大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。
文章目录
- 前言
- 一、题目:1965. 丢失信息的雇员
- 二、解题
- 1.正确示范①
- 提交SQL
- 运行结果
- 2.正确示范②
- 提交SQL
- 运行结果
- 3.正确示范③
- 提交SQL
- 运行结果
- 4.正确示范④
- 提交SQL
- 运行结果
- 5.其他
- 总结
前言
一、题目:1965. 丢失信息的雇员
表: Employees
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| employee_id | int |
| name | varchar |
+-------------+---------+
employee_id 是这个表的主键。
每一行表示雇员的id 和他的姓名。表: Salaries
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| employee_id | int |
| salary | int |
+-------------+---------+
employee_id is 这个表的主键。
每一行表示雇员的id 和他的薪水。写出一个查询语句,找到所有 丢失信息 的雇员id。当满足下面一个条件时,就被认为是雇员的信息丢失:
雇员的 姓名 丢失了,或者
雇员的 薪水信息 丢失了,或者
返回这些雇员的id employee_id , 从小到大排序 。
查询结果格式如下面的例子所示。
输入:
Employees table:
+-------------+----------+
| employee_id | name |
+-------------+----------+
| 2 | Crew |
| 4 | Haven |
| 5 | Kristian |
+-------------+----------+
Salaries table:
+-------------+--------+
| employee_id | salary |
+-------------+--------+
| 5 | 76071 |
| 1 | 22517 |
| 4 | 63539 |
+-------------+--------+
输出:
+-------------+
| employee_id |
+-------------+
| 1 |
| 2 |
+-------------+解释:
雇员1,2,4,5 都工作在这个公司。
1号雇员的姓名丢失了。
2号雇员的薪水信息丢失了。
二、解题
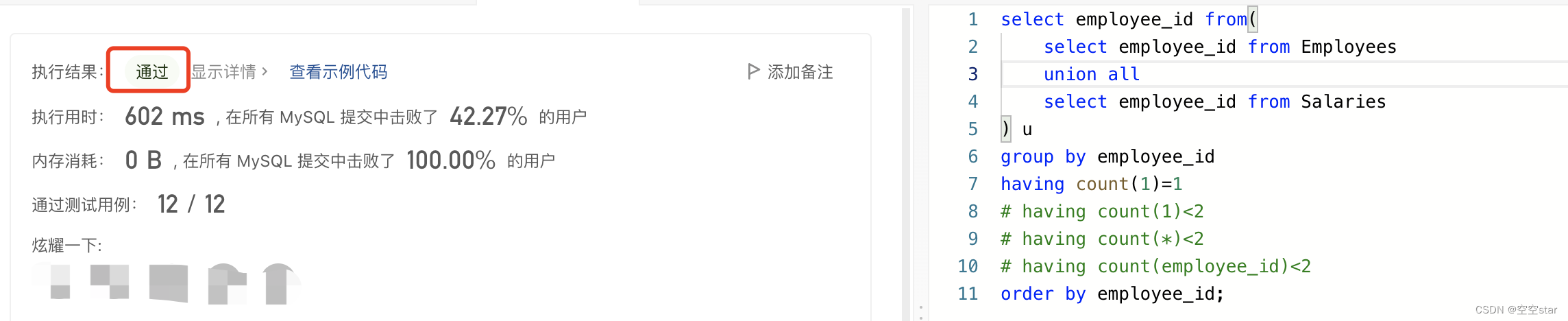
1.正确示范①
提交SQL
这里只能用
union all
select employee_id from(select employee_id from Employeesunion all select employee_id from Salaries
) u
group by employee_id
having count(1)=1
# having count(1)<2
# having count(*)<2
# having count(employee_id)<2
order by employee_id;
运行结果
2.正确示范②
提交SQL
这里
union或者union all都可以
select employee_id from(select employee_id from Employeesunion select employee_id from Salaries
) u
where u.employee_id not in(select u1.employee_id from Employees u1join Salaries u2 on u1.employee_id=u2.employee_id
)
order by u.employee_id;
运行结果
3.正确示范③
提交SQL
这里
union或者union all都可以
select u1.employee_id
from Employees u1
left join Salaries u2
on u1.employee_id=u2.employee_id
where u2.employee_id is null
union
select u1.employee_id
from Salaries u1
left join Employees u2
on u1.employee_id=u2.employee_id
where u2.employee_id is null
order by employee_id;
运行结果

4.正确示范④
提交SQL
这里
union或者union all都可以
select employee_id from Employees u1
where not exists (select 1 from Salaries u2 where u1.employee_id=u2.employee_id
)
union
select employee_id from Salaries u1
where not exists (select 1 from Employees u2 where u1.employee_id=u2.employee_id
)
order by employee_id;
运行结果

5.其他
总结
正确示范①思路:
通过union all将雇员表和工资表的雇员id整合起来,
通过group by employee_id按照雇员id分组,
筛选出出现次数小于2或者等于1的having count(1)<2、having count(*)<2、having count(employee_id)<2都可以,
最后通过order by employee_id按照雇员id升序;
正确示范②思路:
通过union或者union all将雇员表和工资表的雇员id整合起来,
限定雇员idnot in雇员表和工资表join后的雇员id,
最后通过order by employee_id按照雇员id升序;
正确示范③思路:
通过雇员表left join工资表,限定工资表的employee_id is null,
通过工资表left join雇员表,限定雇员表的employee_id is null,
将以上两个查询union或者union all起来,
最后通过order by employee_id按照雇员id升序;
正确示范④思路:
通过not exists找出雇员表有工资表没有的雇员id,
通过not exists找出工资表有雇员表没有的雇员id,
将以上两个查询union或者union all起来,
最后通过order by employee_id按照雇员id升序。