目录
📚Hadoop介绍
📚Hadoop优点
📚Hadoop的体系结构
🐰HDFS的体系结构
🐰MapReduce的体系结构
🐰HDFS和MapReduce的协同作用
📚Hadoop与分布式开发
🐰MapReduce计算模型
📚Hadoop介绍
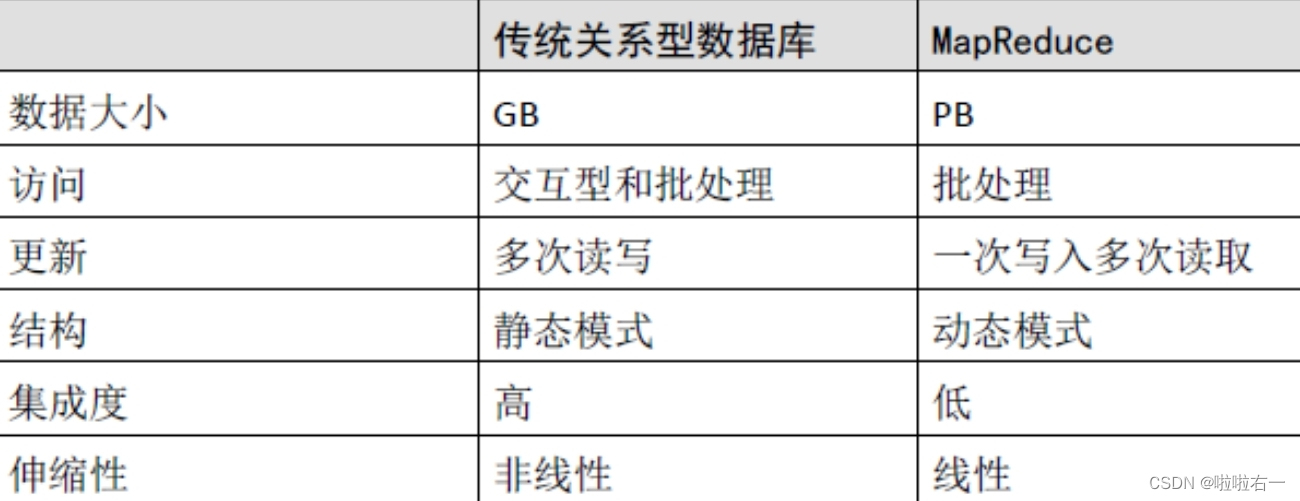
Hadoop是一个开源的可运行于大规模集群上的分布式并行编程框架,它实现了Map/Reduce计算模型。
狭义上说,Hadoop的核心组件有:
- HDFS(分布式文件系统):解决海量数据存储
- MapReduce(分布式运算编程框架):解决海量数据计算
- YARN(作业调度和集群资源管理的框架):解决资源任务调度
📚Hadoop优点
- Hadoop是可靠的:因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
- Hadoop是高效的:因为它以并行的方式工作,通过并行处理加快处理速度。
- Hadoop是可伸缩的:它能够处理PB级数据,即有扩容能力。
- Hadoop成本低:依赖于廉价服务器,因此它的成本比较低,任何人都可以使用。
由于Hadoop优势突出,基于Hadoop的应用已经遍地开花,尤其是互联网领域。

📚Hadoop的体系结构
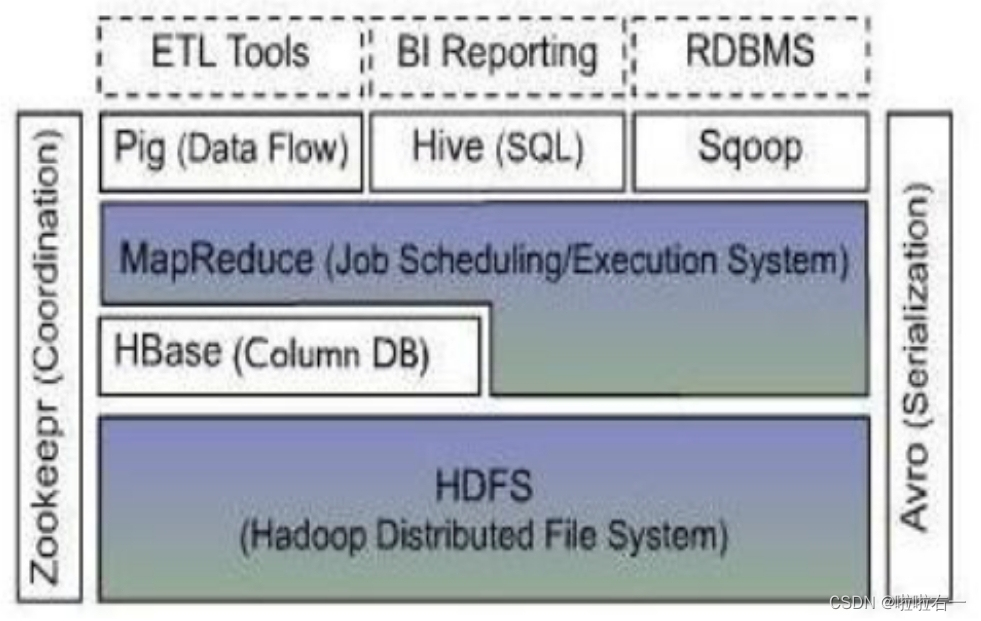
- HDFS是一种分布式文件系统,运行于大型商用机集群,HDFS提供了高可靠性的底层存储支持。
- HBase位于结构化存储层,是一个分布式的列存储数据库。
- MapReduce是一种分布式数据处理模式和执行环境。
- Zookeeper是一个分布式的,高可用性的协调服务,提供分布式锁之类的基本服务。
- Hive是一个建立在Hadoop基础上的数据仓库,用于管理存储于HDFS或HBase中的结构化/半结构化数据。
- Pig提供一种数据流语言,程序员可以将复杂的数据分析任务实现为Pig操作上的数据流脚本,这些脚本可自动转换为MapRduce任务链,在Hadoop上执行,从而简化工作难度。
- Sqoop是SQL-to-Hadoop的缩写,为在RDBMS与Hadoop平台间进行快速批量数据交换。
🐰HDFS的体系结构
- 一个HDFS集群是由一个NameNode和若干个DataNode组成。
- NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;
- 集群中的DataNode管理存储的数据。
- HDFS支持用户以文件的形式存储数据,文件被分为若干个数据块,而且这若干个数据块存放在一组DataNode上。
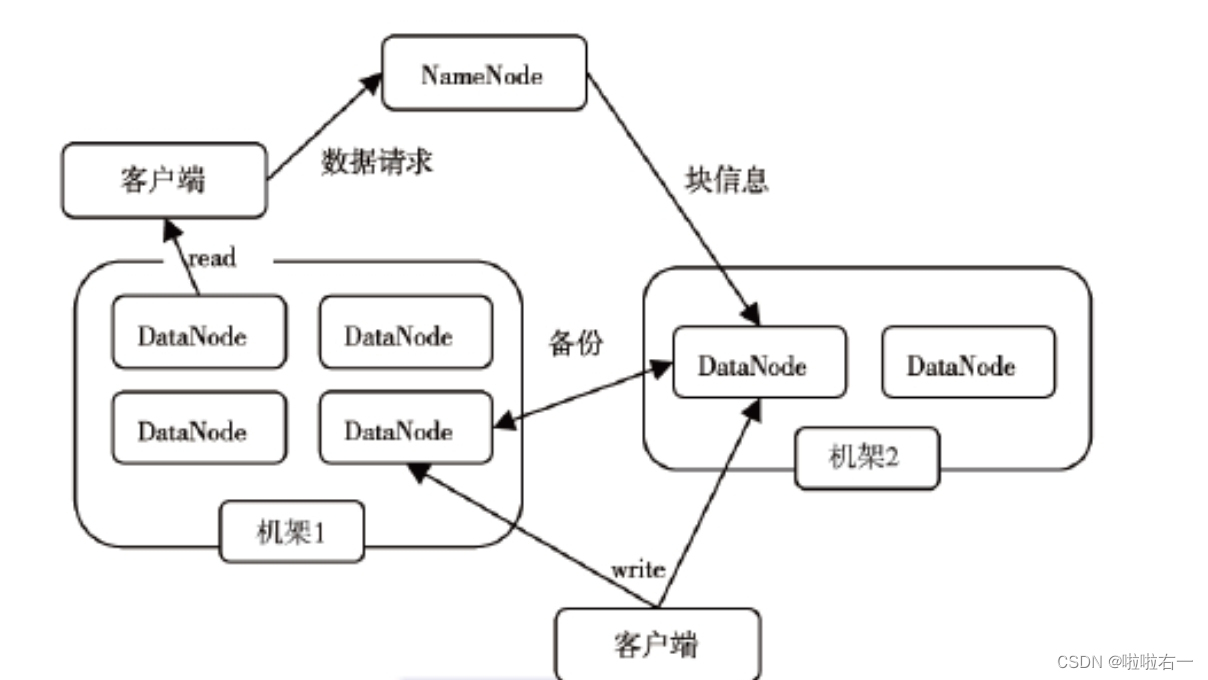
NameNode:就是master,它是一个主管,管理者。管理HDFS的命名空间,管理数据块(Block)映射信息,配置副本策略,处理客户端读写请求。
DataNode:就是Slave,它是劳累的打工人。NameNode下达命令,DataNode执行实际操作。存储实际的数据块,执行数据块的读写操作,定时向NameNode汇报block信息。
🐰MapReduce的体系结构
- MapReduce是一种并行编程模式。基于它可以将任务分发到由上千台商用计算机组成的集群上,并以一种高容错的方式并行处理大量的数据集,实现Hadoop的并行任务处理功能。
- MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点上的TaskTracker共同组成的。
- 主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上;主节点监控它们的执行情况,并且重新执行之前失败的任务。从节点仅负责由主节点指派的任务。
- 当一个Job被提交时,JobTracker接受到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
🌟MapReduce编程模型与Hadoop分布式开发息息相关,下文会做详细介绍。
🐰HDFS和MapReduce的协同作用
- HDFS在集群上实现了分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。
- HDFS在MapReduce任务处理中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果。
- TaskTracker和DataNode需配对地设置在同一个物理的从节点服务器上;JobTracker和NameNode可以设置在同一个物理主控节点服务器上,也可以分开设置
HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心,二者相互作用,完成了Hadoop分布式集群的主要任务。
📚Hadoop与分布式开发
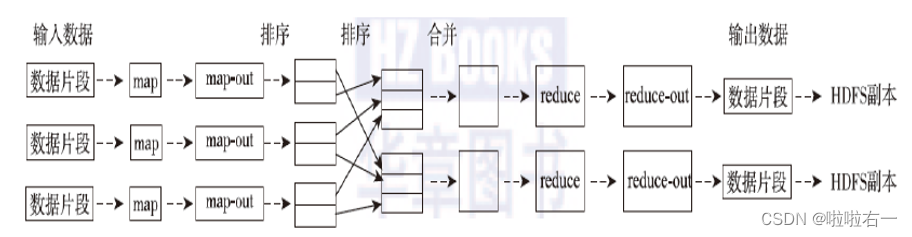
基于MapReduce的处理过程示例--文档词频统计:WordCount
- 将大数据集分解为成百上千个小数据集,每个(或若干个)数据集分别由集群中的一个节点进行处理并生成中间结果,然后这些中间结果又由大量的节点合并,形成最终结果。
- MapReduce框架下并行程序结构中,需要用户完成的工作仅仅是根据任务编写Map和Reduce函数。


🐰MapReduce计算模型
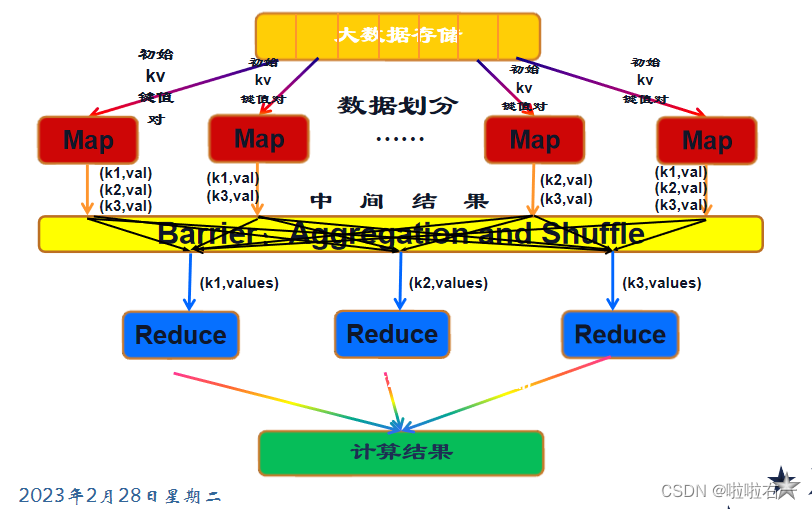
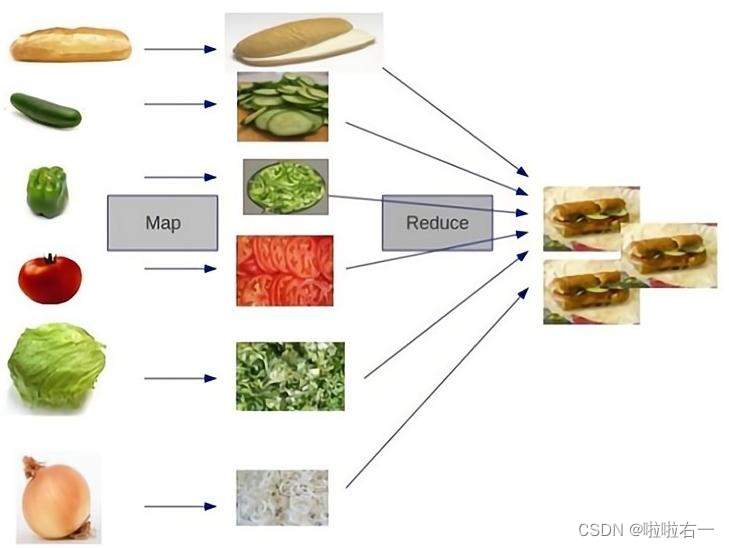
MapReduce编程模型的原理:利用一个输入的key/value对集合,来产生一个输出的key/value对集合。这个过程基于Map和Reduce这两个用户自定义函数实现。
- Map阶段:是在单机上进行的针对一小块数据的计算过程,简单来说,就是按照给定的方法进行筛选分类。
- Shuffle阶段:在map阶段的基础上,进行数据移动,为后续的reduce阶段做准备。简单说就是shuffle将同类型的数据进行合并。
- Reduce阶段:对移动后的数据进行处理,依然是在单机上处理一小份数据,举个例子,对Shuffle得到的合并后的数据进行count,得到sum值。
关于Shuffle:
- shuffle的意思就是洗牌,它是MapReduce的核心,也是被称为奇迹发生的地方。MapReduce玩的就是洗数据,然后让数据出现在该出现的位置。
碎碎念:
- Shuffle阶段所进行的洗牌,可借助哈希表实现,将对应的数据放到相应的“桶”里,从而实现同类型的合并。
- MapReduce思想有种“分而治之”的味道。Map负责“分”,Reduce负责“合”。
参考博客:Lansonli【Hadoop专栏】
be happy——