大数据原理与应用教材链接:大数据技术原理与应用电子课件-林子雨编著
Hadoop伪分布式安装借鉴文章:Hadoop伪分布式安装-比课本详细
大数据 | (二)SSH连接报错Permission denied:SSH连接报错Permission denied
哈喽,大家好!本期给大家带来的是Hadoop的伪分布式安装。
随着大数据时代的到来,“大数据”已经成为互联网信息技术行业的流行词汇。
而随着Hadoop的发展,Hadoop也逐渐成为大数据的代名词。
一、Hadoop概述
1.1 Hadoop简介
Hadoop是apache软件基金会旗下的一个开源分布式计算平台,为用户提供系统底层细节透明的分布式基础架构。
Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且开源部署在廉价的计算机集群中。Hadoop的核心是HDFS(Hadoop分布式文件系统)和MapReduce(一种编程模型)
1.2 Hadoop特性
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:
- 高可靠性。即使一个副本发生鼓掌,其他副本也可以保证正常对外提供服务。
- 高效性。Hadoop采用分布式存储和分布式处理两大核心技术,能够高效的处理PB级数据
- 高可扩展性。Hadoop可以扩展到数以千计的计算机节点上。
- 高容错性。采用数据冗余存储方式,自动保存数据的多个副本。
- 成本低。Hadoop采用廉价的计算机集群
- 运行在Linux系统上。Hadoop基于Java语言开发,可以较好的运行在Linux上
- 支持多种编程语言。Hadoop上的应用程序也可以使用其他语言编写,如C++。
1.3 Hadoop应用现状
国内采用Hadoop的公司主要有百度、淘宝、网易、华为、中国移动等,其中淘宝的计算机集群比较大。
1.4 Hadoop版本
Apache Hadoop版本分为三代、分别时Hadoop1.0、Hadoop2.0、Hadoop3.0。除了免费开源的Apache Hadoop以外,还有一些商业公司推出的Hadoop发行版。2008年,Cloudera成为第一个Hadoop商业化公司,并在2009年推出第一个Hadoop发行版。
二、Hadoop生态系统
经过多年的发展,Hadoop生态系统不断完善和成熟,目前已经包含了多个子项目,除了核心的HDFS和MapReduce以外,Hadoop生态系统还包括ZooKeeper、HBase、Hive、Pig、Mahout、Flume、Sqoop、Ambari等功能组件。
三、Hadoop的安装和使用
3.1 更新apt和安装vim编辑器
首先使用如下命令更新软件包:
sudo apt-get update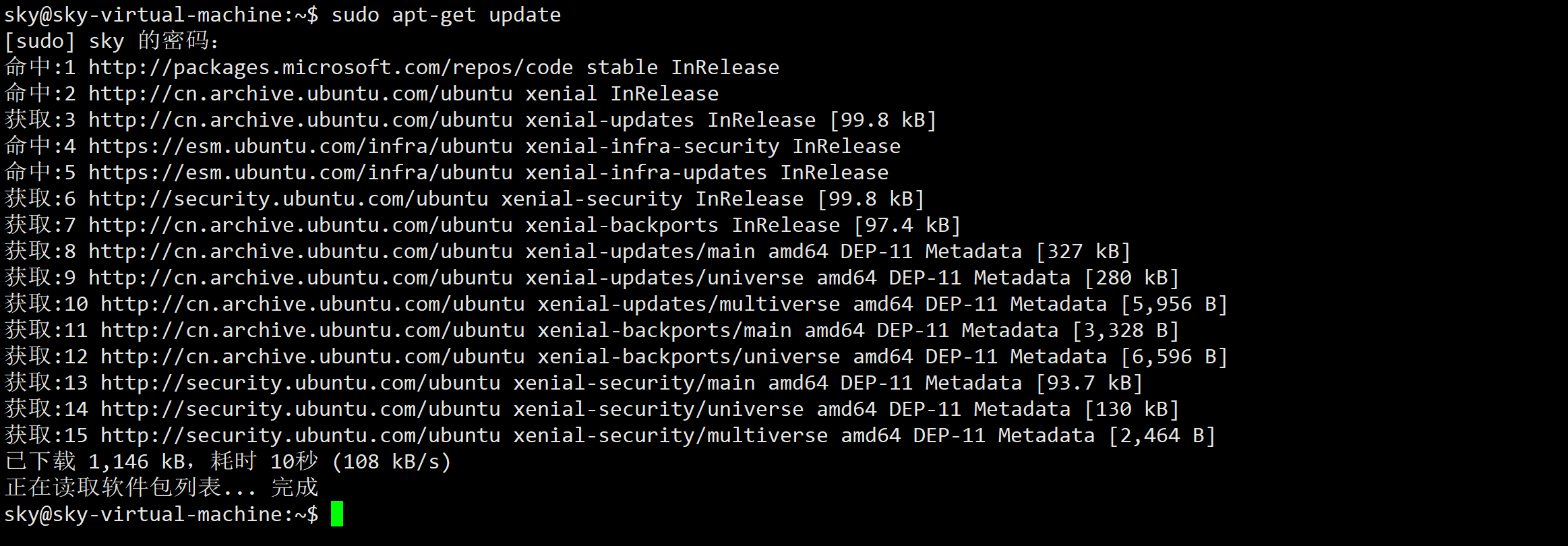
然后安装 Vim 编辑器:
sudo apt-get install vim
3.2 安装SSH并配置SSH免密登录
使用如下命令安装SSH-Server:
sudo apt-get install openssh-server之后可以使用如下命令,并输入登录到本机:
ssh localhost输入如下命令退出登录:
exit使用命令进入到如下目录:
cd ~/.ssh/生成公钥和私钥:
ssh-keygen -t rsa此时 ls ,可以看到文件夹下有这些目录:

之后再使用如下命令,就可以直接登录了!
ssh localhost如果遇到SSH免密登录报错,请参考博主的这篇文章,因为篇幅原因将这个错误独立开来,方便大家查看。SSH连接报错Permission denied
3.3 安装Java环境
如果你之前安装过JDK,可以使用如下命令查看JAVA_HOME(JDK的安装路径),输入Java,javac等检测,并跳过这个步骤。
echo $JAVA_HOME如果之前没有安装过JDK,请继续往下看。
首先从官网或博主的百度网盘下载JDK8压缩包:
官网下载地址:JDK8Linux压缩包下载地址
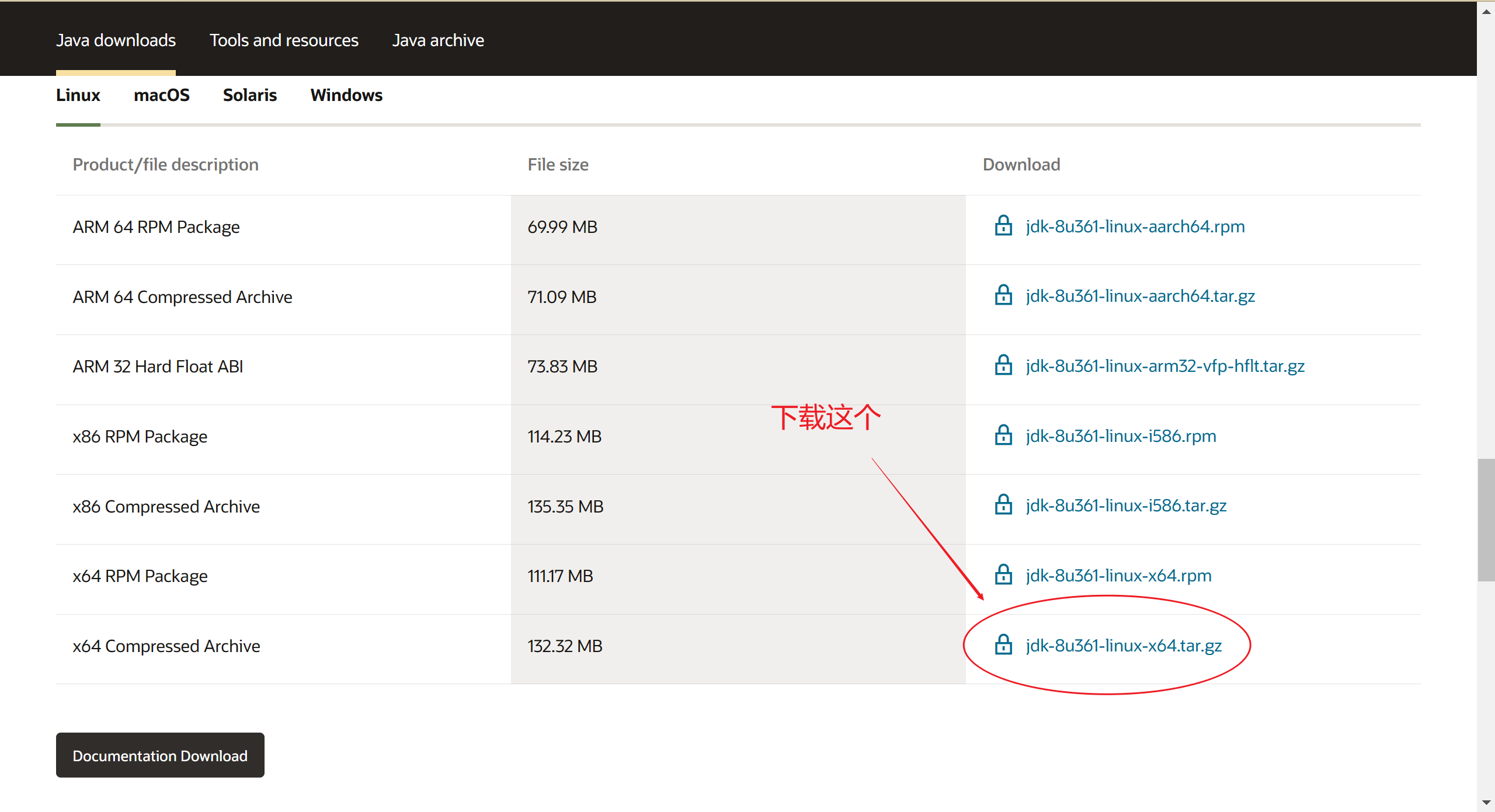
百度网盘下载地址:百度网盘JDK8Linux压缩包下载地址
通过 xftp 或 lrzsz 传输到Linux系统上,并解压到当前文件夹:
tar -xzvf jdk-8u202-linux-x64.tar.gz
配置环境变量:
vim ~/.bashrc按 i 进入插入模式,在文件开头输入以下内容:

按下esc,然后输入冒号,wq保存退出。
刷新配置:
source ~/.bashrc使用如下命令测试是否安装成功:
java -version如果出现类似下面的结果,就说明安装成功了!

3.4 安装单机Hadoop
下载Hadoop,可以在官网下载,也可以在博主的百度网盘下载,这里选择的Hadoop版本是3.1.3。
Hadoop官网下载:Hadoop官网下载地址
百度网盘下载地址:Hadoop百度网盘下载地址
然后将安装包上传到Linux服务器,并使用如下命令解压:
tar -xzvf hadoop-3.1.3.tar.gz解压后得到这个Hadoop-3.1.3这个文件夹,但是这里我改文件名了
改文件名命令:
mv hadoop-3.1.3 hadoop 现在可以运行如下命令,查看Hadoop是否安装成功:
现在可以运行如下命令,查看Hadoop是否安装成功:
./bin/hadoop version至此,安装Hadoop完成,下面进行Hadoop的伪分布式安装(重要!)
3.5 Hadoop伪分布式安装
首先修改两个配置文件,分别是core-site.xml文件和hdfs-site.xml文件,进入到hadoop目录下的etc/hadoop目录,执行下面的操作。
修改core-site.xml文件内容如下:
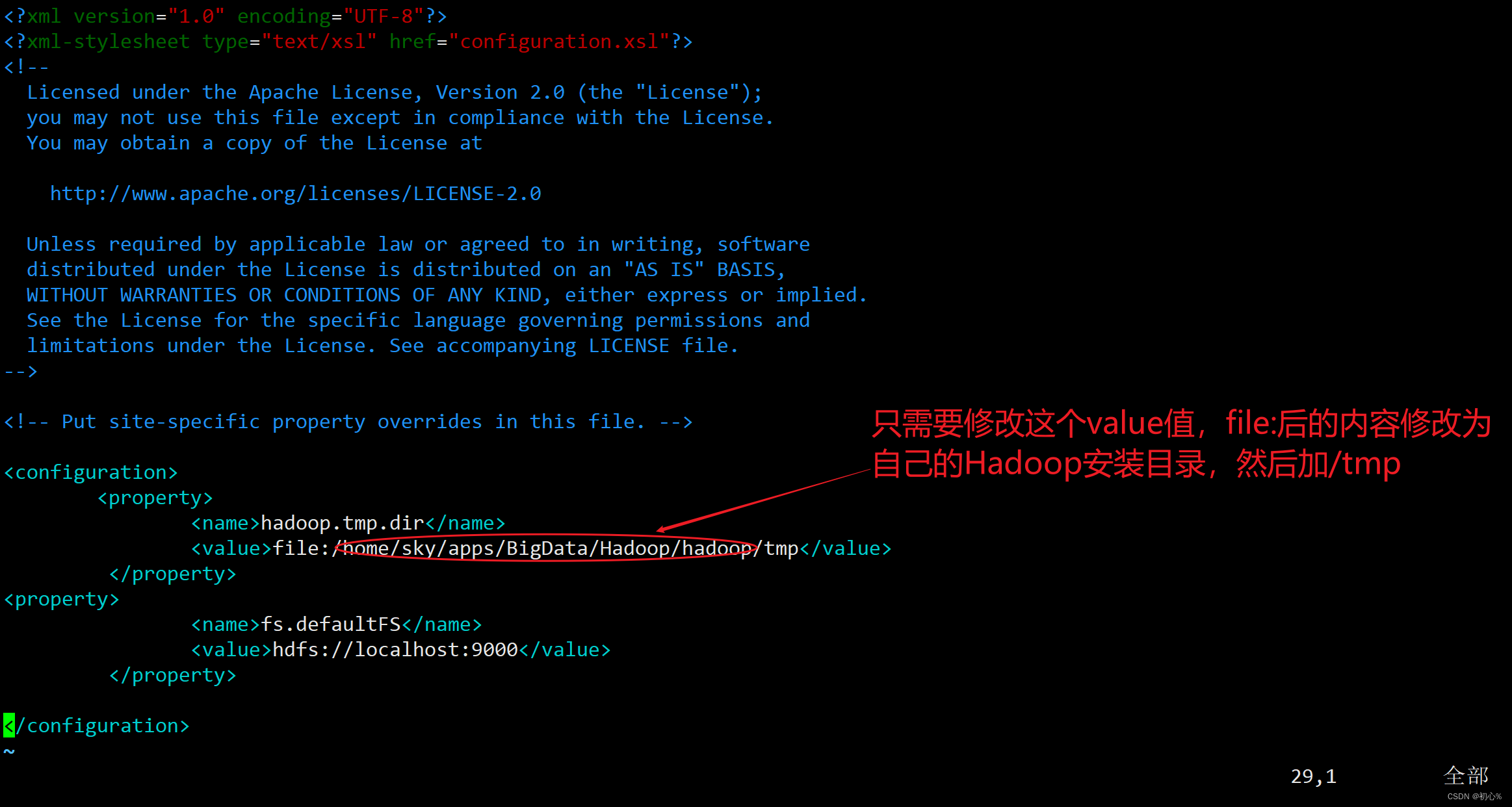
修改core-site.xml文件内容如下:
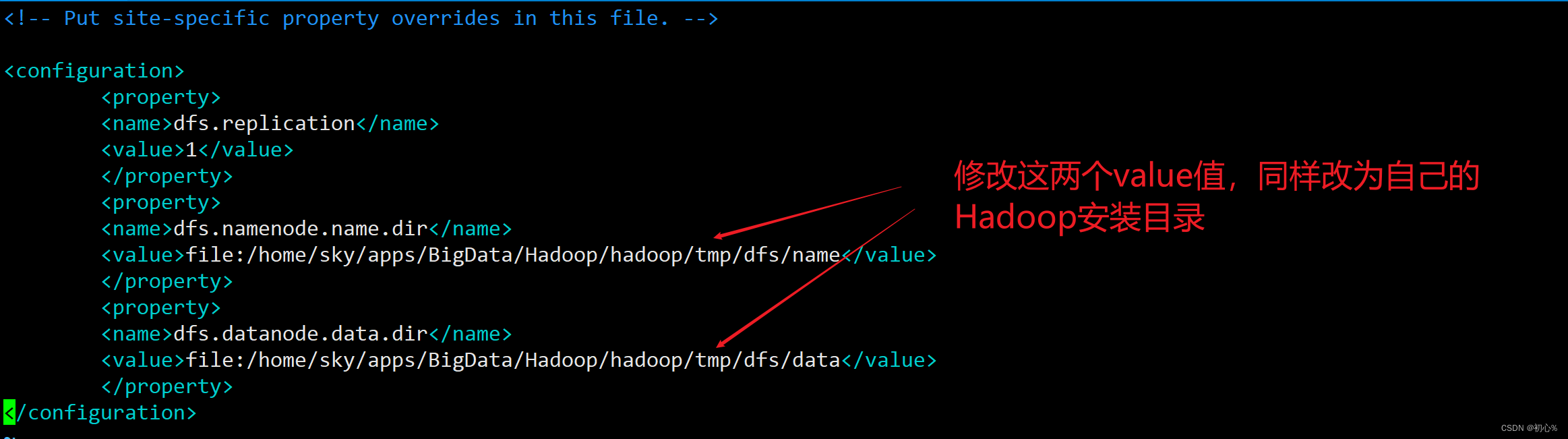
进入到hadoop目录下,之后执行如下命令:
./bin/hdfs namenode -format执行完之后,如果没有报错类似于Java报错的内容,说明Hadoop伪分布式安装就成功了!
因为这个Hadoop格式化只能执行一次,博主在这之前已经执行过,所以这里不再演示执行结果。
附上一些操作过程中可能用到的命令:
查看文件权限:
ls -l 文件名用户操作:
列出所有的用户
cat /ect/passwd删除用户:
userdel -r 用户名添加用户:
sudo useradd -m 用户名切换用户:
su写在最后:
大数据作为一种近几年才兴起的技术,对科学研究、思维方式、社会发展、就业市场和人才培养都有重要的影响。希望大家能从Hadoop安装这个里程,开始自己的大数据之旅吧!共勉!