这里全部内容都是由这个网址转载过来的。
https://tech.youmi.net/2016/07/163347168.html
解说:
关于算法的完成。需要看很多的文章和视频才能有更好的理解和领悟。这里就随便点一下。
1,FPGA作为部署终端,只执行前向传导任务。并不执行反向传导。
2,前向传导,只有乘法和加法。z(2)=w(2)a(1)+b(2)z(2)=w(2)a(1)+b(2) 。
3,最常用的层有卷积层,全连接层,最大池化,激活函数,正则化等。 目前来说卷积层和全连接层问题不大。主要是激活函数,正则化等处理在FPGA上的实现。
有兴趣相关技术的人可以看个人介绍和我毛华望联系。
----------------------------------
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,每个神经元都只影响邻层的一部分神经元,具有局部感受野,因此,网络具有极强的捕捉局部特征的能力;另一方面,通过权值共享和池化,显著地降低了网络的计算复杂度,使得CNN得到广泛应用。CNN是图像分类和语音识别领域的杰出算法,也是目前大部分计算机视觉系统的核心技术,从facebook的图像自动标签到自动驾驶汽车,乃至AlphaGo都在使用。与此同时,近两年CNN逐渐被应用于NLP任务,在sentence classification中,基于CNN的模型取得了非常显著的效果。
本文假设读者比较熟悉神经网络的相关知识,特别是反向传播算法的过程,从数学推导的角度来理解CNN的内部原理。
1 神经网络
神经网络是由多个感知器(神经元)构成的全连接的网络,本质上来说,这样的连接只是简单的线性加权和而已,所以每个神经元加上同一个非线性函数(如sigmoid,tanh等),使得网络能拟合非线性。通常,称这个非线性函数为激活函数。一个典型的全连接神经网络如下所示: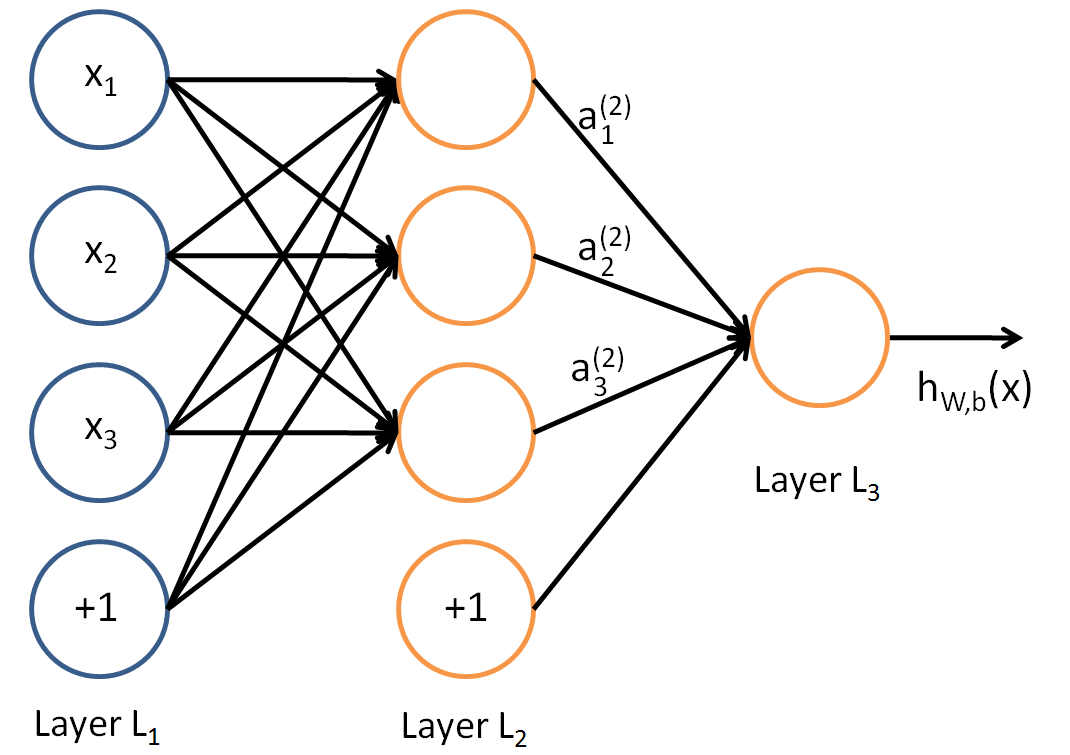
1.1 前向传导
上图中,每个圆圈代表一个神经元(标上“+1”的是偏置节点,不算入神经元),从神经元引出的连接是参数矩阵w,从偏置节点引出的是参数向量b。w和b是整个网络最重要的参数。
1.1.1 输入层
假设输入x=[x1,x2,x3]x=[x1,x2,x3],令第一层的输入z(1)z(1)和激活输出a(1)a(1)相等,即z(1)=a(1)=xz(1)=a(1)=x。
1.1.2 隐藏层
第二层的输入为:
z(2)1=a(1)1w(2)11+a(1)2w(2)12+a(1)3w(2)13+b(2)1z(2)2=a(1)1w(2)21+a(1)2w(2)22+a(1)3w(2)23+b(2)2z(2)3=a(1)1w(2)31+a(1)2w(2)32+a(1)3w(2)33+b(2)3z1(2)=a1(1)w11(2)+a2(1)w12(2)+a3(1)w13(2)+b1(2)z2(2)=a1(1)w21(2)+a2(1)w22(2)+a3(1)w23(2)+b2(2)z3(2)=a1(1)w31(2)+a2(1)w32(2)+a3(1)w33(2)+b3(2)
用向量简洁表达为:
z(2)=w(2)a(1)+b(2)z(2)=w(2)a(1)+b(2)
其中,z(2)∈R3×1,w(2)∈R3×3,a(1)∈R3×1,b(2)∈R3×1z(2)∈R3×1,w(2)∈R3×3,a(1)∈R3×1,b(2)∈R3×1
第二层的激活输出为:
a(2)=f(z(2))a(2)=f(z(2))
其中,ff为激活函数,a(2)∈R3×1a(2)∈R3×1。
1.1.3 输出层
第三层输入:
z(3)=w(3)a(2)+b(3)z(3)=w(3)a(2)+b(3)
其中,z(3)∈R1×1,w(3)∈R1×3,a(2)∈R3×1,b(3)∈R1×1z(3)∈R1×1,w(3)∈R1×3,a(2)∈R3×1,b(3)∈R1×1
第三层激活输出:
a(3)=f(z(3))a(3)=f(z(3))
其中,ff为激活函数,a(3)∈R1×1a(3)∈R1×1。特别地,记a(3)a(3)为hw,b(x)hw,b(x)
1.1.4 前向传导
因此,前向传导可以表示为:
z(l+1)=w(l+1)a(l)+b(l+1)a(l+1)=f(z(l+1))z(l+1)=w(l+1)a(l)+b(l+1)a(l+1)=f(z(l+1))
其中,l=1,2,...,L−1l=1,2,...,L−1,LL为神经网络的层数。
1.2 反向传播
假设神经网络的代价函数为:
J(w,b)=1m∑i=1mJ(w,b;x(i),y(i))其中:J(w,b;x(i),y(i))=12(y(i)−hw,b(x(i)))2J(w,b)=1m∑i=1mJ(w,b;x(i),y(i))其中:J(w,b;x(i),y(i))=12(y(i)−hw,b(x(i)))2
即,网络的整体代价为所有训练样例的平均代价。
此处我们是要找到最佳的w,b使得J(w,b)J(w,b)即代价函数的值最小,因此JJ是关于w,bw,b的函数,其中w,bw,b也不是标量,是很多wij,biwij,bi的集合。代价函数中没有显式的看到w,bw,b的表达式,那是因为用简洁的hw,b(x(i))hw,b(x(i))替换了。因此要强调的是:JJ的展开表达式(假设能展开)中只有w,bw,b才是变量,其他都是已知的。
因此,根据梯度下降法的思想,对于每个w(l)ij,b(l)ijwij(l),bij(l),我们只要往负梯度方向更新就可以了,即:
w(l)ij:=w(l)ij−α∂J∂w(l)ijb(l)ij:=b(l)ij−α∂J∂b(l)ijwij(l):=wij(l)−α∂J∂wij(l)bij(l):=bij(l)−α∂J∂bij(l)
向量化表达即为:
w(l):=w(l)−α∂J∂w(l)b(l):=b(l)−α∂J∂b(l)w(l):=w(l)−α∂J∂w(l)b(l):=b(l)−α∂J∂b(l)
其中,αα是学习率。
因此,只要能求出w,bw,b的偏导数就能迭代更新,从而完成整个算法。看似简单,但却困难。因为J(w,b)J(w,b)是很难写出显式表达式的,从而很难对每个wij,bijwij,bij都求出偏导,主要原因是网络是分层的进而w,bw,b也是分层,这才导致了偏导的难求,从而才有了反向传播。
既然w,bw,b是分层的,那么很自然地也可以分层地求w,bw,b的偏导。那么很自然的,需要找到一个递推的结构来表达偏导。观察到前向传导中的结构z(l+1)=w(l+1)a(l)+b(l+1)z(l+1)=w(l+1)a(l)+b(l+1),只要求出z(l+1)z(l+1)的偏导,自然就可以求出w(l+1),b(l+1)w(l+1),b(l+1)的偏导(矩阵、向量的求导形式类似标量,a(l)a(l)视为常量)。
考虑单个样例的情形,当ll为输出层时(l=3),有:
δ(3)=∂J∂z(3)=∂∂z(3)12(y−h(x))2=∂∂z(3)12(y−a(3))2 =∂∂z(3)12(y−f(z(3)))2=(y−h(x))∘f′(z(3))δ(3)=∂J∂z(3)=∂∂z(3)12(y−h(x))2=∂∂z(3)12(y−a(3))2 =∂∂z(3)12(y−f(z(3)))2=(y−h(x))∘f′(z(3))
其中,∘∘是按元素(element-wise)相乘。
当ll为非输出层(隐藏层)时(l=2),有:
δ(2)=∂J∂z(2)=∂J∂z(3)⋅∂z(3)∂z(2)=δ(3)⋅∂z(3)∂z(2) =δ(3)⋅∂∂z(2)[w(2)f(z(2))+b(2)]=w(2)f′(z(2))∘δ(3)δ(2)=∂J∂z(2)=∂J∂z(3)⋅∂z(3)∂z(2)=δ(3)⋅∂z(3)∂z(2) =δ(3)⋅∂∂z(2)[w(2)f(z(2))+b(2)]=w(2)f′(z(2))∘δ(3)
因此:
δ(L)=(y−h(x))⋅a(L)δ(l)=w(l)a(l)⋅ δ(l+1),(l=2,...,L−1)δ(L)=(y−h(x))⋅a(L)δ(l)=w(l)a(l)⋅ δ(l+1),(l=2,...,L−1)
所以:
∂J∂w(l)=∂J∂z(l)⋅∂z(l)∂w(l)=δ(l)⋅(a(l−1))T∂J∂b(l)=∂J∂z(l)⋅∂z(l)∂b(l)=δ(l),(l=2,...,L)∂J∂w(l)=∂J∂z(l)⋅∂z(l)∂w(l)=δ(l)⋅(a(l−1))T∂J∂b(l)=∂J∂z(l)⋅∂z(l)∂b(l)=δ(l),(l=2,...,L)
2 卷积神经网络
2.1 卷积
假设有矩阵A3×3A3×3和B2×2B2×2:
A=⎡⎣⎢147258369⎤⎦⎥B=[1324]A=[123456789]B=[1234]
那么B卷积A的结果就是让 B 在矩阵 A 上滑动,换言之,就是 B 与 A 的所有2 × 2连续子矩阵做“对应元素积之和”运算,所以,此时的结果 C 应该为:
C=[37674777]C=[37476777]
因此,假设 A 的大小为ha×waha×wa,B的大小为hb×wbhb×wb(其中ha≥hb,wa≥wbha≥hb,wa≥wb),则C的大小为(ha−hb+1)×(wa−wb+1)(ha−hb+1)×(wa−wb+1),矩阵B称为卷积核或滤波器(filter),矩阵C称为特征图(feature map)。上述运算称为窄卷积,若矩阵A预先上下各添加hb−1hb−1行零向量,左右各添加wb−1wb−1列零向量,再与B卷积,则称为宽卷积。窄卷积和宽卷积分别用conv2(A, B, 'valid')和conv2(A, B, 'full')表示。
2.2 池化
假设矩阵C为6×46×4的矩阵,池化窗口为2×22×2,则按照池化窗口大小将矩阵C分割成6块不相交的2×22×2小矩阵,对对每个块中的所有元素做求和平均操作,称为平均池化,取最大 值则称为最大池化。得到的矩阵S称为pool map。如:
C=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢115599226600337711448822⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥C=[123412345678567890129012]
若平均池化,则:
S=⎡⎣⎢1.55.54.53.57.51.5⎤⎦⎥S=[1.53.55.57.54.51.5]
若最大池化,则:
S=⎡⎣⎢269482⎤⎦⎥S=[246892]
由于池化也称为下采样,用S=down(C)S=down(C)表示,为了使得池化层具有可学习性,一般令:
S=βdown(C)+bS=βdown(C)+b
其中,ββ和bb为标量参数。
2.3 卷积神经网络
卷积神经网络是权值共享,非全连接的神经网络。以2个卷积层和2个池化层的卷积神经网络为例,其结构图如下: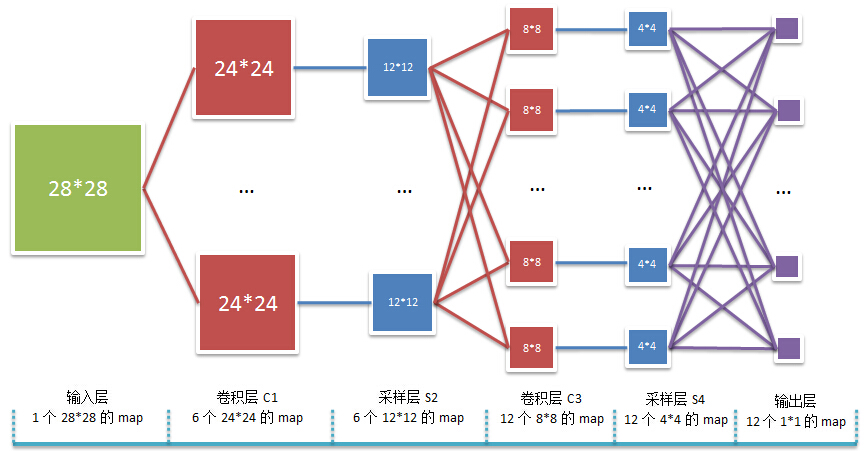
2.3.1 前向传导
C1层:卷积神经网络的输入是28×2828×28的矩阵A,经过F1F1个5×55×5的卷积核K1i(i=1,2,...,F1)Ki1(i=1,2,...,F1)的卷积生成F1F1个24×2424×24大小的feature maps:
C1i=conv2(A,K1i,′valid′)+b1iu1i=C1ia1i=f(u1i)Ci1=conv2(A,Ki1,′valid′)+bi1ui1=Ci1ai1=f(ui1)
S2层:接着池化,池化窗口为2×22×2,一个24×2424×24的feature map池化成一个12×1212×12大小的 pool map,共生成F1F1个pool maps:
S2i=β2idown(a1i)+b2iu2i=S2ia2i=f(u2i)Si2=βi2down(ai1)+bi2ui2=Si2ai2=f(ui2)
C3层:接着再次卷积,C3层中每个8×88×8的feature map C3iCi3都由S2中的所有F1F1个 pool maps 经过F1F1个5×55×5的卷积核K3ij(j=1,2,...,F1)Kij3(j=1,2,...,F1),共生成F3F3个feature maps:
C3i=∑j=1F1conv2(a2j,k3ij,′valid′)+b3iju3i=C3ia3i=f(u3i)Ci3=∑j=1F1conv2(aj2,kij3,′valid′)+bij3ui3=Ci3ai3=f(ui3)
S4层:接着再次池化,池化窗口为2×22×2,一个8×88×8的feature map池化成一个4×44×4大小的pool map,共生成F3F3个pool maps:
S4i=β4idown(a3i)+b4iu4i=S4ia4i=f(u4i)Si4=βi4down(ai3)+bi4ui4=Si4ai4=f(ui4)
全连接层:最后,将a4i(i=1,2,...,F3)ai4(i=1,2,...,F3)顺序展开成向量,并有序连接成一个长向量,作为全连接层网络的输入。
2.3.2 反向传播
卷积神经网络的反向传播本质上是和BP神经网络是一致的,区别在于全连接和非全连接:在反向求导时,卷积神经网络要明确参数连接了哪些神经元;而全连接的普通神经网络中的相邻两层的神经元都是与另一层的所有神经元相连的,因此反向求导时非常简单。
全连接层 全连接层的反向求导是与普通神经网络的反向求导是一致的:
∂J∂w(l)=δ(l)(a(l−1))T∂J∂b(l)=δ(l)∂J∂w(l)=δ(l)(a(l−1))T∂J∂b(l)=δ(l)
卷积层 假设当前卷积层为ll,下一层为池化层l+1l+1,上一层也为池化层l−1l−1。那么从l−1l−1层到ll层有:
a(l)i=f(u(l)i)=f(∑j=1Nl−1conv2(a(l−1)j,K(l)ij)+b(l)ij)ai(l)=f(ui(l))=f(∑j=1Nl−1conv2(aj(l−1),Kij(l))+bij(l))
其中,Nl−1Nl−1为l−1l−1层pool maps的个数。如,当l=1l=1时,Nl−1=1Nl−1=1;当l=3l=3时,Nl−1=F1Nl−1=F1。
为了求得卷积层ll的各个神经元的δδ,关键是要必须弄清楚该神经元与l+1l+1层中的哪些神经元连接,因为求该神经元的δδ时,只与这些神经元相关。递推的方式与全连接的神经网络的不同之处在于:
- 卷积层ll的各个神经元的δδ只和l+1l+1层的相关神经元有关
- 卷积层 ll 到池化层 l+1l+1 做了下采样运算,使得矩阵维度减小,因此,δ(l+1)iδi(l+1)需要上采样up成卷积层的矩阵维度。定义 up 运算为(若上采样窗口为2×22×2):
up([1324])=⎡⎣⎢⎢⎢1133113322442244⎤⎦⎥⎥⎥up([1234])=[1122112233443344]
因此,有:
δ(l)i=β(l+1)i(a(u(l)i)∘up(δl+1i))∂J∂b(l)i=∑s,t(δi)st∂J∂K(l)ij=∑st(δ(l)i)st(P(l−1)j)stδi(l)=βi(l+1)(a(ui(l))∘up(δil+1))∂J∂bi(l)=∑s,t(δi)st∂J∂Kij(l)=∑st(δi(l))st(Pj(l−1))st
其中,(∗)st(∗)st遍历∗∗的所有元素,(P(l−1)j)st(Pj(l−1))st是(δ(l)i)(δi(l))所连接的 l−1l−1 层中al−1jajl−1中相关的元素构成的矩阵。
池化层 假设当前池化层为 ll,下一层为全连接层,那么当前池化层就是全连接层的输入,可以根据全连接层的 BP 求导公式递推算出。因此只需讨论下一层 l+1l+1 为卷积层的情形,上一层 l−1l−1也为卷积层,该情形下有:
a(l)i=f(β(l)idown(a(l−1)i)+b(l)i)ai(l)=f(βi(l)down(ai(l−1))+bi(l))
同样地,为了求得池化层 ll 的各个神经元的δδ,关键是要必须弄清楚该神经元与 l+1l+1层中的哪些神经元连接,因为求该神经元的δδ时,只与这些神经元相关。递推的方式与全 连接的神经网络的不同之处在于:
- 池化层 ll 的各个神经元的δδ只和 l+1l+1 层的相关神经元有关
- 池化层 ll 到卷积层 l+1l+1 做了窄卷积运算,使得矩阵维度减小,因此,δl+1iδil+1 需要与相应的卷积核做宽卷积运算使得矩阵维度扩展回去。 因此,有:
δ(l)i=∑j=1Nla(l)i∘conv2(δ(l+1)j,K(l+1)ji,′full′)∂J∂b(l)i=∑s,t(δ(l)i)st∂J∂β(l)i=∑s,t(δ(l)i∘d(l−1)i)stδi(l)=∑j=1Nlai(l)∘conv2(δj(l+1),Kji(l+1),′full′)∂J∂bi(l)=∑s,t(δi(l))st∂J∂βi(l)=∑s,t(δi(l)∘di(l−1))st
其中,(∗)st(∗)st遍历∗∗的所有元素,d(l−1)i=down(a(l−1)i)di(l−1)=down(ai(l−1))。