1、简介
PASCAL 全称:Pattern Analysis, Statical Modeling and Computational Learning
PASCAL VOC(The PASCAL Visual Object Classes )是一个经典的计算机视觉数据集,由牛津大学、马里兰大学和微软剑桥研究院的研究人员创建的。 该数据集于2005年首次发布,从那时起就被用于训练和评估目标检测算法。
PASCAL VOC 从 2005年开始举办挑战赛,每年的内容都有所不同,主要包括:
- 图像分类(Classification )
- 目标检测(Detection)
- 目标分割(Segmentation)
- 人体布局(Human Layout)
- 动作识别(Action Classification)
我们知道在 ImageNet挑战赛上涌现了一大批优秀的分类模型,而PASCAL挑战赛上则是涌现了一大批优秀的目标检测和分割模型,这项挑战赛已于2012年停止举办了,但是研究者仍然可以在其服务器上提交预测结果以评估模型的性能。
虽然近期的目标检测或分割模型更倾向于使用MS COCO数据集,但是这丝毫不影响 PASCAL VOC数据集的重要性,毕竟PASCAL对于目标检测或分割类型来说属于先驱者的地位。对于现在的研究者来说比较重要的两个年份的数据集是 PASCAL VOC 2007 与 PASCAL VOC 2012,这两个数据集频频在现在的一些检测或分割类的论文当中出现。
2、 官网地址
官网地址:http://host.robots.ox.ac.uk/pascal/VOC/
官方文档 : http://host.robots.ox.ac.uk/pascal/VOC/pubs/everingham10.pdf
3、数据集下载
1)下载方式一 :点击下方 链接直接下载
Pascal VOC 2007
- 训练集和验证集 下载地址 : training/validation data (450MB tar file)
- 测试集(图像 + 标注)下载地址: annotated test data (430MB tar file)
- 测试集(仅标注文件)下载地址: annotation only (12MB tar file, no images)
Pascal VOC 2012
- 训练集和验证集 下载地址: training/validation data (2GB tar file)
- 测试集标注未公开
2)下载方式二 : 从官网下载
a、Pascal VOC 2007 数据集
点击链接 进入 Pascal VOC 2007 主页 : http://host.robots.ox.ac.uk/pascal/VOC/voc2007
在页面中找到如下 下载链接,点击进行下载

b、Pascal VOC 2012 数据集
点击链接 进入 Pascal VOC 2012 主页 : http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
在页面中找到如下 下载链接,点击进行下载

4、数据集的发展 与 20个类别
1)数据集的发展
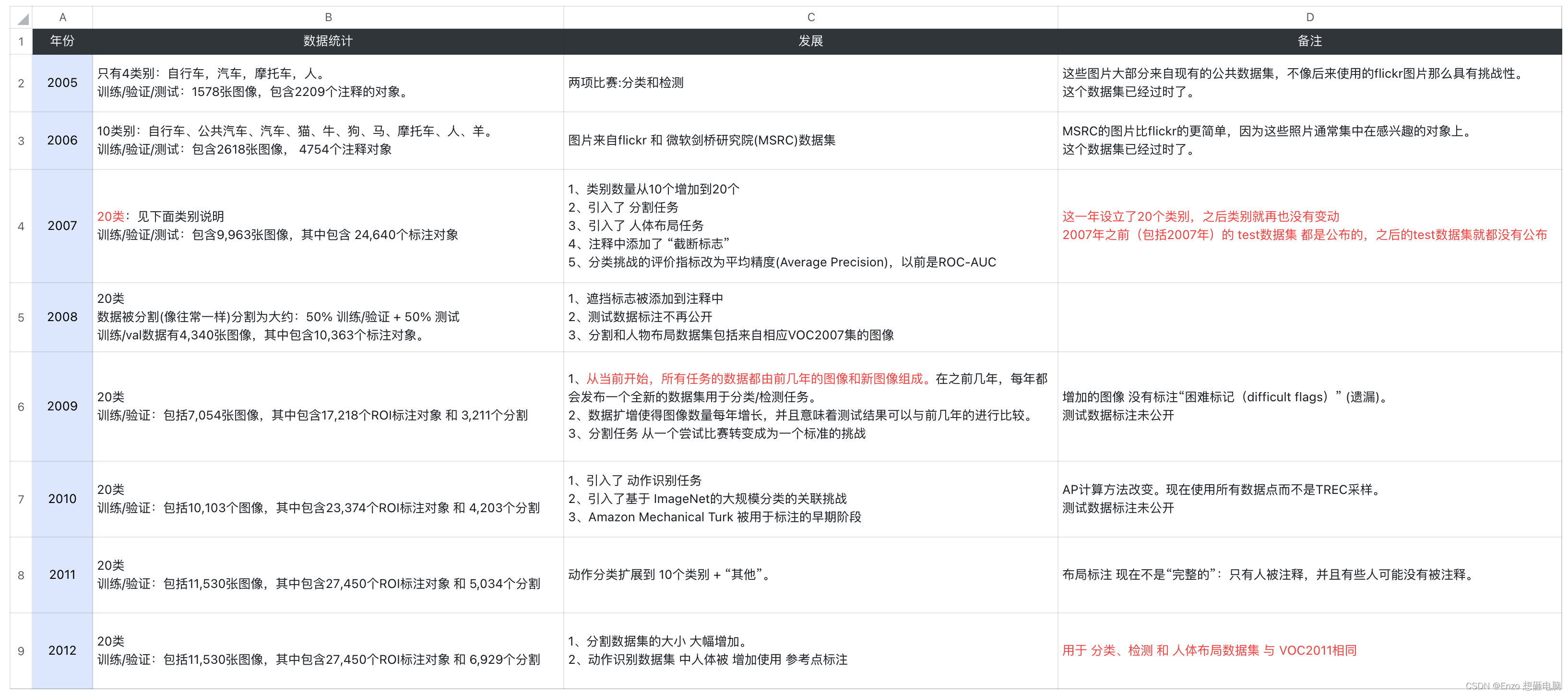
对于 分类 和 检测 来说,下图所示为数据集的发展历程,相同颜色的代表相同的数据集:

- 05年、06年、07年、08年数据集,为互斥的,独立的、完全不相同的数据集
- 09年开始,所有数据集由前几年的部分图像 和 新图像组成
09年的数据集 = 07年部分图像 + 08年部分图像 + 09年新图像 - 10、11 年的数据集,均是在前一年的数据集上进行扩充
- 12 年的数据集 和 11年的数据集一样
虽然 Pascal VOC 2012 和 2007 版本的数据集存在一些共享的部分,但是它们的图像和标注文件在细节上还是有所不同的,因此在使用数据集时需要注意版本和文件的正确匹配。
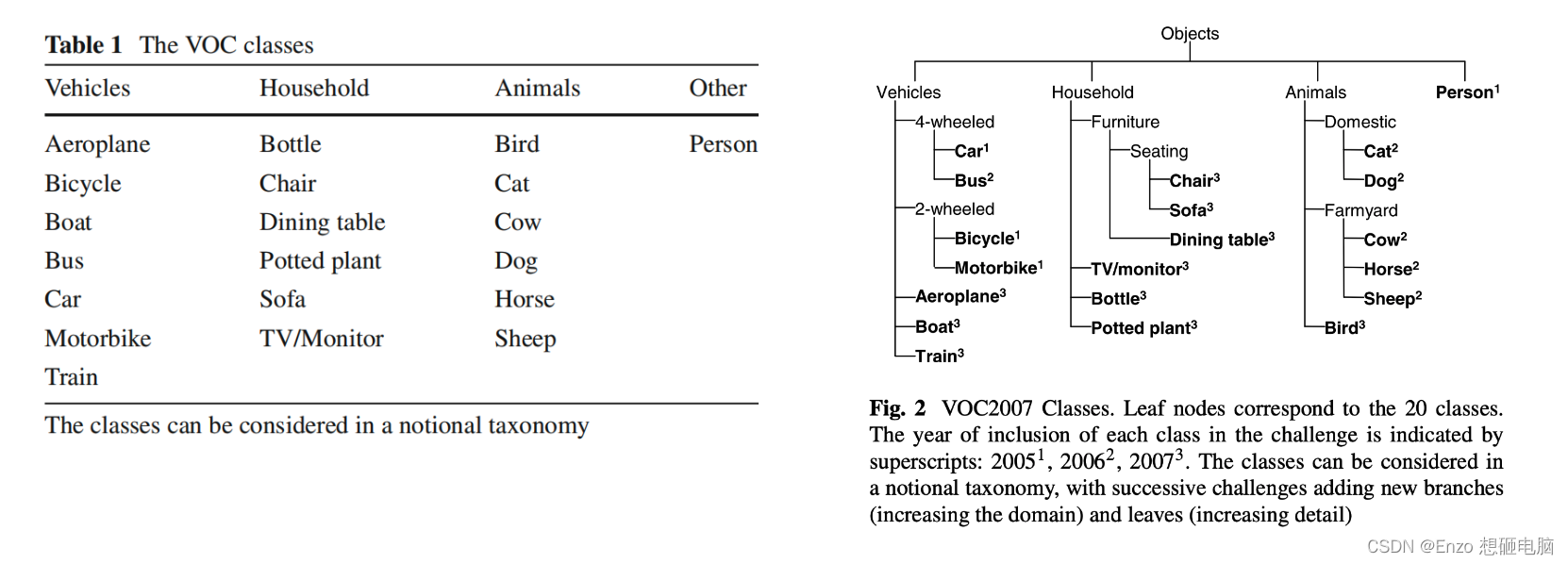
2)20个类别
对于 图像分类任务 和 目标检测任务,数据集有 20个类别 (4大类)
}"aeroplane": 1,"bicycle": 2,"bird": 3,"boat": 4,"bottle": 5,"bus": 6,"car": 7,"cat": 8,"chair": 9,"cow": 10,"diningtable": 11,"dog": 12,"horse": 13,"motorbike": 14,"person": 15,"pottedplant": 16,"sheep": 17,"sofa": 18,"train": 19,"tvmonitor": 20
}
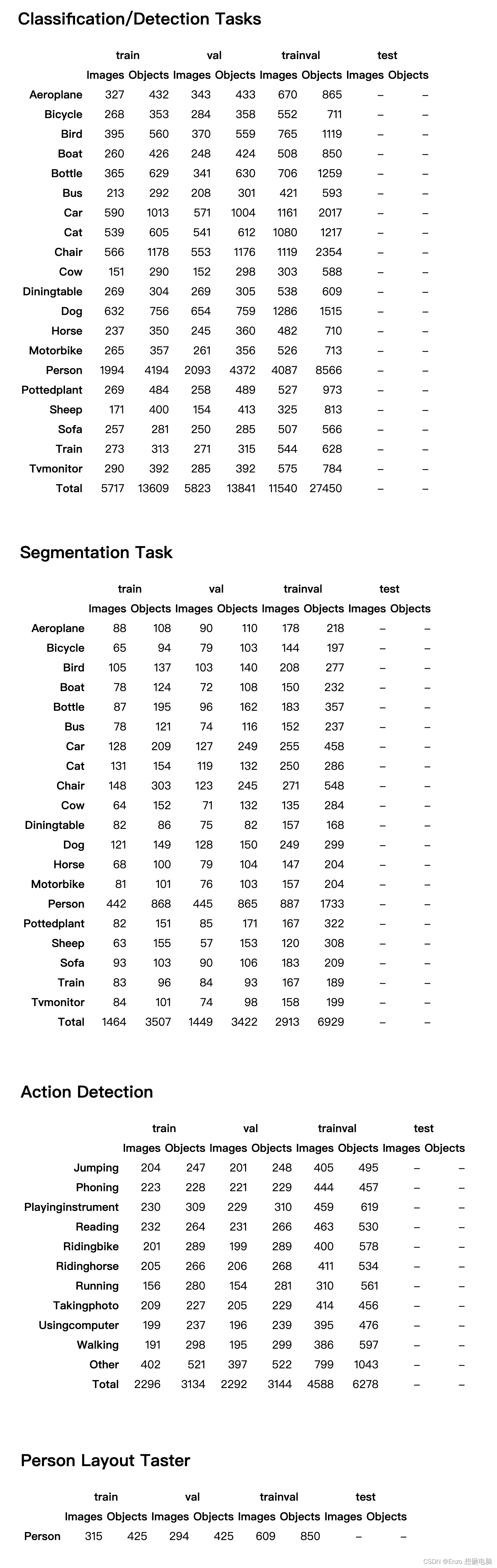
5、数据分布与统计
1)Pascal VOC 2007
\quad \quad 官方地址
![[图片]](https://img-blog.csdnimg.cn/8ae14d628bac4dc3b40ff99c64a83fcd.png)
2)Pascal VOC 2012
\quad \quad 官方地址
6、数据集的使用
目前广大研究者们普遍使用的是 VOC2007和VOC2012数据集。
论文中针对 VOC2007和VOC2012 的具体用法有以下几种:
- 只用VOC2007的trainval 训练,使用VOC2007的test测试
- 只用VOC2012的trainval 训练,使用VOC2012的test测试,这种用法很少使用,因为大家都会结合VOC2007使用
- 使用 VOC2007 的 train+val 和 VOC2012的 train+val 训练,然后使用 VOC2007的test测试,这个用法是论文中经常看到的 07+12 ,研究者可以自己测试在VOC2007上的结果,因为VOC2007的test是公开的。
- 使用 VOC2007 的 train+val+test 和 VOC2012的 train+val训练,然后使用 VOC2012的test测试,这个用法是论文中经常看到的 07++12 ,这种方法需提交到VOC官方服务器上评估结果,因为VOC2012 test没有公布。
- 先在 MS COCO 的 trainval 上预训练,再使用 VOC2007 的 train+val、 VOC2012的 train+val 微调训练,然后使用 VOC2007的test测试,这个用法是论文中经常看到的 07+12+COCO 。
- 先在 MS COCO 的 trainval 上预训练,再使用 VOC2007 的 train+val+test 、 VOC2012的 train+val 微调训练,然后使用 VOC2012的test测试 ,这个用法是论文中经常看到的 07++12+COCO,这种方法需提交到VOC官方服务器上评估结果,因为VOC2012 test没有公布。
7、数据集结构
1)Pascal VOC 2007
.
└── VOCdevkit└── VOC2007├── Annotations 标注文件(图像分类、目标检测、人体布局)│ ├── 000005.xml│ ├── 000007.xml│ ├── 000009.xml│ └── ... (共 5011个标注文件)├── ImageSets 数据集分割信息 (训练集、验证集、训练集+验证集)│ ├── Layout 用于人体布局图像信息│ │ ├── train.txt│ │ ├── trainval.txt│ │ └── val.txt│ ├── Main 用于图像分类和目标检测图像信息│ │ ├── train.txt │ │ ├── trainval.txt │ │ ├── val.txt │ │ └── ... (共63个文件)│ └── Segmentation 用于语义分割和实例分割图像信息│ ├── train.txt│ ├── trainval.txt│ └── val.txt├── JPEGImages 所有原图像│ ├── 000005.jpg│ ├── 000007.jpg│ ├── 000009.jpg│ └── ... (共5011张图像)├── SegmentationClass 语义分割标注图像│ ├── 000032.png│ ├── 000033.png│ ├── 000039.png│ └── ... (共422张图像)└── SegmentationObject 实例分割标注图像├── 000032.png├── 000033.png├── 000039.png└── ... (共422张图像)
2)Pascal VOC 2012
.
└── VOCdevkit└── VOC2012├── Annotations 标注文件(图像分类、目标检测、人体布局)│ ├── 2007_000027.xml│ ├── 2007_000032.xml│ ├── 2007_000033.xml│ ├── 2007_000039.xml│ └── ...(共17125张图像)├── ImageSets 数据集分割信息 (训练集、验证集、训练集+验证集)│ ├── Action 用于动作识别│ │ ├── train.txt 2296张图像│ │ ├── trainval.txt 4588张图像│ │ ├── val.txt 2292张图像│ │ └── ...│ ├── Layout 用于人体布局│ │ ├── train.txt 4425张图像│ │ ├── trainval.txt 850张图像│ │ └── val.txt 425张图像│ ├── Main 用于图像分类和目标检测 │ │ ├── train.txt 5717张图像 │ │ ├── train_val.txt 11540张图像│ │ └── trainval.txt 5823张图像 │ └── Segmentation 用于语义分割和实例分割 │ ├── train.txt 1464张图像│ ├── trainval.txt 2913张图像│ └── val.txt 1449张图像├── JPEGImages 所有原图像│ ├── 2007_000027.jpg│ ├── 2007_000032.jpg│ ├── 2007_000033.jpg│ ├── 2007_000039.jpg│ └── ...(共17125张图像)├── SegmentationClass 语义分割标注图像│ ├── 2007_000032.png│ ├── 2007_000033.png │ ├── 2007_000039.png│ ├── 2007_000042.png│ └── ...(共2913张图像)└── SegmentationObject 实例分割标注图像├── 2007_000032.png├── 2007_000033.png├── 2007_000039.png├── 2007_000042.png└── ...(共2913张图像)
3)2007 和 2012 数据结构的区别
1、Pascal VOC 2012 的数据集 因为是在前几年的数据集上进行扩增,所以文件名中包含年份,而 Pascal VOC 2007 的文件名中不包含
- Pascal VOC 2007 的标注文件名 和 图像文件名 类似为: 000005.xml、 000005.jpg
- Pascal VOC 2012 的标注文件名 和 图像文件名 类似为: 2007_000027.xml、 2007_000039.png
2、Pascal VOC 2012 的 ImageSets 中包括 Action 文件:用于动作识别任务的数据集划分,而 Pascal VOC 2007 的 ImageSets 文件中不包含, 因为 动作识别任务(Action Classification) 是2010年才有的。
3、.xml 的标注文件内容 有所不同,比如: 12版本中有的图像标注 是有 动作信息
8、标注文件结构
(1)目标检测 标注文件 Annotation
<annotation><folder>VOC2007</folder><filename>000001.jpg</filename><source><database>The VOC2007 Database</database><annotation>PASCAL VOC2007</annotation><image>flickr</image><flickrid>341012865</flickrid></source><owner><flickrid>Fried Camels</flickrid><name>Jinky the Fruit Bat</name></owner><size><width>353</width><height>500</height><depth>3</depth></size><segmented>0</segmented><object><name>dog</name><pose>Left</pose><truncated>1</truncated><difficult>0</difficult><bndbox><xmin>48</xmin><ymin>240</ymin><xmax>195</xmax><ymax>371</ymax></bndbox></object><object><name>person</name><pose>Left</pose><truncated>1</truncated><difficult>0</difficult><bndbox><xmin>8</xmin><ymin>12</ymin><xmax>352</xmax><ymax>498</ymax></bndbox></object>
</annotation>
- annotation:标注文件的根节点,包含了整个标注信息
- folder:图像所在的文件夹名称
- filename:图像的文件名
- source:图像来源
- owner:图像拥有者
- size:图像的尺寸信息,包括宽度、高度、深度。
- segmented:是否被分割标注过: 值为 0,未被过分割;值为 1,被分割标注。
- object:图像中的一个物体,其中的 信息包括:
- name:物体的类别名称, 20个类别
- bndbox:物体的边界框信息,包括左上角和右下角的坐标
- xmin:边界框左上角的 x 坐标
- ymin:边界框左上角的 y 坐标
- xmax:边界框右下角的 x 坐标
- ymax:边界框右下角的 y 坐标
- difficult:标记物体是否难以识别的标志,0 表示容易识别,1 表示难以识别
- truncated:标记物体是否被截断:0 表示未被截断,1 表示被截断(比如在图片之外,或者被遮挡超过15%)
- pose:标记物体的姿态,例如正面、侧面等
(2)语义分割标注图像 SegmentationClass
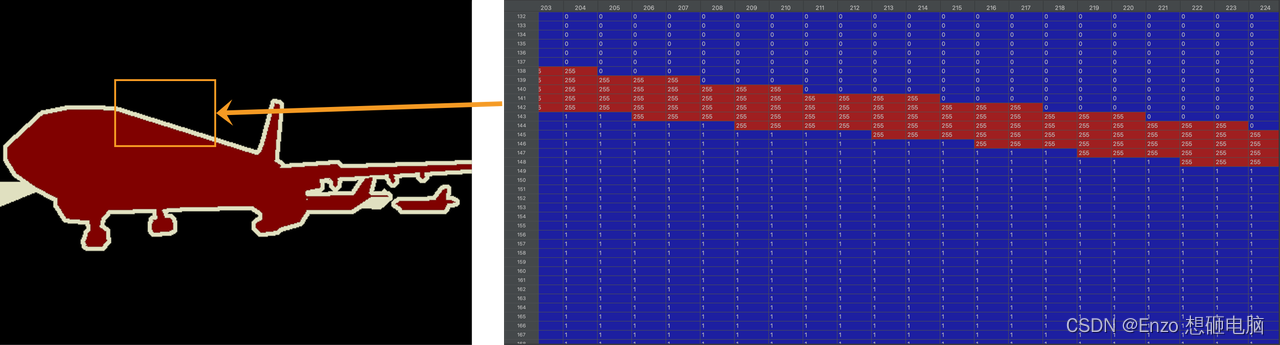
- 背景部分的 标注像素值 为 0
- 边界部分的标注像素值为 255
- 难以分割的区域,例如有重叠物体或遮挡的区域,标注像素值为255
- 被分割出的object 内部, 标注像素值为其类别索引。 比如,被分割的飞机部分的像素值为飞机类别索引值 1
}"aeroplane": 1,"bicycle": 2,"bird": 3,"boat": 4,"bottle": 5,"bus": 6,"car": 7,"cat": 8,"chair": 9,"cow": 10,"diningtable": 11,"dog": 12,"horse": 13,"motorbike": 14,"person": 15,"pottedplant": 16,"sheep": 17,"sofa": 18,"train": 19,"tvmonitor": 20
}
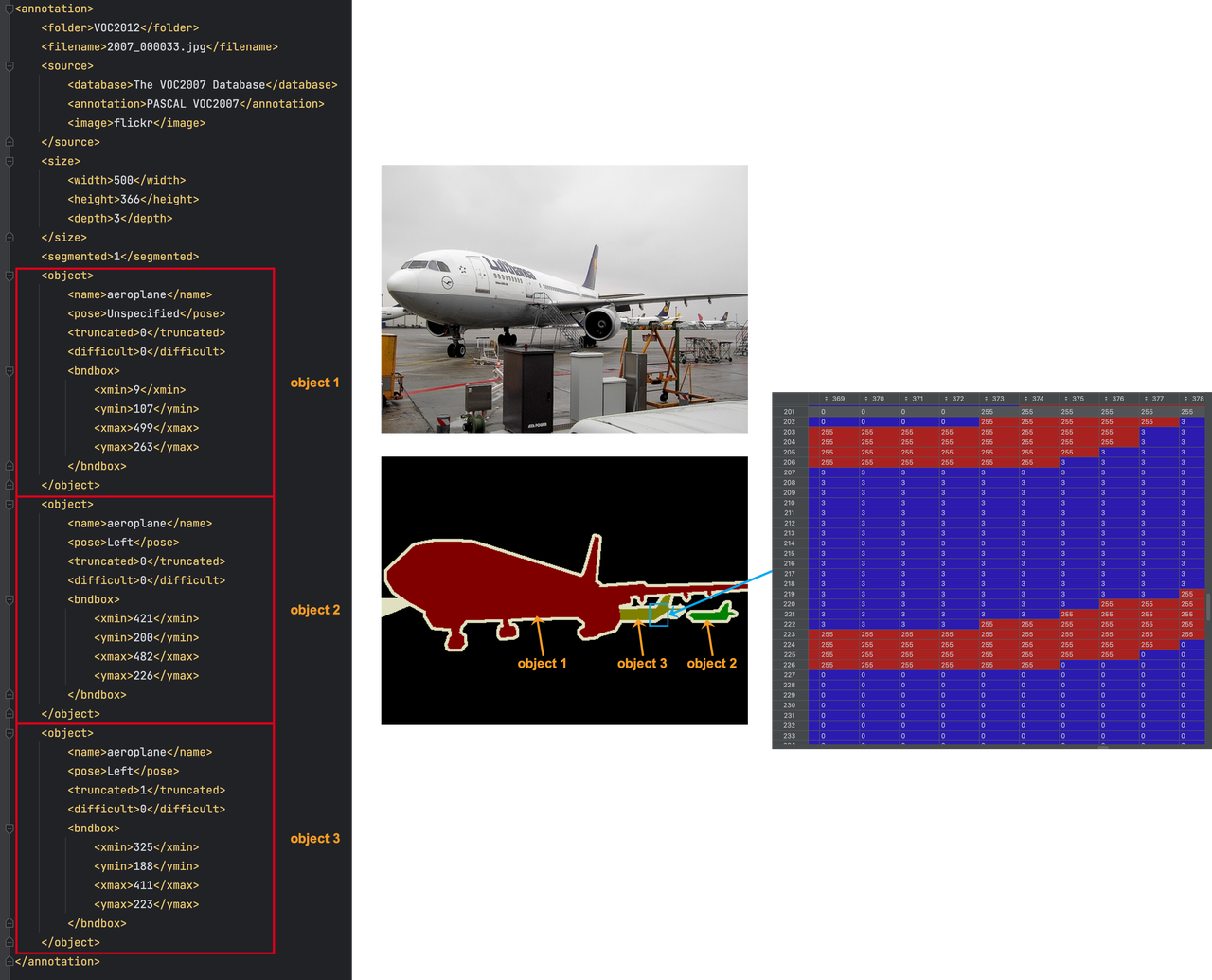
(3)实例分割标注图像 SegmentationObject
- 背景部分的 标注像素值 为 0
- 边界部分的标注像素值为 255
- 难以分割的区域,例如有重叠物体或遮挡的区域,标注像素值为255
- 被分割出的 object 内部,使用 物体实例的 ID 来标识它。物体实例的 ID :为该物体在 .xml 标注文件中的 index 。比如,在 .xml 标注文件中,排位第2个的 object,ID = 2,在标注图像中,该 object 的像素值,就为2
(4)人体布局 Human Layout
< /part> 标签 框起来的部分,就是人体布局的标签
<annotation><folder>VOC2012</folder><filename>2007_000027.jpg</filename><source><database>The VOC2007 Database</database><annotation>PASCAL VOC2007</annotation><image>flickr</image></source><size><width>486</width><height>500</height><depth>3</depth></size><segmented>0</segmented><object><name>person</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>174</xmin><ymin>101</ymin><xmax>349</xmax><ymax>351</ymax></bndbox><part><name>head</name><bndbox><xmin>169</xmin><ymin>104</ymin><xmax>209</xmax><ymax>146</ymax></bndbox></part><part><name>hand</name><bndbox><xmin>278</xmin><ymin>210</ymin><xmax>297</xmax><ymax>233</ymax></bndbox></part><part> <name>foot</name> <bndbox> <xmin>273</xmin> <ymin>333</ymin> <xmax>297</xmax> <ymax>354</ymax> </bndbox> </part> <part><name>foot</name><bndbox><xmin>319</xmin><ymin>307</ymin><xmax>340</xmax><ymax>326</ymax></bndbox></part></object>
</annotation>
(5)动作识别 Action Classification
< /actions> 标签 框起来的部分,就是动作识别的标签
<annotation><filename>2011_003279.jpg</filename><folder>VOC2011</folder><object><name>person</name><actions> <jumping>0</jumping> <other>0</other> <phoning>0</phoning> <playinginstrument>0</playinginstrument> <reading>0</reading> <ridingbike>0</ridingbike> <ridinghorse>0</ridinghorse> <running>0</running> <takingphoto>0</takingphoto> <usingcomputer>0</usingcomputer> <walking>1</walking> </actions> <bndbox><xmax>188</xmax><xmin>109</xmin><ymax>500</ymax><ymin>307</ymin></bndbox><difficult>0</difficult><pose>Unspecified</pose><point><x>153</x><y>374</y></point></object><segmented>0</segmented><size><depth>3</depth><height>500</height><width>367</width></size><source><annotation>PASCAL VOC2011</annotation><database>The VOC2011 Database</database><image>flickr</image></source>
</annotation>

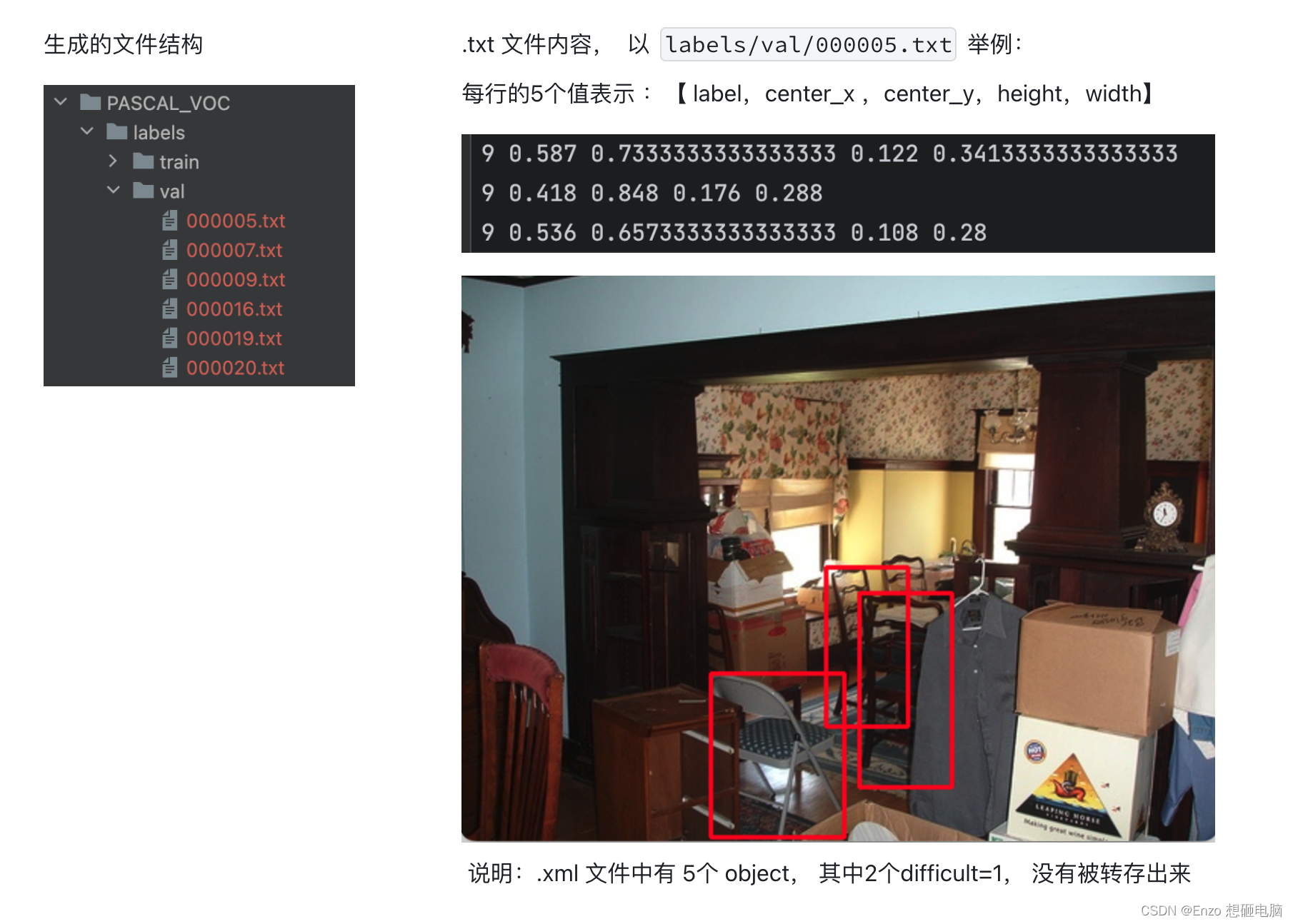
9、数据集解析 - 目标检测任务
将数据集转换为 yolo 格式 , YOLO 数据格式介绍: YOLO 数据集格式
import xml.etree.ElementTree as ET
import os# voc的20个类别
classes = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable','dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']def convert(size, bbox):x = (bbox[0] + bbox[1]) / 2.0y = (bbox[2] + bbox[3]) / 2.0w = bbox[1] - bbox[0]h = bbox[3] - bbox[2]x = x / size[0]w = w / size[0]y = y / size[1]h = h / size[1]return (x, y, w, h)def convert_annotation(xml_file, save_file):# 保存yolo格式 的label 的 .txt 文件地址save_file = open(save_file, 'w')tree = ET.parse(xml_file)size = tree.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in tree.findall('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls) + 1 # 类别索引从1开始,类别0是背景bbox = obj.find('bndbox')b = (float(bbox.find('xmin').text),float(bbox.find('xmax').text),float(bbox.find('ymin').text),float(bbox.find('ymax').text))bb = convert((w, h), b)save_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')save_file.close()if __name__ == "__main__":# 数据集根目录地址data_root = "/Users/enzo/Documents/GitHub/dataset/VOCdevkit/VOC2007"# 标注文件地址annotation = os.path.join(data_root, 'Annotations')# yolo格式的文件保存地址save_root = './labels'if not os.path.exists(save_root):os.makedirs(save_root)for train_val in ["train", "val"]:if not os.path.exists(os.path.join(save_root, train_val)):os.makedirs(os.path.join(save_root, train_val))# 数据集划分的 .txt 文件地址txt_file = os.path.join(data_root, 'ImageSets/Main', train_val+'.txt')with open(txt_file, 'r') as f:lines = f.readlines()file_names = [line.strip() for line in lines if len(line.strip())>0]for file_name in file_names:xml_file = os.path.join(annotation, file_name+'.xml')save_file = os.path.join(save_root, train_val, file_name+'.txt')convert_annotation(xml_file, save_file)
10、Reference
https://arleyzhang.github.io/articles/1dc20586/
![[开发|java] com.typesafe.config配置示例说明](/images/no-images.jpg)