目录
1. 非类型模板参数
2. 模板的特化
2.1 概念
2.2 函数模板特化
2.3 类模板特化
2.3.1 全特化
3 模板分离编译
3.1 什么是分离编译
3.2 模板的分离编译
4. 模板总结
有需要的老哥可以先看看模板的介绍:http://t.csdn.cn/2TkUY![]() http://t.csdn.cn/2TkUY
http://t.csdn.cn/2TkUY
1. 非类型模板参数
模板参数分为类型形参与非类型形参。类型形参:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。非类型形参:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
namespace grm
{// 定义一个模板类型的静态数组template<class T, size_t N = 10>class array{public:T& operator[](size_t index) { return _array[index]; }const T& operator[](size_t index)const { return _array[index]; }size_t size()const { return _size; }bool empty()const { return 0 == _size; }private:T _array[N];size_t _size;};
}int main()
{grm::array<int, 100> arr;return 0;
}就比如上面这种,模板参数多了一个int类型的N,实例化出arr后,为其开辟的就是100个空间大小。
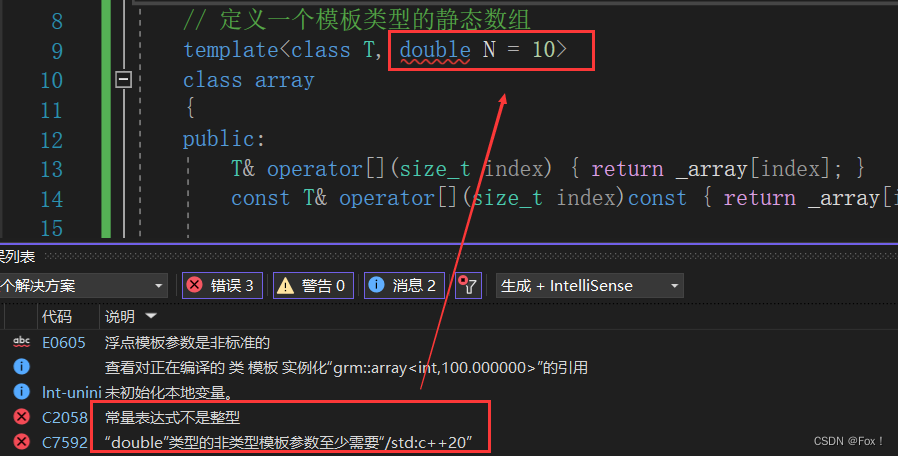
注意:1. 浮点数、类对象以及字符串是不允许作为非类型模板参数的。2. 非类型的模板参数必须在编译期就能确认结果。
像下面这种写法编译器会直接报错的:
2. 模板的特化
2.1 概念
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板 。
这个我们在priority_queue的介绍中已经遇到了这种情况,当push一个日期类的地址时我们用普通的方法已经不能够达到我们想要的目的了。
此时,就需要对模板进行特化。即:在原模板类的基础上,针对特殊类型所进行特殊化的实现方式。模板特化中分为函数模板特化与类模板特化。
2.2 函数模板特化
函数模板的特化步骤:1. 必须要先有一个基础的函数模板2. 关键字template后面接一对空的尖括号<>3. 函数名后跟一对尖括号,尖括号中指定需要特化的类型4. 函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{return left < right;
}
// 对Less函数模板进行特化
template<>
bool Less<Date*>(Date* left, Date* right)
{return *left < *right;
}
int main()
{cout << Less(1, 2) << endl;Date d1(2022, 7, 7);Date d2(2022, 7, 8);cout << Less(d1, d2) << endl;Date* p1 = &d1;Date* p2 = &d2;cout << Less(p1, p2) << endl; // 调用特化之后的版本,而不走模板生成了return 0;
}但是我个人感觉使用这种方法还不如直接重载一个版本。
注意:一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出。
bool Less(Date* left, Date* right)
{return *left < *right;
}这种实现简单明了,代码的可读性高,容易书写,因为对于一些参数类型复杂的函数模板,特化时特别给出,因此函数模板不建议特化。
2.3 类模板特化
2.3.1 全特化
全特化即是将模板参数列表中所有的参数都确定化。
template<class T1, class T2>
class Data
{
public:Data() {cout<<"Data<T1, T2>" <<endl;}
private:T1 _d1;T2 _d2;
};
template<>
class Data<int, char>
{
public:Data() {cout<<"Data<int, char>" <<endl;}
private:int _d1;char _d2;
};
void TestVector()
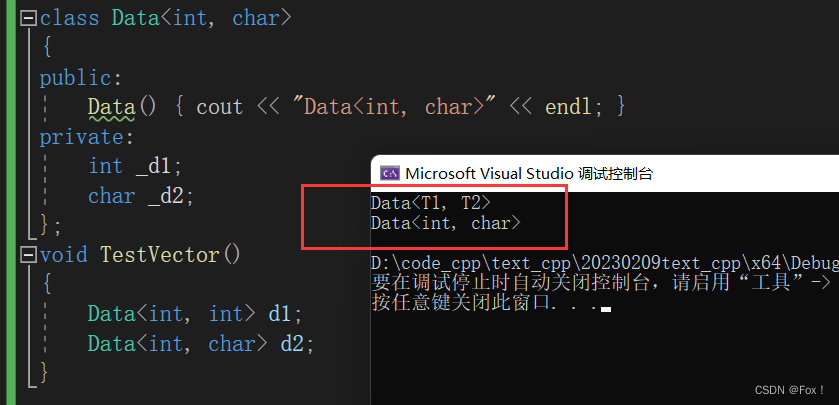
{Data<int, int> d1;Data<int, char> d2;
}我们可以调试起来看看:发现d1会调用第一种模板,而d2会调用第二种模板参数:
像我们之前实现日期类的比较就可以用这种版本:
2.3.2 偏特化
偏特化:任何针对模版参数进一步进行条件限制设计的特化版本。比如对于以下模板类:
template<class T1, class T2>
class Data
{
public:Data() {cout<<"Data<T1, T2>" <<endl;}
private:T1 _d1;T2 _d2;
};偏特化有以下两种表现方式:
- 部分特化:将模板参数类表中的一部分参数特化。
// 将第二个参数特化为int
template <class T1>
class Data<T1, int>
{
public:Data() {cout<<"Data<T1, int>" <<endl;}
private:T1 _d1;int _d2;
};- 参数更进一步的限制
偏特化并不仅仅是指特化部分参数,而是针对模板参数更进一步的条件限制所设计出来的一个特化版本。
//两个参数偏特化为指针类型
template <typename T1, typename T2>
class Data <T1*, T2*>
{
public:Data() {cout<<"Data<T1*, T2*>" <<endl;}private:
T1 _d1;T2 _d2;
};
//两个参数偏特化为引用类型
template <typename T1, typename T2>
class Data <T1&, T2&>
{
public:Data(const T1& d1, const T2& d2): _d1(d1), _d2(d2){cout<<"Data<T1&, T2&>" <<endl;}private:const T1 & _d1;const T2 & _d2; };
void test2 ()
{Data<double , int> d1; // 调用特化的int版本Data<int , double> d2; // 调用基础的模板 Data<int *, int*> d3; // 调用特化的指针版本Data<int&, int&> d4(1, 2); // 调用特化的指针版本
}3 模板分离编译
3.1 什么是分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
3.2 模板的分离编译
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义:
// a.h
template<class T>
T Add(const T& left, const T& right);// a.cpp
template<class T>
T Add(const T& left, const T& right)
{return left + right;
}// main.cpp
#include"a.h"
int main()
{Add(1, 2);Add(1.0, 2.0);return 0;
}我们来运行一下:
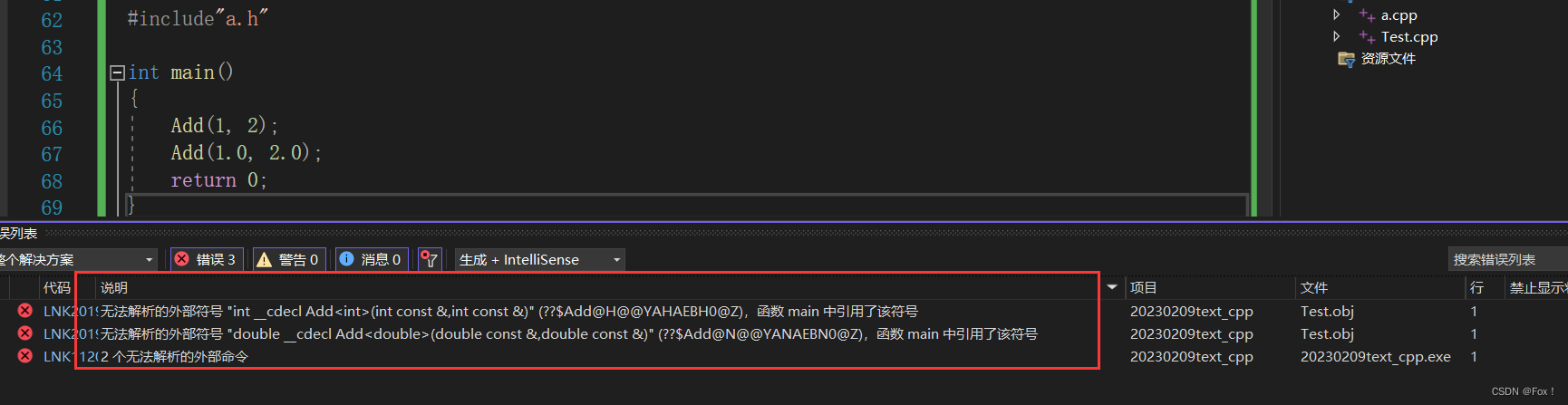
发现报了链接错误,为什么呢?
我们可以简单来分析一下:程序处理阶段分为4个过程:
预处理 编译 汇编 链接想了解这四个步骤的具体详解可以参照博主的这一篇文章:
http://t.csdn.cn/QA43T![]() http://t.csdn.cn/QA43T在a.cpp中,编译器没有看见对Add模板函数的实例化(原因C++标准明确表示,当一个模板不被用到的时侯它就不该被实例化出来),因此是不会生成具体的函数,当链接时找函数地址时就会因找不到而报错,具体处理方式有两种:
http://t.csdn.cn/QA43T在a.cpp中,编译器没有看见对Add模板函数的实例化(原因C++标准明确表示,当一个模板不被用到的时侯它就不该被实例化出来),因此是不会生成具体的函数,当链接时找函数地址时就会因找不到而报错,具体处理方式有两种:
1 模板定义的位置显式实例化:
template<>
int Add(const int& left, const int& right)
{return left + right;
}template<>
double Add(const double& left, const double& right)
{return left + right;
}但是这种方式就没有了范型编程的优势了,所以这种方式并不可取。
2 将声明和定义放到一个文件 "xxx.hpp" 里面或者xxx.h其实也是可以的。(推荐使用放在xxx.h中)
//a.h
template<class T>
T Add(const T& left, const T& right)
{return left + right;
}这种处理方式是在告诉编译器如果要调用的话由于有函数的定义就会直接实例化出对象,不用再等到链接时再去寻找。
下面摘抄了一位大佬中博客的一句话,我觉得能够更好的帮助理解:
在分离式编译的环境下,编译器编译某一个.cpp文件时并不知道另一个.cpp文件的存在,也不会去查找(当遇到未决符号时它会寄希望于连接器)。这种模式在没有模板的情况下运行良好,但遇到模板时就傻眼了,因为模板仅在需要的时候才会实例化出来,所以,当编译器只看到模板的声明时,它不能实例化该模板,只能创建一个具有外部连接的符号并期待连接器能够将符号的地址决议出来。然而当实现该模板的.cpp文件中没有用到模板的实例时,编译器懒得去实例化,所以,整个工程的.obj中就找不到一行模板实例的二进制代码,于是连接器也黔驴技穷了。
(上面这句话就出自于这篇文章)
【分离编译扩展阅读】https://blog.csdn.net/pongba/article/details/19130 https://blog.csdn.net/pongba/article/details/19130
https://blog.csdn.net/pongba/article/details/19130
4. 模板总结
【优点】
1. 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生2. 增强了代码的灵活性【缺陷】1. 模板会导致代码膨胀问题,也会导致编译时间变长2. 出现模板编译错误时,错误信息非常凌乱,不易定位错误