目录
- 文本特征处理作用
- 常见的文本特征处理方法
- 添加n-gram特征
- 说明
- 提取n-gram
- 文本长度规范
- 说明
- 实现
- 导包问题记录
- 心得
文本特征处理作用
文本特征处理包括为语料添加具有普适性的文本特征, 如:n-gram特征
以及对加入特征之后的文本语料进行必要的处理, 如: 长度规范.
这些特征处理工作能够有效的将重要的文本特征加入模型训练中, 增强模型评估指标。
常见的文本特征处理方法
添加n-gram特征
说明
给定一段文本序列, 其中n个词或字的相邻共现特征即n-gram特征, 常用的n-gram特征是bi-gram和tri-gram特征, 分别对应n为2和3.
如[“我”,“爱”,“你”] 对应向量[1, 23, 45] ,我爱两个字共现且相邻(bi-gram特),用1000表示这种关系,则包含2-gram特征的向量为[1,23,45,1000]
n > 3 时 会导致算力不够,常为2, 3
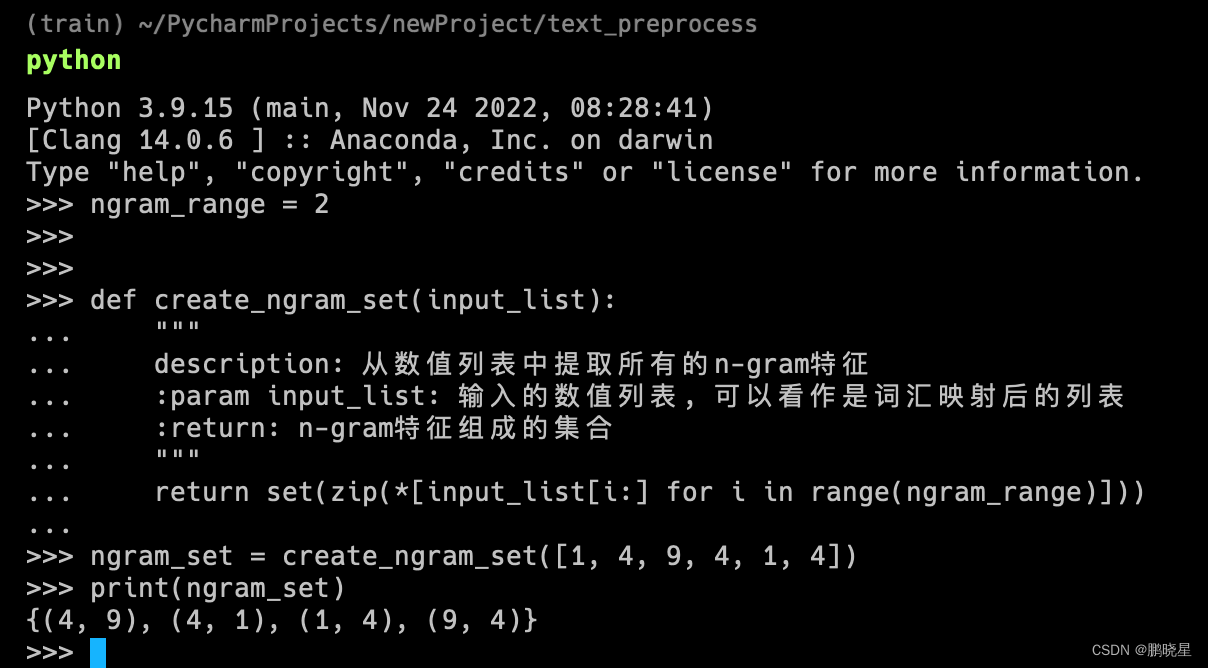
提取n-gram
ngram_range = 2def create_ngram_set(input_list):"""description: 从数值列表中提取所有的n-gram特征:param input_list: 输入的数值列表, 可以看作是词汇映射后的列表:return: n-gram特征组成的集合"""return set(zip(*[input_list[i:] for i in range(ngram_range)]))ngram_set = create_ngram_set([1, 4, 9, 4, 1, 4])
print(ngram_set)
文本长度规范
说明
-
规范原因:
一般模型的输入需要等尺寸大小的矩阵, 因此在进入模型前需要对每条文本数值映射后的长度进行规范。 -
规范过程:
此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度, 对超长文本进行截断, 对不足文本进行补齐(一般使用数字0)
实现
from keras_preprocessing import sequence# cut_len根据数据分析中句子长度分布,覆盖90%左右语料的最短长度.
cut_len = 10def padding(x_train):"""description: 对输入文本张量进行长度规范:param x_train: 文本的张量表示:return: 进行截断补齐后的文本张量表示"""# 使用sequence.pad_sequences即可完成return sequence.pad_sequences(x_train, cut_len)if __name__ == '__main__':# 假定x_train里面有两条文本, 一条长度大于10, 一天小于10x_train = [[1, 23, 5, 32, 55, 63, 2, 21, 78, 32, 23, 1],[2, 32, 1, 23, 1]]res = padding(x_train)print(res)

导包问题记录

错误导包
from keras.preprocessing import sequence
改为
from keras_preprocessing import sequence
心得
在练习的时候如果在服务器上通过命令行方式敲写,更加需要细心,以及对报错进行思考并总结