爬取League of Legends壁纸
详细思路与过程
网址:https://wall.alphacoders.com/search.php?search=League+of+Legends
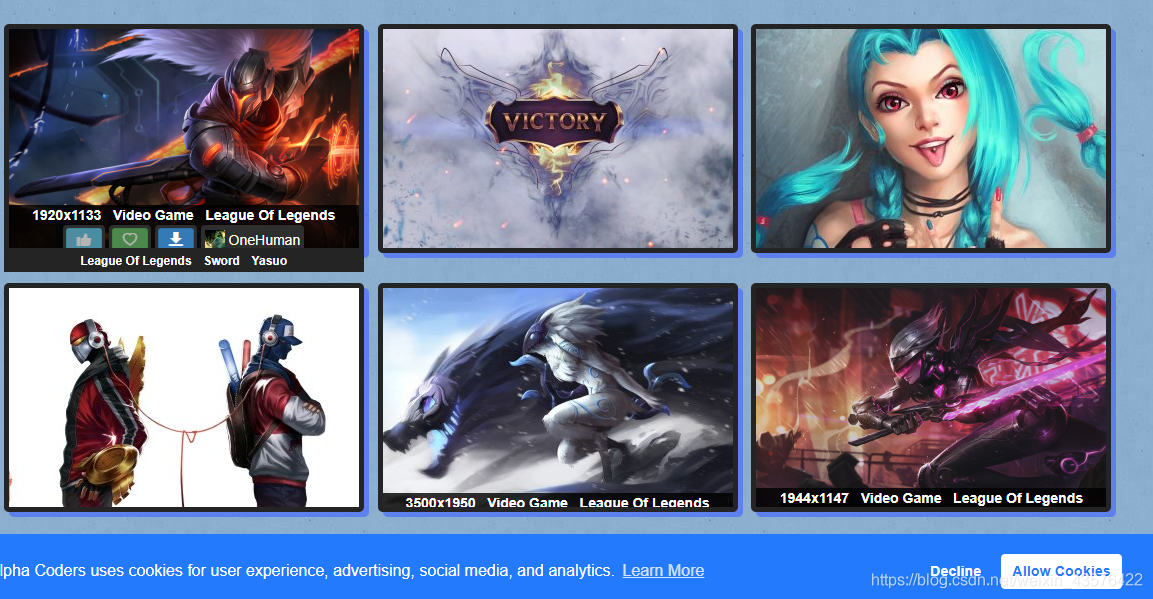
把鼠标放置某一张图片上,就会出现该图片的link:
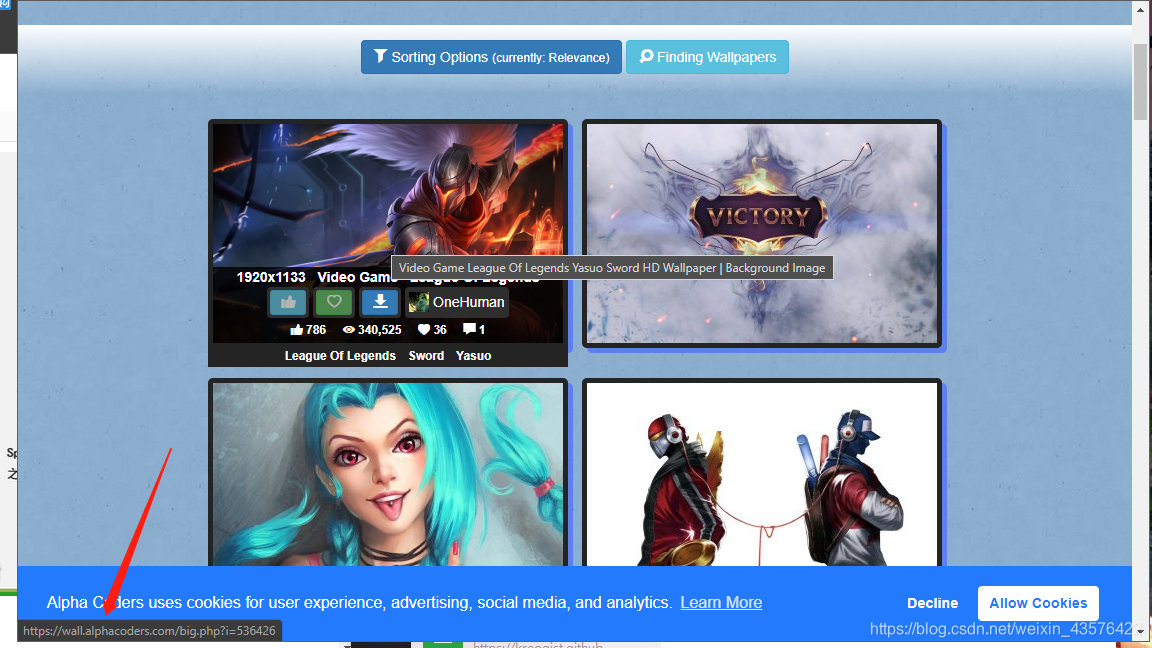
右键,查看网页源代码(没有这个选项的就换个浏览器):
并按ctrl+F,进行关键词检索,搜索你上一步看到的链接,比如我这里是i=536426

这是我们要的
接着把关键词改为

刚好30个标签,回去数一个主页面正是有30张图。所以可以确认这是我们要的。但是这是一个相对路径:
<div class='boxgrid'><a href="big.php?i=536426"
点进去这个图片,查看完整链接:

https://wall.alphacoders.com/big.php?i=536426
那么显然在获取href之后再前面加上:
https://wall.alphacoders.com/
就是完整的链接。
接下来的操作非常类似:
把鼠标放置某一张图片上,就会出现该图片的link,
在这个图片界面右键,查看源代码,
根据你刚刚看到的关键词检索:
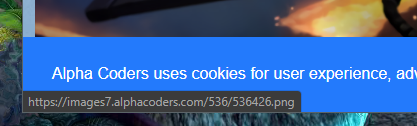
轻轻松松又找到了

直接复制这个链接:
https://images7.alphacoders.com/536/536426.png
换一个浏览器发现可以直接打开

并且我们返回最开始的界面,点击下一页
https://wall.alphacoders.com/search.php?search=league+of+legends&page=2
https://wall.alphacoders.com/search.php?search=league+of+legends&page=3
https://wall.alphacoders.com/search.php?search=league+of+legends&page=4
https://wall.alphacoders.com/search.php?search=league+of+legends&page=5
https://wall.alphacoders.com/search.php?search=league+of+legends&page=6
发现每一页的规律其实 是
https://wall.alphacoders.com/search.php?search=league+of+legends&page=页数
那么接下来就可以编写爬虫代码了:
- 打开https://wall.alphacoders.com/search.php?search=League+of+Legendss&page=1
- 爬取当前页面的图片link
- 点击下一页,即把网址的page+1,重复第二步,直到爬完所需页数
- 分别点击每一张图,获取真正的图片link,保存图片
代码如下:
#网址:https://wall.alphacoders.com/search.php?search=League+of+Legendsimport requests
import re #正则表达式
import os
from lxml import etree #python的html/xml解析器
from multiprocessing import Pool #进程池headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ''AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/78.0.3904.97 Safari/537.36'
}#获取当前页面图片链接
def get_pic_link(url):res = requests.get(url,headers)selector = etree.HTML(res.text)href = selector.xpath('//div[@class="boxgrid"]/a/@href')#得到一个列表links = []for i in href:link = 'https://wall.alphacoders.com/'+str(i)res2 = requests.get(link,headers)selector2 = etree.HTML(res2.text)href2 = selector2.xpath('//div[@class="center img-container-desktop"]/a/@href')print(href2[0])links.append(href2[0])return links#将图片保存到本地
def save_pic(link):html = requests.get(link,headers)#获取图片标题title = link.split(r'/')[-1]with open(title,'wb') as f:f.write(html.content)if __name__ == '__main__':try:begin = 3end = 6urls = []urls.extend('https://wall.alphacoders.com/search.php?search=league+of+legends&page={}'.format(i) for i in range(begin,end))#这里设置页数for i in range(begin,end):#得到每个页面图片地址pool = Pool(processes=8)pool.map(save_pic,get_pic_link(urls[i-begin]))print('已保存第',+i,'页') except:print('error')就会得到:




爱了爱了




