目录
1. 图片爬取
2. 破解百度翻译
3. 豆瓣电影爬取
4. 肯德基餐厅位置爬取
1. 图片爬取
通过以下代码我们可以看到图片已经爬取进入虚拟机里面。
# -*- coding: utf-8 -*-
import re
import requests
from urllib import error
from bs4 import BeautifulSoup
import osfile = ''
List = []#爬取图片链接
def Find(url, A):global Listprint('正在检测图片总数,请稍等.....')s = 0try:Result = A.get(url, timeout=7, allow_redirects=False)except BaseException:print("error");else:result = Result.textpic_url = re.findall('data-src="(.*?)" data-type', result) # 先利用正则表达式找到图片urls += len(pic_url)if len(pic_url) == 0:print("没读到")else:List.append(pic_url)return s#下载图片
def dowmloadPicture():num = 1for each in List[0]:print('正在下载第' + str(num) + '张图片,图片地址:' + str(each))try:if each is not None:pic = requests.get(each, timeout=7)else:continueexcept BaseException:print('错误,当前图片无法下载')continueelse:if len(pic.content) < 200:continuestring = file + r'\\' + str(num) + '.jpg'fp = open(string, 'wb')fp.write(pic.content)fp.close()num+=1if __name__ == '__main__': # 主函数入口headers = {'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Connection': 'keep-alive','User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0','Upgrade-Insecure-Requests': '1'}A = requests.Session()A.headers = headersurl = 'https://mp.weixin.qq.com/s?__biz=MjM5NzU4OTQ0NQ==&mid=2650705400&idx=6&sn=5367e2f883a68cbb1a1157f0aa1057b2&chksm=bedd955289aa1c44c63a5e2e59805a24db3056dee709518884ceab738b8d306df1fd198af716&scene=27'total = Find(url, A)print('经过检测图片共有%d张' % (total))file = input('请建立一个存储图片的文件夹,输入文件夹名称即可: ')y = os.path.exists(file)if y == 1:print('该文件已存在,请重新输入')file = input('请建立一个存储图片的文件夹,)输入文件夹名称即可: ')os.mkdir(file)else:os.mkdir(file)dowmloadPicture()print('当前爬取结束,感谢使用')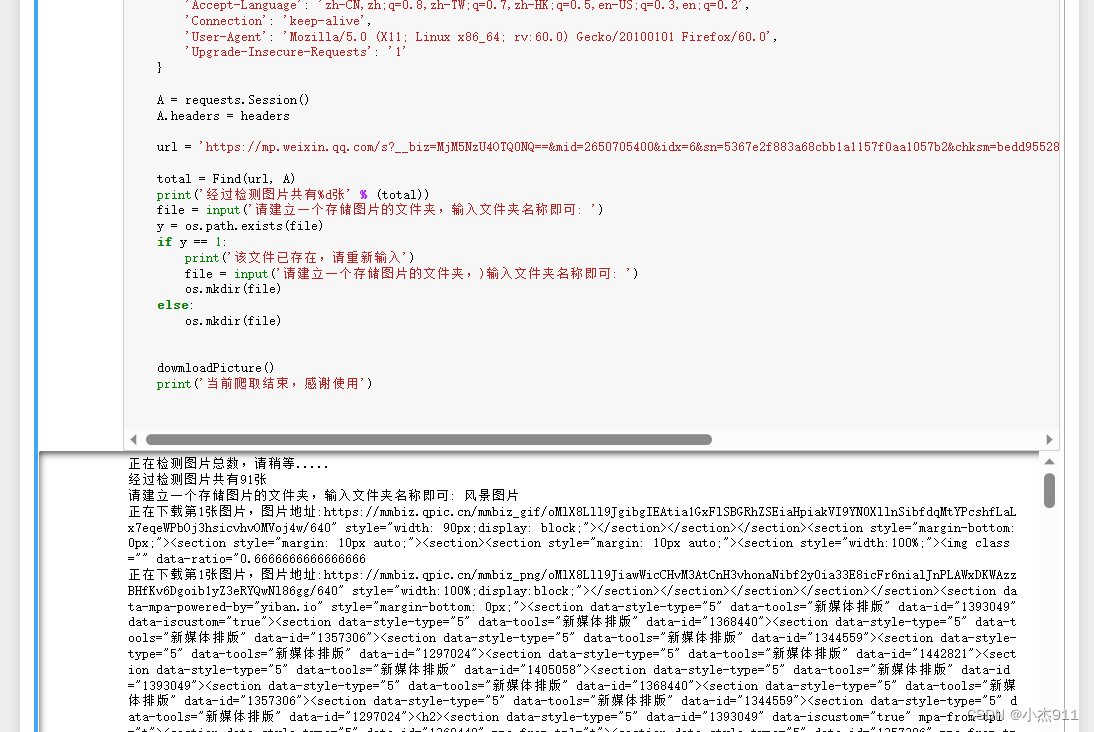

2. 破解百度翻译
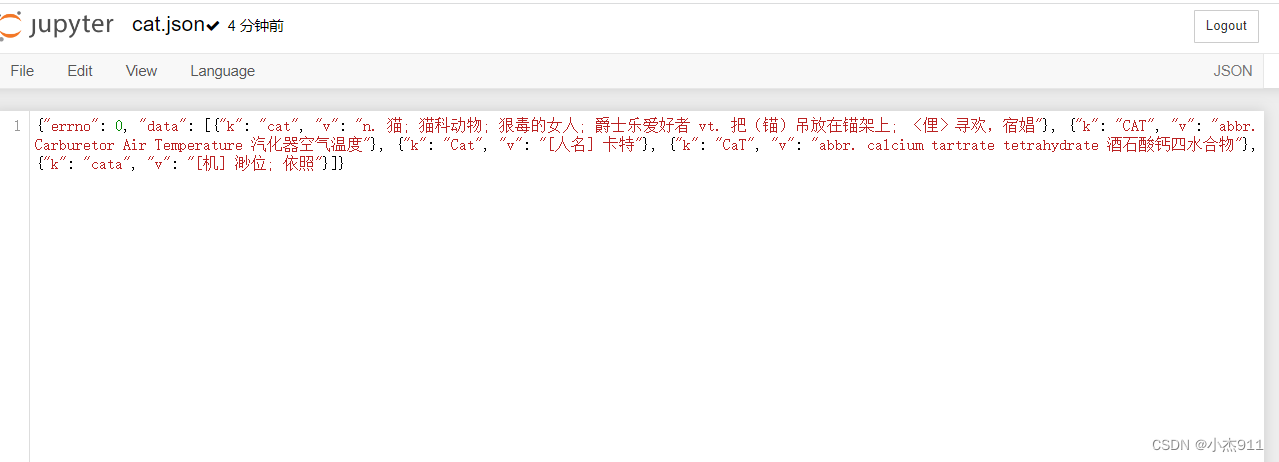
实现了翻译后的文本获取,保存本地json。
import requests
import json
if __name__ == "__main__":#1.指定urlpost_url = 'https://fanyi.baidu.com/sug'#2.进行UA伪装headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}#3.post请求参数处理(同get请求一致)word = input('输入要翻译的单词:')data = {'kw':word}#4.请求发送response = requests.post(url=post_url,data=data,headers=headers)#5.获取响应数据:json()方法返回的是obj(如果确认响应数据是json类型的,才可以使用json())dic_obj = response.json()#持久化存储fileName = word+'.json'fp = open(fileName,'w',encoding='utf-8')json.dump(dic_obj,fp=fp,ensure_ascii=False)print('over!!!')doc_obj=response.json()print(doc_obj)print('获取翻译结果成功!') 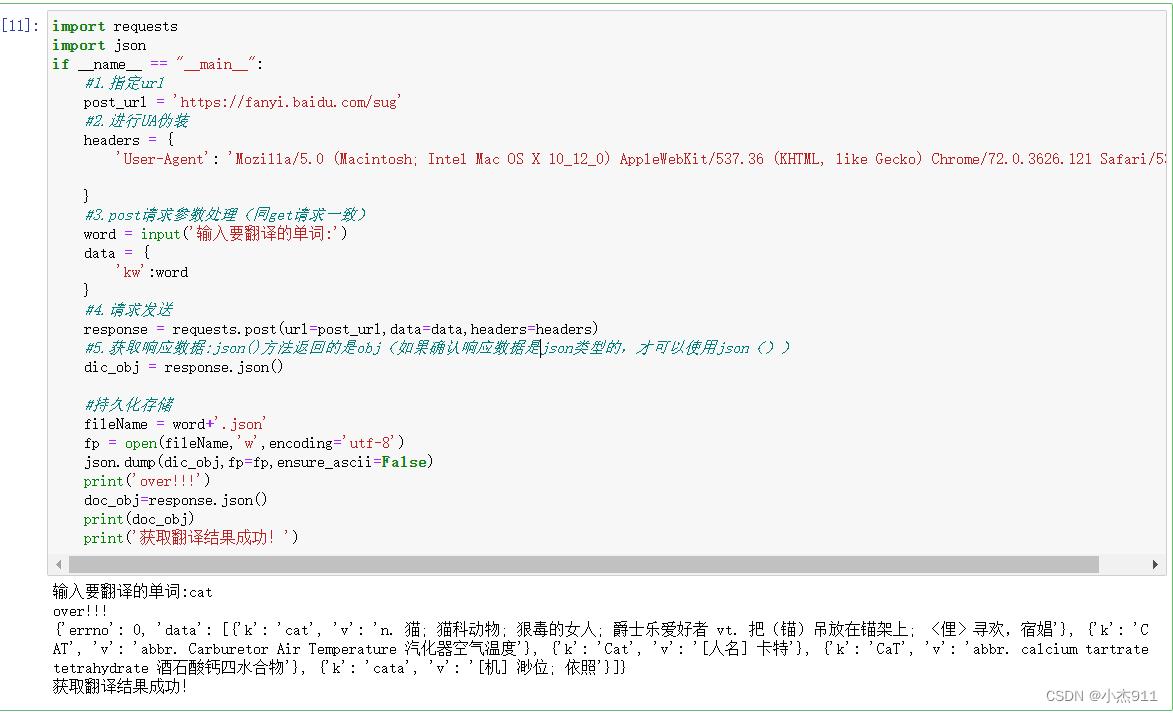
![]()
3. 豆瓣电影爬取
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import json
if __name__ == "__main__":url = 'https://movie.douban.com/j/chart/top_list'param = {'type': '24','interval_id': '100:90','action':'','start': '0',#从库中的第几部电影去取'limit': '20',#一次取出的个数}headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}response = requests.get(url=url,params=param,headers=headers)list_data = response.json()fp = open('./douban.json','w',encoding='utf-8')json.dump(list_data,fp=fp,ensure_ascii=False)doc_obj=response.json()print(doc_obj)print('over!!!')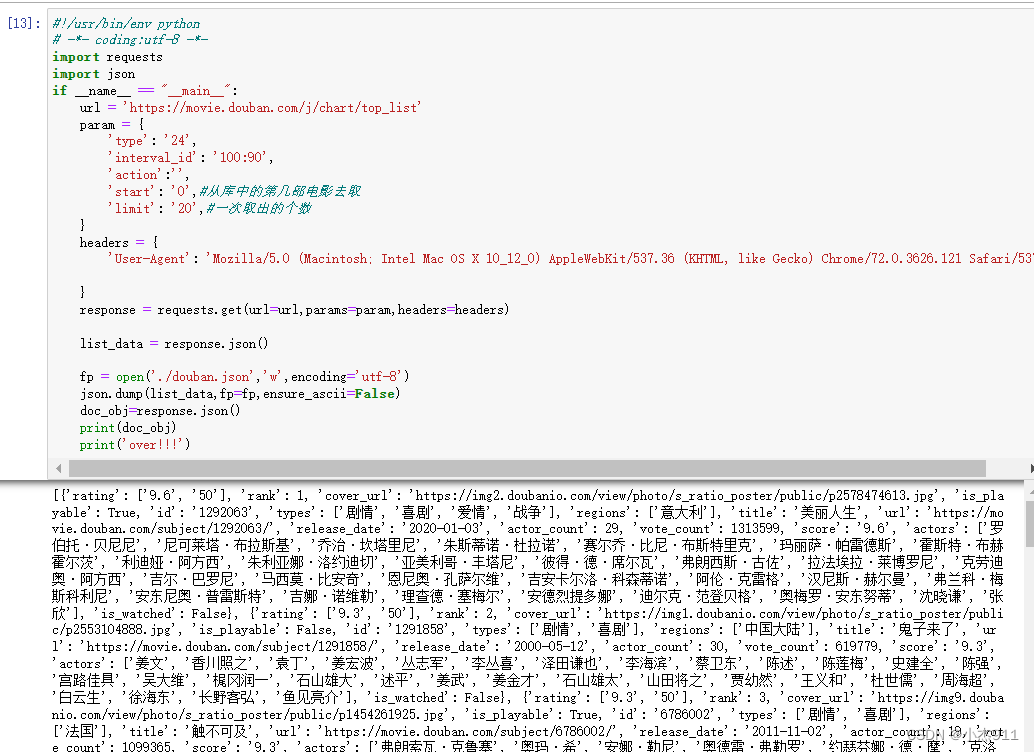
4. 肯德基餐厅位置爬取
# 爬取肯德基餐厅位置信息import requests;# 判断是否是当前文件运行
if __name__ == '__main__':# 请求数据的url定义url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword';# 请求头定义headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.4153 SLBChan/103"};# 获取用户输入的城市名cityName = input("请输入查询的城市名称:")# 请求参数定义params = {"cname":"","pid":"","keyword":cityName,"pageIndex":1,"pageSize":10}# 发起第一次post请求,获取表数据量response = requests.post(url=url,data=params,headers=headers);json_obj = response.json();rowCount = json_obj.get("Table")[0].get("rowcount");# 发起第二次post请求,获取数据params["pageSize"] = rowCount;response = requests.post(url=url, data=params, headers=headers);json_obj = response.json();datas = json_obj["Table1"];# 文件内容 标题定义fileContent = "省份\t城市名\t商店名\t地址\t特殊权限\n"# 遍历提取数据,进行格式化for item in datas:t_obj = item;fileContent += t_obj.get("provinceName") + "\t";fileContent += t_obj.get("cityName") + "\t";fileContent += t_obj.get("storeName") + "\t";fileContent += t_obj.get("addressDetail") + "\t";pro_value = t_obj.get("pro")if pro_value is not None:fileContent += str(pro_value) + "\n"else:fileContent += "\n"doc_obj=response.json()print(doc_obj)# 写到文件中保存file = open("./KenDeiJi_datas.txt","w",encoding="utf-8");file.write(fileContent);file.close();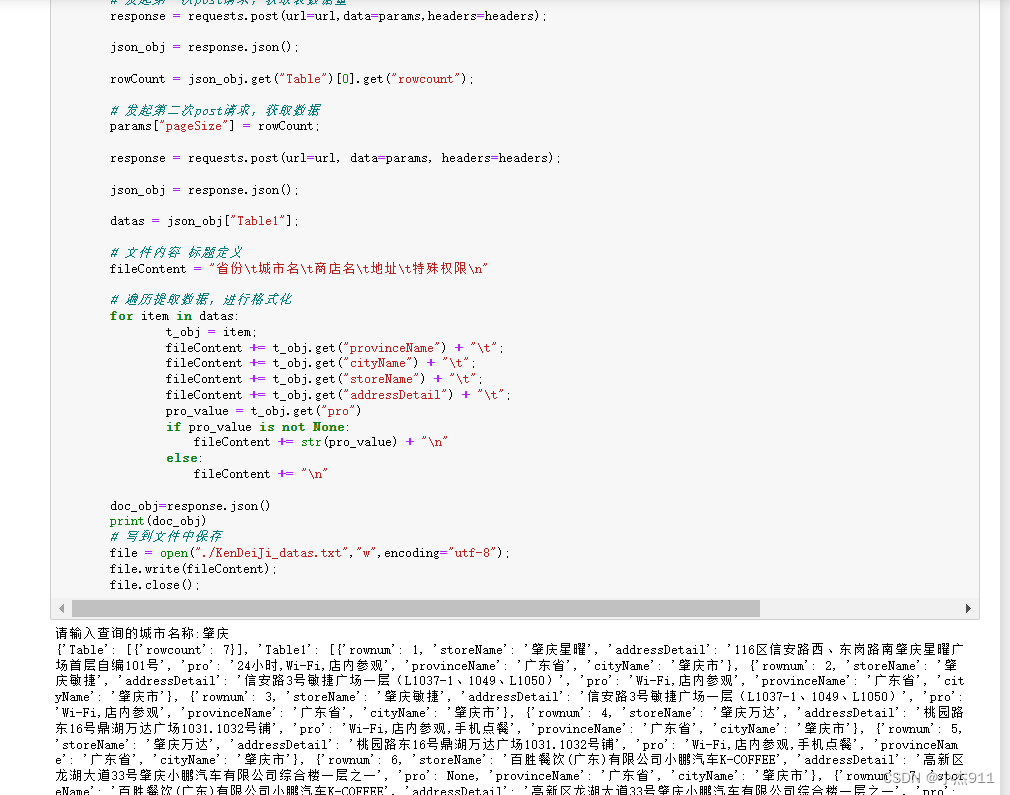
![]()

关注博主下篇更精彩
一键三连!!!
一键三连!!!
一键三连!!!
感谢一键三连!!!