文章目录
- GPU计算
- 1. GPU和CPU的区别
- 2. GPU的主要参数解读
- 3. 如何在pytorch中使用GPU
- 4. 市面上主流GPU的选择
GPU计算
1. GPU和CPU的区别
设计目标不同,CPU基于低延时,GPU基于高吞吐。
- CPU:处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理
- GPU:处理类型高度统一的、相互无依赖的大规模数据,不需要被打断的纯净的计算环境
什么类型的程序适合在GPU上运行?
- 计算密集型
- 易于并行的程序
2. GPU的主要参数解读
- 显存大小:当模型越大或者训练时的批量越大时,所需要的显存就越多。
- FLOPs:每秒浮点运算次数(亦称每秒峰值速度)是每秒所运行的浮点运算次数(英语:Floating-point operations per second;缩写:FLOPS)的简称,被用来估算电脑性能,尤其是在使用到大量浮点运算的科学计算领域中。
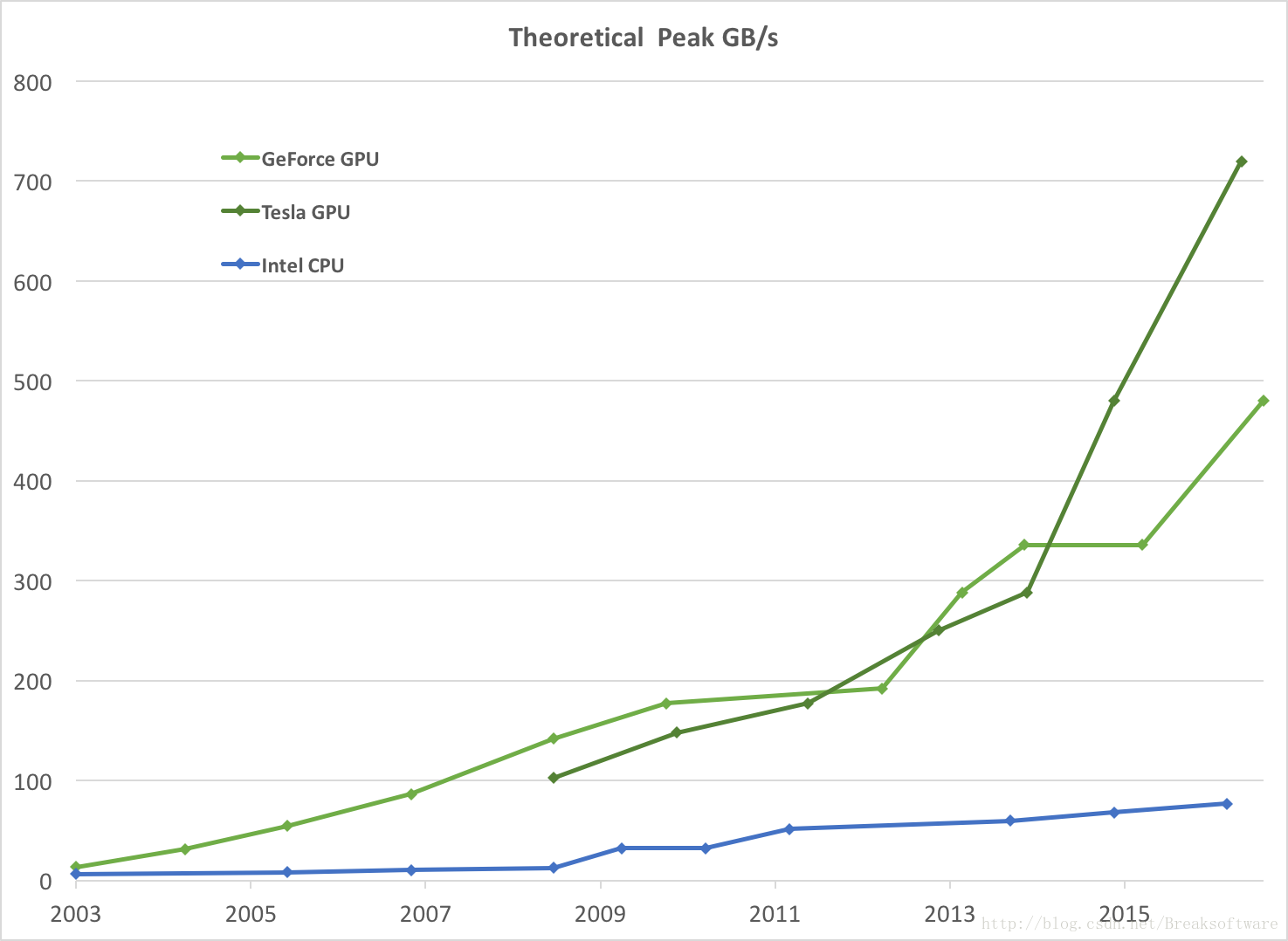
- 显存带宽:显存在一个时钟周期内所能传送数据的位数;位数越大则瞬间所能传输的数据量越大。
3. 如何在pytorch中使用GPU
- 模型转为cuda
- 数据转为cuda
- 输出数据去cuda,转为numpy


如果有可用的数个GPU:可以设置dev="cuda:0"或dev="cuda:1"。需要注意的是,如果使用多卡进行训练和预测,可能会出现部分计算结果丢失的情况。在有GPU条件下,可以尝试“训练用单卡,预测用多卡”、“训练用多卡、预测用单卡”等几种情况下的结果。
4. 市面上主流GPU的选择
参考:https://www.bybusa.com/gpu-rank
https://zhuanlan.zhihu.com/p/61411536
http://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/
使用主机机箱配置或者(云)服务器,不要使用笔记本。
入门免费:Colab,Kaggle(RTX 2070)
针对不同深度学习架构,GPU参数的选择优先级是不一样的,总体来说分两条路线:
卷积网络和Transformer:张量核心>FLOPs(每秒浮点运算次数)>显存带宽>16位浮点计算能力
循环神经网络:显存带宽>16位浮点计算能力>张量核心>FLOPs
欢迎各位关注我的个人公众号:HsuDan,我将分享更多自己的学习心得、避坑总结、面试经验、AI最新技术资讯。