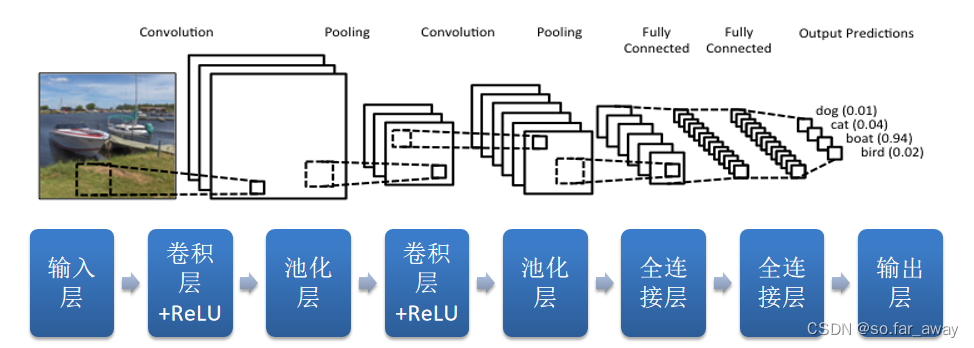
为什么要在Mapper端Join
解决数据倾斜有一个技巧:把Reducer端的操作变成Mapper端的Reduce,通过这种方式不需要发生Shuffle。如果把Reducer端的操作放在Mapper端,就避免了Shuffle。避免了Shuffle,在很大程度上就化解掉了数据倾斜的问题。Spark是RDD的链式操作,DAGScheduler根据RDD的不同类型的依赖关系划分成不同的Stage,所谓不同类型的依赖关系,就是宽依赖、窄依赖。当发生宽依赖的时候,把Stage划分成更小的Stage。划分的依据就是宽依赖。宽依赖的算子如reducByKey、groupByKey等。我们想做的是把宽依赖减掉,避免掉Shuffle,把操作直接发生在Mapper端。从Stage的角度讲,后面的Stage都是前面Stage的Reducer端,前面的Stage都是后面Stage的Mapper端。如果能去掉Reducer端的Shuffle操作,将其放在Mapper端,对我们解决数据倾斜很有价值。Spark 2.0版本中就有Mapper端聚合,只有Mapper端完成Shuffle的业务。
适用场景
在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M或者一两G)。
实现思路
不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行m