上期回顾
RabbitMQ集群中节点包括内存节点、磁盘节点。内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘上。如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。那么内存节点的性能只能体现在资源管理上,比如增加或删除队列(queue),虚拟主机(vrtual hosts),交换机(exchange)等,发送和接受message速度同磁盘节点一样。一个集群至少要有一个磁盘节点。一个rabbitmq集群中可以共享user,vhost,exchange等,所有的数据和状态都是必须在所有节点上复制的,对于queue根据集群模式不同,应该有不同的表现。在集群模式下只要有任何一个节点能够工作,RabbitMQ集群对外就能提供服务。
部署完成分布式的rabbitmq集群,提升了吞吐量。但是,它也存在一定的问题。虽然是集群,但他并不具备容灾的能力,如图:
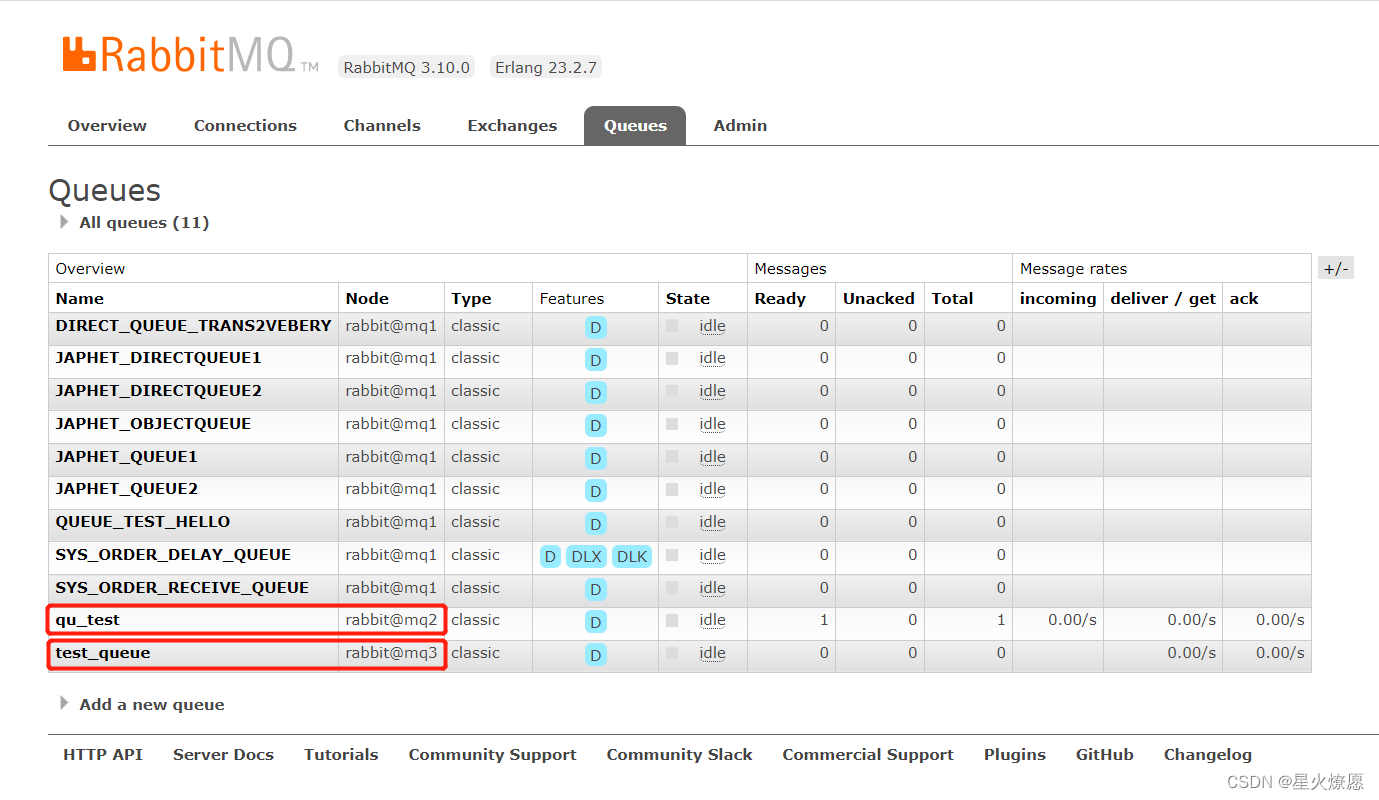
qu_test和test_queue两个队列在创建时,分别被创建在了mq2和mq3上;
如果mq2宕机,那么qu_test队列将变为不可用;
如果mq3宕机,那么test_queue队列将变为不可用;
普通模式的集群类似于分布式的分片;
配置使用镜像模式,可以弥补容灾上的缺陷;
副本:每个节点都存储着相同的数据,每个单节点都存储着数据的总和;每一个节点相当于复制粘贴的一样;
分片:数据被分开,分别存储在每个节点上。每个节点的数据累加就等于数据的综合;任意节点上数据的丢失都会导致总数据的缺失;
默认的集群模式
queue创建之后,如果没有其它policy,则queue就会按照普通模式集群。对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构,但队列的元数据仅保存有一份,即创建该队列的rabbitmq节点(A节点),当A节点宕机,你可以去其B节点查看,./rabbitmqctl list_queues发现该队列已经丢失,但声明的exchange还存在。
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer,所以consumer应平均连接每一个节点,从中取消息。该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。如果做了队列持久化或消息持久化,那么得等A节点恢复,然后才可被消费,并且在A节点恢复之前其它节点不能再创建A节点已经创建过的持久队列;如果没有持久化的话,消息就会失丢。这种模式更适合非持久化队列,只有该队列是非持久的,客户端才能重新连接到集群里的其他节点,并重新创建队列。假如该队列是持久化的,那么唯一办法是将故障节点恢复起来。
为什么RabbitMQ不将队列复制到集群里每个节点呢?这与它的集群的设计本意相冲突,集群的设计目的就是增加更多节点时,能线性的增加性能(CPU、内存)和容量(内存、磁盘)。当然RabbitMQ新版本集群也支持队列复制(有个选项可以配置)。比如在有五个节点的集群里,可以指定某个队列的内容在2个节点上进行存储,从而在性能与高可用性之间取得一个平衡(应该就是指镜像模式)。
镜像模式
把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案。
该模式解决了上述问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用,一个队列想做成镜像队列,需要先设置policy,然后客户端创建队列的时候,rabbitmq集群根据“队列名称”自动设置是普通集群模式或镜像队列。具体如下:
队列通过策略来使能镜像。策略能在任何时刻改变,rabbitmq队列也近可能的将队列随着策略变化而变化;非镜像队列和镜像队列之间是有区别的,前者缺乏额外的镜像基础设施,没有任何slave,因此会运行得更快。
镜像配置简单示例
镜像模式,其实不是一种模式,而是通过配置策略实现交换机、队列的复制;
以 test 为开头命名的交换机或队列,同步到集群中其他节点中,自动同步;
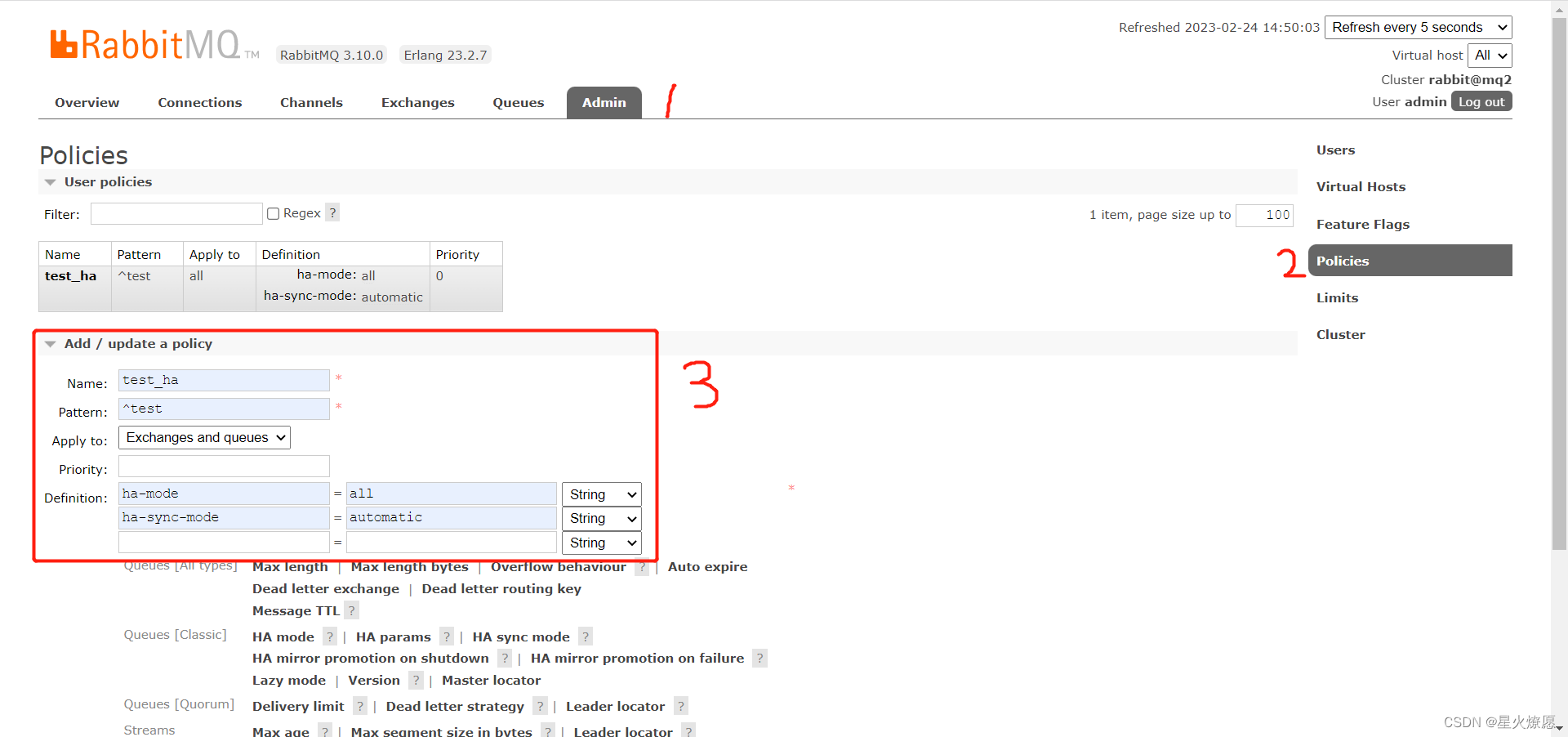
配置策略,可以从web端配置,也可以使用命令在服务端配置;
Name:给策略起一个名字;
Pattern:匹配哪些资源(交换机、队列)
Apply to:作用到哪些资源。有三种:交换机和队列、交换机、队列;
Priority:优先级;(选填)
Definition:定义具体的匹配项;
示例一:
rabbitmqctl set_policy -p "/" policy3 "^QUEUE" '{"ha-mode":"nodes","ha-params":["rabbit@mq-002","rabbit@mq-003"],"ha-sync-mode":"automatic"}'示例二:
rabbitmqctl set_policy ha-all "^my" '{"ha-mode":"all","ha-sync-mode":"automatic"}'参数解释:
# ha-all:为策略名称;
# ^my:为匹配符,只有一个^代表匹配所有,^abc为匹配名称以abc开头的queue或exchange;
# ha-mode:为同步模式,一共3种模式:
# all-所有(所有的节点都同步消息),
# exctly-指定节点的数目(需配置ha-params参数,此参数为int类型比如2,在集群中随机抽取2个节点同步消息)
# nodes-指定具体节点(需配置ha-params参数,此参数为数组类型比如["rabbit@rabbitmq1","rabbit@rabbitmq2"],明确指定在这两个节点上同步消息)。配置项中,较复杂的可能就是Definition了。常用的也就哪几种;