本文由 林鸿钊@funco 翻译,仅作为交流学习之用,诚向各方大佬请教。
翻译不易,感谢支持,转载也请注明出处,不胜感激。
翻译:Bing-CF-IDF+:语义驱动的新闻推荐系统
原文:Bing-CF-IDF+: A Semantics-Driven News Recommender System
摘要: 随着网络中,新闻数量的不断增长,查找关联内容的需求也在增强。语义驱动的推荐系统通过用户的阅读记录生成用户画像,并与新闻相匹配,从而向用户推荐未读新闻项。本论文提出先进的语义驱动的 CF-IDF+ 新闻推荐系统。该新闻推荐系统通过识别新闻项的概念及其相关概念,从而构建用户画像,并对用户未未读的新闻信息进行分析处理。由于该领域的特性,且其依赖领域知识,使基于概念的推荐系统会忽略新闻项中许多高频,却包含新闻项相关信息的命名实体。因此,我们通过 Bing 距离,找到命名实体的隐含信息,并补充至 CF-IDF+ 推荐方法中。这使得我们的 Bing-CF-IDF+ 推荐方法在 F1 值和 Kappa 统计方面优于传统 TF-IDF;基于概念的 CF-IDF 和 CF-IDF+ 推荐方法。
译者注
这里的 Kappa 统计,我理解指的是卡帕系数(Kappa Coefficient),也称为科恩卡帕系数。是一种衡量分类精度的方法。
关键字: 新闻推荐系统;基于内容的推荐系统;语义网络;命名实体;Bing-CF-IDF+
Abstract. With the ever growing amount of news on the Web, the need for automatically fifinding the relevant content increases. Semantics-driven news recommender systems suggest unread items to users by matching user profifiles, which are based on information found in previously read articles, with emerging news. This paper proposes an extension to the state-of-the-art semantics-driven CF-IDF+ news recommender system, which uses identifified news item concepts and their related concepts for constructing user profifiles and processing unread news messages. Due to its domain specifificity and reliance on knowledge bases, such a concept based recommender neglects many highly frequent named entities found in news items, which contain relevant information about a news item’s content. Therefore, we extend the CF-IDF+ recommender by adding information found in named entities, through the employment of a Bing based distance measure. Our Bing-CF-IDF+ recommender outperforms the classic TF-IDF and the concept-based CF-IDF and CF-IDF+ recommenders in terms of the F1-score and the Kappa statistic.
keywords. News recommendation system; Content-based recommender; Semantic Web; Named entities; Bing-CF-IDF+;
1 引言
网络上的信息流正在以越来越快的速度增长,并超出符合网络用户需求的信息量。为了满足用户访问网络的基本需求,自动化且准确的区分相关与不相关内容变的极为重要。推荐系统被证明是媒体和新闻内容的高效处理工具。推荐系统可以利用领域模型等工具,聚合最近访问内容,从而构建用户画像。从相似性角度处理新增内容,有助于计算用户画像与内容之间的相似性,实现更高效而智能的程序来处理过量的信息,进而支持个性化的 web 体验。
The ever growing information stream on the Web is gradually overwhelming the rapidly increasing population of Web users that try to access information matching their needs. An automated and accurate approach for distinguishing between relevant and non-relevant content is becoming of utmost importance for fulfilling the basic needs of the people accessing the Web. Recommender systems [1] have proven to be powerful tools for efficient processing of media and news content. Such systems build up user profiles by gathering information on recently viewed content, e.g., by exploiting domain models [18]. New content is analyzed in a similar fashion, so that similarities between user profiles and content can be computed, thus supporting a personalized Web experience [19,20] through efficient and intelligent procedures to deal with the information overload.
通常,推荐系统分为三类:基于内容的推荐系统;协同过滤推荐系统和混合推荐系统。基于内容的推荐系统将未被发现的新闻、媒体等内容与用户的兴趣匹配作出推荐;协同过滤推荐系统寻找相似用户,并向最相似的用户推荐其喜欢的新内容;混合推荐则是两者结合。因此, (依据本文主题) 后文仅讨论基于内容的推荐系统。
Traditionally, there are three kinds of recommender systems: content-based recommenders, collaborative filtering recommenders, and hybrid recommenders [5]. Content-based recommenders use the content of the unseen news items, media, etc., to match the interests of the user. Collaborative filtering recommenders find similar users and recommend new content of interest to the most similar users. Hybrid recommenders combine the former two methods. In this paper, a new content-based recommender is proposed that is aimed specifically towards news recommendation. Therefore, solely content-based recommender systems are discussed in the remainder of this paper.
基于内容的推荐系统基于用户画像与新闻内容之间的相似度,向用户推荐其未读内容。有多种方法可以计算相似度,每种度量方式使用不同的信息类型,一种是基于新闻的文本字符串;另一种则基于同义词集或概念。本文中,我们将扩展语义驱动的的 CF-IDF+ 推荐系统,该方法已经被证明优于传统 TF-IDF 和 CF-IDF 推荐系统。TF-IDF 基于词项计算相似度, CF-IDF 进一步增加了概念的含义,而 CF-IDF+ 更进一步利用了用户画像或新闻文章的关联概念,从而提供更准确的推荐结果。
Content-based news recommenders suggest unread news items based on similarities between the content of the news item and the user profile. The similarity can be computed in various ways, each measure utilizing different types of information. Some measures are based on terms (text strings) found in news items, while others are based on synsets or concepts. In this paper, we propose an extension to the previously proposed semantics-driven CF-IDF+ recommender [9] that has already proved to outperform the classic TF-IDF [21] and CF-IDF [12] recommenders. Where TF-IDF employs term-based similarities, CF-IDF adds the notion of concepts. CF-IDF+ additionally makes use of concepts that are related to concepts extracted from a news article or user profile, providing more accurate representations.
另一种基于内容的推荐方法是使用文档中的命名实体。命名实体可以看作对象的文本实例(比如人名和地名)。通常,命名实体被用于文本分析和信息提取。例如:支持更高效的搜索;答题算法;文本分类和推荐系统。近来,系统尝尝处理大量的结构化或半结构化文本。通过忽略不相关词语,同时,只考虑命名实体,可以极大减少相似度计算维度,从而保证推荐准确度,同时降低成本。在我们的新闻推荐系统中,也使用该方法处理概念和同义词集,该方式也可能有利于补充我们的系统。
Another content-based recommendation method is based on named entities within a document. Named entities can be considered as real-world instantiations of objects, such as persons and locations. Typically, named entities are used for text analytics and information extraction purposes, e.g., by supporting more efficient search and question answering algorithms, text classification, and recommender systems [22]. The latter systems often have to deal with large amounts of (semi-)unstructured texts. By omitting the irrelevant words and only considering named entities, the dimensionality of similarity computations can be greatly reduced, thus allowing for less expensive, yet accurate recommendations. This is also in line with the usage of concepts and synsets employed in our news recommenders, and could be a beneficial addition to our systems.
命名实体经常出现在新闻中,但他们大多会被忽略,因为基于概念的推荐系统本身并不关注这部分。因此,CF-IDF+ 方法不使用信息命名实体提供的所有信息。对于这一问题,一种合理的方案是,采用某种方法,从 web 搜索引擎中,统计这些命名实体在不同网页的出现次数。在前期工作中,我们利用 Googe Named Entities 相关功能,但在其API不再免费后,我们改用了 Bing,而 Bing 截止撰稿为止,依然免费。
Named entities appear often in news items, yet are mostly neglected because they are, for instance, not present in domain ontologies that underly concept-based recommenders. As a consequence, the CF-IDF+ method does not use all the information that is provided by named entities. A possible solution to this problem is the introduction of a methodology that takes into consideration page counts gathered by Web search engines such as Google or Bing for specific named entities. In earlier work, originally, we made use of Google named entities. However, we had to move to Bing as the usage of Google API was not for free anymore, while Bing API usage was still for free.
译者注
- 截至翻译日期,原『论文-参考文献』中所列的Bing API网页已经不可被访问,相关功能转移至Azure中,可以申请一定时间内免费试用
- Bing基本服务: https://cn.bing.com/partners/developers#LocalBusinessSearch
- 微软Azure-Bing Entity Search: https://azure.microsoft.com/en-us/services/cognitive-services/bing-entity-search-api/
本论文所属推荐方法将在 CF-IDF+ 方法的基础上,考虑新闻中所含命名实体的信息。即,结合 CF-IDF+ 方法和通过 Bing 搜索引擎提供的免费 API 计算的相似度。我们将实现的Bing-CF-IDF+ 推荐系统,由两个部分独立加权组成:CF-IDF+ 推荐系统基于概念计算相似度;Bing推荐系统基于命名实体计算相似度。Bing-CF-IDF+ 推荐系统仅考虑未在概念集中出现的命名实体。这项工作的主要作用是,新闻推荐系统中,领域知识的概念和相关概念(CF-IDF+)与基于搜索引擎的距离度量的综合利用。
The recommender proposed in this paper extends the CF-IDF+ method by using information given in the named entities of news items. It combines the results of the CF-IDF+ method with similarities computed by the Bing search engine, which offered, at the time of conducting the research, a free API [3]. Our proposed recommender, Bing-CF-IDF+, consists of two individually weighted parts. The CF-IDF+ recommender computes the similarity based on concepts, whereas the Bing recommender computes the similarity based on named entities. Only the named entities that do not appear in the concepts are considered by the Bing-CF-IDF+ recommender. The main contribution of this work is the joint exploitation of concepts and their relationships from a domain ontology (CF-IDF+), on one side, and named entities and a search engine-based distance measure (Bing), on the other side, in a news recommender system.
后文将依次描述一下内容:第2章,将讨论在已有的推荐系统方面的相关工作;第3章将对我们的方法及其实现作介绍;第4章,评估Bing-CF-IDF+ 的性能,并与 CF-IDF+、CF-IDF、 TF-IDF推荐系统作对比。第5章,提出结论,并补充一些未来的工作方向。
The remainder of this paper is organized as follows. In Sect. 2, related work on previously proposed recommenders is discussed. Section 3 provides an introduction to our method and its implementation, and Sect. 4 evaluates the performance of Bing-CF-IDF+, compared against CF-IDF+, CF-IDF, and TF-IDF recommenders. Section 5 provides conclusions and some additional directions for future work.
2 相关工作
目前,已经存在许多基于配置的新闻推荐系统(profile-based recommenders)的研究。这些推荐系统基于用户的历史浏览记录构建用户画像,在用户画像与新闻内容之间计算相似度,以此向用户推荐他们未读过的文章。本章,将主要分别介绍基于词项、同义词集、概念、关系和命名实体的推荐系统。
The research endeavours on profile-based (news) recommenders have been plentiful [14]. These recommenders compute similarity levels between news items and user profiles derived from previously read articles, and use these for recommending unseen items. In this section, we focus on recommenders employing terms, synsets, concepts, relations, and named entities.
2.1 基于词项的推荐系统
对于新闻推荐系统,基于TF-IDF是最常用的方法之一。该方法关联了词频(Term Frequency, TF; 文档中该词的出现频率)和逆文档频率(Inverse Document Frequency, IDF; 一种包含该词的文档数相关的度量)。该方法大多使用余弦相似度(consine similarity)计算用户与新闻文章的相似度。
TF-IDF [21], one of the most commonly used methods for recommending news items, is based on news item terms. The method combines the Term Frequency (TF), which is the frequency of specific terms within a document, and the Inverse Document Frequency (IDF) [16], which is a measure of the fraction of documents that contain these terms. This method is often combined with the cosine similarity method to determine the similarity between users and news articles.
对于包含某个词的文档 d ∈ D d \in D d∈D,某个词 t ∈ T t \in T t∈T 的词频 t f ( t , d ) tf(t, d) tf(t,d) 及其逆文档频率 i d f ( t , d ) idf(t, d) idf(t,d) 计算方式如下:
The term frequency of term t ∈ T in document d ∈ D, tf(t, d), and its associated inverse document frequency idf(t, d) are computed as follows:
t f ( t , d ) = n t , d Σ k n t , d tf(t, d) = \frac{n_{t,d}}{\Sigma_k{n_{t, d}}} tf(t,d)=Σknt,dnt,d
i d f ( t , d ) = log ∣ D ∣ ∣ d ∈ D : t ∈ d ∣ idf(t, d) = \log{\frac{|D|}{|d \in D : t \in d|}} idf(t,d)=log∣d∈D:t∈d∣∣D∣
词频是新闻内容中,总词数与该词出现次数的比值。逆文档频率是总新闻数 ∣ D ∣ |D| ∣D∣与包含该词 t t t 的新闻数。则,TF-IDF由TF与IDF乘积运算求得。TF-IDF值越大,说明该词越常在当前新闻中出现,而在其他新闻内容中少见。
where term frequencies are calculated by dividing the frequency that term t t t occurs in news item d ( n t , d ) d (nt,d) d(nt,d) by the total number of all terms in news item d d d. The inverse document frequency is computed as a division of the total number of news items ∣ D ∣ |D| ∣D∣ by the amount of news items in which term t t t can be found. Subsequently, TF-IDF is computed as a multiplication of TF and IDF,
t f - i d f ( t , d ) = t f ( t , d ) × i d f ( t , d ) tf\verb|-|idf(t, d) = tf(t, d) \times idf(t, d) tf-idf(t,d)=tf(t,d)×idf(t,d)
最后,通过余弦相似度函数计算用户喜好与其未读文章之间的相似度:
Subsequently, TF-IDF is computed as a multiplication of TF and IDF:
s i m t f - i d f ( d u , d r ) = d r ⋅ d u ∣ ∣ d r ∣ ∣ × ∣ ∣ d u ∣ ∣ sim_{tf\verb|-|idf(d_u, d_r)} = \frac{d_r \cdot d_u}{||d_r|| \times ||d_u||} simtf-idf(du,dr)=∣∣dr∣∣×∣∣du∣∣dr⋅du
其中, d r d_r dr 表示用户喜好向量, d u d_u du 表示未读新闻向量。 s i m t f - i d f ( d u , d r ) sim_{tf\verb|-|idf(d_u, d_r)} simtf-idf(du,dr)越大,表示该未读新闻与用户喜好越接近。在所有未读新闻中,将与用户画像相似度高于一定值的新闻推荐给相应用户。
where d r d_r dr is the vector representation of the user’s interest and d u d_u du is the vector representation of an unread news item. The larger simTF-IDF is, the more similar the unread news item and user’s interest are. All unread news items that have a higher similarity value with a user profile than a certain cut-off value are recommended to the corresponding user.
2.2 基于同义词频率的推荐系统
一种与TF-IDF相似的方法是SF-IDF(Syset Frequency - Inverse Document Frequency; 同义词频率-逆文档频率)。该方法不仅考虑到词项的影响,还进一步考虑了同义词集(synsets)。同义词集从类似 WordNet 的语义词典获取。由于含义模糊,一个词可能存在多个同义词,因此,存在歧义,例如,由 [2] 提出,并于 [15] 实现的自适应Lesk算法(adapted Lesk algorithm)。
A similar method to the TF-IDF method is the Synset Frequency - Inverse Document Frequency (SF-IDF) method [6]. This method uses synonym sets (synsets) associated to terms rather than terms alone. Synsets are provided by a semantic lexicon such as WordNet [10]. Due to ambiguity, a single term can have multiple synsets, thus requiring word sense disambiguation, e.g., by using the adapted Lesk algorithm proposed in [2] and implemented in [15].
译者注
WordNet 是英文语义词典,可以以在线的方式获取同义词、近义词信息等。中文方面,也有类似网站,可自行从开源社区或某些高校、研究院网站获取。
SF-IDF值及其余弦相似度的计算与前文介绍的TF-IDF值几乎一样,只是将词项 t t t 替换为同义词 s,即 s f ( s , d ) = n s , d / Σ k n k , d sf(s, d) = {n_{s, d}}/{\Sigma_k{n_{k,d}}} sf(s,d)=ns,d/Σknk,d 并且 i d f ( s , d ) = l o g ∣ D ∣ / ∣ d ∈ D : s ∈ d ∣ idf(s, d) = log{|D|/|d \in D : s \in d|} idf(s,d)=log∣D∣/∣d∈D:s∈d∣,则
The SF-IDF measure and its corresponding cosine similarity scores are computed using the same equations as introduced for TF-IDF, only by replacing term t t t by synset s s s, so that s f ( s , d ) = n s , d / Σ k n k , d sf(s, d) = n_{s,d}/\Sigma_k{n_{k,d}} sf(s,d)=ns,d/Σknk,d and i d f ( s , d ) = l o g ∣ D ∣ / ∣ d ∈ D : s ∈ d ∣ idf(s, d) = log |D| / |d ∈ D : s ∈ d| idf(s,d)=log∣D∣/∣d∈D:s∈d∣, and hence
s f - i d f ( s , d ) = s f ( s , d ) × i d f ( s , d ) sf\verb|-|idf(s, d) = sf(s, d) \times idf(s, d) sf-idf(s,d)=sf(s,d)×idf(s,d)
之后,用前文定义的余弦相似度计算 s i m S F - I D F sim_{SF\verb|-|IDF} simSF-IDF 即可。
Then, the previously defined cosine similarity is used for computing s i m S F - I D F sim_{SF\verb|-|IDF} simSF-IDF.
2.3 基于概念的推荐系统
概念频率-逆文档频率方法使用领域知识的概念计算相似度,这与直接使用词项或同义词集不同。文章的概念通过自然语言处理(NLP, Natural Language Processing)引擎。对各个文档而言,生成的概念被存储在向量中,并且,这些向量也可以用于计算 CF-IDF 值。与 TF-IDF 和 SF-IDF 类似,CF-IDF 值计算方式如下:
The Concept Frequency - Inverse Document Frequency (CF-IDF) method [12] calculates similarity measures using concepts from a domain ontology rather than terms or synsets. The concepts of an article are obtained using a Natural Language Processing (NLP) engine. For every document, the resulting concepts are then stored in a vector and these vectors can be used to calculate the CF-IDF measure. Similar to TF-IDF and SF-IDF, scores for concept c c c are computed as follows:
c f - i d f ( c , d ) = c f ( c , d ) × i d f ( c , d ) cf\verb|-|idf(c, d) = cf(c, d) \times idf(c, d) cf-idf(c,d)=cf(c,d)×idf(c,d)
此时,概念频率与逆文档频率定义分别为 c f ( c , d ) = n c , d / Σ k n k , d cf(c, d) = n_{c,d} / \Sigma_k{n_{k,d}} cf(c,d)=nc,d/Σknk,d 和 i d f ( c , d ) = l o g ∣ D ∣ / ∣ d ∈ D : c ∈ d ∣ idf(c,d) = log|D| / |d \in D : c \in d| idf(c,d)=log∣D∣/∣d∈D:c∈d∣。 s i m C F − I D F sim_{CF-IDF} simCF−IDF 余弦相似度计算保持不变。
where frequencies and inverse document frequencies are defined as c f ( c , d ) = n c , d / Σ k n k , d cf(c, d) = n_{c,d} / \Sigma_k{n_{k,d}} cf(c,d)=nc,d/Σknk,d and i d f ( c , d ) = l o g ∣ D ∣ / ∣ d ∈ D : c ∈ d ∣ idf(c,d) = log|D| / |d \in D : c \in d| idf(c,d)=log∣D∣/∣d∈D:c∈d∣, respectively. Cosine similarity computations remain unchanged for s i m C F − I D F sim_{CF-IDF} simCF−IDF.
2.4 基于关系的推荐系统
可以用相关同义词或概念扩展 SF-IDF 和 CF-IDF。为此,可以从语义词典和词项本身出发,找出其他相关元素。
Both SF-IDF and CF-IDF can be extended in such a way that also related synsets or concepts are taken into consideration. For this, the semantic lexicon and ontology can be used in order to derive related elements.
SF-IDF+ [17] 认为关联同义词集通过关联关系获取(有 27 种独有的语义关系,如:上下义关系(hyponymy)、反义词、同义词等,这些可以通过 WorNet 获取),并添加到 SF-IDF的向量表示中。对于各同义词,通过SF-IDF值与预定义的权重相乘可以求得相应的 sf-idf+ 值。由于当前词的关联同义词,永远不能不当前词本身更重要,因此,同义词的权重范围在0至1之间。如公式 [7] 所示,它展示了如何将关联的同义词集添加至向量中:
In SF-IDF+ [17], related synsets are considered to be synsets that are connected through a relation (27 unique semantic relationships, e.g., hyponymy, antonymy, synonymy, etc., exist in WordNet), and are added to the vector representation from SF-IDF. For each synset, scores are computed by multiplying the original SF-IDF score with a predefined weight. Weights always range between 0 and 1, as related synsets should never be more important that the synset itself. In Eq. 7, it is shown how the related synsets are added to the vector:
s f - i d f + ( s , d , r ) = s f ( s , d ) × i d f ( s , d ) × ω r sf\verb|-|idf\verb|+|(s, d, r) = sf(s, d) \times idf(s, d) \times \omega_r sf-idf+(s,d,r)=sf(s,d)×idf(s,d)×ωr
用同样的方式扩展CF-IDF(CF-IDF+ [9])。通过三种关联关系,从内容本身的概念获取相关概念。
The same rules apply also for CF-IDF in its extended form (CF-IDF+ [9]). Related concepts are retrieved by taking into account related ontology concepts by three possible relationships, as a concept can have superclasses, subclasses, and domain-specific related concepts. Similarly, the CF-IDF+ value for a concept c c c and its related concept r r r in document d is computed as follows:
c f - i d f + ( c , d , r ) = c f ( c , d ) × i d f ( c , d ) × ω r cf\verb|-|idf\verb|+|(c, d, r) = cf(c, d) \times idf(c, d) \times \omega_r cf-idf+(c,d,r)=cf(c,d)×idf(c,d)×ωr
此时,用前文所述 c c c 与 r r r 的三种关系之一来表示权重 w r w_r wr。在扩展向量表示中,如果同一关联概念(或同义词)存在多个不同的权重,仅保留最大值。所得向量用于计算用户画像与其未读新闻的余弦相似度。
where w r w_r wr represents the weight assigned to one of the three previously mentioned relationships present between c c c and r r r. If multiple weights are computed for the same concept (or synset), only the highest value is retained in the extended vector representation. The extended vector representation is used for computing the similarity between the user profile and the unread news items using the cosine similarity measure.
译者注
同一个关联概念/同义词可能被多个过个本体概念或内容词项关联,即会在关联概念/同义词集中出现多次,并存在多个不同的关联内容。
2.5 基于命名实体的推荐系统
近期,我们又另外尝试在 Bing-SF-IDF+ [7] 算法中,将 SF-IDF+ 与 来自 Bing 的命名实体信息结合,从而获取符合预期的结果。在这里,通过查询 Bing 搜索引擎,并基于包含相应词项的页面数计算相似度,即使是语义词典未收录的命名实体也将被考虑在内。
In recent endeavours, we additionally tried combining SF-IDF+ with named entities from Bing in Bing-SF-IDF+ [7], which showed promising results. Here, named entities that are not covered by the synsets from a semantic lexicon were still taken into account by consulting the Bing search engine and computing similarities based on page counts.
计算结果是 SF-IDF+ 和 Bing相似值的加权平均值,后者是通过共现相似度 (co-occurrence similarity measure) 计算得到的。类似的,我们希望研究 Bing 应用于(相关)概念的优点。
Computations are based on a weighted average of SF-IDF+ and Bing similarity scores, where the latter is computed using a co-occurrence similarity measure. Similarly, we would like to investigate the merits of the application of Bing named entities to (related) concepts.
2.6 性能
多年来,上述方法已经已经得到了充分测试。为了提供参考价值,其中一部分还在不同的条件下多次测试。总的来说,各方法的性能(用F1值表示)如 表1 所示。通常,我们可以认为,基于概念的方法优于基于语义的方法和基础 TF-IDF 方法。此外,基于关系的推荐比其他推荐具有更好的性能。包含命名实体有助于提高推荐质量。
The discussed methods have been thoroughly tested throughout the years. Some have served as a reference, and have been tested multiple times under different conditions. Overall, the performance of the methods (in terms of F1) is as described in Table 1. In general, we can say that concept-based methods outperform synset-based methods and the baseline TF-IDF method. Moreover, relation-based recommenders show a performance improvement over their regular counterparts. Including named entities boosts recommendation quality even more.
Table 1. Average F 1 F_1 F1-measures for the recommenders
| 推荐算法 | μ \mu μ | |
|---|---|---|
| TF-IDF | 0.449 | [7] |
| SF-IDF | 0.468 | [6] |
| CF-IDF | 0.485 | [12] |
| SF-IDF+ | 0.548 | [17] |
| CF-IDF+ | 0.571 | [9] |
| Bing-SF-IDF+ | 0.579 | [7] |
译者注
表格中的 μ \mu μ 表示的是 F1 值,是一种综合考虑 Precision 和 Recall 的度量。
3 框架
我们引入下述两个步骤以改进现有方法:用 Bing 命名实体的点互(point-wise)信息相似度计算 Bing 相似度;用基于概念和关联概念的余弦相似度计算 CF-IDF+ 值。Bing-CF-IDF+ 值即为 Bing 值与 CF-IDF+ 值的加权平均值。用户可以自己选择感兴趣的概念或新闻内容来构建用户画像,我们的方法可以从用户自己构建的画像中提取概念和命名实体。新增的新闻用类似的方式处理,同时,消除领域知识已涵盖的命名实体。
We improve the existing methods by introducing a two-step procedure, in which we compute a Bing similarity score using point-wise mutual information similarities for Bing named entities, and a CF-IDF+ similarity score using cosine similarities based on concepts and related concepts. Bing-CF-IDF+ scores are computed as a weighted average between Bing and CF-IDF+ scores. Our approach makes use of a user profile, which can be constructed manually by a user by selecting either interesting concepts or interesting news items from which concepts and named entities can be extracted. Incoming news messages are processed similarly, while eliminating named entities that are already covered by the domain ontology.
译者注
最后一句描述的过程,个人理解为类似 Charu 所著《Recommender System》中描述的基于知识的推荐系统。
3.1 Bing
基于概念的推荐系统仅适用存在于领域知识中的命名实体。然而,一篇文章中,可能有更多领域以外的命名实体,如果不考虑这部分命名实体,可能导致整个相似度分析错误。
Concept-based recommendation methods only make use of named entities that are included in the domain ontology. However, there could be many more named entities in a single article, that – if they would not be taken into consideration – could skew the entire similarity analysis. Therefore, the Bing similarity measure [7] takes all these named entities into account.
设 U 和 R 分别表示未读新闻中的命名实体和用户画像。
Let U U U and R R R be sets of named entities in an unread news item and the user profile:
U = { u 1 , u 2 , . . . , u k } U = \{u_1, u_2, ... , u_k\} U={u1,u2,...,uk}
R = { r 1 , r 2 , . . . , r k } R = \{r_1, r_2, ... , r_k\} R={r1,r2,...,rk}
未读新闻 U U U 中的命名实体为 u i u_i ui,用户画像 R R R 中的命名实体为 r j r_j rj,U的数量为 k k k,R的数量为 l l l 。则我们定义 U U U 与 R R R 的笛卡尔积如下:
where u i u_i ui is a named entity in unread item U U U, r j r_j rj a named entity in user profile R R R, and k k k and l l l are the number of named entities in the unread item and the user profile, respectively. Now let us define the set of possible named entity pairs from the unread news item and the user profile by taking their cartesian product:
V = U × R = ( < u 1 , r 1 > , . . . , < u k , r l > ) V = U \times R = (<u_1, r_1>, ... ,<u_k, r_l>) V=U×R=(<u1,r1>,...,<uk,rl>)
随后,用 《Normalized (pointwise) mutual information in collocation extraction》[4] 所述方法计算点互信息共现相似度。用 Bing 分别计算各命名实体单独出现的页面数和命名实体对共现页面数。计算方式是通过 Bing 找到的 Web 页面数。对每个命名实体对而言,相似度即为实际联合概率与期望联合概率之差。命名实体对相似度如下:
Subsequently, we compute the point-wise mutual information co-occurrence similarity measure as proposed by [4]. We search the named entities in a pair both separately and together in Bing to construct page counts. A page count is defined as the number of Web pages that are found by Bing. For every pair the similarity is computed as the difference between the actual and the expected joint probability. The similarity measure for a pair is defined as:
s i m P M I ( u , r ) = l o g c ( u , r ) N c ( u ) N × c ( r ) N sim_{PMI}(u, r) = log{\frac{\frac{c(u, r)}{N}}{\frac{c(u)}{N} \times \frac{c(r)}{N}}} simPMI(u,r)=logNc(u)×Nc(r)Nc(u,r)
译者注
以防万一这里提醒一下, l o g A − l o g B = l o g A / B logA - logB = log{A/B} logA−logB=logA/B 。
其中, c ( u , r ) c(u, r) c(u,r) 表示命名实体对 ( u , r ) (u, r) (u,r) 的 (由 Bing 所得)共现页面数。 c ( u ) c(u) c(u) 和 c ( r ) c(r) c(r) 分别为出现命名实体 u u u 和命名实体 r r r 页面数, N N N 是能通过 Bing 获取的 Web 页面总数。N 估计在150左右。 Bing 相似度 s i m B i n g sim_{Bing} simBing 定义如下所示:
where c ( u , r ) c(u, r) c(u,r) is the Bing page count for pair ( u , r ) (u, r) (u,r), c ( u ) c(u) c(u) and c ( r ) c(r) c(r) the page counts for named entities u u u and r r r, and N N N the total number of Web pages that can be found by Bing. N N N is estimated to be around 15 billion. The Bing similarity measure s i m B i n g sim_{Bing} simBing is then defined as:
s i m B i n g ( d u , d r ) = Σ ( u , r ) ∈ V s i m P M I ( u , r ) ∣ V ∣ sim_{Bing}(d_u, d_r) = \frac{\Sigma_{(u, r) \in V}{sim_{PMI}(u, r)}}{|V|} simBing(du,dr)=∣V∣Σ(u,r)∈VsimPMI(u,r)
3.2 CF-IDF+
CF-IDF+ 方法用概念和关联概念计算。概念可以是一个类,关联概念则为其子类或超类;它也可以是一个实例,通过领域关系找到其他概念。概念之间的关系包含新闻文章中有价值的信息,并能提高推荐准确率。与 CF-IDF 类似,CF-IDF+方法将新闻项的概念和关系向量化存储。对于 c c c,包含其所有关联概念的新的概念集合定义如下:
The CF-IDF+ method makes use of concepts and related concepts. A concept can be a class, which can have superclasses and subclasses. It can also be an instance and refer to other concepts using domain relationships. The relations between concepts contain valuable information about a news article and can therefore increase recommendation accuracy. Similar to the CF-IDF method, the CF-IDF+ method stores the concepts and related concepts of a news item into a vector. For every concept c c c, a new set of concepts is defined which contains all related concepts:
C ( c ) = { c } ∪ r ∈ R ( c ) r ( c ) C(c) = \{c\} \cup_{r \in R(c)} r(c) C(c)={c}∪r∈R(c)r(c)
其中, c c c 是新闻项中的概念, r ( c ) r(c) r(c) 是通过关系 r r r 找到的 概念 c c c 的关联概念, R ( c ) R(c) R(c) 为概念 c c c 的关系集合。
where c c c is a concept in the news item, r ( c ) r(c) r(c) are concepts related to concept c c c by relation r r r, and R ( c ) R(c) R(c) is the set of relationships of concept c c c.
所有新闻项的概念的扩展集合合并为如下大集合 U U U :
The extended sets of concepts for all news items are now unified to one large set U U U:
U = { C ( u 1 ) , C ( u 2 ) , . . . , C ( u m ) } U = \{C(u_1), C(u_2), ... ,C(u_m)\} U={C(u1),C(u2),...,C(um)}
其中, C ( u m ) C(u_m) C(um) 是新闻项的扩展概念集合 m t h m^{th} mth 扩展概念
where C ( u m ) C(u_m) C(um) is the m t h m^{th} mth extended concept in the set of extended concepts of the news item. CF-IDF+ scores and their cosine similarities can be computed as introduced earlier using Eqs. 8 and 4. If these scores exceed a predetermined cut-off value, the news item is recommended to the user.
3.3 Bing-CF-IDF+
我们可以计算各未读新闻项与用户画像之间的 Bing 相似度和 CF-IDF+ 相似度。 Bing-CF-IDF 是 Bing 相似度与 CF-IDF+ 相似度的加权组合。对于相似度的相互可比性,用最小最大值归一化至 0 到 1 之间。
We can now calculate the Bing and the CF-IDF+ similarity measures between every unread news item and the user profile. Bing-CF-IDF+ is a weighed combination of the Bing and the CF-IDF+ similarity measures. For inter-comparability of the similarities, s i m C F − I D F + sim_{CF-IDF+} simCF−IDF+ and s i m B i n g ( d u , d r ) sim_{Bing}(d_u, d_r) simBing(du,dr) are normalized using a min-max scaling between 0 and 1:
s i m C F − I D F + ( d u , d r ) = s i m C F − I D F + ( d u , d r ) − m i n u s i m C F − I D F + ( d u , d r ) m a x u s i m C F − I D F + ( d u , d r ) − m i n u s i m C F − I D F + ( d u , d r ) sim_{CF-IDF+}(d_u,d_r) = \frac{sim_{CF-IDF+}(d_u, d_r) - min_usim_{CF-IDF+}(d_u, d_r)}{max_u sim_{CF-IDF+}(d_u, d_r) - min_usim_{CF-IDF+}(d_u, d_r)} simCF−IDF+(du,dr)=maxusimCF−IDF+(du,dr)−minusimCF−IDF+(du,dr)simCF−IDF+(du,dr)−minusimCF−IDF+(du,dr)
s i m B i n g ( d u , d r ) = s i m B i n g ( d u , d r ) − m i n u s i m B i n g ( d u , d r ) m a x u s i m B i n g ( d u , d r ) − m i n u s i m B i n g ( d u , d r ) sim_{Bing}(d_u,d_r) = \frac{sim_{Bing}(d_u, d_r) - min_usim_{Bing}(d_u, d_r)}{max_u sim_{Bing}(d_u, d_r) - min_usim_{Bing}(d_u, d_r)} simBing(du,dr)=maxusimBing(du,dr)−minusimBing(du,dr)simBing(du,dr)−minusimBing(du,dr)
译者注
这里提及『 … normalized using a min-max scaling between 0 and 1 …』,直译是『将…用最小最大缩放至0 到 1 之间』。这个过程其实描述的就是 min-max normalization,有的文献翻译为『最小最大归一化』,有的翻译为『最小最大缩放(Min-max scaling)』。是一种特征缩放方法。通常的范围是 [0, 1] 或 [-1, 1]。
d u d_u du 和 d r d_r dr 分别表示未读新闻项和用户画像。两者加权平均值即为 Bing-CF-IDF+ 相似度 s i m B i n g − C F − I D F + ( d u , d r ) sim_{Bing-CF-IDF+}(d_u, d_r) simBing−CF−IDF+(du,dr) :
where d u d_u du and d r d_r dr are an unread news item and the user profile, respectively. The Bing-CF-IDF+ similarity measure s i m B i n g − C F − I D F + ( d u , d r ) sim_{Bing-CF-IDF+}(d_u, d_r) simBing−CF−IDF+(du,dr) is computed by taking a weighted average over both similarities:
s i m B i n g − C F − I D F + ( d u , d r ) = α × s i m B i n g + ( 1 − α ) × s i m C F − I D F + sim_{Bing-CF-IDF+}(d_u, d_r) = \alpha \times sim_{Bing} + (1 - \alpha) \times sim_{CF-IDF+} simBing−CF−IDF+(du,dr)=α×simBing+(1−α)×simCF−IDF+
其中,在训练集上进行网格搜索对 α \alpha α 优化。当相似度超出预定义阈值 t t t 时,推荐新闻项。请注意,这里只考虑找不到的表示概念的命名实体。
where α \alpha α is optimized using a grid search optimization on the training set. Again a news item is recommended when the similarity measures exceeds the predefined threshold value t t t. Please note that only named entities that are not found as denoting concepts are considered here.
3.4 执行
Bing-CF-IDF+ 推荐系统应用于 Hermes 框架 [11],这是基于 Java 的用语义 Web技术实现的个性化新闻服务。Hermes 抓取了用户查询记录和新闻项的RSS源,并提供多种推荐方法,这些推荐方法使用存储了领域概念的内部知识库。Hermes 基于用户画像提供的推荐结果,用户画像则由相应浏览记录构建。Hermes 包含多个用于扩展基础功能的插件。Athena 插件用内部OWL领域知识进行分类并推荐新闻项 [13]。除了几个基于概念的推荐方法,Athena 还另外提供用户画像构建工具,以许可用户在可视化的知识图谱中,选择相关主题。Ceryx 插件 [6] 作为 Athena 的扩展。与 Athena 类似,Ceryx 也使用用户画像执行任务。然而,关于查找相关新闻项的算法有些许不同。除了对词项和概念分类,Ceryx 还能理解单词的意义。因此,Ceryx 能像 SF-IDF+ 和 CF-IDF+ 一样执行推荐过程。Bing-CF-IDF+ 推荐系统也是为了 Ceryx 编写的。
The Bing-CF-IDF+ recommender is implemented in the Hermes framework [11], which is a Java-based personalizing news service using Semantic Web technologies. Hermes ingests user queries and RSS feeds of news items, and supports multiple recommendation methods using an internal knowledge base for storing ontological concepts. Hermes provides recommendations based on user profiles that are constructed based on browsing behaviour. Hermes contains several plugins that extend the basic functionality. The Athena plug-in classifies and recommends news items using an internal OWL domain ontology [13]. Next to several concept-based recommender methods, Athena supports an additional profile builder, where a user is allowed to select relevant topics in a visual knowledge graph. The Ceryx plug-in [6] is an extension to Athena. Just like Athena, Ceryx works with a user profile. However, the algorithm to find related news items is slightly different. Besides classifying terms and concepts, Ceryx also determines the senses of words. Therefore, Ceryx is capable of handling recommender methods like SF-IDF+ and CF-IDF+. The Bing-CF-IDF+ recommender is also written for Ceryx.
4 评估
为了评估新推出的 Bing-CF-IDF+ 算法,我们比较它与其他基于概念的替代方案,例如:CF-IDF 和 CF-IDF+,以及传统 TF-IDF 文档。本章首先阐述关于数据和性能度量的实验配置。接下来,讨论语义关系的权重及其性质。最后,比较各算法之间的性能。
In order to evaluate the performance of the newly proposed Bing-CF-IDF+ method, we compare it with its concept-based alternatives, i.e., CF-IDF and CF-IDF+, as well as the TF-IDF baseline. This section starts by elaborating on the experimental setup regarding data and performance measures. Next, the weights of the semantic relationships and their properties are discussed. Last, performance measures are compared.
4.1 测试工具
数据集随机切分为训练集(60%)和测试集(40%)。首先,从训练集中添加用户感兴趣的新闻项,用于创建用户画像。最佳权重由验证集确定,验证集由训练集切分得到,即,训练集切分为等大小的验证集和训练集。我们最终得到三个不同的集合:验证集(30%)、训练集(30%)和测试集(40%)。验证集和测试集由未读新闻项组成。可以先用验证集确定最优权重,再用测试集计算性能。
The data set is randomly split into a training set and a test set, with respectively 60% and 40% of the data. First, a user profile is created by adding the interesting news items from the training set. The optimal weights are determined by using a validation set which is created by splitting the training set into two equally-sized sets, i.e., a validation set and a training set. We end up having three different sets: a validation set (30%), a training set (30%), and a test set (40%). The validation set and the test set are considered to consist of ‘unread’ news items. The validation set can now be used to determine the optimal weights, needed to calculate performance measures by using the test set later on.
如前文所述,CF-IDF+ 推荐系统对每个新闻项计算相似度。如若该相似度大于特定临界值,即可向相应用户推荐相应的未读新闻项。推荐结果可以按照真阳性(TP)、假阳性(FP)、真阴性(TN)或假阴性(FN)进行分类。信息检索指标可以从该混淆矩阵选择:精度、召回率(灵敏度)和特异性。此外,我们可以由此求得 F1 值(用精度和召回率的调和平均值)和 ROC 曲线(对假阳性率逆运算或 1 减灵敏度得到的真阳性率或灵敏度)。最后,我们通过计算 Kappa 统计 [8] 来验证分类能力是否高于随机猜测。语义关系的参数单独通过增量过程,优化全局 F1 值进行优化。此外,确定 Bing 和 CF-IDF+ 的权重 α \alpha α 参数也用类似方式优化。
As discussed before, the CF-IDF+ recommender computes similarity measures for every unread news item. In case this similarity measure exceeds a certain cut-off value, the unread news item is recommended to the user. The results of the recommenders can be classified for news items as either true positive (TP), false positive (FP), true negative (TN), or false negative (FN). A selection of information retrieval metrics can be deduced from this confusion matrix: precision, recall (sensitivity), and specificity. Additionally, we can deduce the F1-scores (i.e., the harmonic mean of precision and recall) and ROC-curve (i.e., the True Positive Rate or sensitivity plotted against the False Positive Rate or 1 − specificity) from these measures. Last, we compute the Kappa statistic [8] to verify whether the classification power is higher than a random guess. The parameters for semantic relationships are optimized individually through an incremental procedure, optimizing the global F1-scores. Additionally, the α parameter that determines the weight of the Bing and CF-IDF+ parts is optimized similarly.
Table 2. Amount of interesting (I+) and non-interesting (I−) news items, and the inter-annotator agreement (IAA)
| Topic | I+ | I- | IAA |
|---|---|---|---|
| Asia or its countries | 21 | 79 | 99% |
| Financial markets | 24 | 76 | 72% |
| Google or its rivals | 26 | 74 | 97% |
| Web services | 26 | 74 | 94% |
| Microsoft or its rivals | 29 | 71 | 98% |
| National economies | 33 | 67 | 90% |
| Technology | 29 | 71 | 87% |
| United States | 45 | 55 | 85% |
Table 3. Mean and variance for the parameters of the Bing-CF-IDF+ recommender
| w s u p e r w_{super} wsuper | w s u b w_{sub} wsub | w r e l w_{rel} wrel | α \alpha α | |
|---|---|---|---|---|
| $ \mu $ | 0.426 | 0.384 | 0.523 | 0.170 |
| σ 2 \sigma^2 σ2 | 0.135 | 0.120 | 0.103 | 0.020 |
4.2 参数优化
对于每个临界值, 以 0.01 为步进值(增量),以此优化超类、子类、领域关系的权重参数,同时,平衡两个相似性度量的 α \alpha α。结果如 Table 3 所示,计算了这些参数的均值和方差。
For each cut-off value, with an increment of 0.01, we optimize the weight parameters for superclass, subclass, and domain relationships, and the α α α that balances the two similarity measures. The results are displayed in Table 3, where the mean and variance of each of these parameters are computed.
通常,必应相似度比 CF-IDF+ 权重更低,表明 Bing 的输入值比语义关系对我们的推荐系统影响更低。这表明一个事实:概念比命名实体包含更多信息。此外,266个已识别的命名实体中,有44个出现在我们已使用的领域知识中,这表明丢失了20%的可用命名实体。尽管如此, α \alpha α 值也大于0,因此,在推荐方法中使用 Bing 的命名实体是有用的。至于语义关系,在均值方面,领域关系中的概念($ w_{rel}$)似乎比子类、超类中的概念(分别为 w s u b w_{sub} wsub 和 w s u p e r w_{super} wsuper)更重要,同时,通过超类中的概念比子类关系得到的概念更重要。这符合 [9] 的研究成果,也符合我们的预期——因为,对于用户感兴趣的物品,超类提供了更泛化的一般信息,而子类只是用户兴趣更进一步的具现。
On average, the Bing similarity measure has a lower weight than the CF-IDF+ measure, indicating that input from Bing has a lower impact on our recommender than the semantic relationships. This can be explained by the fact that concepts contain more informational value than named entities. Moreover, 44 out of 266 identified named entities appear in our employed ontology, indicating a loss of 20% of the available named entities. Nonetheless, α α α is greater than zero, and thus there is a use to employing named entities from Bing in the recommendation method. As for the semantic relationships, on average, concepts retrieved through domain relationships seem ( w r e l w_{rel} wrel) to be more important than sub- and superclasses ( w s u b w_{sub} wsub and w s u p e r w_{super} wsuper, respectively), and concepts retrieved through superclasses are more important than those deduced from subclass relations. This corresponds to the results of [9], and match our expectations, as superclasses give more general information about the topic of interest whereas subclasses risk to be too specific.
译者注
最后一句,按照个人理解意译了。
4.3 测试结果
现在,确定了每个临界值的最优值,我们可以计算全局精度、召回率和 F1 值。Table 4 展示了没饿个推荐系统的 F1 值的均值,强调一下,Bing-CF-IDF+ 比其他推荐系统表现更好。实际上,推荐系统越复杂,平均性能越好。如 Table 5 所示,除 CF-IDF 优于 TF-IDF 外,所有改进都是有效的。
Now that the optimal values of the parameters are determined for each cut-off value, we can compute the global precision, recall, and F1-measures. Table 4 displays the mean F1-scores for each recommender, underlining that Bing-CF-IDF+ outperforms the other recommenders. In fact, the more complex the recommender, the better the average performance. As shown in Table 5, all improvements are significant, except for CF-IDF over TF-IDF.
我们的观察结果如 Fig. 1a 所示。从该图表来看,显然,在整个临界值范围内,Bing-CF-IDF+ 都优于其他推荐系统。在低临界值范围内,TF-IDF 比 CF-IDF 和 CF-IDF+ 有更好的表现(低于预期的召回率,和高于预期的精度)。由于 CF-IDF 变种的性质,这一结果符合预期,因为当使用概念而非词项(或命名实体),我们用少量的特征,采取更严格的方式来匹配(用户兴趣项)。
Our observations are also supported by Fig. 1a. From the plot, it is evident that, throughout the range of cut-off values, Bing-CF-IDF+ outperforms the other recommenders consistently. TF-IDF is more performant for lower cutoff values (i.e., higher expected recall and lower expected precision) than CF-IDF and CF-IDF+. Due to the nature of CF-IDF variants, this is an expected outcome, because when using concepts rather than terms (or named entities for that matter), we enforce a much more restricted approach with a very limited amount of tokens (concepts) to match on.
Fig. 1b 和 Fig. 1c 也体现了这一点。这些图表还表明,尽管 Bing-CF-IDF+ 的召回率和 CF-IDF+ 很相似,但 Bing-CF-IDF+ 的精度明显高于 CF-IDF+。因此,引入语义关系似乎改善了召回率,同时额外引入 Bing 命名实体改善精度并未影响 CF-IDF 的召回率。
This is also depicted in Fig. 1b and 1c. These figures also show that, while recall for Bing-CF-IDF+ and CF-IDF+ is very similar, the precision of BingCF-IDF+ clearly improves over CF-IDF+. Recall for CF-IDF (and TF-IDF) is much lower. Therefore, it seems that the addition of semantic relations improves recall, and the additional inclusion of Bing named entities improves precision, without making concessions to the recall of CF-IDF.
下一步,我们评估Bing-CF-IDF+、CF-IDF+、CF-IDF 和 TF-IDF 推荐方法的接受者操作特征曲线(ROC curves)。ROC曲线如 Fig. 2 所示,Bing-CF-IDF+ 和 CF-IDF+ 的假阳性率优于 CF-IDF 和 TF-IDF。这表明 Bing-CF-IDF+ 和 CF-IDF+ 在更多复杂情况下,更能抑制假阳性,召回率(真阳性率)更高,拥有更高的精度。然而,在物品宏观角度而言,不同推荐系统之间的曲线面积只有细微差异(大约为 0.85)。Bing-CF-IDF+ 比 TF-IDF 拥有更高的精度和更低的召回率。
Next we evaluate the Receiver Operating Characteristic (ROC) curves for the Bing-CF-IDF+, CF-IDF+, CF-IDF, and TF-IDF recommenders. The ROC curve in Fig. 2 shows that the Bing-CF-IDF+ and CF-IDF+ outperform CFIDF and TF-IDF for low False Positive Rates. This indicates that recall (True Positive Rate) is higher for (Bing-)CF-IDF+ in more difficult situations against a handful of false positives, i.e., a higher precision. However, in the grand scale of things, the areas under the curve differ only slightly between the recommenders (value is approximately 0.85). This is in line with the higher precision and lower recall of Bing-CF-IDF+ when compared to TF-IDF.
译者注
这里作者说了一大堆,总结起来就是,根据 Fig. 2 我们可以知道,Bing-CF-IDF+ 和 CF-IDF+ 比 CF-IDF 和TF-IDF 拥有更高的精度和更低的召回率(误判可能性较低)。
最后,我们通过计算 Kappa 统计判断推荐系统分类是否优于随机猜测分类。其值越高,表明分类效果越好。不同临界值的 Kappa 统计如 Fig. 3 所示。由图可知,Bing-CF-IDF+ 推荐方法的 Kappa 统计比其他三个推荐方法的 Kappa 统计更高。只有临界值为0.25时,Bing-CF-IDF+ 的系数与 TF-IDF 类似,并且临界值为0.70时与 CF-IDF+ 一致。因为 Bing-CF-IDF+ 推荐方法的 Kappa 统计整体而言明显较高,因此,我们可以说,整体而言,Bi那个-CF-IDF+拥有比 CF-IDF+,CF-IDF 和 TF-IDF 推荐方法更好的分类能力。
Last, we compute the Kappa statistic to measure whether the proposed classifications made by the recommender are better than classification made by a random guess. Higher values indicate more classification power, and are preferred. In Fig. 3, the results of the Kappa statistic can be found for varying cut-off values. The plot shows that overall, the Kappa statistic of the BingCF-IDF+ recommender is higher than the Kappa statistic of the other three recommenders. Only for a cut-off value of 0.25, the statistics of the Bing-CF-IDF+ and the TF-IDF are similar, and for cut-off value 0.70 the statistics of the Bing-CF-IDF+ and the CF-IDF+ are alike. Because the Bing-CF-IDF+ recommender clearly has higher values for the Kappa statistic over all cut-off values, we can state that overall, the Bing-CF-IDF+ has more classification power than the CF-IDF+, CF-IDF, and TF-IDF recommenders.
Fig. 1. Global precision, recall, and F1 scores for the recommenders
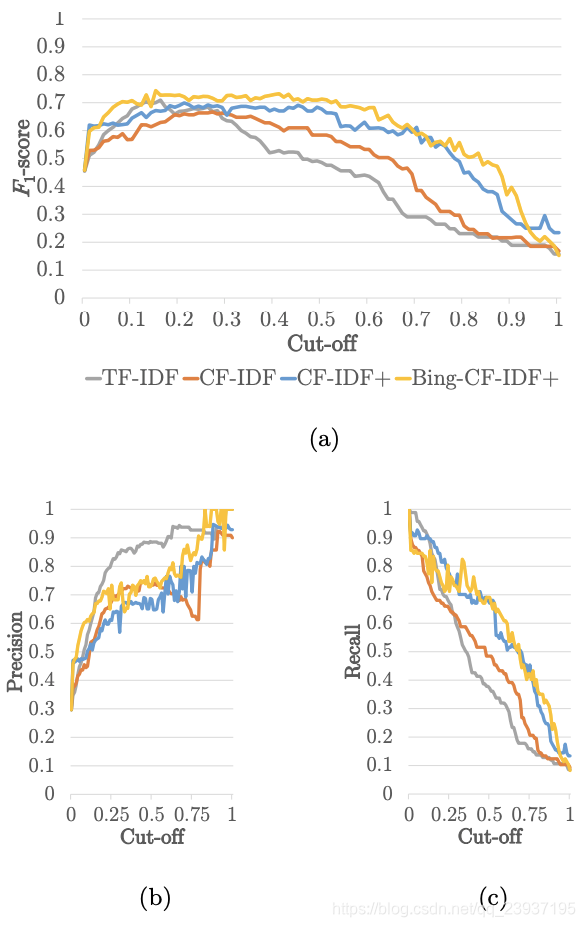
Fig. 2. ROC curve for the recommenders
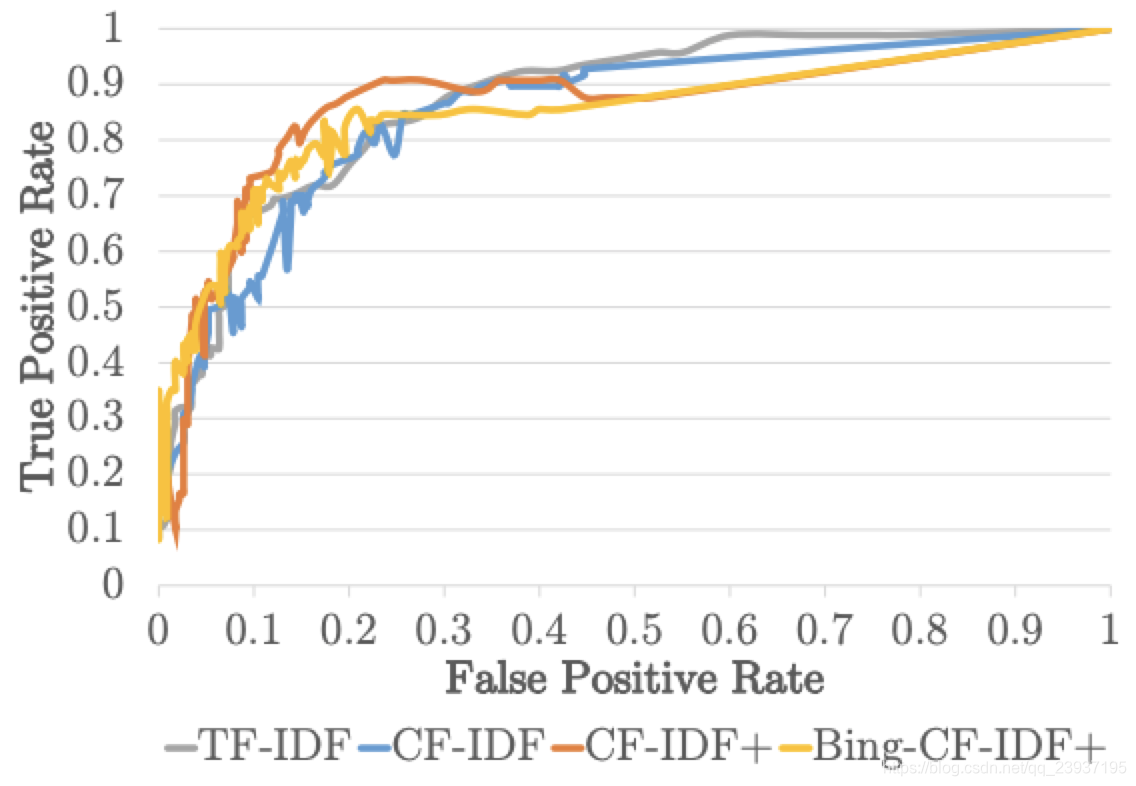
Fig. 3. Kappa statistics for the recommenders
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lk51CqRz-1589347021601)(image-20200513103222972.png)]](https://img-blog.csdnimg.cn/20200513132200715.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzIzOTM3MTk1,size_16,color_FFFFFF,t_70)
5 总结
在之前的工作中,已经出现了一些新的推荐算法。传统的基于词的 TF-IDF 改进为类似考虑语义词典中同义词集的 SF-IDF 和 考虑领域知识的概念的 CF-IDF 的方法。CF-IDF+ 还基于类似子类与超类的相关概念匹配新闻项内容。但是,当某个命名实体被领域知识忽略,则其也不会出现在推荐结果中。因此,我们引入 Bing-CF-IDF+ 相似度,它在 CF-IDF+ 相似性度量的基础上,增加命名实体的Bing Web 搜索相似度值,从而增加了两个步骤。
In previous work, several new recommendation methods have been proposed. The traditional term-based TF-IDF was improved by methods like SF-IDF and CF-IDF, which take into account synsets from a semantic lexicon and concepts from a domain ontology, respectively. The CF-IDF+ similarity measure also matches news items based on related concepts like sub- and superclasses. However, named entities are not fully covered in recommendations whenever they are omitted in the domain ontology. Therefore, we have introduced the BingCF-IDF+ similarity measure, which is a two-step procedure that extends the CF-IDF+ similarity measure with Bing Web search similarity scores for named entities.
为了评估新的 Bing-CF-IDF+ 推荐系统的性能,我们已经优化了 Bing 和 CF-IDF+ 中,概念间的语义关联性的权重。语义关系、基于概念和基于命名实体的推荐系统的参数使用网格搜索(grid search)优化,以最大化每个临界值的全局 F 1 F1 F1 值,即,最小值新闻项被推荐的最小值(可能性)。我们已经用100条金融新闻项和8个用户画像测试 Bing-CF-IDF+ 的性能。我们评估结果表明,Bing-CF-IDF+ 相似性度量在 F 1 F1 F1 值和 Kappa 统计方面,优于 TF-IDF、CF-IDF 和 CF-IDF+。
In order to evaluate the performance of the new Bing-CF-IDF+ recommender, we have optimized the weights for the semantic relationships between the concepts and for the Bing and CF-IDF+ recommenders themselves. These parameters are optimized using a grid search for both the semantic relationships and the concept-based and named entity-based recommenders, while maximizing the global F 1 F1 F1-measure per cut-off value, i.e., the minimum score for a news item to be recommended. We have tested the performance of Bing-CF-IDF+ against existing recommenders on 100 financial news items and 8 user profiles. In our evaluation, we have shown that the Bing-CF-IDF+ similarity measure outperforms TF-IDF, CF-IDF, and CF-IDF+ in terms of the F 1 F1 F1 measure and the Kappa statistic.
我们设想未来各种各样的工作方向。现在已经用增量网格搜索完成了参数优化。还可以用诸如基因演进算法进一步改进策略。此外,我们希望研究更大的关系集合。现在,我们已经考虑了直接超类和子类。但假设概念的非直接超类和子类也很有价值。最后,基于更大新闻项集合进行更彻底而权威的评估,将更能体现 Bing-CF-IDF+ 的强大性能。
We envision various directions for future work. Parameter optimization has been performed using an incremental grid search. This could improved by applying more advanced optimization strategies, such as genetic algorithms. Moreover, we would like to investigate a larger collection of relationships. Now, we have considered the direct super- and subclasses, but hypothetically, non-direct superand subclasses of concepts could be valuable as well. Last, a more thorough and powerful evaluation based on a larger set of news items would further underline the strong performance of Bing-CF-IDF+.
译者注
网格搜索(grid-search)是一种调参手段。是枚举搜索的一种。比如,一个模型有两个参数,分别为 A 和 B,列出A的所有可能和B的所有可能,各自代表一个维度,则可以得到一个二维表,表中每一个元素都是一种可能性。此时,网格搜索的方法是,遍历这个表,将所有参数组合情况依次代入模型中,以计算各个组合情况的的性能,可以得到至少一种性能最高的参数组合情况。推荐参考:https://www.jiqizhixin.com/graph/technologies/0b250c7d-d9ad-4c03-8503-c0b9e82685a3。
参考文献
- Adomavicius, G., Tuzhilin, A.: Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Transactions on Knowledge and Data Engineering 17(6), 734–749 (2005)
- Banerjee, S., Pedersen, T.: An adapted Lesk algorithm for word sense disambiguation using WordNet. In: Gelbukh, A.F. (ed.) 4th International Conference on Computational Linguistics and Intelligent Text Processing (CICLING 2002). Lecture Notes in Computer Science, vol. 2276, pp. 136–145. Springer (2002)
- Bing: Bing API 2.0. Whitepaper. From: http://www.bing.com/developers/s/APIBasics.html (2018)
- Bouma, G.: Normalized (pointwise) mutual information in collocation extraction. In: Chiarcos, C., de Castilho, R.E., Stede, M. (eds.) Biennial GSCL Conference 2009 (GSCL 2009). pp. 31–40. Gunter Narr Verlag T¨ubingen (2009)
- Burke, R.: Hybrid recommender systems: Survey and experiments. User Modeling and User-Adapted Interaction 12(4), 331–370 (2002)
- Capelle, M., Moerland, M., Frasincar, F., Hogenboom, F.: Semantics-based news recommendation. In: Akerkar, R., B˘adic˘a, C., Dan Burdescu, D. (eds.) 2nd International Conference on Web Intelligence, Mining and Semantics (WIMS 2012). ACM (2012)
- Capelle, M., Moerland, M., Hogenboom, F., Frasincar, F., Vandic, D.: Bing-SFIDF+: A hybrid semantics-driven news recommender. In: Wainwright, R.L., Corchado, J.M., Bechini, A., Hong, J. (eds.) 30th Symposium on Applied Computing (SAC 2015), Web Technologies Track. pp. 732–739. ACM (2015)
- Cohen, J.: A coefficient of agreement for nominal scales. Educational and Psychological Measurement 20(1), 37–46 (1960)
- de Koning, E., Hogenboom, F., Frasincar, F.: News recommendation with CFIDF+. In: Krogstie, J., Reijers, H.A. (eds.) 30th International Conference on Advanced Information Systems Engineering (CAiSE 2018). Lecture Notes in Computer Science, vol. 10816, pp. 170–184. Springer (2018)
- Fellbaum, C.: WordNet: An Electronic Lexical Database. MIT Press (1998)
- Frasincar, F., Borsje, J., Levering, L.: A Semantic Web-based approach for building personalized news services. International Journal of E-Business Research 5(3), 35–53 (2009)
- Goossen, F., IJntema, W., Frasincar, F., Hogenboom, F., Kaymak, U.: News personalization using the CF-IDF semantic recommender. In: Akerkar, R. (ed.) International Conference on Web Intelligence, Mining and Semantics (WIMS 2011). ACM (2011)
- IJntema, W., Goossen, F., Frasincar, F., Hogenboom, F.: Ontology-based news recommendation. In: Daniel, F., Delcambre, L.M.L., Fotouhi, F., Garrig´os, I., Guerrini, G., Maz´on, J.N., Mesiti, M., M¨uller-Feuerstein, S., Trujillo, J., Truta, T.M., Volz, B., Waller, E., Xiong, L., Zim´anyi, E. (eds.) International Workshop on Business intelligencE and the WEB (BEWEB 2010) at 13th International Conference on Extending Database Technology and Thirteenth International Conference on Database Theory (EDBT/ICDT 2010). ACM (2010)
- Jannach, D., Resnick, P., Tuzhilin, A., Zanker, M.: Recommender systems - beyond matrix completion. Communications of the ACM 59(11), 94–102 (2016)
- Jensen, A.S., Boss, N.S.: Textual Similarity: Comparing Texts in Order to Discover How Closely They Discuss the Same Topics. Bachelor’s Thesis, Technical University of Denmark (2008)
- Jones, K.S.: A statistical interpretation of term specificity and its application in
retrieval. Journal of Documentation 28(1), 11–21 (1972) - Moerland, M., Hogenboom, F., Capelle, M., Frasincar, F.: Semantics-based news recommendation with SF-IDF+. In: Camacho, D., Akerkar, R., Rodr´ıguez-Moreno, M.D. (eds.) 3rd International Conference on Web Intelligence, Mining and Semantics (WIMS 2013). ACM (2013)
- Robal, T., Haav, H., Kalja, A.: Making Web users’ domain models explicit by applying ontologies. In: Hainaut, J., Rundensteiner, E.A., Kirchberg, M., Bertolotto, M., Brochhausen, M., Chen, Y.P., Cherfi, S.S., Doerr, M., Han, H., Hartmann, S., Parsons, J., Poels, G., Rolland, C., Trujillo, J., Yu, E.S.K., Zim´anyi, E. (eds.) Advances in Conceptual Modeling - Foundations and Applications, ER 2007 Workshops CMLSA, FP-UML, ONISW, QoIS, RIGiM, SeCoGIS. Lecture Notes in Computer Science, vol. 4802, pp. 170–179. Springer (2007)
- Robal, T., Kalja, A.: Conceptual Web users’ actions prediction for ontology-based browsing recommendations. In: Papadopoulos, G.A., Wojtkowski, W., Wojtkowski, W.G., Wrycza, S., Zupancic, J. (eds.) 17th International Conference on Information Systems Development (ISD 2008). pp. 121–129. Springer (2010)
- Robal, T., Kalja, A.: Applying user domain model to improve Web recommendations. In: Caplinskas, A., Dzemyda, G., Lupeikiene, A., Vasilecas, O. (eds.) Databases and Information Systems VII - Selected Papers from the Tenth International Baltic Conference (DB&IS 2012). Frontiers in Artificial Intelligence and Applications, vol. 249, pp. 118–131. IOS Press (2013)
- Salton, G., Buckley, C.: Term-weighting approaches in automatic text retrieval. Information Processing and Management 24(5), 513–523 (1988)
- Sekine, S., Ranchhod, E. (eds.): Named Entities: Recognition, clasification and use. John Benjamins Publishing Company (2009)