HashMap就是以Key-Value的方式进行数据存储的一种数据结构。
HashMap在jdk1.7之前和jdk1.8之后的底层数据结构是不一样的。
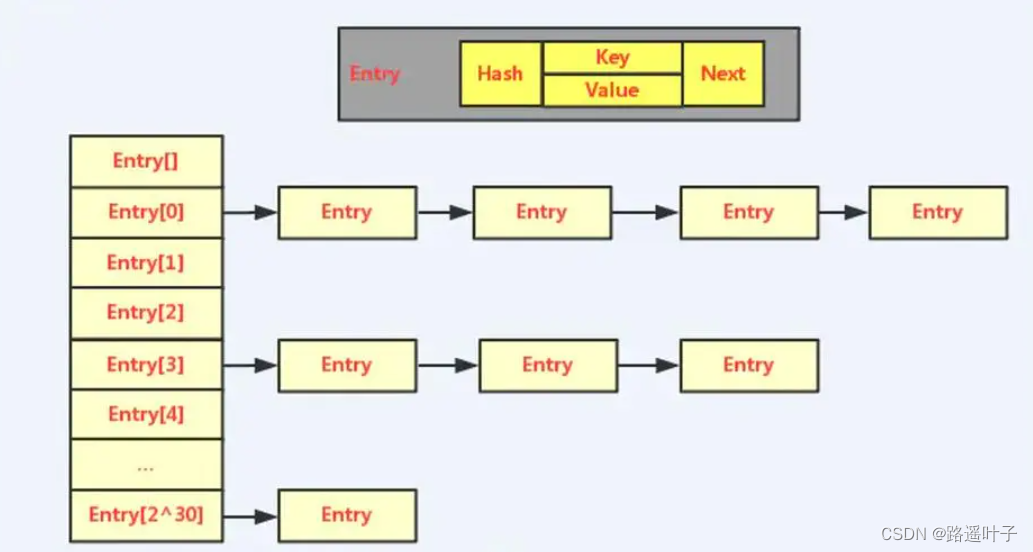
在jdk1.7之前是数组+链表的形式,并通过entry节点保存key和value值;当Hash冲突比较严重的时候,在数组上形成的链表就会变的越来越长,由于链表是不支持索引查询的,所以这个时候要想在链表中找一个元素的话就需要遍历一遍链表,最坏的结果是查找的元素在链表的末尾,这样显然会导致查询效率大大降低;
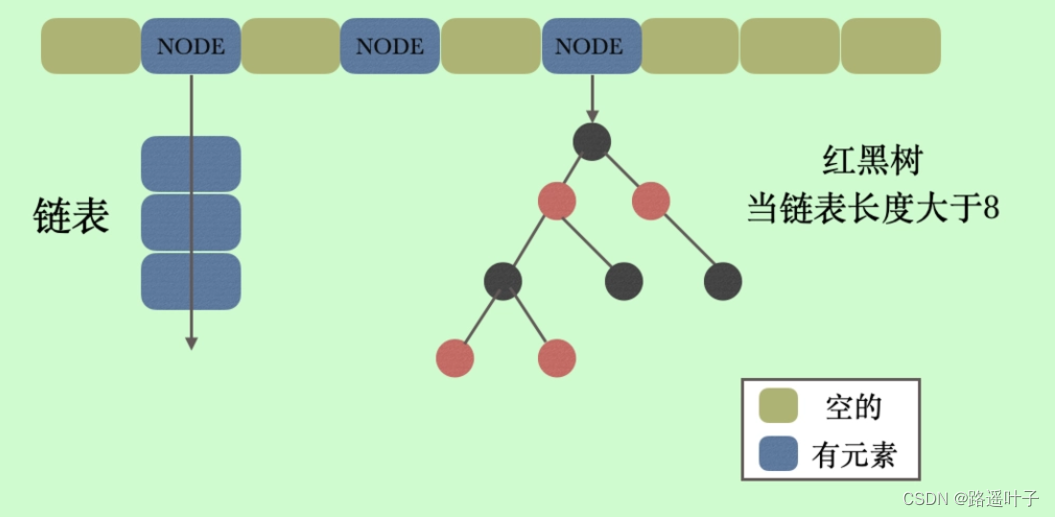
所以为避免这一问题的发生,在jdk1.8加入了红黑树,红黑树是一个自平衡的二叉查找树,使用红黑结点并使得两端保持相对平衡;所以jdk1.8后HashMap的底层数据结构是数组+链表+红黑树的形式。
Jdk8开始当链表高度到8、数组长度超过64时,会将链表转为红黑树,元素以内部类使用Node类存储Key和Value。
通过计算key的hash值,进行二次hash然后对数组长度进行取模,获得对应数组下标; 获得下标后,会先判断下标位置是否存在元素,如果下标位置没有元素,则直接创建Node存入数组;如果存在元素就会产生hash冲突;
冲突产生后,先对key值进行equals()比较,如果key值相同则取代该元素,不同则通过尾插法插入链表,在插入的同时遍历链表计算高度,如果中途存在key值相同的元素则进行覆盖;如果没有就直接插入到链表尾部。
插入完成,对链表高度进行判断,如果链表高度达到8,并且数组长度到64则转变为红黑树;反之,如果红黑树结点低于等于6则会退化为链表。
注意,如果Key为null的话,则存在下标0的位置上。
jdk7中HashMap底层数据结构图:
jdk8中HashMap底层数据结构图:
——》以上讲述了HashMap底层数据结构是怎样的,同时这个题也是面试的高频提问题。在回答过程中,还穿插 了为什么在jdk8要加入红黑树这一问题。以上是自己总结的面试题,根据自我理解和查找资料得出,欢迎各位CSDN的友友们前来指教!