Hi35xx stmmac网卡驱动源码解读
一、源文件
drivers/net/stmmac/stmmac_main.c
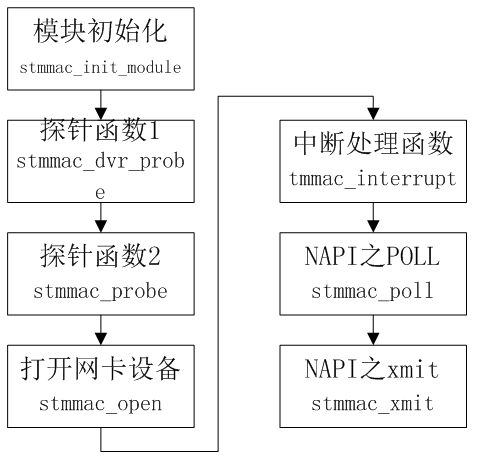
源码阅读顺序如下图:
二、platform_device_register与platform_driver_register
platform_device_register:注册设备
platform_driver_register:注册驱动
两者通过name联系起来,所有两者的name必须要保持一致。
platform_device_register必须在驱动加载前完成,原因驱动注册时需要匹配内核中已经注册的设备名。
platform_driver_register注册时,会将当前注册的drivername和已注册的所有device中name进行比较,只有找到相同了的才能注册成功。匹配后就会调用probe进行检测设备,然后将该设备绑定到驱动上。
Platform是一个虚拟的地址总线,相比pci,USB,它主要用于描述SOC上的片上资源。使用约定:如果不属于任何总线的设备,例如网卡,串口等设备,都挂在这个虚拟总线上。
三、平台驱动数据结构
static struct platform_driver stmmac_driver= {
.probe = stmmac_dvr_probe,(见第四节)
.remove = stmmac_dvr_remove,
.driver = {
.name = STMMAC_RESOURCE_NAME,
.owner = THIS_MODULE,
.pm = &stmmac_pm_ops,
},
};
static struct platform_devicestmmac_platform_device[] = {
{
.name = STMMAC_RESOURCE_NAME,
.id = 0,
.dev = {
.platform_data = &stmmac_ethernet_platform_data,
.dma_mask = (u64 *) ~0,
.coherent_dma_mask = (u64) ~0,
.release = stmmac_platform_device_release,
},
.num_resources = ARRAY_SIZE(stmmac_resources),
.resource = stmmac_resources,
}
};
static struct plat_stmmacenet_datastmmac_ethernet_platform_data = {
.bus_id = 1,
.pbl = DMA_BURST_LEN,
.has_gmac = 1,
.enh_desc = 1,
#ifdef TNK_HW_PLATFORM_FPGA
.clk_csr = 0x2, /* For 24Mhz bus clock input */
#else
.clk_csr = 0x4, /* For 155Mhz bus clock input */
#endif
};
四、驱动探针stmmac_dvr_probe
当平台驱动在注册时,如果和平台设备名字匹配了,就会调用该初始化接口。
1、接口操作基本流程
该函数流程图如下:
(1)获取系统配置寄存器基地址
ret = stmmac_syscfg_init(pdev);
(2)获取MAC控制器寄存器基地址
stmmac_base_ioaddr =ioremap_nocache(res->start, res->end - res->start + 1);
(3)申请网卡设备和私有数据
ndev =alloc_etherdev(sizeof(struct stmmac_priv));
网卡设备和私有数据紧紧的挨在一起:网卡设备+私用数据结构,通过netdev_priv获取私有数据。网卡设备是通用数据结构,私有数据则为各个MAC控制器的数据结构
(4)MAC控制器设置
ret =stmmac_mac_device_setup(ndev);(见第2小节)
(5)网络设备真正注册
ret = stmmac_probe(ndev);(重要,见第五节)
(6)MDIO总线注册
ret = stmmac_mdio_register(ndev);(见第3小节)
(7)将网卡设备赋给全局变量
stmmac_device_list[priv->id] = ndev;,在其他接口中会使用这个全局变量。
注:3~7步骤,如果是多网卡则循环执行。
(8)复位DMA,GMA等寄存器
stmmac_reset();
(9)判断是否支持checksum offload engine
priv->rx_coe =priv->hw->mac->rx_coe(priv->ioaddr);在上面的第4步进行了函数初始化
(10)设置硬件DMA工作模式
stmmac_dma_operation_mode(priv);(见第4小节)
(11)初始化RX/TX队列
priv->dma_tx_size = STMMAC_ALIGN(dma_txsize);
priv->dma_rx_size =STMMAC_ALIGN(dma_rxsize);
priv->dma_buf_sz = STMMAC_ALIGN(buf_sz);
init_dma_desc_rings(ndev);(见第5小节)
(12)硬件DMA初始化
priv->hw->dma->init(priv->dma_ioaddr,
priv->dma_channel,
priv->plat->pbl,
priv->dma_tx_phy,
priv->dma_rx_phy,0)
最重要的意见事情:由init_dma_desc_rings 申请的priv->dma_tx_phy和priv->dma_rx_phy DMA handle写入接收和发送描述子链表地址寄存器
(13)接收发送index初始化
priv->dirty_rx = priv->cur_rx = 0;
priv->dirty_tx = priv->cur_tx = 0;
cur:已获取上传给网络协议层的数据帧index,协议层会释放skb
dirty:已经填充skb到dma队列的index
两个数值不断累加,通过取余%的方式循环处理dma队列。
如图所示:

(14)初始化接收回收队列
skb_queue_head_init(&priv->rx_recycle);
注意:9~11步骤,如果多网卡会循环执行。
(15)初始化TOE_NK
ret = tnk_init(stmmac_base_ioaddr,&pdev->dev);(见第6小节)
(16)请求中断
ret= request_irq(SYNOP_GMAC_IRQNUM, stmmac_interrupt, IRQF_SHARED,STMMAC_RESOURCE_NAME, pdev);(重要,见第七节)
(17)使能所有中断
writel(~0, stmmac_base_ioaddr +TNK_REG_INTR_EN);
2、MAC控制器设置stmmac_mac_device_setup(ndev);
(1)选择GMAC设备并初始化
device = dwmac1000_setup(priv->ioaddr);
A.申请一个MAC设备:mac =kzalloc();
B.GMAC操作:mac->mac = &dwmac1000_ops;
C.GMAC dma操作:mac->dma = &dwmac1000_dma_ops;
(2)选择增强型描述子数据结构
device->desc = &enh_desc_ops;
注:以上很多都是对MAC寄存器的基本操作。
3、MII bus注册stmmac_mdio_register
(1)申请MII总线
stmmac_mii_bus = mdiobus_alloc();
(2)初始化mdio工作时钟
tnkclk = mdio_clk_init();
(3)初始化MII总线结构体
stmmac_mii_bus->name = "STMMAC MIIBus";
stmmac_mii_bus->read =&stmmac_mdio_read;
stmmac_mii_bus->write =&stmmac_mdio_write;
stmmac_mii_bus->reset =&stmmac_mdio_reset;
……..
(4)注册MII总线mdiobus_register(stmmac_mii_bus);
A.注册总线设备device_register(&bus->dev);
B.复位总线bus->reset(bus);
C.扫描总线上的PHY设备,最大支持32个
phydev = mdiobus_scan(bus, i);
主要做三件事情:读取PHY ID,创建PHY device,然后注册PHY设备。
创建PHY设备接口get_phy_device中会调用phy_device_create会对PHY设备数据结构初始化,然后初始化工作队列phy_state_machine,该接口中会调用adjust_link接口。
(5)将MII总线赋给stmmac私有数据
priv->mii = stmmac_mii_bus;
4、设置硬件DMA工作模式stmmac_dma_operation_mode
priv->hw->dma->dma_mode(priv->dma_ioaddr,priv->dma_channel,
tc, SF_DMA_MODE);
发送:tc默认为64,不支持DMA存储转发。TxFIFO根据FIFO阀值来判断是否转发
接收:支持DMA存储转发。当RxFIFO接收到一个完整帧后才将该帧向上转发。
5、初始化dma描述子队列init_dma_desc_rings
(1)RX队列申请
priv->rx_skbuff_dma = kmalloc(rxsize *sizeof(dma_addr_t), GFP_KERNEL);
申请256个skb对应的dma地址队列
priv->rx_skbuff =kmalloc(sizeof(structsk_buff *) * rxsize, GFP_KERNEL);
申请256个skb队列
priv->dma_rx =(struct dma_desc *) dma_alloc_coherent(priv->device,
rxsize *sizeof(structdma_desc),
&priv->dma_rx_phy,
GFP_KERNEL);
DMA描述符(在datasheet为接收描述子)建立一致性DMA映射,大小为256* sizeof(structdma_desc),返回缓冲区虚拟内存地址。priv->dma_rx_phy返回正确的DMA handle,个人感觉是虚拟地址对应的物理地址,因为这个地址需要写入接收描述子链表地址寄存器。(该函数不是很明白)
(2)TX队列申请
priv->tx_skbuff = kmalloc(sizeof(struct sk_buff*) * txsize, GFP_KERNEL);
申请256个skb指针
priv->tx_page = kmalloc(sizeof(structpage *) * txsize, GFP_KERNEL);
申请256个page指针
priv->dma_tx = (struct dma_desc*)dma_alloc_coherent(priv->device,
txsize *sizeof(structdma_desc),
&priv->dma_tx_phy,
GFP_KERNEL);
同上
(3)RX 队列初始化以及关联(1)中申请的数据
通过for循环申请256个skb,每个skb大小为2KB。
A.skb =netdev_alloc_skb_ip_align(dev, bfsize);
申请skb数据
B.priv->rx_skbuff[i]= skb;
将skb放入接收队列
C. priv->rx_skbuff_dma[i]= dma_map_single(priv->device, skb->data, bfsize, DMA_FROM_DEVICE);
然后将skb数据通过流式DMA映射加入skb dma地址队列
D.(priv->dma_rx +i)->des2= priv->rx_skbuff_dma[i];
再将skb dma地址放入dma描述符
(4)TX队列没有类似接收的RX初始化操作
for (i = 0; i < txsize; i++) {
priv->tx_skbuff[i] = NULL;
priv->tx_page[i] = NULL;
priv->dma_tx[i].des2 = 0;
}
因为skb是在网络层被申请,传递到驱动中来。
(5)初始化RX/TX描述符
priv->hw->desc->init_rx_desc(priv->dma_rx,rxsize, dis_ic);
priv->hw->desc->init_tx_desc(priv->dma_tx,txsize);
(6) dma描述子队列和skb映射图

上面是接收DMA描述符队列和skb初始化时建立映射过程。对于发送DMA发送队列只有在发送时才会建立映射,如果一个数据包存在多个数据片段,还会调用dma_map_page接口进行页映射处理。
(7)skb申请分配空间图
skb = netdev_alloc_skb_ip_align(dev,bfsize);

skb->len:数据包中全部数据的长度,skb->data_len分隔存储数据片段长度。当只有一个数据片段时data_len = 0。
6、TOE_NK初始化tnk_init()
(1)建立proc目录
ret = tnk_proc_init(hitoe ? max_connections: 0);
(2)如果使用TOE,则对TOE进行进行一系列初始化
由于没有使用,所以此处不讲述。
五、真正注册网络设备stmmac_probe
1、接口基本操作流程
该函数基本流程图:

(1)初始化网卡设备以太网基本信息ether_setup();
dev->header_ops = ð_header_ops;
dev->hard_header_len =ETH_HLEN;(14)
dev->mtu = ETH_DATA_LEN;(1500)
dev->addr_len = ETH_ALEN;(6)
dev->tx_queue_len = 1000; /*Ethernet wants good queues */
dev->flags =IFF_BROADCAST|IFF_MULTICAST;
dev->priv_flags =IFF_TX_SKB_SHARING;
memset(dev->broadcast, 0xFF, ETH_ALEN);
(2)初始化网卡操作函数和ethtool操作函数
dev->netdev_ops =&stmmac_netdev_ops;(见第2小节)
stmmac_set_ethtool_ops(dev);(见第3小节)
dev->features |= NETIF_F_SG |NETIF_F_HIGHDMA | NETIF_F_IP_CSUM
| NETIF_F_IPV6_CSUM;
设置网卡接口特性,这些特性驱动和协议层将会用到
dev->watchdog_timeo =msecs_to_jiffies(watchdog); 设置发送超时,超时后最终会调用stmmac_tx_timeout这个进行超时处理
(3)初始化NAPI轮询接收数据包接口
netif_napi_add(dev, &priv->napi, stmmac_poll, 64);(重要,见第八节)
初始化napi,poll=stmmac_poll,weight=64,poll_list等信息
Weight: 描述接口的相对重要性,当资源紧张时,在接口上能承受多大的流量。
(4)从寄存器中获取MAC地址,并判断有效性
priv->hw->mac->get_umac_addr((void__iomem *)dev->base_addr, dev->dev_addr, 0);
(5)初始化自旋锁
spin_lock_init(&priv->lock);
tnk_lock_init(&priv->tlock);
(6)注册网卡设备
ret = register_netdev(dev);
2、网卡基本操作函数
static const struct net_device_opsstmmac_netdev_ops = {
.ndo_open = stmmac_open,(见第六节)
.ndo_start_xmit = stmmac_xmit,(见第九节)
.ndo_stop = stmmac_release,
.ndo_change_mtu = stmmac_change_mtu,
.ndo_set_multicast_list = stmmac_multicast_list,
.ndo_tx_timeout = stmmac_tx_timeout,
.ndo_do_ioctl = stmmac_ioctl,
.ndo_set_config = stmmac_config,
#ifdef STMMAC_VLAN_TAG_USED
.ndo_vlan_rx_register = stmmac_vlan_rx_register,
#endif
#ifdef CONFIG_NET_POLL_CONTROLLER
.ndo_poll_controller = stmmac_poll_controller,
#endif
.ndo_set_mac_address = eth_mac_addr,
};
3、ethtool操作函数
static struct ethtool_opsstmmac_ethtool_ops = {
.begin = stmmac_check_if_running,
.get_drvinfo = stmmac_ethtool_getdrvinfo,
.get_settings = stmmac_ethtool_getsettings,
.set_settings = stmmac_ethtool_setsettings,
.get_msglevel = stmmac_ethtool_getmsglevel,
.set_msglevel = stmmac_ethtool_setmsglevel,
.get_regs = stmmac_ethtool_gregs,
.get_regs_len = stmmac_ethtool_get_regs_len,
.get_link = stmmac_ethtool_get_link,
.get_rx_csum = stmmac_ethtool_get_rx_csum,
.get_tx_csum = ethtool_op_get_tx_csum,
.set_tx_csum = ethtool_op_set_tx_ipv6_csum,
.get_sg = ethtool_op_get_sg,
.set_sg = ethtool_op_set_sg,
.get_pauseparam = stmmac_get_pauseparam,
.set_pauseparam = stmmac_set_pauseparam,
.get_ethtool_stats = stmmac_get_ethtool_stats,
.get_strings = stmmac_get_strings,
.get_wol = stmmac_get_wol,
.set_wol = stmmac_set_wol,
.get_sset_count = stmmac_get_sset_count,
.get_tso = ethtool_op_get_tso,
.set_tso = ethtool_op_set_tso,
};
六、打开网卡设备stmmac_open
1、基本流程
基本流程图:

(1)MAC地址有效性
is_valid_ether_addr(dev->dev_addr)
(2)修正传递给驱动参数
stmmac_verify_args();
(3)初始化PHY设备
stmmac_init_phy(dev);(见第2小节)
(4)设备MAC地址到硬件
priv->hw->mac->set_umac_addr(priv->ioaddr,dev->dev_addr, 0);
(5)初始化MAC core
priv->hw->mac->core_init(priv->ioaddr);
(6)使能NAPI并schedule
napi_enable(&priv->napi);
napi_schedule(&priv->napi)
(7)启动DMA收发(写寄存器)
priv->hw->dma->start_tx(priv->dma_ioaddr,priv->dma_channel);
priv->hw->dma->start_rx(priv->dma_ioaddr,priv->dma_channel);
(8)启动相关定时器
priv->poll_timer.function= stmmac_poll_func;
定时唤醒处于挂起状态的RxDMA/TxDMA
priv->check_timer.function= stmmac_check_func;
读取寄存器地址获取当前接收描述符地址,如果在cur_rx和dirty_cur之前,则设置描述子归属为GMAC操作。
(9)使能MAC TX/RX
stmmac_enable_mac(priv->ioaddr);
(10)启动队列
netif_start_queue(dev);
2、初始化PHY设备stmmac_init_phy
(1)通知内核载波消失
netif_carrier_off(dev);
(2)以太网设备连接到PHY设备
phydev= phy_connect(dev, phy_id, &stmmac_adjust_link, 0, priv->phy_interface);
stmmac_adjust_link:根绝实际PHY情况,调整连接参数:全双工/半双功,速度,MII/GMII
A.d =bus_find_device_by_name(&mdio_bus_type, NULL, bus_id);
在MDIO bus总线PHY device列表中找到指定的设备
B.设备转化为PHY设备
phydev= to_phy_device(d);
C.rc =phy_connect_direct(dev, phydev, handler, flags, interface);
连接以太网device到指定的PHY 设备,然后启动PHY。
七、中断处理函数stmmac_interrupt
中断里3个并行流程:网卡1、网卡2、TOE,网卡和网卡2处理流程一样,且未使用TOE,只分析网卡1。
接收到第一个数据包或者数据发送完成时,产生中断,进入该中断处理函数。
1、读取中断状态寄存器
不管发送或者接收,产生DMA0中断时,则进入dma中断处理函数
2、stmmac_dma_interrupt
status = priv->hw->dma->dma_interrupt(priv->dma_ioaddr,priv->dma_channel,
&priv->xstats);
读取dma中断状态,如果是正确的接收和发送,则进行NAPI调度_stmmac_schedule(priv)。
里面调用napi_schedule(&priv->napi),同时禁止中断(中断由stmmac_poll里面开启)。
3、napi_schedule简单说明
(1)将priv->napi加入到softnet_data->napi,从定义看每个CPU有一个softnet_data
(2)启动网络接收软中断NET_RX_SOFTIRQ
(3)在CPU一定时间内处理该软中断
(4)软中断处理函数为net_rx_action,里面则会调用n->poll进行相应处理(该处的poll为下面probe是注册的stmmac_poll,见后面章节说明)
(5)软中断处理函数在subsys_initcall(net_dev_init)时注册
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
(6)最后在do_softirq中统一处理所有的软中断。
常见软中断类型:
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCUshould always be the last softirq */
NR_SOFTIRQS
};
4、中断里没对接收到的数据进行处理,而是调用NAPI接口在适当的时间进行处理。
八、NAPI接口之stmmac_poll
该接口完成两个事情:一个是当数据发送完成时产生中断,进入该函数进行资源回收;另外一个是收到数据产生中断,进入该函数进行数据接收和处理。
1、基本操作流程
(1)接口开始时记录proc信息
stmmac_poll_begin();
(2)回收已经发送完成的资源(放在发送章节讲解)
stmmac_tx(priv);(见第九节7小节)
(3)接收数据包
stmmac_rx(priv, budget);(见第2小节)
(4)如果接收到的数据包没有超过接口的容量,则开启中断
if (work_done< budget) {
stm_proc.polls_done++;
napi_complete(napi);
stmmac_enable_irq(priv);
}
(5)结束接口调用
stmmac_poll_end();
2、数据包接收处理stmmac_rx
unsigned int entry = priv->cur_rx % rxsize;
struct dma_desc *p = priv->dma_rx +entry;
(1)priv->hw->desc->get_rx_owner(p)
判断当前描述子的归属:描述子数据结构中OWN位,0:当前描述子应该由CPU操作,1:前描述子应该由GMAC操作。对于接收,初始化dma描述子队列时设置为1。
GMAC根据寄存器配置,获取可用接收描述子,然后从RxFIFO中读取从PHY接收的Ethernet报文,如果报文符合接收条件,将该报文写入接收描述子指向的数据缓冲区,并回写接收描述子。这个回写就会将OWN位设置为0。
(2)获取下一帧描述符
next_entry = (++priv->cur_rx) % rxsize;
p_next =priv->dma_rx + next_entry;
priv->cur_rx:已经传递给协议层的index
(3)获取收到帧状态
status =(priv->hw->desc->rx_status(&priv->dev->stats, &priv->xstats,p));
如果是丢弃帧,则什么都不处理;否则上传到上层网络。
(4)获取帧长度
frame_len =priv->hw->desc->get_rx_frame_len(p);
(5)获取帧数据
skb = priv->rx_skbuff[entry];
priv->rx_skbuff[entry] = NULL;
注意:skb将有上层网络处理完后进行释放。
(6)设置skb数据长度和解除流式DMA映射
skb_put(skb, frame_len);
dma_unmap_single(priv->device, priv->rx_skbuff_dma[entry],priv->dma_buf_sz, DMA_FROM_DEVICE);
(7)获取skb的协议类型
skb->protocol = eth_type_trans(skb,priv->dev);
skb->dev = priv->dev;
(8)将skb通过NAPI接口上传上层网络协议处理
napi_gro_receive(&priv->napi,skb);(见第九节)
注:以上是一个while循环操作
(9)重新填充接收队列
stmmac_rx_refill(priv);(见第3小节)
3、接收队列填充函数stmmac_rx_refill
由第2小节,接收到数据的skb从dma接收队列剥离,传递给网络层处理完成后,会将skb给释放。所以,需要重新申请新的skb传递填充dma接收队列。
(1)判断是否需要重新填充
将priv->cur_rx和priv->dirty_rx进行对比,如果priv->cur_rx > priv->dirty_rx即上传给网络协议层的数量大于已经填充dma的数量时,才会重新填充dma接收队列。
(2)检查描述子操作归属
priv->hw->desc->get_rx_owner(p+ entry),只有属于CPU的,才进行填充操作。
(3)申请新的SKB
skb= __skb_dequeue(&priv->rx_recycle);
先从回收队列中获取有效的skb。该回收队列来自由协议层申请且发送完成的数据帧skb。在stmmac_tx接口进行回收,它没有释放skb,而是放在了回收队列中,提高利用效率。
skb= netdev_alloc_skb_ip_align(priv->dev,
若回收队列没有,则重新申请skb。
(4)填充接收DMA描述符队列
priv->rx_skbuff[entry]= skb;
priv->rx_skbuff_dma[entry]= dma_map_single(priv->device, skb->data, bfsize, DMA_FROM_DEVICE);
(p+ entry)->des2 = priv->rx_skbuff_dma[entry];
(5)设置描述子归属,交给GMAC操作
priv->hw->desc->set_rx_owner(p+ entry);
注:以上通过for循环进行,直到没有需要填充为止。
(6)激活RxDMA
STMMAC_SYNC_BARRIER();
处理下一条指令前,先flush一下DMA write buffers
priv->hw->dma->enable_dma_receive(priv->dma_ioaddr,priv->dma_channel);
写任何值唤醒处于挂起的RxDMA。
九、传递skb数据给协议栈napi_gro_receive(generic receive offload)
1、概念了解
TSO、UFO和GSO是对应网络发送,LRO、GRO是对应网络接收。
TSO(TCPSegmentation Offload)是一种利用网卡对TCP数据包分片,减轻CPU负荷的一种技术,也叫LSO(Largesegment offload),TSO—TCP,UFO—UDP。如果硬件支持TSO功能,也需要硬件支持的TCP校验计算和分散/聚集功能。
GSO(GenericSegmentation Offload)比TSO更通用。基本思想:尽可能的推迟数据分片直至发送到网卡驱动之前,此时会检查网卡是否支持分片功能(TSO、UFO),如果支持直接发送到网卡,如果不支持就进行分片后再发往网卡。这样大数据包只需走一次协议栈,而不是被分割成几个数据包分别走,提高效率。
LRO(Large ReceiveOfflaod) 通过接收到的多个TCP数据聚合成一个大的数据包,然后传递给网络协议层处理,以减少上层协议栈处理开销,提高系统接收TCP数据包能力
GRO(Generic ReceiveOffload)基本思想跟LRO类似,但是更加通用,现在驱动基本使用GRO接口,而不是LRO。
RSS(Receive SideScaling)是一项网卡的特性,俗称多队列。具备多个RSS队列的网卡,可以将不同的网络流分成不同的队列,再分别将这些队列分配到多个CPU核心进行处理,从而将负荷分散,充分利用多核处理器的能力。
2、GRO结构体struct napi_gro_cb
GRO功能使用skb结构体内私有空间char cb[48]来存放gro所用到的一些信息。
具体内容如下:
struct napi_gro_cb {
/* Virtual address ofskb_shinfo(skb)->frags[0].page + offset. */
指向存在skb_shinfo(skb)->frag[0].page页的数据的头部。见skb_gro_reset_offset
void *frag0;
/*Length of frag0. 第一页中数据的长度 */
unsigned int frag0_len;
/* This indicates where we areprocessing relative to skb->data. 表明skb->data到GRO需要处理的数据区的偏移量 */
比如进入ip层进行GRO处理,这时skb->data指向ip 头, 而ip层的gro 正好要处理ip头,这时偏移量就为0。进入传输层后进行GRO处理,这时skb->data还指向ip头, 而tcp层gro要处理tcp头,这时偏移量就是ip头部长度
intdata_offset;
/* This is non-zero if thepacket may be of the same flow. 挂在napi->gro_list上的报文是否跟现在的报文进行匹配*/
每层的gro_receive都设置该标记位。 接收到一个报文后,使用该报文和挂在napi->gro_list上 的报文进行匹配。 在链路层,使用dev 和 mac头进行匹配,如果一样表示两个报文是通一个设备发过来的,就标记napi->gro_list上对应的skb的same为1. 到网络层,再进一步进行匹配时,只需跟napi->list上刚被链路层标记 same为1的报文进行网络层的匹配即可,不需再跟每个报文进行匹配。 如果网络层不匹配,就清除该标记。 到传输层,也是只配置被网络层标记same为1 的报文即可。这样设计为的是减少没必要的匹配操作
intsame_flow;
/* This is non-zero if thepacket cannot be merged with the new skb. */
如果该字段不为0,表示该数据报文没必要再等待合并,可以直接送进协议栈进行处理了
int flush;
/*Number of segments aggregated. 该报文被合并过的次数*/
intcount;
/*Free the skb? 是否该被丢弃*/
intfree;
};
3、函数基本流程
(1)skb_gro_reset_offset(见第4小节)
初始化NAPI_GRO_CB;
(2)__napi_gro_receive(见第6小节)
连路层gro_receive,实现数据包合并还是上传协议栈
(3)napi_skb_finish(见第5小节,内容少先讲)
根据第二个函数的返回值决定合并,feed协议栈,还是free。
4、初始化GRO cb: skb_gro_reset_offset(skb)
支持S/G IO的网卡存在如下一种可能:skb本身不包含数据(头也没有),所有的数据都保存在skb_share_info中,且frags.page不在higih_mem。此种情况如果要合并,将包头信息取出来即skb_shared_info的frags[0],将头信息保存到napi_gro_cb 的frags0中。
具体源码如下:
NAPI_GRO_CB(skb)->data_offset = 0;
NAPI_GRO_CB(skb)->frag0 = NULL;
NAPI_GRO_CB(skb)->frag0_len = 0;
如果mac_header和skb->tail相等并且地址不在高端内存,则说明包头保存在skb_shinfo中,所以我们需要从frags中取得对应的数据包
if(skb->mac_header == skb->tail && !PageHighMem(skb_shinfo(skb)->frags[0].page)){
可以看到frag0保存的就是对应的skb的frags的第一个元素的地址
NAPI_GRO_CB(skb)->frag0= page_address(skb_shinfo(skb)->frags[0].page)+
skb_shinfo(skb)->frags[0].page_offset;
然后保存对应的大小
NAPI_GRO_CB(skb)->frag0_len= skb_shinfo(skb)->frags[0].size;
}
5、napi_skb_finish
根据__napi_gro_receive的返回值处理合并后的数据包。
switch(ret) {
//将数据包送进协议栈
case GRO_NORMAL:
if (netif_receive_skb(skb))(见第8小节)
ret = GRO_DROP;
break;
//报文可以丢弃或者已经合并进gro,则free报文
case GRO_DROP:
case GRO_MERGED_FREE:
kfree_skb(skb);
break;
//数据已经被gro保存起来,但是并没有合并的,skb还需要保留不能释放。
case GRO_HELD:
case GRO_MERGED:
break;
}
return ret;
6、__napi_gro_receive接收合并函数
(1)基本概念
每个协议中定义自己的GRO接收合并函数和合并后处理函数,即gro_receive和gro_complete。GRO系统会根据协议来调用对应回调函数。gro_receive将 skb合并到gro_list中,返回值:空则表示合并后无需送入协议栈,非空则需要立即送入协议栈。gro_complete则是当返回值非空时将gro合并数据包送到协议栈时被调用。
__napi_gro_receive和napi_gro_complete可以被看做是链路层的gro_receive和gro_complete。
各个协议层gro_receive:
.gro_receive = tcp4_gro_receive,
.gro_receive = inet_gro_receive,
.gro_receive = ipv6_gro_receive,
各个协议层gro_complete:
.gro_complete = tcp4_gro_complete,
.gro_complete = inet_gro_complete,
.gro_complete = ipv6_gro_complete,
(2)函数基本内容
A.for (p = napi->gro_list;p; p = p->next) {
unsigned long diffs;
diffs = (unsigned long)p->dev ^(unsigned long)skb->dev;
diffs |= p->vlan_tci ^skb->vlan_tci;
diffs |=compare_ether_header(skb_mac_header(p),
skb_gro_mac_header(skb));
NAPI_GRO_CB(p)->same_flow = !diffs;
NAPI_GRO_CB(p)->flush = 0;
}
遍历gro_list,查找列表中skb是否有和当前skb相同的流,然后给same_flow赋值。如果此层(链路层)相同,则ip层、tcp层再进行相同流判断,否则不会进行判断。不同层流是否相同的判断条件不一样,此处判断3个判断条件:同一设备、同一VLAN、同一MAC头。
B. returndev_gro_receive(napi, skb);(见第7节)
真正的接收合并处理
7、dev_gro_receive真正的接收合并
可以分为两部分看待,一个是正常的合并处理,另外一个就是frags0处理部分。需要注意GRO不支持切片的IP包,IP切片的组包在内核IP层会做一遍,GRO再做没意义增加复杂度。
(1)合并相同流处理
A.先遍历对应的ptype(协议的类链表),找到匹配协议后,调用对应的回调函数gro_receive;链路层则调用ip层的gro_receive即inet_gro_receive。
B.进入ip层合并处理,主要判断是否same_flow和是否需要flush。只有两个包是same_flow的情况下才会flush判断
same_flow判断:协议需要相同,tos域需要相同,源和目的地址需要相同;只要一个不同就是设置为0。
flush判断:是切片包,ttl不一样,id顺序不对;只要一个满足skb就会flush出gro到协议栈。然后进入TCP层的gro_receive即tcp4_gro_receive。
C.进入TCP层合并处理:类似IP层,对same_flow和flush判断。其中对flush的判断比较多和复杂,如果需要flush就不需要进行合并处理,返回相应的gro_list。
真正的合并函数:skb_gro_receive(此处暂不分析)。
(2)当gro_receive返回值非空时,对flush出gro的skb进行立即feed进协议栈处理napi_gro_complete。如果当前skb的same_flow非0表明找到同流且已合并直接返回,如果未找到同流,则添加skb到gro_list中。
(3)frags0处理部分
将skb_shinfo结构体存放的frags,往前移动到skb。(为啥这么做?)
8、netif_receive_skb
最终将skb数据分发给各个协议层。有空再讲解。
十、发送数据stmmac_xmit
该接口实现了Scatter/Gather I/O功能,通过skb_shinfo宏来判断数据包是一个数据片段组成,还是由大量数据片段组成。
1、获取可用发送描述子
entry= priv->cur_tx % txsize;
desc= priv->dma_tx + entry;
first= desc; 保存第一个数据片段
2、将skb放到发送队列
priv->tx_skbuff[entry]= skb;
priv->tx_page[entry]= NULL;
3、发送单个或第一个数据包
unsignedint nopaged_len = skb_headlen(skb);
desc->des2= dma_map_single(priv->device, skb->data,nopaged_len, DMA_TO_DEVICE);
priv->hw->desc->prepare_tx_desc(desc,1, nopaged_len, csum_insertion);
当只有一个数据片段时,skb->data将发送所有数据;当有多个数据片段时,skb->data则指向第一个数据片段,数据长度skb->len –skb->data_len,其他数据存放在共享数据结构frags数组中。(skb->len:数据包中全部数据的长度,skb->data_len分隔存储数据片段长度)
4、发送剩余数据片段
对于多个数据片段时,还要进行数据片段的发送,采用页处理。直接处理页结构,而不是内核虚拟地址。
for(i = 0; i < nfrags; i++)
{
skb_frag_t *frag =&skb_shinfo(skb)->frags[i];
int len = frag->size;
entry = (entry + 1) % txsize;
desc = priv->dma_tx + entry;
TX_DBG("\t[entry %d] segment len:%d\n", entry, len);
desc->des2 = dma_map_page(priv->device, frag->page,
frag->page_offset,
len, DMA_TO_DEVICE);
priv->tx_skbuff[entry] = NULL;
priv->tx_page[entry] =frag->page;
get_page(frag->page);(需要查一下原理)
priv->hw->desc->prepare_tx_desc(desc, 0, len, csum_insertion);
priv->hw->desc->set_tx_owner(desc);
}
5、将第一个数据片段描述子交给GMAC,记录当前发送index
priv->hw->desc->set_tx_owner(first);
priv->cur_tx += count;
6、激活RxDMA
STMMAC_SYNC_BARRIER();
处理下一条指令前,先flush一下DMA write buffers
priv->hw->dma->enable_dma_transmission(priv->dma_ioaddr,
priv->dma_channel);
写任何值唤醒处于挂起的RxDMA
7、发送资源回收接口stmmac_tx
当数据发送完成时产生中断,调用stmmac_poll函数进入该接口进行发送资源回收操作。
(1)从寄存器获取当前发送描述符DMA index
(2)循环判断dirty_tx 和 cur_tx
while(priv->dirty_tx != priv->cur_tx)
(3)判断DMA index 和 描述符归属
if (entry == hw_dma_index) // entry =dirty_tx % txsize
break;
if(priv->hw->desc->get_tx_owner(p))
break;
(4)skb加入回收接收队列
if((skb_queue_len(&priv->rx_recycle) <priv->dma_rx_size)
&&skb_recycle_check(skb, priv->dma_buf_sz))
__skb_queue_head(&priv->rx_recycle,skb);
else
dev_kfree_skb(skb);
接收回收队列没有超出接收队列总长度(256),且skb可以进行回收的情况下,将skb加入回收队里。其他就释放skb。
(5)释放多数据数据片段的page页
put_page(priv->tx_page[entry]);
priv->tx_page[entry]= NULL;
(6)增加dirty_tx
entry= (++priv->dirty_tx) % txsize;
十一、其他补充
参考文档