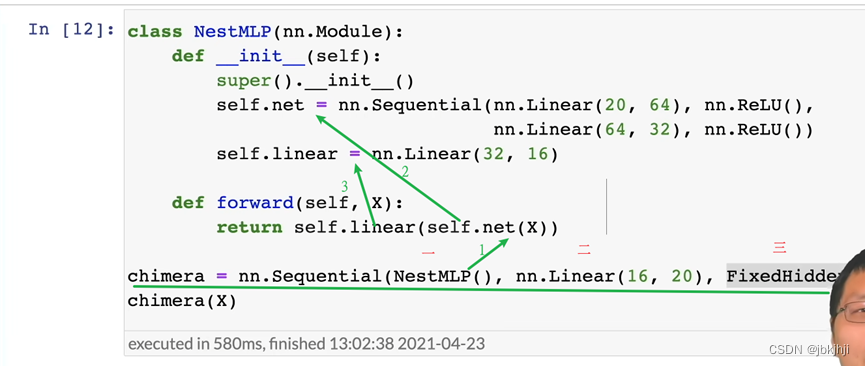
3.1 层和块
块(block)可以描述单个层、由多个层组成的组件或整个模型本身。以下代码通过实例化nn.Sequential来构建模型, 层的执行顺序是作为参数传递的。 简而言之,nn.Sequential定义了一种特殊的Module, 即在PyTorch中表示一个块的类, 它维护了一个由Module组成的有序列表。 注意,两个全连接层都是Linear类的实例, Linear类本身就是Module的子类。
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))3.1.1 自定义块
每个块必须提供的功能:
-
将输入数据作为其前向传播函数的参数。
-
通过前向传播函数来生成输出。请注意,输出的形状可能与输入的形状不同。例如,我们上面模型中的第一个全连接的层接收一个20维的输入,但是返回一个维度为256的输出。
-
计算其输出关于输入的梯度,可通过其反向传播函数进行访问。通常这是自动发生的。
-
存储和访问前向传播计算所需的参数。
-
根据需要初始化模型参数。
import torch
from torch import nn
from torch.nn import functional as FX = torch.rand(2,20)class MLP(nn.Module):def __init__(self):super().__init__()#调用MLP的父类Module的构造函数进行必要的初始化 例如线性的w和bself.hidden = nn.Linear(20,256)#隐藏层self.out = nn.Linear(256,10)#输出层def forward(self,X):#定义模型的前向传播return self.out(F.relu(self.hidden(X)))# ReLU的函数版本,其在nn.functional模块中定义net = MLP()
net(X)#块的一个主要优点是它的多功能性。 我们可以子类化块以创建层(如全连接层的类)、 整个模型(如上面的MLP类)或具有中等复杂度的各种组件。输出结果:
tensor([[ 0.1207, -0.1397, -0.0507, 0.0215, 0.1688, 0.3081, 0.1183, -0.3262, -0.2948, 0.0578], [ 0.1575, -0.1467, -0.0656, 0.1134, 0.0938, 0.1988, 0.0573, -0.3333, -0.2152, 0.1373]], grad_fn=<AddmmBackward0>)
3.1.2 顺序块-Sequential类
Sequential的设计是为了把其他模块顺序的串起来,自定义Sequential类只需要定义两个关键函数:
-
一种将块逐个追加到列表中的函数。
-
一种前向传播函数,用于将输入按追加块的顺序传递给块组成的“链条”。
class MySequential(nn.Module):def __init__(self,*args):super().__init__()for idx, module in enumerate(args):#enumerate()在遍历中可以获得索引和元素值。”self._modules[str(idx)] = module#把每个模块添加到字典里面#这里不使用自己定义列表是因为,在模块的参数初始化过程中系统知道在_modules字典中查找需要初始化参数的子块。def forward(self,X):for block in self._modules.values():#X = block(X)#每一个块依次进行计算return X
net = MySequential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10))
net(X)输出结果:
tensor([[-0.0415, -0.1059, -0.2242, 0.2065, -0.2658, 0.2432, 0.0123, 0.0771, 0.2188, -0.0420], [ 0.0145, -0.0870, -0.1768, 0.2148, -0.1436, 0.1497, 0.0112, 0.0389, 0.0588, -0.0525]], grad_fn=<AddmmBackward0>)
3.1.3 在向前传播函数中执行代码
Sequential类使模型构造变得简单,允许组合新的架构,而不必定义自己的类。 然而,并不是所有的架构都是简单的顺序架构。 当需要更强的灵活性时,我们需要定义自己的块。 例如,我们可能希望在前向传播函数中执行Python的控制流。 此外,我们可能希望执行任意的数学运算, 而不是简单地依赖预定义的神经网络层。
class FixedHiddenMLP(nn.Module):def __init__(self):super().__init__()self.rand_weight = torch.rand((20,20),requires_grad=False)self.linear = nn.Linear(20,20)def forward(self,X):X = self.linear(X)X = F.relu(torch.mm(X,self.rand_weight)+1)X = self.linear(X)while X.abs().sum()>1:X /= 2return X.sum()
net = FixedHiddenMLP()
net(X)输出结果:
tensor(-0.1532, grad_fn=<SumBackward0>)
总结:
-
一个块可以由许多层组成;一个块可以由许多块组成。
-
块可以包含代码。
-
块负责大量的内部处理,包括参数初始化和反向传播。
-
层和块的顺序连接由
Sequential块处理
3.2 参数管理
3.2.1 访问参数
当通过Sequential类定义模型时, 我们可以通过索引来访问模型的任意层。 这就像模型是一个列表一样,每层的参数都在其属性中。
import torch
from torch import nnnet = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
X = torch.rand(size=(2, 4))
net(X)print(net[2].state_dict())#访问第2层的参数字典 即nn.Linear(8.1)的参数
print(net[2].weight)#访问weight
print(net[2].bias)#访问bias
print(net[2].weight.data)#直接输出值
输出结果:
OrderedDict([('weight', tensor([[-0.3429, 0.2159, -0.3050, 0.3406, -0.1746, 0.0702, 0.2869, -0.1781]])), ('bias', tensor([0.0261]))])
Parameter containing: tensor([[-0.3429, 0.2159, -0.3050, 0.3406, -0.1746, 0.0702, 0.2869, -0.1781]], requires_grad=True)
Parameter containing: tensor([0.0261], requires_grad=True)
tensor([[-0.3429, 0.2159, -0.3050, 0.3406, -0.1746, 0.0702, 0.2869, -0.1781]])
直接访问所有层的所有参数:
print(*[(name, param.shape) for name, param in net[0].named_parameters()])
print(*[(name, param.shape) for name, param in net.named_parameters()])
#加*的目的是取出list中的每个值
#例:print(*[1,2,3]) --> 1 2 3输出结果:
('weight', torch.Size([8, 4])) ('bias', torch.Size([8])) ('0.weight', torch.Size([8, 4])) ('0.bias', torch.Size([8])) ('2.weight', torch.Size([1, 8])) ('2.bias', torch.Size([1]))
3.2.2 参数初始化
自定义参数的初始化规则
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
def init_normal(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, mean=0, std=0.01)#将所有权重参数初始化为标准差为0.01的高斯随机变量#nn.init.constant_(m.weight, 1) #将wight参数初始化为给定的常数1nn.init.zeros_(m.bias)#将偏置参数设置为0
net.apply(init_normal)
net[0].weight.data[0],net[0].bias.data#nn.Linear(4, 8)初始化后的权重和偏置输出结果:
(tensor([-0.0001, -0.0070, 0.0078, 0.0049]), tensor([0., 0., 0., 0., 0., 0., 0., 0.]))
#(tensor([1., 1., 1., 1.]), tensor([0., 0., 0., 0., 0., 0., 0., 0.]))
对不同层网络使用不同的初始化参数方法,例如使用Xavier初始化方法初始化第一个神经网络层, 然后将第三个神经网络层初始化为常量值42。
def init_xavier(m):if type(m)==nn.Linear:nn.init.xavier_uniform_(m.weight)
def init_42(m):if type(m)==nn.Linear:nn.init.constant_(m.weight,42)
net[0].apply(init_xavier)
net[2].apply(init_42)
print(net[0].weight.data[0])
print(net[2].weight.data)输出结果:
tensor([-0.1781, -0.4115, 0.3015, 0.1715]) tensor([[42., 42., 42., 42., 42., 42., 42., 42.]])
实现w满足该函数的初始化代码(思想跟前面一致,这里函数的表达自己写不出来 所以记录下来):
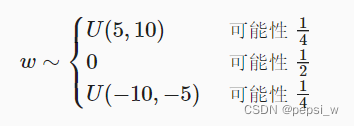
def my_init(m):if type(m) == nn.Linear:print("Init", *[(name, param.shape)for name, param in m.named_parameters()][0])nn.init.uniform_(m.weight, -10, 10)m.weight.data *= m.weight.data.abs() >= 5net.apply(my_init)3.2.3 不同模型组件间共享参数
在多个层间共享参数以定义一个稠密层,然后使用它的参数来设置另一个层的参数 。
# 需要给共享层一个名称,以便可以引用它的参数
shared = nn.Linear(8, 8)
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(),shared, nn.ReLU(),shared, nn.ReLU(),nn.Linear(8, 1))
net(X)
# 检查参数是否相同
print(net[2].weight.data[0] == net[4].weight.data[0])
net[2].weight.data[0, 0] = 100
# 确保它们实际上是同一个对象,而不只是有相同的值
print(net[2].weight.data[0] == net[4].weight.data[0])输出:
tensor([True, True, True, True, True, True, True, True])
tensor([True, True, True, True, True, True, True, True])3.3 自定义层
3.3.1 不带参数的层
这里不需要参数,就直接使用父类的初始化,并设置一个向前传播forward函数(这里设置为从输入中减去均值)。
class Mylayer(nn.Module):def __init__(self):super().__init__()def forward(self,X):return X-X.mean()net = nn.Sequential(nn.Linear(8,128),Mylayer())#可直接传入Sequential进行使用
X = torch.rand(4,8)
Y = net(X)
Y.mean()输出结果:(由于处理的是浮点数,因为存储精度的原因,我们仍然可能会看到一个非常小的非零数。)
tensor(9.3132e-09, grad_fn=<MeanBackward0>)
3.3.2 带参数的层
该层需要两个参数,一个用于表示权重,另一个用于表示偏置项。 使用修正线性单元作为激活函数。 该层需要输入参数:in_units和units,分别表示输入数和输出数。
class MyLinear(nn.Module):def __init__(self, in_units, units):super().__init__()self.weight = nn.Parameter(torch.randn(in_units, units))self.bias = nn.Parameter(torch.randn(units,))def forward(self, X):linear = torch.matmul(X, self.weight.data) + self.bias.datareturn F.relu(linear)linear = MyLinear(5, 3)
linear.weight输出结果:
Parameter containing: tensor([[-1.4779, -0.6027, -0.2225],[ 1.1270, -0.6127, -0.2008],[-2.1864, -1.0548, 0.2558],[ 0.0225, 0.0553, 0.4876],[ 0.3558, 1.1427, 1.0245]], requires_grad=True)
3.4 读写文件
3.4.1 加载和保存张量
可以直接调用load和save函数分别读写它们。 这两个函数都要求我们提供一个名称,save要求将要保存的变量作为输入。
x = torch.arange(4)
torch.save(x, 'x-file')#写到名为“x-file”的文件中y = torch.load('x-file')
x==y
输出:
tensor([True, True, True, True])
3.4.2 加载和保存模型参数
深度学习框架提供了内置函数来保存和加载整个网络。 需要注意的一个重要细节是,这将保存模型的参数而不是保存整个模型。
class MLP(nn.Module):def __init__(self):super().__init__()self.hidden = nn.Linear(20, 256)self.output = nn.Linear(256, 10)def forward(self, x):return self.output(F.relu(self.hidden(x)))net = MLP()
X = torch.randn(size=(2, 20))
Y = net(X)torch.save(net.state_dict(), 'mlp.params')#实例化了原始多层感知机模型的一个备份,这里不需要随机初始化模型参数,而是直接读取文件中存储的参数。
clone = MLP()
clone.load_state_dict(torch.load('mlp.params'))Y_clone = clone(X)
Y_clone == Y#检查是否一致输出结果:
tensor([[True, True, True, True, True, True, True, True, True, True],[True, True, True, True, True, True, True, True, True, True]])
3.5 GPU
-
我们可以指定用于存储和计算的设备,例如CPU或GPU。默认情况下,数据在主内存中创建,然后使用CPU进行计算。
-
深度学习框架要求计算的所有输入数据都在同一设备上,无论是CPU还是GPU。
-
不经意地移动数据可能会显著降低性能。一个典型的错误如下:计算GPU上每个小批量的损失,并在命令行中将其报告给用户(或将其记录在NumPy
ndarray中)时,将触发全局解释器锁,从而使所有GPU阻塞。最好是为GPU内部的日志分配内存,并且只移动较大的日志。