乾明 编译整理
量子位 出品 | 公众号 QbitAI
注意力(Attention)机制,是神经机器翻译模型中非常重要的一环,直接影响了翻译的准确度与否。
可以这么说,没有注意力机制,机器翻译的水平只有60-70分。有了注意力机制,翻译的水平就能够达到80-90分了。
它是如何发挥作用的呢?很多人一解释起来,就是铺天盖地的数学公式,让人还没来得及看,就直接懵逼了。

最近,有一篇文章用图解的方式,完整地介绍了“注意力机制”的原理逻辑,并以谷歌神经翻译为例,解释了它的运作机制。
作者说,写这篇文章的目的,是为了让大家在不去看数学公式的情况下,掌握注意力的概念。他也会以人类译者为例,将相关的概念形象化。
神经机器翻译为何需要注意力机制?
神经机器翻译方法诞生于2013年。那一年,牛津大学的研究团队发表了一篇题为Recurrent Continuous Translation Models的论文,提出了一个用于机器翻译的新模型。

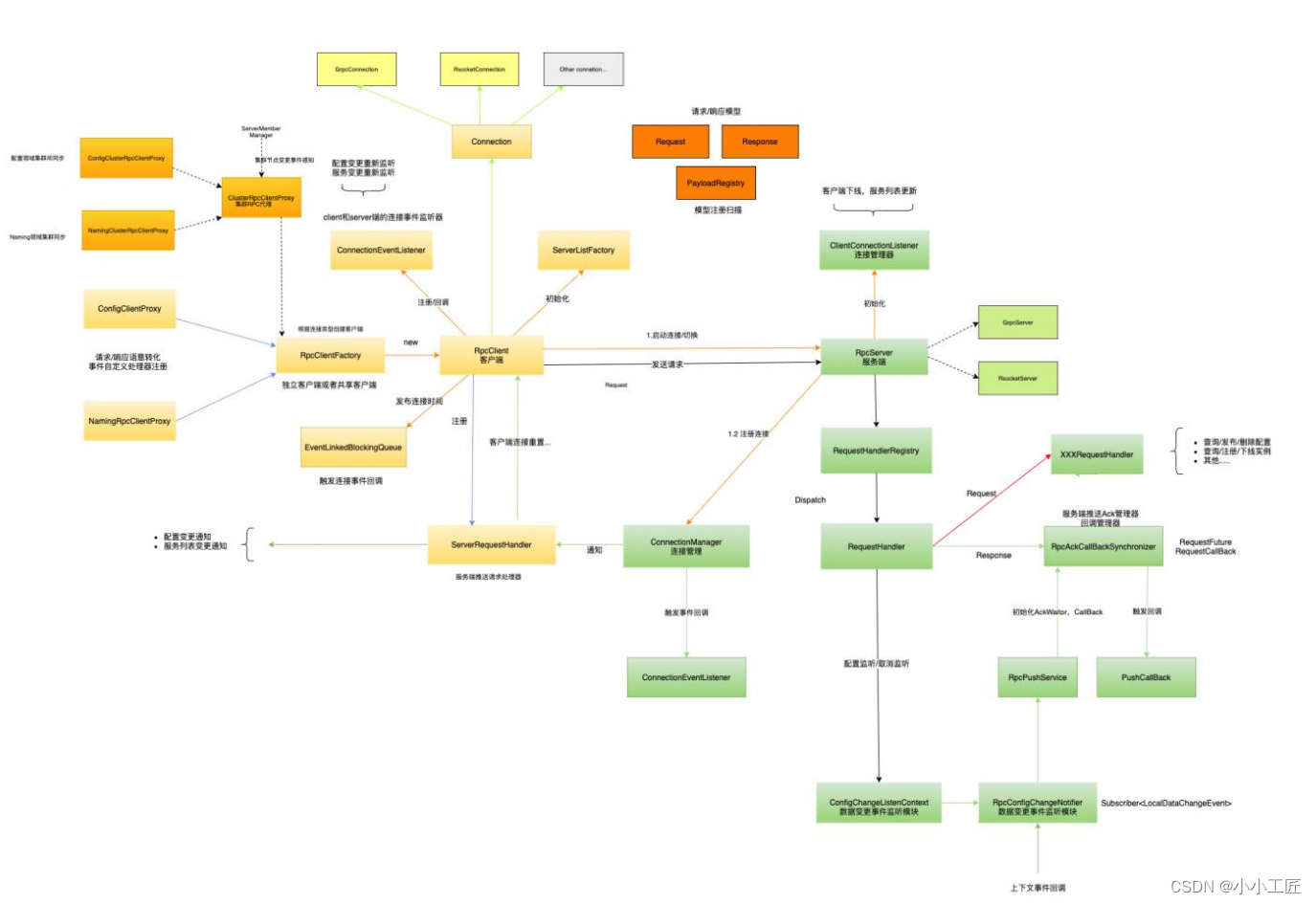
这个新模型使用的是端到端的编码器-解码器结构。
在处理翻译工作的时候,先用卷积神经网络(CNN),将原始文本编码成连续的向量,然后使用循环神经网络(RNN)将连续向量转换成目标语言。
但由于梯度爆炸/消失的存在,但使用这种方法很难获取更长句子背后的信息,导致翻译性能大幅下降。
在2014年,当时在谷歌工作的Ilya Sutskever等人提出了序列到序列(seq2seq)学习的方法,将RNN同时用于编码器和解码器。

也把RNN的典型变体长短时记忆(LSTM)引入到了神经机器翻译中。这样以来,梯度爆炸/消失就得到了控制,长距离重新排序的问题得到了缓解。
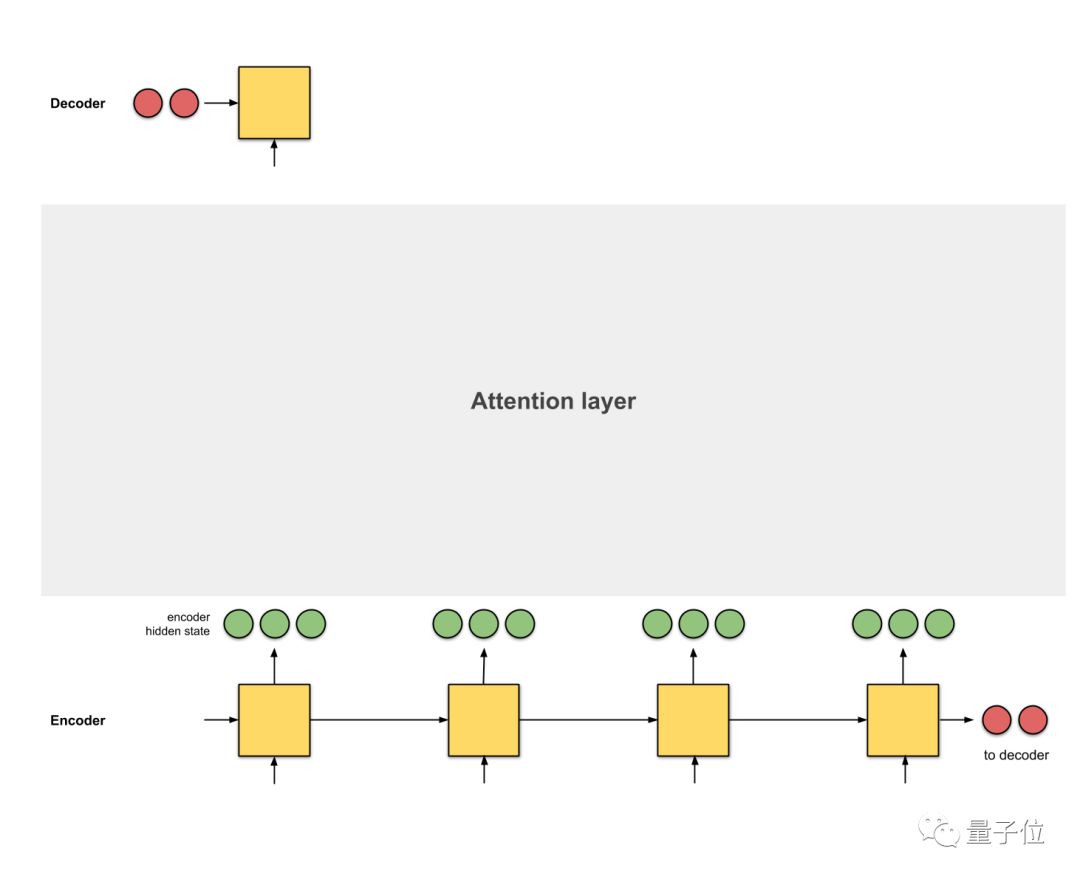
正所谓是摁下葫芦起来瓢,新的问题又出现了。seq2seq方法中,解码器从编码器中接收的唯一信息, 是最后编码器的隐藏状态,这是一个向量表征,是输入序列文本的数字概要。
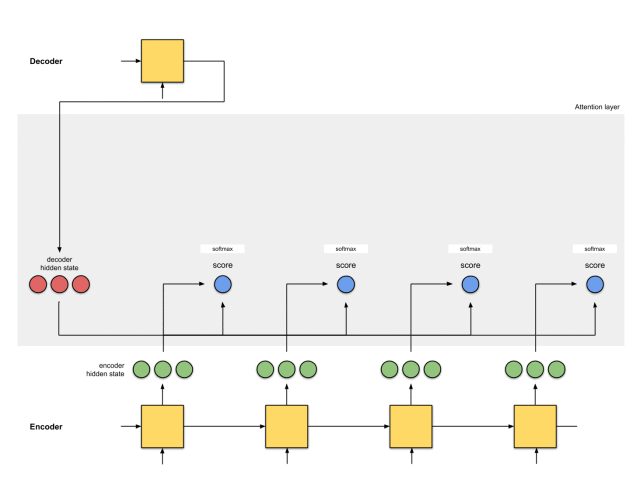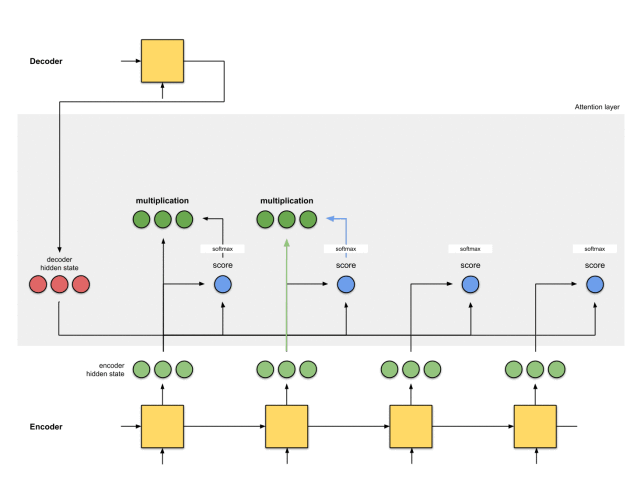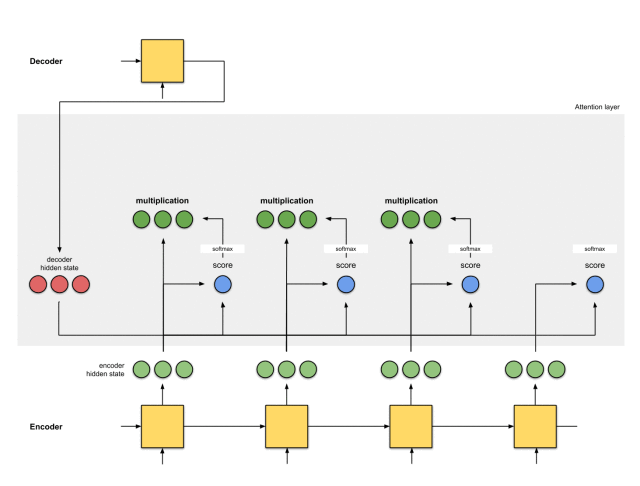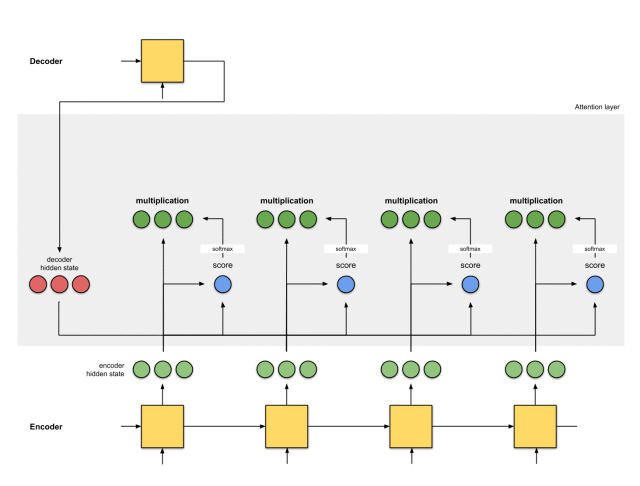
具体如下图中的两个红色节点所示。
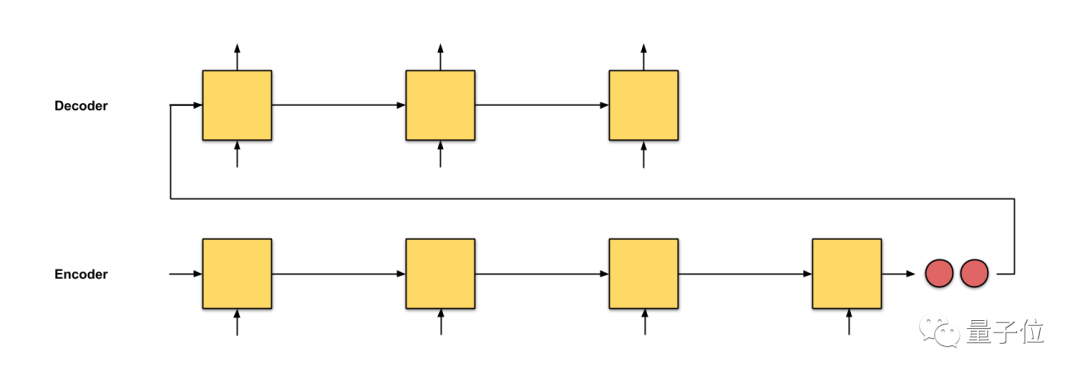
对于像下图这样很长的输入文本来说,我们特别希望这个隐藏状态,能够充分概括输入序列,解码器就能够根据这一个向量表征来很好的完成转换了。

但这很难,灾难性的遗忘出现了。比如上面说的这两个段落的字,在看到这的时候,你还能记得多少?能把它们翻译成英语吗?
除此之外,还有一个问题。在基于RNN的模型中,不管原始文本的句子有多长,都会被压缩成一个固定长度的向量。
在解码的时候,会有各种麻烦事,也没办法确定准确的信息。特别是句子很长的时候,更麻烦。
怎么办?“注意力机制”登场
2014年,DeepMind团队发表Recurrent Models of Visual Attention,提出了注意力机制,并将其用于图像分类的任务中。

与CNN相比,使用注意力机制的RNN取得了非常好的效果,直接带起了一波研究注意力机制的热潮。
很快,注意力就出现在了神经机器翻译中。
在ICLR 2015上,蒙特利尔大学的Yoshua Bengio团队发表了一篇论文,在神经机器翻译中引入了注意力机制。(这篇论文在2014年9月,就已经提交到了arXiv上)

注意力,是编码器和解码器之间的接口。有了它,解码器接收到的,就不仅仅是一个统一的向量表征了,还有来自编码器每个时间步的向量表征,比如下图中的绿色节点。
通过注意力机制,模型就能够有选择地关注输入序列中有用的部分,从而在解码器和编码器之间对齐。
之后,神经机器翻译所面临的问题,基本上也都有了解决方案。
2016年,谷歌推出了首个基于神经机器翻译的翻译系统。
现在,神经机器翻译已经成为了主流翻译工具的核心方法。
在这段发展历程中,RNN和LSTM,已经有了大量的介绍。注意力机制到底是怎么运作的呢?它到底有何魔力?
接下来请你收看——
图解注意力运作机制
注意力一共分类两种。一种是全局注意力,使用所有编码器隐藏状态。另一种是局部注意力,使用的是编码器隐藏状态的子集。在这篇文章中,提到的注意力,都是全局注意力。
在开始之前,需要看换一下仅基于seq2seq方法的模型是如何翻译的。
以一个将文本从德语翻译成英语的翻译员为例。
使用“seq2seq”方法的话,他会从头开始逐字逐句阅读德语文本,然后逐字逐句将文本翻译成英语。如果句子特别长的话,他在翻译的时候,可能就已经忘了之前文本上的内容了。
如果使用seq2seq+注意力的方法,他在逐字逐句阅读德语文本的时候,会写下关键词。然后,利用这些关键词,将文本翻译成英语。
在模型中,注意力会为每个单词打一个分,将焦点放在不同的单词上。然后,基于softmax得分,使用编码器隐藏状态的加权和,来聚合编码器隐藏状态,以获得语境向量。
注意力层的实现可以分为6个步骤。
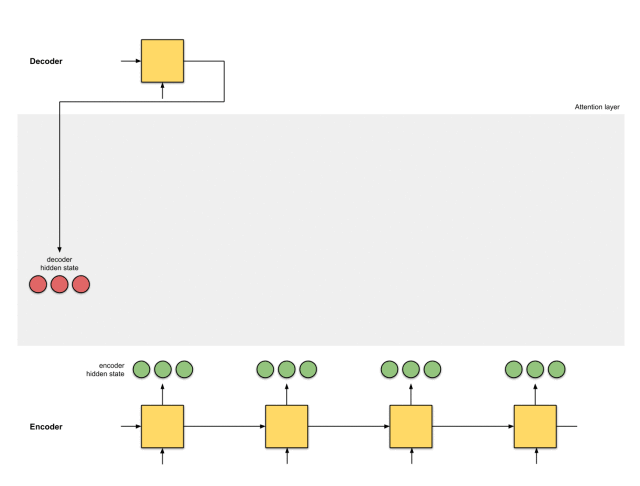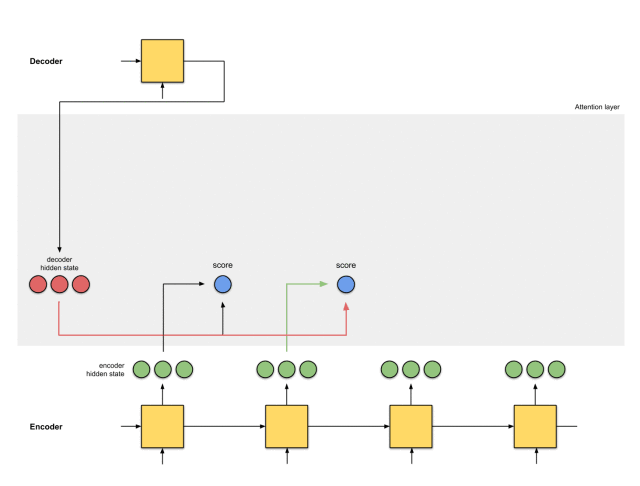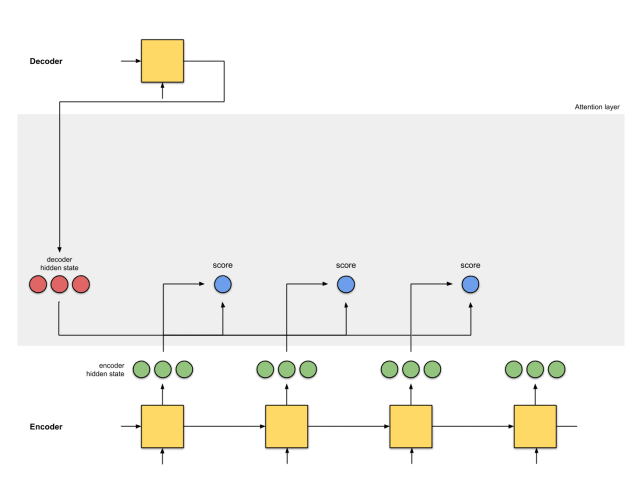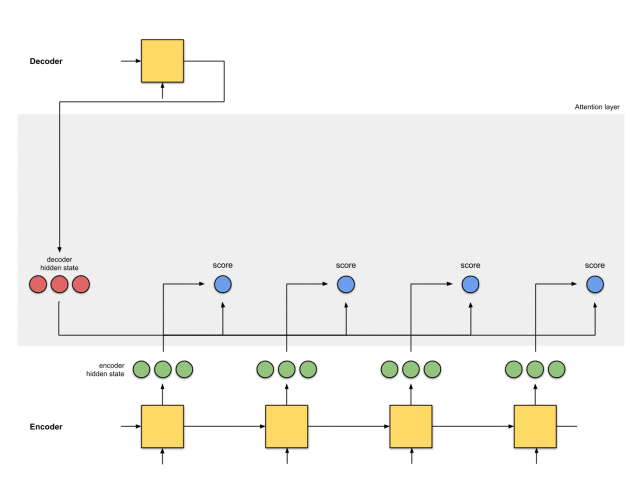
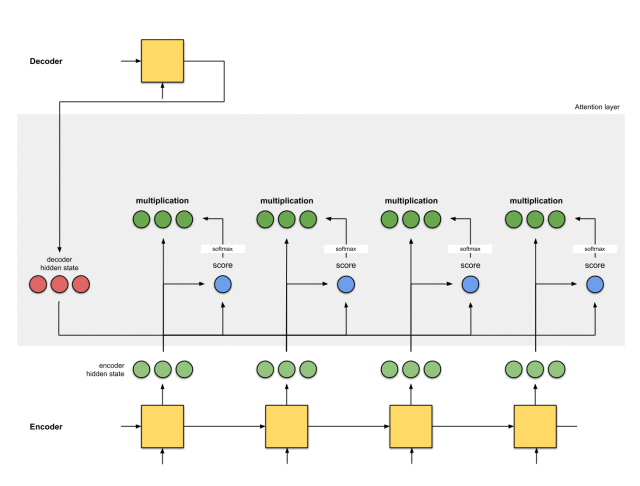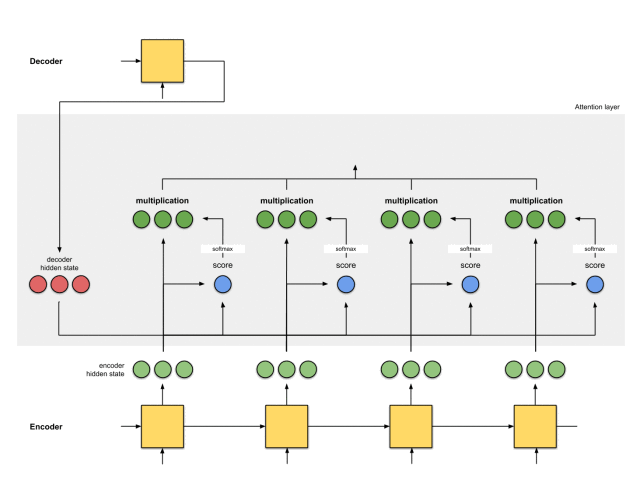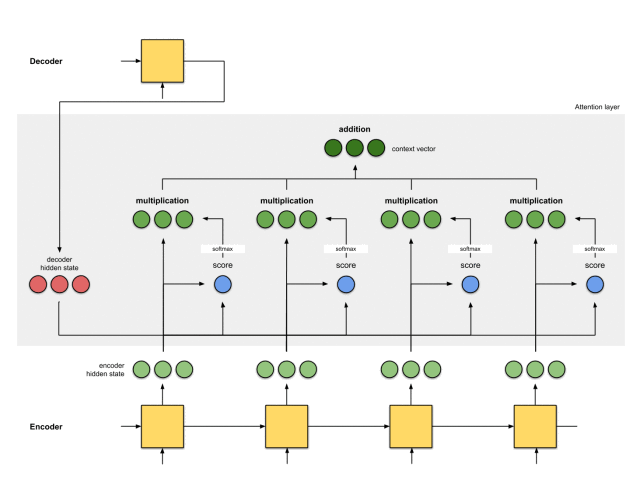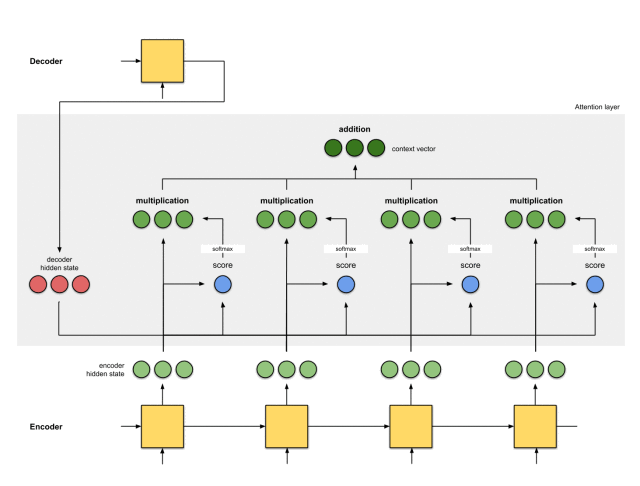
第一步:准备隐藏状态
首先,准备第一个解码器的隐藏状态(红色)和所有可用的编码器的隐藏状态(绿色)。在我们的例子中,有4个编码器的隐藏状态和当前解码器的隐藏状态。

第二步:获取每个编码器隐藏状态的分数
通过评分函数来获取每个编码器隐藏状态的分数(标量)。在这个例子中,评分函数是解码器和编码器隐藏状态之间的点积。
decoder_hidden = [10, 5, 10]
encoder_hidden score
---------------------
[0, 1, 1] 15 (= 10×0 + 5×1 + 10×1, the dot product)
[5, 0, 1] 60
[1, 1, 0] 15
[0, 5, 1] 35
在上面的例子中,编码器隐藏状态[5,0,1]的注意力分数为60,很高。这意味着要翻译的下一个词将受到这个编码器隐藏状态的严重影响。
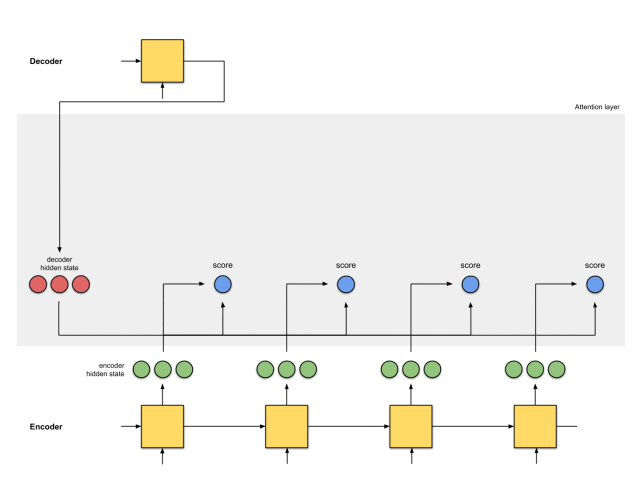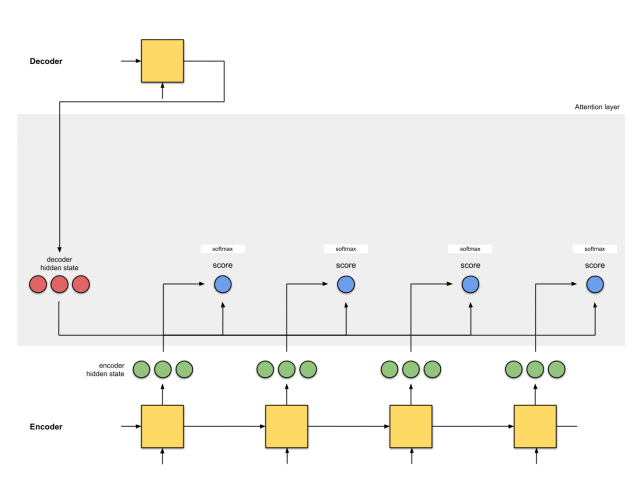
第三步:通过softmax层运行所有得分
我们将得分放到softmax函数层,使softmax得分(标量)之和为1。这些得分代表注意力的分布。
encoder_hidden score score^
-----------------------------
[0, 1, 1] 15 0
[5, 0, 1] 60 1
[1, 1, 0] 15 0
[0, 5, 1] 35 0
需要注意的是,基于softmaxed得分的score^。注意力仅按预期分布在[5,0,1]上。实际上,这些数字不是二进制数,而是0到1之间的浮点数。
第四步:将每个编码器的隐藏状态乘以其softmax得分
将每个编码器的隐藏状态与其softmaxed得分(标量)相乘,就能获得对齐向量。这就是发生对齐机制的地方。
encoder_hidden score score^ alignment
----------------------------------------
[0, 1, 1] 15 0 [0, 0, 0]
[5, 0, 1] 60 1 [5, 0, 1]
[1, 1, 0] 15 0 [0, 0, 0]
[0, 5, 1] 35 0 [0, 0, 0]
由于注意力分数很低,除了[5,0,1]之外的所有编码器隐藏状态的对齐都减少到了0。这意味着,我们可以预期,第一个被翻译的单词,应该与带有[5,0,1]嵌入的输入单词匹配起来。
第五步:将对齐向量聚合起来
将对齐向量聚合起来,得到语境向量。
encoder_hidden score score^ alignment
----------------------------------------
[0, 1, 1] 15 0 [0, 0, 0]
[5, 0, 1] 60 1 [5, 0, 1]
[1, 1, 0] 15 0 [0, 0, 0]
[0, 5, 1] 35 0 [0, 0, 0]
context = [0+5+0+0, 0+0+0+0, 0+1+0+0] = [5, 0, 1]
第六步:将语境向量输入到解码器中
这一步怎么做,取决于模型的架构设计。在接下来的示例中,会看到在模型架构中,解码器如何利用语境向量。
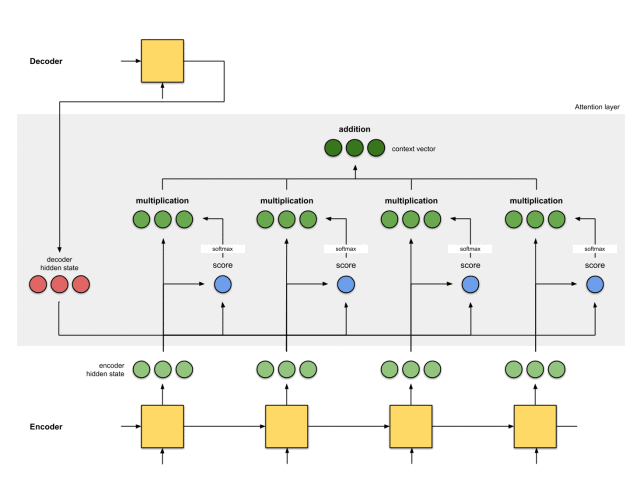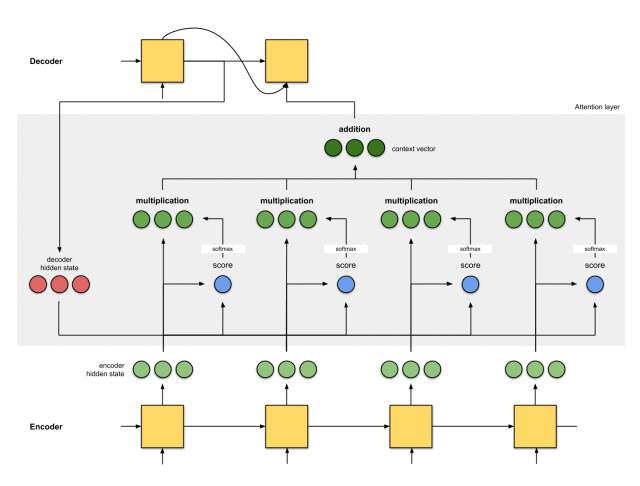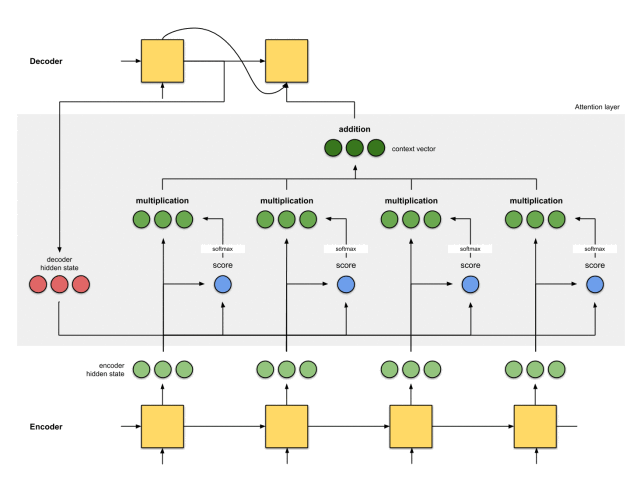
整体的运行机制,如下图所示:

那么,注意力机制是如何发挥作用的呢?
反向传播。反向传播将尽一切努力确保输出接近实际情况。这是通过改变RNN中的权重和评分函数(如果有的话)来完成的。
这些权重将影响编码器的隐藏状态和解码器的隐藏状态,进而影响注意力得分。
谷歌神经机器翻译如何应用注意力机制?
在介绍谷歌神经机器翻译模型之前,还需要补补课,看一下另外两个模型。
Bengio团队的研究
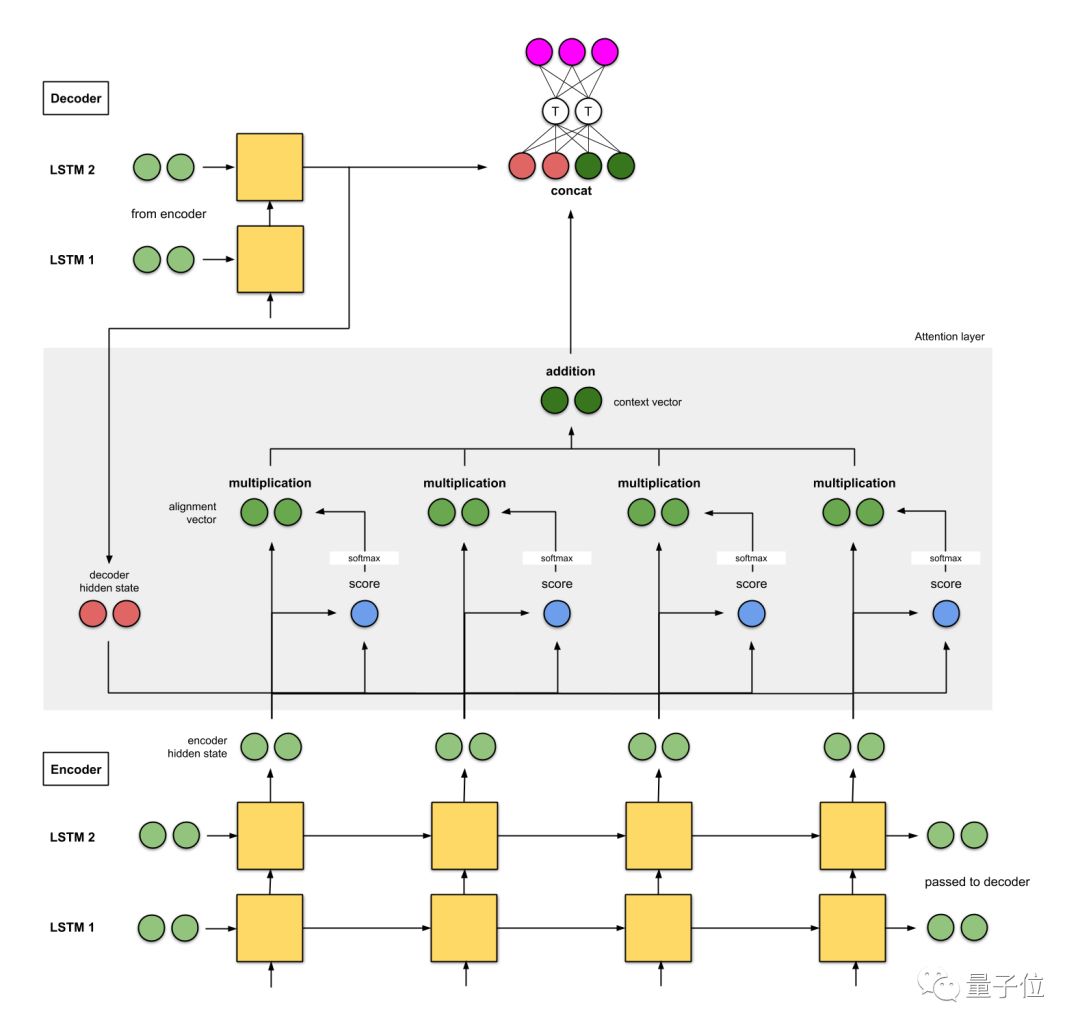
这是一个具有双向编码器的seq2seq+注意力模型,以下是模型架构的注意事项:
1、编码器是一个双向(正向+反向)门控循环单元(BiGRU)。解码器是一个GRU,它的初始隐藏状态,是从反向编码器GRU的最后隐藏状态修改得来的向量。
2、注意力层中的评分函数使用的是additive/concat。
3、到下一个解码器时间步的输入是来自前一个解码器时间步(粉红色)的输出和来自当前时间步(深绿色)语境向量之间的串联。
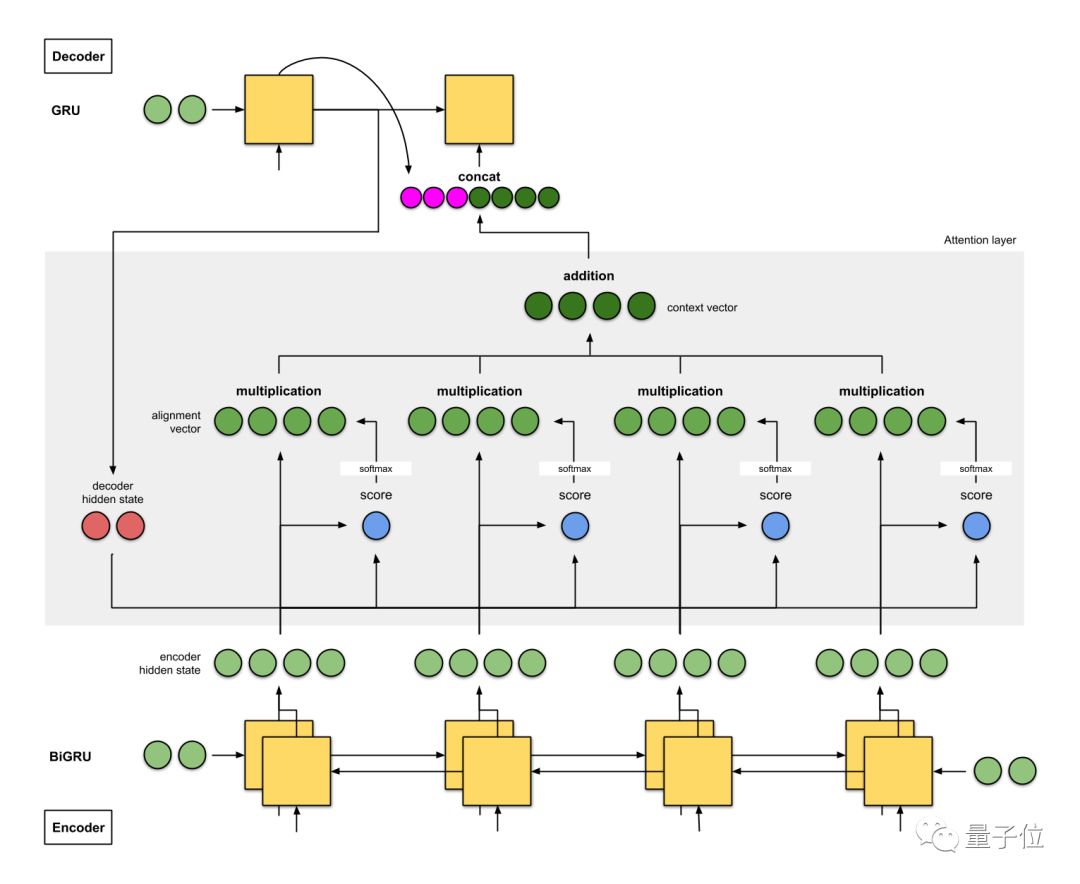
这个模型架构,在WMT’14英语-法语数据集上的BLEU分数是26.75。
(论文链接在文末)
相当于在将德语文本翻译成英语的时候,用了两个翻译员。
翻译员A,在逐字逐句阅读德语文本的时候,会写下关键词。翻译员B,在倒着逐字逐句阅读德语文本的时候,写下关键词。
这两个翻译员,会定期讨论他们在讨论之前阅读的每一个单词。
读完德语文本之后,翻译员B会根据他们两个之间的讨论,以及选择的关键词,将文本翻译成英语。
在这里,翻译员A,是正向RNN,翻译员B,是反向RNN。
斯坦福大学团队的研究
与Bengio等人的模型相比,斯坦福大学团队提出的模型架构,更具有概括性,也更加简单。要点如下:
1、编码器是一个双层的LSTM网络。解码器也具有相同的架构,它初始隐藏状态是最后的编码器隐藏状态。
2、他们模型的评分函数有四种,分别是:additive/concat、dot product、location-based和’general’。
3、当前解码器时间步的输出与来自当前时间步的语境向量之间的串联,会输入到前馈神经网络中,来得出当前解码器时间步的最终输出(粉红色)。
(论文链接在文末)
这个模型架构,在WMT’15英语-德语数据集上的BLEU分数是25.9。
简单来说,这是一个采用双层堆叠编码器的seq2seq+注意力模型。
在将德语文本翻译到英语时,翻译员A一样在阅读德语文本的时候,写下关键词。在这里,翻译员B比翻译员A要更专业,他也会阅读同样的德语文本,并写下关键词。
主要注意的是,翻译员A阅读的每个单词,都要向翻译员B报告。完成阅读后,他们会根据他们选择的关键词,将文本翻译成英语。
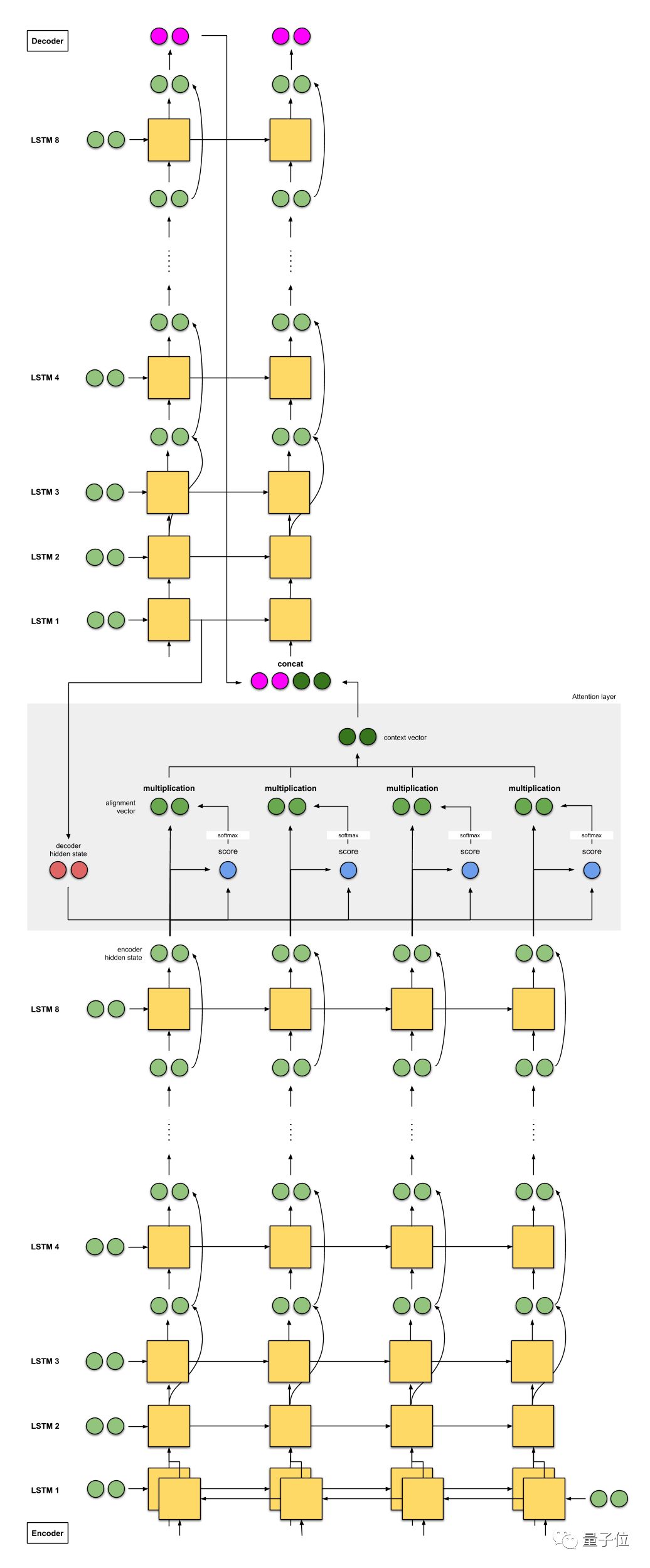
谷歌的神经机器翻译模型
谷歌神经机器翻译,集两者之大成,但受Bengio等人的模型影响多一点。要点是:
1、编码器由8个LSTM组成,其中第一个是双向的(输出是连接的),连续层的输出之间有残差连接(从第3层开始)。解码器是8个单向LSTM的独立堆栈。
2、评分函数使用的是additive/concat。
3、解码器下一个时间步的输入是前一个时间步(粉红色)的输出与当前时间步(深绿色)的语境向量之间的串联。
这个模型架构,在WMT’14英语-法语数据集上的BLEU分数是38.95。在WMT’14英语-德语数据集上的BLEU分数是24.17。
(论文链接在文末)
这是一个具有8个堆叠编码器的seq2seq(+双向+残差连接)+注意力的模型。
相当于在将德语文本翻译成英语的时候,用了八个翻译员,分别是翻译员A、B、C…H。每一位翻译员都阅读相同的德语文本。
对于文本中的每一个单词,翻译员A都会给翻译员B分享他的发现,翻译员B会改进这些发现,然后与翻译员C分享,一直重复这个过程,直到翻译员H结束。
此外,在阅读德语文本的时候,翻译员H会基于他知道的和收到的信息写下关键词。
每个人都读完了这个英语文本后,翻译员A就会被告知翻译第一个单词。
首先,他试图回忆文本内容,给出翻译,然后与翻译员B分享他的答案,翻译员B改进答案并与翻译员C分享,一直重复这个过程,直到翻译员H结束。
然后,翻译员H会根据他写下的关键词给出第一个词的翻译。然后重复这个过程,直到翻译结束。
相关资料推荐
Yoshua Bengio等人研究的论文
Neural Machine Translation by Jointly Learning to Align and Translate
https://arxiv.org/abs/1409.0473
斯坦福大学团队的论文
Effective Approaches to Attention-based Neural Machine Translation
https://arxiv.org/abs/1508.04025
谷歌神经机器翻译模型的论文
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
https://arxiv.org/abs/1609.08144
其他相关论文推荐:
Recurrent Models of Visual Attention
https://papers.nips.cc/paper/5542-recurrent-models-of-visual-attention.pdf
Recurrent Continuous Translation Models
https://www.aclweb.org/anthology/D13-1176
Attention Is All You Need
https://arxiv.org/abs/1706.03762
Sequence to Sequence Learning with Neural Networks
https://arxiv.org/abs/1409.3215
教程资源:
TensorFlow’s seq2seq Tutorial with Attention (Tutorial on seq2seq+attention)
https://github.com/tensorflow/nmt
入门博客文章:
Lilian Weng’s Blog on Attention (Great start to attention)
https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html#a-family-of-attention-mechanisms
Jay Alammar’s Blog on Seq2Seq with Attention (Great illustrations and worked example on seq2seq+attention)
https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
写这篇文章的,是一位名叫Raimi Bin Karim新加坡人,现在是AI Singapore中的一名AI学徒。AI Singapore,是一家为新加坡培育人工智能产业与人才的机构。
原文链接:
https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3
— 完 —
2018中国人工智能明星创业公司

加入社群
量子位AI社群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !