本次送书之前先给大家介绍我的好友周萝卜,他是一个非常有趣的人,经常使用python做一些骚操作!今天这篇文章就是他给大家带来的分享。下面是他的公众号,大家感兴趣的可以关注一下他哦!
正文开启
当我们进入王者荣耀游戏客户端,是可以在英雄关系页面看到不同英雄之间的关联信息的,比如花木兰和兰陵王之间的宿命,安其拉和亚瑟的单恋以及露娜与铠那命运弄人的兄妹之情等等
要厘清这些英雄之间的关系,还是比较困难的,尤其是还有很多中心英雄,与其有关系的英雄多大数十个。今天我们就通过 neo4j 数据库来处理这些错综复杂的关系,看看一直伴随我们每个王者峡谷的英雄都有着怎样的“朋友圈”呢
数据获取
找了很久,还是在网上找到了一个比较全面的英雄关系数据
https://www.haosix.com/gonglue/411

网页很简单,直接上 requests 爬取即可
import requests
from bs4 import BeautifulSoup
import pandas as pd
import os
import csvres = requests.get("https://www.haosix.com/gonglue/411")然后我们通过 beautifulsoup 来解析网页
soup = BeautifulSoup(res.text)
div = soup.find('div', class_="bbcode-body bbcode-body-v2 markdown-body")
p_list = div.find_all("p")[2:-1]现在列表 p_list 当中就是我们需要的数据了
接下来我们编写一个处理数据的函数,把网页上的数据转换成我们需要的形式
def deal_str(data):rel_dict = {}name = data.split(":")name1 = name[0]name_rel = name[1].split("、")if r"(" in name_rel[0]:for i in name_rel:tmp = i.split("(")rel_dict[tmp[0]] = tmp[1].split(")")[0]return [name1, rel_dict]return [name1, "无"]我们来看下函数效果
deal_str('裴擒虎:杨玉环(女神与同伴)、公孙离(收留之人与同伴)、弈星(互补的同伴)、明世隐(下属与首领)、苏烈(下属与曾经上司)')
得到了英雄名称以及和他有关系的英雄关系信息
再下来就是保存到 csv 文件
def save_data_name(data_name, list_info):if not os.path.exists(data_name + r'.csv'):# 表头name = ["name","id"]# 建立DataFrame对象file_test = pd.DataFrame(columns=name, data=list_info)# 数据写入file_test.to_csv(data_name + r'.csv', encoding='utf-8', index=False)else:with open(data_name + r'.csv', 'a+', newline='', encoding='utf-8') as file_test:# 追加到文件后面writer = csv.writer(file_test)# 写入文件writer.writerows(list_info)一切准备工作完毕之后,就可以整合代码了
content = {}
index = 0
for p in p_list:content = deal_str(p.text)save_data_name("name", [[content[0], index]])if type(content[1]) == dict:for k,v in content[1].items():print([content[0], k, v])save_data_relation("relation", [[content[0], k, v]])index += 1处理过程如下

这要我们就得到了两个 csv 文件,一个保存了英雄名称,另一个保存了英雄关系信息


Neo4j 使用简介
Neo4j 是目前最为流行的图数据库,用于存储丰富的关系数据。图是由顶点(Vertex),边(Edge)和属性(Property)组成的,顶点和边都可以设置属性,顶点也称作节点,边也称作关系,每个节点和关系都可以由一个或多个属性
对于 Neo4j 的安装就不再赘述了,想我这里就是在自己本地的 Windows 上安装了一个,还是比较简单的
安装完成之后,我们一般可以在本地开发 Neo4j 控制浏览器
http://localhost:7474/browser/
然后我们把前面生成的两个文件放到 Neo4j 安装目录的 import 文件夹下(安全考虑,Neo4j 默认只能从该目录下导入文件)

接下来我们在 Neo4j 命令行中编写 Cypher 命令,先导入 csv 文件
英雄名称文件:
LOAD CSV WITH HEADERS FROM "file:///name.csv" AS line MERGE (p:person{name:line.name,id:line.id})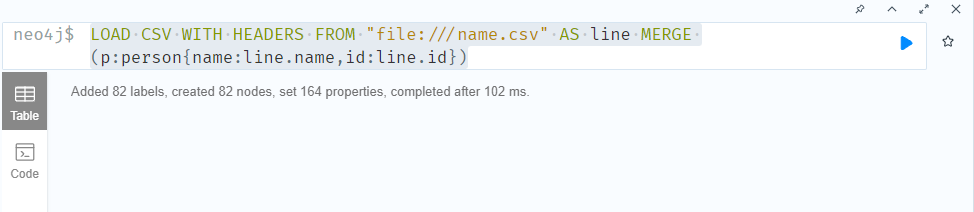
英雄关系文件:
LOAD CSV WITH HEADERS FROM "file:///relation.csv" AS relations MATCH (entity1:person{name:relations.name1}), (entity2: person{name:relations.name2}) CREATE (entity1)-[:rel{relation:relations.relation}]->(entity2)
如果一切不出意外,我们就已经完成了数据导入,下面就可以查看关系了
MATCH p=()-->() return p;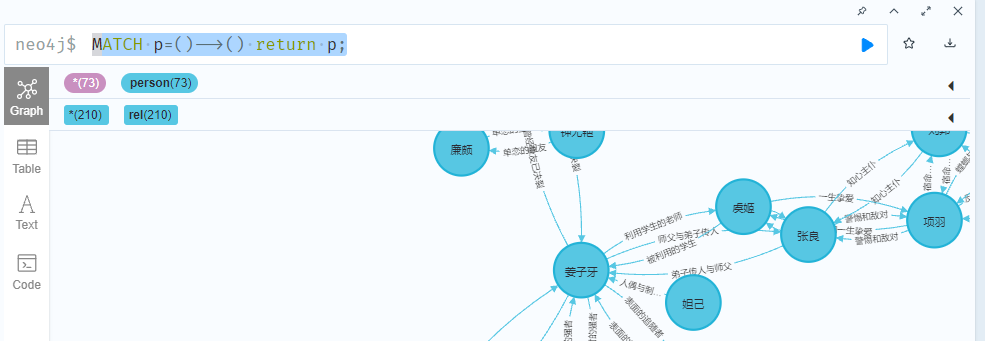
我们先来看一张整体图

不是特别清晰,我们来看看局部
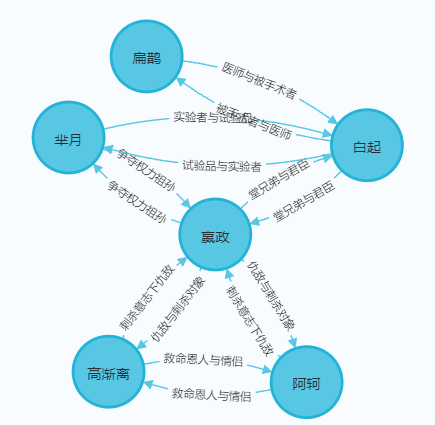

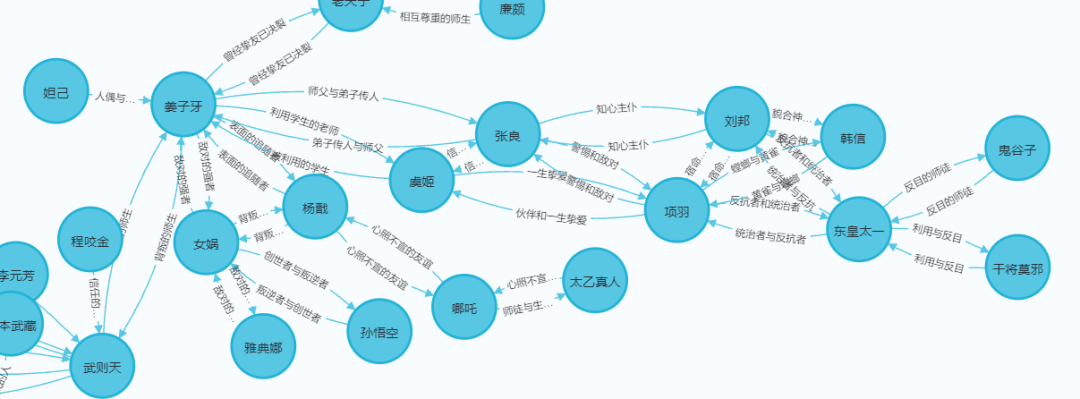
好了,今天的分享就到这里,我们下次见,不要忘记一键三连哦!
送书时间
本次送书是《对比Excel,轻松学习Python报表自动化》,这本书的主题就是数据分析师角度的报表自动化。
全书主要分为 4 个部分:
第 1 部分介绍 Python 基础知识,让读者对 Python 中常用的操作和概念有所了解;
第 2 部分介绍格式相关的设置方法,包括字体设置、条件格式设置等内容;
第 3 部分介绍各种类型的函数;
第 4 部分介绍自动化相关的其他技能,比如自动发送邮件、自动打包等操作。
真正做过数据分析师的人应该知道,一份报表大体其实就两部分:数据处理+格式设置。
数据处理就是对数据进行缺失值、重复值、异常值、还有加减乘除等处理。
格式设置主要就是字体设置、单元格设置、条件格式这些。
关于数据处理,第一本书《对比Excel,轻松学习Python数据分析》讲得差不多了,《对比Excel,轻松学习Python报表自动化》一书更多讲述格式设置和函数运算等内容。

公众号回复:送书 ,参与抽奖(共3本)
点击下方回复:送书 即可!
大家如果有什么建议,欢迎扫一扫二维码私聊小编~
回复:加群 可加入Python技术交流群



