = t1.id
ORDER BY t1.kemu,t1.score
DESC
6. 计算学生平均分数
计算每个人的平均成绩, 要求显示字段: 学号,姓名,平均成绩
select a.id, a.name, c.avg_score
from student a,
(select b.id, avg(b.score) as avg_score
from grade b
group by b.id
)c
where a.id = c.id
7. 统计各科目成绩
计算每个人的成绩,总分数,平均分,要求显示:学号,姓名,语文,数学,英语,总分,平均分
使用case when 语法把科目字段分解成具体的科目:语文,数学, 英语
SELECT a.id as 学号, a.name as 姓名,
sum(case when b.kemu='语文' then score else 0 end) as 语文,
sum(case when b.kemu='数学' then score else 0 end) as 数学,
sum(case when b.kemu='英语' then score else 0 end) as 英语,
sum(b.score) as 总分 ,
sum(b.score)/count(b.score) as 平均分
FROM student a, grade b
where a.id = b.id
GROUP BY b.id, b.id
8. 每门课程平均成绩
列出各门课程的平均成绩,要求显示字段:课程,平均成绩
select b.kemu, avg(b.score)
from grade b
group by b.kemu
9. 成绩排名
列出数学成绩的排名, 要求显示字段:学号,姓名,成绩,排名
在查询结果表里面添加一个变量@paiming,让它自动加1
SELECT
t.id, a.name,t.score as 数学分数, @paiming := @paiming+1 as 排名
FROM(SELECT b.id, b.scoreFROM grade bWHERE b.kemu = '数学'ORDER BY score DESC) AS t,(SELECT @paiming := 0) r,student a
WHERE a.id = t.id
10. 同结果名次相同
上图由于同一个分数的小伙伴,排名不一样,本着公平、公正、公开的原则,同一分数名次一样
SELECT
t.id, a.name,t.score as 数学分数,
(CASE
WHEN @temp = t.score THEN@paiming
WHEN @temp := t.score THEN@paiming :=@paiming + 1
WHEN @temp = 0 THEN@paiming :=@paiming + 1
END) AS numFROM(SELECT b.id, b.scoreFROM grade bWHERE b.kemu = '数学'ORDER BY score DESC) AS t,(SELECT @paiming := 0, @temp := 0) r,student a
WHERE a.id = t.id
排名相同的占个名次
SELECT obj.id, obj.score as 数学,@rownum := @rownum + 1 AS num_tmp,@incrnum := (CASE
WHEN @rowtotal = obj.score THEN@incrnum
WHEN @rowtotal := obj.score THEN@rownum
END) AS 排名FROM
(SELECT id, score
FROM grade
WHERE kemu = "数学"
ORDER BY
score DESC
) AS obj,
(SELECT @rownum := 0 ,@rowtotal := NULL ,@incrnum := 0) r
11. 查询前3名
列出数学成绩前3名的学生(要求显示字段:学号,姓名, 科目,成绩)
select a.id, a.name, b.kemu, b.score
from student a, grade b
where a.id = b.id
and kemu = '数学'
order by score
desc
limit 3
12. 查询第2-3名记录
查询数学成绩第2和第3名的学生
select a.id, a.name, b.kemu, b.score
from student a, grade b
where a.id = b.id
and kemu = '数学'
order by score
desc
limit 1, 2
13. 查询第3到后面所有的
查询第3名到后面所有的学生数学成绩
注意:有些资料上写的limit 2, -1 用-1代码最大值,这个是不对的,会报错,解决办法:随便写个非常大的整数
select a.id, a.name, b.kemu, b.score
from student a, grade b
where a.id = b.id
and kemu = '数学'
order by score
desc
limit 2, 10000
14. 查询每门课都大于80 分的学生姓名
SELECT name
FROM xuesheng
GROUP BY name
HAVING MIN(score)> 80
2、sql链接查询
1. 内连接:a表与b表共有数据
select *
from userinfo
inner join score
on userinfo.id=score.id;
2. 左连接:如果b表的某行在a表中没有匹配行,则将为b表返回空值左连
select *
from userinfo
left join score
on userinfo.id=score.id;
3. 右连接:如果a表的某行在b表中没有匹配行,则将为a表返回空值右连
select *
from userinfo
right join score
on userinfo.id=score.id;
4. 内连接的三表查询
select t1.username,t2.classname,t3.mark
from(userinfo t1 inner join score t3 on t1.id=t3.id)
inner join class t2
on t2.classid=t3.classid;
3、做成函数调用
函数
create procedure mark_sum(in num int)
begin
selece t1.username,sum(t3.mark) from userinfo t1,class t2,score t3 where t1.id=t3.id and t2.classid=t3.classid group by t1.username and t1.id=num;
end
调用:call mark_sum(1);
八、安全/渗透测试
1.用户访问认证
2.传输数据加密
3.安全防护策略:如安全日志、入侵检测、隔离防护、漏洞扫描
4.数据备份与恢复
5.防病毒系统
6.SQL注入、JS注入
关于安全测试最全面的介绍请参考:https://www.cnblogs.com/blogst/p/9241952.html