第七章.集成学习 (Ensemble Learning)
7.1 集成学习—袋装(bagging),随机森林(Random Forest)
集成学习就是组合多个学习器,最后得到一个更好的学习器。
1.常见的4种集成学习算法
- 个体学习器之间不存在强依赖关系,袋装(bagging)
- 随机森林(Random Forest)
- 个体学习器之间存在强依赖关系,提升(boosting)
- Stacking
2.袋装(bagging)
bagging也叫bootstrap aggregating,是原始数据集选择S次后得到S个新数据集的一种技术,是一种有放回的抽样。
1).示例:
①.原始训练数据集:{0,1,2,3,4,5,6,7,8,9}
②.Bootstrap采样:
{7,2,6,7,5,4,8,8,1,0}—未采样3,9
{1,3,8,0,3,5,8,0,1,9}—未采样2,4,6,7
{2,9,4,2,7,9,3,0,1,0}—未采样5,6,8
③.图像
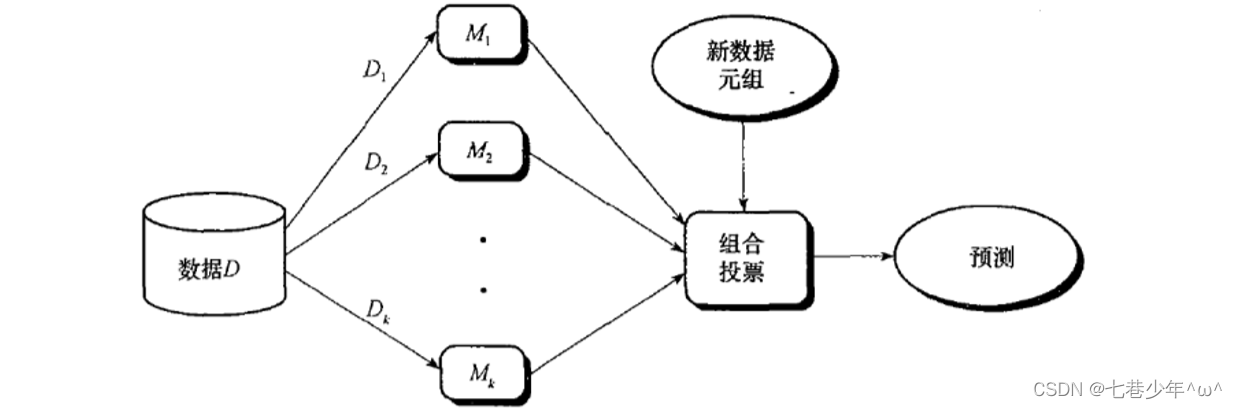
- 从数据D中抽样K组新的数据集,每个数据集可以应用不同的算法进行建模(KNN,神经网络),共有K个模型,引入的新数据使用K个模型进行预测,然后组合投票决定最终输出结果。
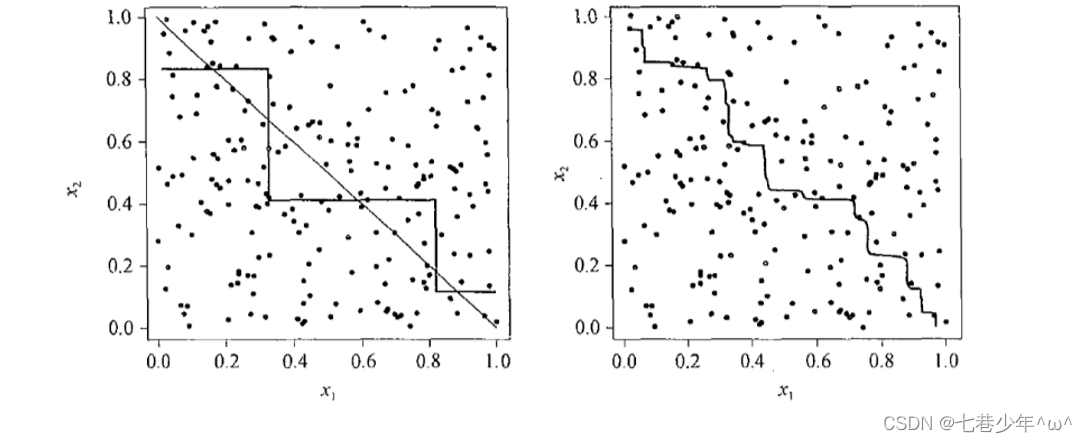
- 假设图中是分类模型,左图有两个分类模型,两个分类模型组合起来可能是右图的决策边界
2).代码实现:
使用bagging后的测试结果有可能有提升,有可能不变,也有可能下降,在数据集比较复杂的情况下,建议使用bagging。
from sklearn import tree
from sklearn import neighbors
from sklearn import datasets
from sklearn.ensemble import BaggingClassifier
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt# 绘图
def plot(model):x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1# 生成网格矩阵xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))z = model.predict(np.c_[xx.ravel(), yy.ravel()])z = z.reshape(xx.shape)# 绘制等高线cs = plt.contourf(xx, yy, z)# 加载数据
iris = datasets.load_iris()
x_data = iris.data[:, :2]
y_data = iris.target# 数据切分
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data)# KNN模型
knn = neighbors.KNeighborsClassifier()
knn.fit(x_train, y_train)
knn_accuracy = knn.score(x_test, y_test)
print('knn_accuracy:', knn_accuracy)# DicisionTree模型
dtree = tree.DecisionTreeClassifier()
dtree.fit(x_train, y_train)
dtree_accuracy = dtree.score(x_test, y_test)
print('dtree_accuracy:', dtree_accuracy)# 绘制bagging_knn分类模型
bagging_knn = BaggingClassifier(knn, n_estimators=100)
bagging_knn.fit(x_train, y_train)
bagging_knn_accuracy = bagging_knn.score(x_test, y_test)
print('bagging_knn_accuracy:', bagging_knn_accuracy)# 绘制bagging_dtree分类模型
bagging_dtree = BaggingClassifier(dtree, n_estimators=100)
bagging_dtree.fit(x_train, y_train)
bagging_dtree_accuracy = bagging_dtree.score(x_test, y_test)
print('bagging_dtree_accuracy:', bagging_dtree_accuracy)# 绘制knn分类模型
plt.subplot(2, 2, 1)
plot(knn)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)# 绘制决策树分类模型
plt.subplot(2, 2, 2)
plot(dtree)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)# 绘制bagging_knn分类模型
plt.subplot(2, 2, 3)
plot(bagging_knn)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)# 绘制bagging_dtree分类模型
plt.subplot(2, 2, 4)
plot(bagging_dtree)
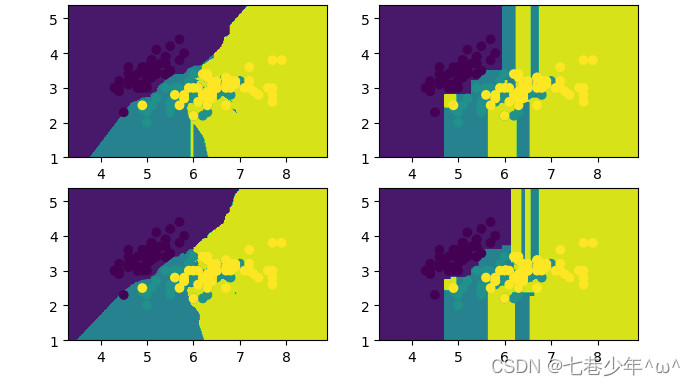
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)plt.show()3).结果展示:
- 数据结果

- 图像结果
3.随机森林(Random Forest)
1).公式:
RF = 决策树 + Bagging + 随机属性选择
2).图像表示:
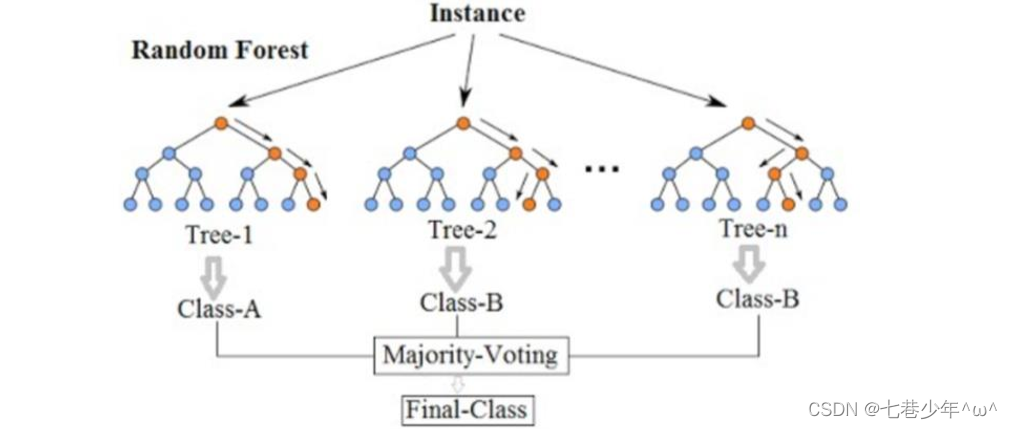
3).RF算法流程
①.样本的随机:从样本集中用bagging的方式,随机选择n个样本。
②.特征的随机:从所有属性d中随机选择k个属性(k<d),然后从k个属性中选择最佳分割属性作为节点建立CART决策树。
③.重复以上两个步骤m次。建立m颗CART决策树
④.这m颗CART决策树形成随机森林,通过投票表决结果,决定数据属于哪一类。
4).代码实现:
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import matplotlib.pyplot as plt# 绘制图像
def plot(model):x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1# 生成网格矩阵xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))z = model.predict(np.c_[xx.ravel(), yy.ravel()])z = z.reshape(xx.shape)cs = plt.contourf(xx, yy, z)# 加载数据
data = np.genfromtxt('D:\\Data\\LR-testSet2.txt', delimiter=',')# 数据切分
x_data = data[:, :-1]
y_data = data[:, -1]# 测试集和训练集切分
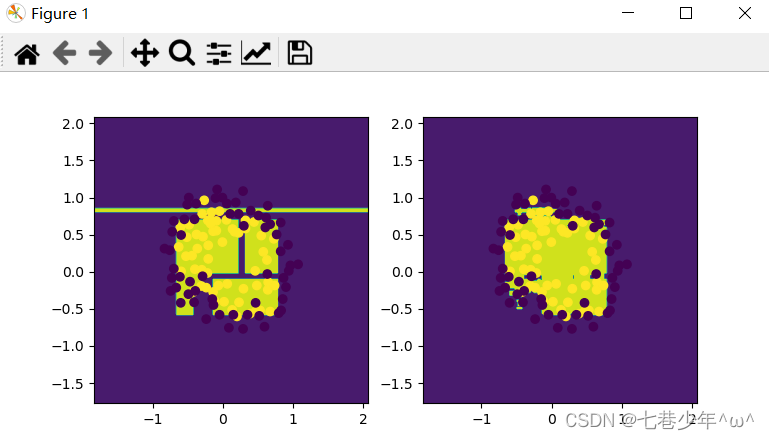
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.5)# 决策树模型
dtree = tree.DecisionTreeClassifier()
dtree.fit(x_train, y_train)
dtree_accuracy = dtree.score(x_test, y_test)
print('dtree_accuracy:', dtree_accuracy)# 随机森林
RF = RandomForestClassifier(n_estimators=50)
RF.fit(x_train, y_train)
RF_accuracy = RF.score(x_test, y_test)
print('RF_accuracy:', RF_accuracy)# 绘制决策树模型
plt.subplot(1, 2, 1)
plot(dtree)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)# 绘制随机森林模型
plt.subplot(1, 2, 2)
plot(RF)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)plt.show()5).结果展示:
- 数据展示:
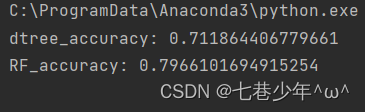
- 图像展示: