今天和大家分享一篇关于 Kafka 和 RabbitMQ 对比的论文,该论文是诺基亚贝尔实验室(Nokia Bell Labs)发表的工业界论文,系统阐述了二者的区别,可以帮助大家在发布订阅系统选型上提供帮助。文中很多引用,也是很好的扩展点,推荐大家阅读。
译文中会忽略某些不好翻译的上下文内容,并且翻译难免会有失原文精髓,还是推荐大家阅读原文
论文标题:
Industry Paper: Kafka versus RabbitMQ
A comparative study of two industry reference publish/subscribe implementations
Authors: Philippe Dobbelaere & Kyumars Sheykh Esmaili
https://www.researchgate.net/publication/317420540_Kafka_versus_RabbitMQ_A_comparative_study_of_two_industry_reference_publishsubscribe_implementations_Industry_Paper
注:该论文发表于2017年,有些概念可能和现有版本不一致。
摘要 (ABSTRACT)
发布订阅(pub/sub)模式是一种广泛采用的分布式交互范式,用以部署可扩展、低耦合系统。
Kafka 和 RabbitMQ 是应用最广的开源发布订阅系统。业务中二个常见的问题是二者的区别是什么、以及项目中应该用哪一个?
这篇paper中,我们将通过对比发布订阅系统的核心功能来建立起一个论证框架,用来全面论证二个系统的不同。以这个论证框架为基础,我们将定量定性的对比二个系统的常见功能。同时,我们还会阐述二个系统的不同点,并列举出二个系统常见的使用场景,读者可以根据自己的需求选择合适的系统。
1. 简介 (INTRODUCTION)
虽然 Apache Kafka [1] 和 RabbitMQ [4] 都是发布订阅系统,但是他们历史上的设计理念是不同的,并且拥有不同的功能。例如,二者的架构模型不同:
-
RabbitMQ 中,生产者生产消息到交换机(Exchanges), 交换机内部会进行消息的路由转发,随后消息进入队列(Queue), 消费者可以通过推(push)或者拉(pull)的方式获取到消息。
-
Kafka 中,生产者将消息发送到不同的topic,这些消息会存储在基于磁盘的顺序日志中(disk based append log)。消费者可以通过拉(pull)的方式获取到消息,并且支持多个消费者消费同一个消息。
大家可以在网上找到很多关于Kafka和RabbitMQ的对比文章,但是我们发现这些文章都没有客观全面的去对比二个系统,例如:1)对比过于强调二者的不同、 2)有些文章已经过时、3)很难去对比二者的实验结果。
在这篇paper中,我们将会全面论证二者的不同:首先我们会在第2节中简要介绍二者的核心功能,以及他们提供的服务质量保证(quality-of-service guarantees);基于第2节的内容,我们会在第3节提供高层次的描述;第4、5节我们会定性、定量比较二个系统的常见功能;除了常见功能外,我们会在第6节列举出各自的独有功能;第7节中,我们会列举出二个系统常用的一些使用场景,同时我们会提供一个对比表,方便大家根据自己的需求来做技术选型;最后我们会在第8节总结该论文。
2. 发布订阅系统背景知识(BACKGROUND: PUB/SUB SYSTEMS)
2.1 核心功能
生产者和消费者解耦是发布订阅系统的基础功能。Eugster et al. [14] 给发布订阅系统列举了三个不同的维度特征:
1)实体解耦 Entity decoupling or Space decoupling:生产者和消费者不需要知道对方的存在,而是通过发布订阅系统作为媒介
2)时间解耦 Time decoupling: 生产者和消费者不需要在同一时间活跃,例如生产者生产完消息后可以停止活动,消费者仍然可以获取消息
3)同步解耦 Synchronization decoupling :生产者消费者不会同步阻碍各自的执行
发布订阅系统的另一个核心功能是路由逻辑 routing logic(或者说是订阅模式 subscription model),该功能决定了生产者的消息会被路由到哪一个消费者。二个常见的路由逻辑是:
-
基于topic的订阅模型(topic-based):生产者会给每个消息打一个或者多个topic标签,通过过滤逻辑来决定消息应该被哪个消费者消费。很多系统支持topic包含通配符(wildcards)
-
基于内容的订阅模型(content-based):生产者不需要打标签,所有的数据和元信息被用于过滤逻辑,消费者自己实现过滤逻辑来获得想要的消息。这种方式如果过滤逻辑复杂的话,会带来一定的性能问题
2.2服务质量保证(quality-of-service guarantees)
除了之前提到的核心功能外,还有一些其他的保证,统一称为服务质量保证(Quality-of-Service (QoS) guarantees )[9, 11, 14]。
为了简洁性,我们把QoS保证分成了5个不同的类别,分别在下面一一展开。这节内容有一个需要注意的前提:“现代的发布订阅系统都是分布式的”。分布式是一个系统可扩展性(scalability )的必要但非充分条件。分布式的特性同时会带来一系列的技术问题,使得分布式存储、索引、计算特别的脆弱[7]。
2.2.1 正确性 Correctness:
引用[28]中把正确性定义成3个主要方面:无丢失,无重复,无顺序混乱(no-loss, no-duplication, no-disorder )。为了保证这3点,发布订阅系统有以下2个保证:
-
消息投递保证(Delivery Guarantees), 分为三种:
-
at most once:最多一次(最大努力best effort),保证了无重复(no-duplication), 但是有可能造成消息丢失,优点是性能最好
-
at least once:至少一次,保证了无丢失(no-loss), 系统会保证消息不丢失,但是有可能造成消息重复以及顺序混乱(例如系统宕机后恢复的场景)
-
exactly once:精确一次,保证了无丢失(no-loss)以及 无重复(no-duplication),exactly once需要比较消耗性能的实现例如二(two-phase commit)
-
-
消息顺序保证(Ordering Guarantees), 分为三种:
-
no oredering:没有顺序保证
-
partitioned ordering:单个分区内可以顺序消费
-
global ordering:全局顺序保证,需要额外的资源来实现,性能最差
-
2.2.2 可用性 Availability:
可用性是指系统整体保证可用不宕机的能力。这里会假设系统已经是可靠系统(reliable):失败可以被检测到,并且可以触发修复动作。
2.2.3 事务 Transactions:
在消息系统(messaging system)中,事务是用来将多个消息汇聚成一个原子单元(atomic units): 单元内的消息必须满足原子性,即全部失败或者全部发送/接收成功。例如,生产者生产了一系列具有上下文语义相关性的消息,生产者不想让消费者看到其中一部分的数据,因为从语义上部分数据是不一致的。
2.2.4 可扩展性 Scalability
可扩展性是指系统可以持续进化,从而支持任务量增加的场景。在发布订阅系统里,可扩展性有多个维度去衡量,例如 消费者/生产者、topics、消息。
2.2.5 效率 Efficiency
效率通常可以用二个指标来衡量:
-
延迟时间(latency or response time): 在传输架构中(transport architecture)消息的延迟时间是消息所要经过的中间流程决定的
-
吞吐量(throughput or bandwidth): 吞吐量是根据单位时间在生产者和消费者之间可以传输的数据包(packets or bytes) 大小来衡量的。与延迟时间对比,吞吐量可以通过增加额外资源来横向扩展。
对于单一流程,延迟时间latency和吞吐量throughput是成反比的.
需要重点说明的是,效率(Efficiency)和可扩展性(Scalability)通常和其他质量保证是冲突的[14]。例如,复杂的订阅模式(highly expressive and selective subscriptions)需要复杂以及性能消耗大的过滤和路由逻辑,因此限制了系统的扩展性(Scalability)。同样,强的可用性(Availability)和消息投递保证(Delivery Guarantees) 需要很大的额外开销,因为消息的确认和复制(Replication)成本会随着增加,而且丢失的消息必须有机制去检测到并且重新发送。
2.3 实现(Realizations)
很多的框架或者库都可以被归类为具有发布订阅消息功能。一种归类的方法是将其放到一个轻量级功能少的系统里,然后再将其放入复杂功能多的系统里来评估。
轻量级系统里,我们有ZeroMQ, Finagle, Kafka等。重量级的有 Java Message Service(JMS)的实现例如ActiveMQ, JBOSS Message, Glassfish等。AMQP 0.9是一个流行的标准化的发布订阅协议,它有很多实现,例如RabbitMQ, Qpid, HornetQ等。更加复杂以及功能丰富的场景是包含了发布订阅的分布式RPC框架,例如 Mule ESB, Apache ServiceMix, JBossESB等。
3 高层次描述(HIGH-LEVEL DESCRIPTION )
这节中,我们会简要的描述Kafka和 RabbitMQ系统。包括其创建的历史原因,它们的设计理念,以及它们的一些实现和优化细节。这些方面会帮助我们进一步了解它们,从而更好的去诠释它们的不同。
3.1 Apache Kafka
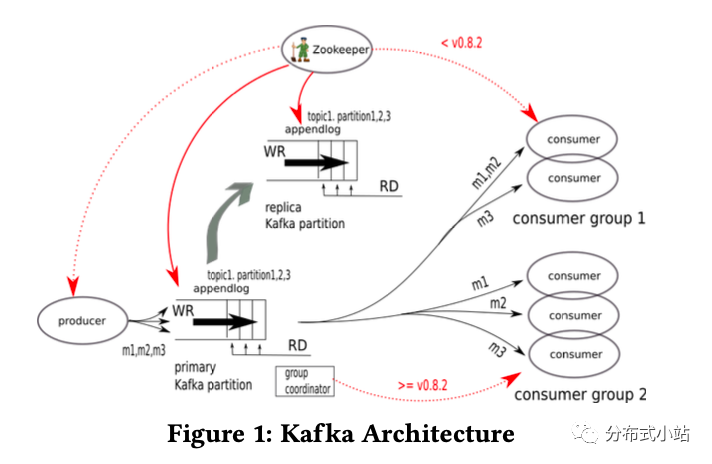
Kafka最初是LinkedIn公司创建的,作为其集中式的事件传输平台(centralized event pipelining platform),这个平台是用来替换一个点对点(point-to-point)的集成系统[17]。
Kafka 设计用于高吞吐量场景(百万级别的消息)[17]。这样的系统里需要注意的点是,在多个消费者消费同一消息流时候会有不同的消费速度(例如批处理和流处理streaming vs batch)。
Kafka最终被设计成一个围绕分布式commit log[32]的可扩展的发布订阅消息系统。其高的吞吐量是相比于其他日志聚合系统(log aggregation systems)的一个优势[17]。数据被写入到log files, 随后才会被写入磁盘,这样的设计带来了非常高效的 I/O模型【译注:kafka的这2个设置是用来定义写入磁盘时机的 log.flush.interval.messages、log.flush.interval.ms, 同时通过replication来保证数据的可靠性】。
图片1是Kafka的架构图。生产者发送消息给Kafka的topic,topic被分散在不同的kafka集群brokers中, 每个broker有可能持有该topic的分片(也有可能没有,比如broker的数量大于partition的数量)。每个partition都是有序的WAL Log(write-ahead log)用来记录消息并且持久化到磁盘上。所有的topic都可以被任意数量的消费者读取到,随着消费者的增加,性能消耗增长很小。
和传统的发布订阅系统相比,kafka中消费者被定义为"消费组"(a group of co-operating processes running as a cluster)。topic中的每个消息都会被投递到到每一个消费组中。根据这个定义,一个partition就成为了topic并发以及消费者消费并发的并发单元(unit of parallelism,译注:相当于想提高并发就得增加partition数量)。并且因为每个parition在一个消费组里都有唯一的消费者,所以消费过程可以延迟记录消费的位置(对比每个消息都去标记),从而提高性能。如果进程在记录位置之前死掉了,它只需要重新消费一小段的消息就好(前提是在at-least-once的投递保证下)。
最后,早期的kafka对于zookeeper的依赖很重[18], 用以实现它的控制面(control plane)请求逻辑,但是对于zk的依赖在kafka的迭代过程中逐步的在减少。大概在0.8.2版本,消费者的管理已经完全不依赖zk了,转而使用了内部的一个协调者。但是其他模块依然依赖zk,例如controller和cluster的管理,topic和partition的管理,数据replication的同步以及静态配置项的管理例如quotas和ACLs。
总结一下,为了满足高吞吐量,kafka和经典的消息系统有以下一些不同点:
-
kafka将数据做了分片,从而使得可以通过增加机器数量来提高生产者、消费者、broker的吞吐量。kafka保证消息在单个分片内是有序的,但是不同的分片不保证消息顺序。
-
消息不是从log里面pop出来的【pop:例如数组pop元素,该元素在原数组就不存在了】,而是可以被重复消费的。
-
消费者的状态是由消费者自己控制的,意味着消息的删除只能人为设置策略,例如根据基于时间或者基于大小来删除消息【log.retention.hours、log.retention.bytes】。
kafka同时也做了以下的优化技巧:
-
基于批量处理的方式,吞吐量得到了大幅提高,有些场景下有50倍的提高[17]。
-
利用持久化数据结构以及操作系统的页面缓存(OS page cache)。操作系统的预读策略来优化消费者的线性读 【预读就是提前将一个比较大的磁盘块中内容读入内存】。当一个消息写入log的时候写缓冲 write buffer 天然的创造了这个缓存,并且大多数消费者都不会落后消息很多,所以缓存的命中率是非常高的,这种场景下用到磁盘I/O会非常的少,减少性能开销。
3.2 RabbitMQ
RabbitMQ 是基于 Advanced Message Queuing Protocol (AMQP)的一个实现,具备高效、可扩展特性。因此,后面我们会先简单介绍AMQP,然后再解释RabbitMQ 基于AMQP的实现和扩展。
3.2.1 AMQP

AMQP协议最开始是为了支持不同的异步消息中间件交互而诞生的 (interoperability of different asynchronous messaging middlewares)【可以参考维基上关于AMQP和Interoperability的定义】。同步消息(e.g., IIOP, RMI, SOAP)有很多中间件标准,但是异步消息却没有,很多公司有自己的非开源的异步消息协议(e.g. IBM Websphere MQ and Microsoft Message Queuing)[31]。JAVA Message Service (JMS)被认为是异步消息里面最为熟知的标准,但是它仅仅是一个接口实现,没有详细的标准协议。而且JMS只能用于JAVA。
AMQP 2003年起源于摩根大通银行(JPMorgan Chase)。最早的AMQP实现是摩根大通和红帽(Red Hat)一起合作创建的Apache Qpid。而RabbitMQ是Erlang语言写的,由Rabbit Technologies公司创建。
AMQP最开始是用于金融圈,有着严格的性能、扩展性和可靠性。但是他的使用场景逐步走出了金融圈应用于各种不同场景中。
如图2所示,AMQP选择了一个模块化的方式,把消息代理(message broker)分成了交换机(Exchanges)和消息队列(message queues)[31]:
-
交换机(Exchanges)主要负责路由,从业务侧接受消息,根据一些规则把消息路由到相对应的消息队列(message queues)。
-
消息队列(message queues)存储消息,并且把消息发送给消费者(consumers)。消息的持久化方式取决于消息队列(message queues)的实现,例如消息队列一般将消息存储到磁盘上,而队列(queues)可能将消息存储在内存中。
AMQP中通过Bindings将Exchange与Message Queue关联起来,这样AMQP就知道如何正确地将消息路由到指定的Queue了。
在AMQP的一个TCP连接中,channels用来隔离消息。在多线程的环境下,每一个线程都有一个自己的channel。
3.2.2 RabbitMQ对于AMQP的实现和扩展。
RabbitMQ 对于AMQP做了以下扩展:对于生产者RabbitMQ有效率更高的确认机制、更好的事务的支持、更好的异步批量支持、对于生产和消费消息的流量控制(flow control)。更详细的一些扩展,可以参考[2]。
RabbitMQ是用Erlang实现的,所以它使用Actor模型(Actor Model)来通信。得益于Erlang的Open Telecom Platform(OTP) 架构,RabbitMQ在高可用架构的创建和管理方面有着独有的优势。Erlang以及Actor模型是RabbitMQ在多topic、多queque场景下实现可扩展性的主要原因,并且用很小的开销就实现了集群能力。
和kafka对比,RabbitMQ更贴近于传统的消息系统。例如RabbitMQ有以下几个特征:1)负责处理了大部分的消费管理, 2) 主要设计思想是在主存中处理消息, 3)队列的逻辑被优化成“接近空的队列”的时候性能最好,所以如果允许消息积压,性能会大幅度下降[5]【译注:空队列message直接从队列进入消费者,如果有积压,会有额外的入列出列操作,内存和cpu的负载都会增加】。
4. 通用特性:定性分析(COMMON FEATURES: QUALITATIVE COMPARISON)
这节我们会定性的去比较kafka v0.10 和RabbitMQ v3.5 的一些通用的发布订阅功能。
4.1 时间解耦 Time decoupling
Kafka和RabbitMQ 都可以将消息存储起来延迟消费,或者说可以控制消费速度远低于生产者的速度。
RabbitMQ可以将消息存储在内存中,但是一旦内存容量不足后,RabbitMQ会将消息转移至磁盘,转移磁盘后消息会从内存总消失,因此会严重影响性能。
Kafka则被设计成可以适应于各种不同的消费速度,因此更适合做时间接偶。
4.2 路由逻辑 Routing Logic
RabbitMQ继承了AMQP的路由逻辑,因此相比kafka可以处理更复杂的路由逻辑。RabbitMQ已经提供了很多不同的exchange类型:1)topic类型,基于topic的exchange,支持多个“a.b.c"基于topic的路由,并且支持通配符;2)header 类型,根据内容的路由【还有Direct和Fanout类型的exchange】。
路由规则可以自己去定义,因为 RabbitMQ支持通过API来创建额外的exchange。例如,RabbitMQ社区提供了额外的exchange定义,最重要的是支持负载均衡[3, 27]。
RabbitMQ同时支持一个候补exchange(Alternate Exchange), 如果一个消息不能被路由(没有被路由可能是exchange没有绑定queue或者没有命中绑定规则),则可以进入这个候补的exchange。
4.3 投递保证 Delivery Guarantees
RabbitMQ和kafka在至少一次(at least once)的投递规则上不同。批量消息中的可能会有个别包的投递失败,所以从这个失败的情况下恢复可能会造成顺序问题。有些业务场景下可能对顺序保证要求很高,所以我们把至少一次(at least once)划分成:
(1)没有顺序保证的at least once:kafka在将消息发送给多个partition的时候不会保证顺序
(2)有顺序保证的at least once:RabbitMQ在将messages写入queue的时候会将messages排序,意味着之前丢失的消息可以按照顺序投递从而不需要将整个批次的messages全部重新发送。kafka在一定条件下会保证顺序,参考4.4节。
标准的AMQP 0.9.1协议中,确保消息不丢失的唯一方法是使用事务,但是这样的性能很差会严重影响吞吐量。为了改进这一点,RabbitMQ使用了一种确认机制(模仿了AMQP中的消费者确认机制)。
确保一个消息被投递包含了消息系统整个架构中各个不同组件的“所有权转移”(ownership transfer)的概念。一个保证不是绝对的:我们定义一个失败的可能性,定义单个组件的失败率 λ,以及一个完整的消息转移链。失败的可能性和概率可以通过增加副本(replication)的方式降低。

现在开始,我们假设生产者和消费者的失败率都是 0,即λ=0.
RabbitMQ和Kafka会在以下几个方面有着不同:生产者的确认、消费者的交互、以及消息的删除。
-
图3中的t1是生产者拥有一个消息,这个消息即将被发送给RabbitMQ/Kafka。
-
图3中的 t2 是二个系统处理消息的逻辑:
-
对于RabbitMQ的broker返回确认信息给producer的时间有:1)如果一个消息不可以被路,broker会在exchange确认该消息不可路由后返回确认信息(ack给producer);2)如果一个消息可以被路由,broker则会在该消息被queue接收后返回确认信息;3)如果是持久化的message,则会在消息被路由到持久化的queue(durable queue)后返回;4)对于镜像队列,则会在所有镜像都接收消息后返回。
-
Kafka则将消息追加到broker的主节点的append log上,有时候可能也需要从节点的确认(取决于消息确认机制的配置)。
-
-
t3 是broker给生产者发送的消息确认信息,消息的所有权现在转移到了RabbitMQ/Kafka,所以生产者可以将该消息删除了。
-
t4 是消费者从RabbitMQ/Kafka获得消息。
-
t5 :
-
RabbitMQ:消费者发送确认信息给broker A, 消息的所有权现在转移到了消费者端,broker可以将该消息删除。注意如果多个消费者订阅该消息,broker则会等待所有的消费者都确认后才删除消息。
-
Kafka:Kafka不会保留消费者消费状态,所以Kafka是不知道消息是否被已经消费了。因此kafka的broker会一直保留消息直到所配置的时间超期。
-
RabbitMQ在AMQP的基础上提供了批量发送消息的机制,并且只需要一次消息回复(ACK/NACK),这意味着这一批消息都已经安全的写入到磁盘上了。
Kafka的消息确认行为可以通过request.required.acks来配置,0代表生产者不需要等待broker的确认(best effort),1代表主broker已经接收到了但是没有写入到磁盘,-1代表大多数(quorum)的确认但是没有写入到磁盘(一般不会有丢失问题,除非所有的副本都在同一个机器上,并且这个时候机器宕机)。
没有副本(replication)的情况下,Kafka默认配置下是不需要等待消息确认的,除非刷盘行为发生(fsync),因此消息可能丢失。这个行为可以通过更改配置文件来改变,但是会牺牲一定的吞吐量。
4.4 顺序保证 Order Guarantees
RabbitMQ会在一个AMQP的channel里保存顺序。RabbitMQ会在队列逻辑里面再次排序重新传送的数据包,因此消费者不需要自己重新给数据排序。因此如果在我们在RabbitMQ前面放一个负载均衡的话,数据包离开负载均衡后进入不同的channel内将不会再有顺序关系。
Kafka是在分区(partition)里面维护顺序。而且在同一个分区里,Kafka会保证批量消息的原子性(同时成功或者一起失败)。然而,为了保证批量消息的顺序,生产者必须保证生产请求的并发只最多只有1个,但是这样会影响最大吞吐量。
4.5 可用性 Availability
RabbitMQ和Kafka的可用性都是通过备份Replication来保证的。
RabbitMQ集群可以配置成备份所有的exchange和binding信息。但是,它不会自动创建镜像队列(队列的备份),需要手动的去设置。
Kafka的可用性需要一个合适的备份数(replication factor)。
根据CAP理论[16],在任何备份的架构下,都可能出现因为网络分区造成的脑裂问题。如果想了解RabbitMQ和Kafka的可用性模型,可以参考Jepsen的系列文章[19, 20]。
4.6 事务 Transactions
AMQP的事务只有在发布和确认(publishes and acks)时刻才有。RabbitMQ额外的提供了拒绝事务。在消费端,消息的确认是事务的,而不是在消费消息本身。AMQP只有在单一队列下保证事务的原子性。RabbitMQ在单一队列下不保证事务的原子性,例如事务提交的时候发生错误,会导致broker重启后一部分事务提交出现在队列里。注意这里的事务不是严格意义上的ACID事务,因为这里需要和生产者、消费者有一定的交互。例如当生产者发送批量消息,如果任意一个消息失败,生产者都会重新发送这一批消息,RabbitMQ会将他们按照顺序插入到队列里,之后生产者会被告知之前失败的消息投递成功了,我们会认为这个事务成功的执行了。
Kafka目前不支持事务。但是已经有一个关于事务的提案了,可能未来会支持。
4.7 多播 Multicast
业务上经常会给多个目标发送同样的信息。
RabbitMQ支持多播(Multicast)是通过给每一个消费者提供一个专用队列实现的。提供一个专用队列对于整个系统影响只有增加了bindings的数量。RabbitMQ维护了消费者对于消息的所有权的信息,因此可以决定是否可以将消息从从RabbitMQ内删除。在扇出(fan-out)情况下,RabbitMQ维护了每个队列的索引和原信息【索引是为了知道一个消息在队列里面的位置,以及这个消息是否被投递和确认】,但是一个消息在多个队列里共享一个消息体【而不是每个队列都有一个同样的消息】。
Kafka中,在非备份模式下,一个消息在一个topic下也只有一个copy;然而多播(Multicast)逻辑是在消费端配置的。每个消费者都可以从Kafka中获取消息。Kafka自己不知道一个消息是不是已经被所有消费者消费,Kafka只会根据设置来保存消息的存留时间【log.retention.hours、log.retention.bytes】。
4.8 动态扩展 Dynamic Scaling
RabbitMQ对于增加节点或者从集群内删除节点支持的很好。新加的节点可以成为新创建队列的master,也可以接受channels用以发布到exchange或者从任意的queue里消费,但是不能被用来对已经存在的队列进行重新分散master队列的分配(除非人为干预)。RabbitMQ里增加新的节点对于消费者是透明的,消费者仍然优先从master队列消费,虽然从其他的节点消费也是可以的,但是会牺牲内网负载因为数据包是存放在master队列【应该是指其他节点需要访问master队列来获取消息体本身从而增加了内网负载】。
Kafka中增加一个新的节点,用户可以选择将现有的partition移动到新节点。这种场景下,会在新的节点里新建一个备份replica,当这个备份跟上了最新的数据后,老的备份就会被删除掉。这个过程可以在线上不中断服务进行。Kafka中增加节点对消费者是不透明的,因为消费者和partition之间需要有一个 mapping 关系。移除一个节点是通过把待删除节点上的partitions重新分配到其他节点上来进行的。
5. 通用特性:量化分析 COMMON FEATURES: QUANTITATIVE COMPARISON
这节我们会用实验方法来量化分析RabbitMQ 和 Kafka的效率/性能。多数的结论都是通过我们自己的实验结果得出来的。对于一些不太好搭建的场景,我们会列出其他作者的实验结果来作为参考。
之前2.2.5节描述过,效率主要通过延迟时间和吞吐量来衡量。因此,这节内容会有:5.1节会讨论延迟时间结果, 5.2节会讨论吞吐量结果。
除了系统和效率的衡量,我们同时会引入其他二个非常重要的维度:1)投递保证,例如 最多一次 和 最少一次的对比;2)可用性,例如有备份的queue和没有备份的queue。
实验设置。我们的实验跑在一台24核的Linux服务器 (Intel Xeon X5660 @ 2.80GHz) , 12GB内存,3.11的内核。磁盘是WD1003FBYX-01Y7B0, 7200转速。注意,虽然多台机器可以增加磁盘带宽,但是同时引入了网络层的影响,这样会让实验结果难以定义。
RabbitMQ版本是3.5.3, Kafka的版本是0.10.0.1。所有的Kafka的设置项都是默认的。最近的一个白皮书指出,Kafka的默认设置会倾向于延迟时间而不是吞吐量(默认的配置里面linger.ms是0,意味着生产者会立即将数据发送出去而不是等待一定时间发送batch消息)。
所有的测试都会跑60秒,结果实在实验开始后30s收集。所有的数据包配制成发送最大负载。测试工具的源代码里面提供了足够的文档来设置这些参数。
一旦需要多个broker,这些broker都会在同一台机器上启动,有效的避免了网络延迟的影响。
除了延迟时间和带宽的结果外,我们同时监控了核心利用率以及内存的消耗量(RabbitMQ没有超过13.4%, Kafka没有超过29.5%)。
最后,所有的测试中,误差都不超过10%,所以没有在结论中体现。
5.1 延迟时间结果 Latency Results
我们先介绍最多一次的模型结果,因为他的延迟时间最低。然后我们分析最少一次的模型结果,来对比引入更强的投递保证后带来的性能消耗。
5.1.1 最多一次模式下的延迟时间 Latency in At Most Once Mode.
对于RabbitMQ, 处理数据包的串行流程主要由一个Erlang进程用来终止生产者和broker间的协议,第二个Erlang进程保存queue的状态,第三个Erlang进程将数据从queue转移到消费者。如果允许消息确认并行,即有一个滑动窗口来代表进行中的还未确认的消息,这种情况下RabbitMQ的延迟结果是最优的(我们实验的滑动窗口大小为10)。
对于kafka,处理数据包的串行流程是由存储的延时时间决定的。就像3.1节描述的, Kafka使用了操作系统的page cache,所以当读请求在写请求后立即发生的话,数据包仍在缓存中的概率很大。
RabbitMQ 和 Kafka的延迟时间结果展示在在Table 1中。我们的数据结果和[29]中的实验结果大体上一致。

从Table 1中,我们可以得出2个重要的结论:1)二个系统都提供了毫秒级别投递保证。Kafka的结果看上去要好一点,然而我们的Kafka是在一个理想的配置下(缓存的miss率是0)测试的,在现实情况下,RabbitMQ的表现要好一些。2)备份replication没有给结果造成很大的影响。对于RabbitMQ来说,结果几乎一致。对Kafka来说,备份只影响了中间值之后的结果,99.9分位时间增长了一倍。
Table 1中的结果是在比较理想的情况下进行的。下面我们会讨论在其它情况下的结果。
当RabbitMQ在接近于满负载情况下时,broker会将消息从内存中写入磁盘,从而释放内存,这意味着实验结果会大幅度变坏。
Kafka,当消费者比生产者要慢的时候,读请求的时候,数据不得不先从磁盘加载到内存。即使Kafka的磁盘读写是一个线性顺序的,延迟时间也会很大的升高,因为对于慢消费者消费变慢,以及快速消费者的缓存会消失导致。这项结果显示在[8]中的实验报告中,它显示当缓存未命中的比例为30%时(即30%的消息需要从磁盘加载),延迟时间增长了不止1个数量级。
另一个影响Kafka延迟时间的是Kafka跑在JVM上,大量的消息会导致垃圾回收暂停(因为Kafka会分配大块存储空间)。这些在延迟时间结果分布上会表现成异常值(outliers)。这种情况同时会影响控制面,因为对于大量的数据,为了防止Kafka连接zookeeper超时,zookeeper上配置的session超时时间 (zookeeper.session.timeout.ms) 响应的需要增加。
5.1.2 最少一次模式下的超时时间 Latency in At Least Once Mode.
RabbitMQ的超时时间在最少一次模式没有太增长,因为数据虽然被写入到了磁盘,但是内存中同时也存在,因此不会影响数据的消费速度。
对于Kafka在最少一次模式,延迟时间有所增加,因为Kafka在该模式下,消息需要通过大多数(quorum)的备份节点确认。
总结一下:
- 对于RabbitMQ,中间值的延迟时间在最少一次和最多一次情况下都在10ms以下。
-
对于Kafka,如果可以从操作系统的page cache中读取,那么它的延迟时间在最多一次情况下也是小于10ms,最少一次情况下会增加一倍。然后,当它从磁盘读取的时候,延迟时间可以增长一个数量级达到100ms。
5.2 吞吐量结果 Throughput Results
RabbitMQ的并发是由Erlang的actor模型的多线程实现的的,因此跨node的并发可以通过独立的node间进行流量分区,或者一个集群里面进行流量分发。Kafka在一个node里的并发也是多线程。Kafka跨node的并发是由分区实现的,参考3.1节。我们的性能测试只考虑了单一节点,所以当考虑到实际多节点情况是,需要根据情况调整实验结果。
5.2.1 最多一次模型下的吞吐量 Throughput in At Most Once Mode
对于RabittMQ,吞吐量最优的情况是配置不限制没有确认消息的数量即confirm == -1。

图4a展示了RabbitMQ单一node节点下消息数量(以大小bytes为单位)对于吞吐量的影响。图中pps代表了每秒传输的数据包。吞吐量随着数据包的增加而降低(除了包交换成本不依赖于数据大小外,包拷贝操作随着数据增加而线性增长)。不限制进行中的未确认的消息提高了吞吐量。备份降低了吞吐量。
如[23]中的报告,在Google Cimpute Engine下设置一个32个节点的集群,使用186个队列,1.3万个消费者和生产者,以及集群前面搭建一个负载均衡的情况下,RabbitMQ可以稳定的处理130万的pps(每秒传输的数据包)。
对于Kafka的吞吐量,有三个重要的因素:
- 消息的数量
-
topic的数量
-
分区的数量
我们做了不同的实验来验证这3个因素的影响。结果描述如下。
图4b显示了消息数量对于吞吐量的影响。吞吐量曲线和RabbitMQ的曲线形状基本一致。当我们把吞吐量以一定单位时间来展示的时候,我们发现吞吐量几乎和消息数量成线性关系:包拷贝在Kafka中占主要的操作。
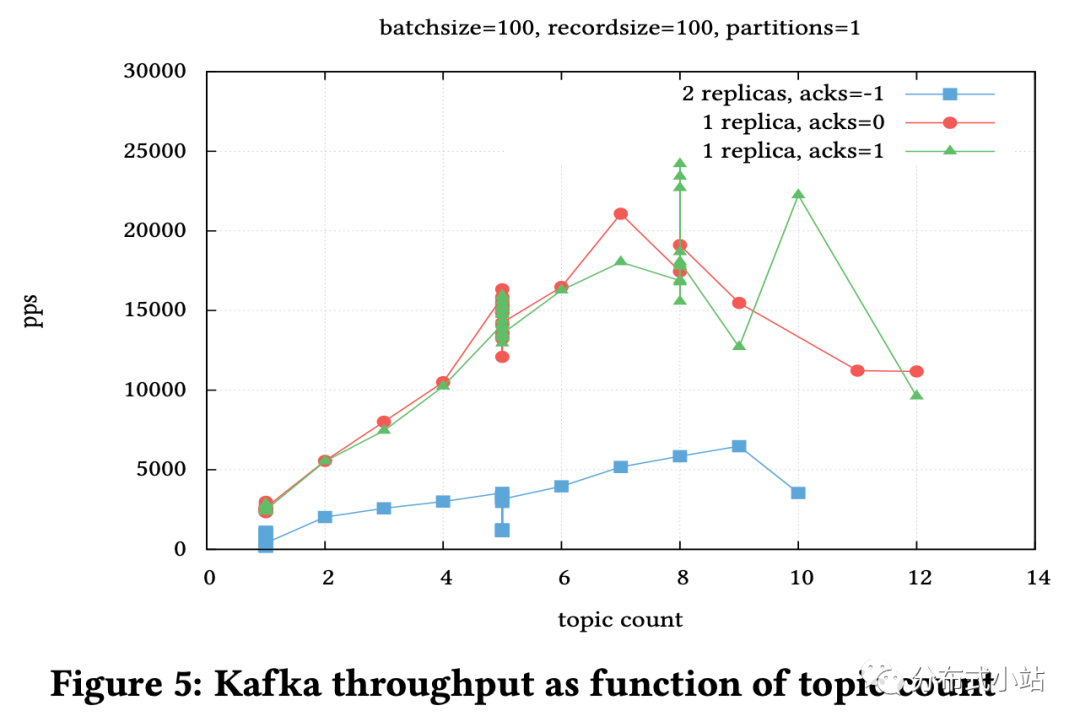
图5展示了topic的数量对于吞吐量的影响。这里的所有topic都是有效的,并且每个topic有自己的生产者。这个图显示结果为线性结果,但是topic/生产者的线性度 在大概8个生产者的时候有一个限制。机器在这个峰值下的利用率为:Kafka 3.25个核,所有生产者10个核,所有消费者4个核以及6个空闲核心。当topic再增加时,性能就开始下降了。
Kafka直到v0.8.2的时候一直不是被设计用以处理大量topic的场景(受限于zookeeper,大约可以处理1000个topic), 可参考[13]中的测试结果。这些测试结果有2方面的不同:利用分区来最大化吞吐量,但是不是每个topic都被用以测试。结果显示topic数量在100到1000之间的时候吞吐量有一个大的下降。注意他们的实验和我们的实验都来自于[13],设置大量的topic或者大量的分区(小几百个)会导控制面逻辑的频繁崩溃。

在[33]中,Wyngaard报告了一个NASA JPL的大消息体(10MB)的实验结果。在3个生产者, 3个消费者,1个topic,单一Kafka实例的情况下,吞吐量达到了6.49 Gbps(大概8000个消息)。增加生产者或者增加Kafka节点都降低了整体的吞吐量。
实验发现当分区数量超过一定值的时候吞吐量不再增加,这可能是因为生产者定义的批量大小是根据分区数量来划分的。
5.2.2 最少一次模型下的吞吐量 Throughput in At Least Once Mode
对于RabbitMQ,最少一次模型意味着消息会被写入磁盘。只要内存里的缓存还存在,读请求还是会从内存里读取。
AMQP支持批量生产,批量消息内RabbitMQ允许单个消息的确认ACK/NACK。同时支持消息写入队列时的排序,这确保了生产者可以传递多个批量的插入而不需要等待消息的确认。
镜像队列会影响吞吐量,因为ACK确认需要备份队列的确认。
参考图4a,相比最多一次模型,最少一次模型下RabbitMQ吞吐量降低了50%。
对于Kafka,分析起来会更加复杂。Kafka假设数据包是批量写入的,并且始终会写入磁盘。最多一次模型下,Kafka定义了一个window代表发出去的正在同步到磁盘的消息(log.flush.interval.messages and log.flush.interval.ms)。这意味着一旦系统宕机,window内的消息将会丢失。
Kafka保证消息可靠投递的唯一的方式是只有当消息被写入磁盘后才返回确认信息,或者被大多数的副本(quorum)接受后才返回确认信息。这极大的降低了生产者的效率,因为生产者需要等待批量消息的确认后才能发送下一批的数据,这在RabbitMQ里面是不存在的因为RabbitMQ的确认机制以及重排序逻辑。如果Kafka跑在冗余node节点下,客户端需要等待大多数节点确认的时间会更长。我们的实验显示,在topic为5,批量大小为100,分区为5,副本从3个增加到4个的时候,性能会有下降。[22]中的实验显示结果类似。最后[21]的结果显示,备份数量的对于性能的影响只体现在需要所有节点确认的情况。对于一个2个副本的系统,对于大的批量消息,性能下降到一半,对于单条消息性能下降到1/3。
所以对Kafka来说,和最多一次模型相比,最少一次模型吞吐量下降了50%-75%。
分析和总结。
影响RabbitMQ 和 Kafka吞吐量的因素很多。为了简化分析以及总结结果,我们利用了曲线拟合方式:我们依据入参以及重要的架构实现细节,定义了一个高阶函数来模拟吞吐量特性。然后每一个case我们都最小化函数的返回值和经验数据的误差。

结果方程和相应的拟合值描述在表2和表3中。注意表中的 U 代表利用率((processor cycle) utilization),effective_size(kafka中)是生产者批量消息以及消息记录大小的最大值。
我们用来模拟RabbitMQ吞吐量行为的函数展示在表2中。得益于Erlang的Actor Model,每个RabbitMQ的吞吐量和生产者的数量成正比,因此生产者因素会出现在这个函数里。然而生产者因素只会线性增长到一定程度,这个是由Erlang分布它的轻量级进程到不同的核心上来决定的,我们的结果显示,pps(每秒传输的数据包packets per second)在生产者数量等于2的时候就饱和了(单个节点,单个队列的情况)。
Table 2中的b部分显示了根据图4a提供函数的拟合值。平均误差很低。[24]中的测量结果和我们的结果类似。
有几个比较重要的点:1)未完成的发布数据包(outstanding published packets)会对结果有小量影响,如果我们把数据包从10增加到100 bytes,吞吐量增加到了20Kpps;2)所有的结果都在跑在Direct Exchange上,如果使用Topic Exchange,因为其复杂的路由逻辑会导致吞吐量下降(100 byte packets吞吐量下降到了19Kpps)。
总结一下,我们可以得出结论:RabbitMQ的吞吐量主要受限于它的路由复杂程度(包的帧数小的时候,包复制的影响可以忽略),这也是为什么我们倾向于将RabbitMQ的性能用单位是的包传输来表述。
用来模拟Kafka的吞吐量函数表数描述在Table 3中。“topic” 参数代表Kafka broker上面的topic数量。值得注意的是,对于Kafka,当我们增加一个0.5次幂的时候结果最适配,原因可能是缓存未命中率的幂律(power law of cache misses)。
对于生产者 = 5, 大小 = 400, 分区 = 10, 我们预估85 Kpps。对于性能更好的处理器(更快的内存,2倍的缓存大小),[15]中结果显示140Kpps。
通过这些参数,我们可以明显看出用bytes来描述Kafka的吞吐量更合适,即使在小帧数的情况下Ubyte也占据主导地位。
最后Kafka中的错误率比RabbitMQ中要高。2个可能的因素是:1)Kafka依赖于底层操作系统级别的缓存,因此难以精确的建立好的实验模型来模拟,也可能机器上跑的其他程序影响了结果;2)Kafka跑在JVM上面,因此相比Erlang 的虚拟环境有更多的可变性[25](因为一些锁以及垃圾回收的进程而造成的影响)。
6. 特性差异 DISTINCT FEATURES
之前的章节中,我们研究了Kafka 和 RabbitMQ的通用特性。然后,这二个系统都有自己的独特特性。这些独特特性在我们选型的时候可能会是一个重要的因素。因此,这节我们会简要分析二者的特性差异。
6.1 Kafka的独特特性 Features Unique to Kafka
-
长时间的消息存储。Kafka将消息存储在磁盘上。数据的清理是通过配置自动完成的。
-
消息重放 Message Replay。鉴于Kafka本身不维护消费者的状态以及长期存储消息的特性,消费者可以轻松的重新消费消息。这个对于下游系统的容灾是一个非常有用的特性。
-
Kafka connect。Kafka connect是一个和其他系统交互的可扩展、高可靠性的流式数据框架。我们只需要简单的定义connectors即可将数据从目标系统和kafka系统做交互。
-
日志压缩 Log Compaction。Kafka可以对于有相同 Key 的不同数据, 只保留最后一条数据。这对于监控一些数据变化的场景(第七节会介绍)来说非常有用【例如监控一个用户昵称的变化,我们只对最后一个昵称感兴趣,之前的变化都是无用数据】。
Kafka生态提供了很多库以及工具用以在kafka之外提供一些额外功能。例如Kafka Streams(7.1.5节会简要介绍)。
6.2 RabbitMQ 的独特特性 Features Unique to RabbitMQ
-
标准协议。RabbitMQ本质上是对开源AMQP协议的实现。因此它有高纬度的互操作性,可以和其他的AMQP一致的实现进行交互或者替换。
-
支持多个协议。除了AMQP外,RabbitMQ支持其他的标准协议来发布消费消息,例如MQTT(IOT社区非常流行的协议)和STOMP。因此如果有多协议混用的场景,RabbitMQ是一个不错的选择
-
分布式的拓扑模型。除了集群模式外,RabbitMQ支持联邦交换器(federated exchanges),在网络情况不是很稳定的情况下对于多地区部署是一个比较好的选择。跟集群模式比较,他的联结维度更低。一个很有用的特性是,federated exchanges 具有按照要求转发的功能。通过Shovel机制,RabbitMQ可以提供另一种方便的方式来将broker和集群关联在一起。
-
丰富的管理、监控工具。RabbitMQ有一套非常简单的洁面管理,可以用来监控和管理消息broker的各个方面,包括:1)connections;2)queues;3)exchanges;4)clustering、federated以及Shovel;5)数据跟踪;6)资源消耗。总体这些都为内部系统提供了一个很好的可视性,方便做测试以及问题的调试。
-
多租户和租户间隔离(multi-tenancy and isolation)。RabbitMQ实现了AMQP定义的Virtual Hosts,用以实现用一个broker来部署多个隔离的环境(例如connections,exchanges,queues,bindings,用户权限,政策等的逻辑分组)。
-
消费者跟踪。在queue级别下,RabbitMQ维护了状态,并且知道消费者在任何时间消费了什么消息。
-
无磁盘使用。RabbitMQ不需要磁盘就可以将消息路由出去。这使得RabbitMQ在一些嵌入式的或者有限制的场景下是一个不错的选择。例如RabbitMQ可以部署在树莓派上Raspberry Pi [6]。
-
生产者消息流量控制。RabbitMQ可以让生产者停止发送消息以免在极端场景下压垮broker。这种优势可应用于不能删除消息的有流量控制的场景下应用。
-
队列大小限制。队列可以被限制大小。这种优势可应用于可删除消息的有流量控制的场景下应用。
-
消息的TTL。消息可以指定TTL“Time To Live”。如果消息超出了限制时间,则不会被投递给消费者。这在对于消息有实效性的场景下非常有用。TTL可以在队列创建的时候给整个队列设置,也可以在单个消息发布的时候给消息本身设置。
7. 优先应用场景 PREFERRED USE CASES
7.1 最适合Kafka的场景
7.1.1 消息发布订阅 Pub/Sub Messaging
Kafka的发布订阅场景在以下几个特性下是一个不错的选择:1)路由逻辑简单,Kafka的topic就可以hold住需求;2)如果每个topic的吞吐量超出了RabbitMQ可以hold住的值(例如event firehose)。
7.1.2 可扩展的数据接收系统 Scalable Ingestion System
很多领先的大数据处理平台一旦将数据载入到系统内后,都有着高的数据存处理吞吐量。但是在很多场景,将数据载入这样的系统本身就是一个瓶颈。Kafka提供了一个可扩展的姐姐方案,并且已经应用到了例如Apache Spark、Apache Flink等系统中。
7.1.3 数据层的基础架构 Data-Layer Infrastructure
Kafka的可靠性,以及多播(Multicase)特性, 使得其可以作为底层的数据基础架构用来连接各种各样的批量和流服务及应用。
7.1.4 捕捉数据变化流 Capturing Change Feeds.
变化流是一些列的更新事件,用于捕捉一个数据状态的各种变化(例如数据库的某一行的变化)。传统上,变化流被DBMSs用于数据的同步复制【例如mysql bin log】。最近,一些现代的数据存储已经对外暴露了数据的变化流,因此可以被用于在分布式的环境下同步状态。Kafka以日志为中心的设计(log-centric design),对于分布式场景下同步数据变化的应用是一个完美的选择。
7.1.5 流式处理 Stream Processing
从0.10.0.0版本开始,kafka增加了一个轻量级的流处理库 - Kafka Streams,它可以用来支持有状态的、容灾的数据处理。Apache Samza 是一个开源的基于kafka的流处理平台。
7.2 最适合RabbitMQ的场景
7.2.1消息发布订阅 Pub/Sub Messaging
RabbitMQ创建初始就是为了做发布订阅系统,因此满足了发布订阅的大多数场景。而且更适用于broker跑在特定的互联逻辑下的消息路由场景。
7.2.2 Request-Response Messaging
RabbitMQ通过correlationId和direct reply-to功能提供了很多RPC形式的交互,这使得RPC客户可以直接从RPC server接受回复,从而不需要专门设置一个回复队列。因此,RabbitMQ对于这类场景以及有强排序的场景来说是一个好的选择。
7.2.3 Operational Metrics Tracking
RabbitMQ在实时处理方面是一个好的选择,因为它的broker可以提供比较复杂的过滤逻辑。
Kafka在离线分析方面是一个好的选择,因为它会将消息长时间存储下来并且允许反复消费消息。但是每个topic的吞吐量是一个是一个重要的决定因素。
7.2.4 IoT应用平台的底层 Underlying Layer for IoT Applications Platform
RabbitMQ 可以被用来在数据流图下(dataflow graph)连接单个处理器节点,无论处理器是在哪里被创建的。这种场景下RabbitMQ作为可以提供很多功能:1)大多数的数据传输延迟5ms以内,一级单节点吞吐量可以达到40Kpps;2)优秀的内部指标可视化,以及通过可视化见面设置数据流的简易测试和调试流程;3)支持MQTT协议;4)支持复杂的路由能力,可以是包过滤逻辑由数据梳理语言实现;5)可以同时处理很多只需要小量的吞吐量(很多应用之多数据流里面的一部分数据感兴趣)的数据流。
7.2.5 信息中心网络 Information-centric Networking
Information-centric Networking是一个能智能化路由消息的架构。因此RabbitMQ在当理解路由key和目的地关联的特定exchange场景下是一个好的选择。[12]中的地理位置路由是一个好的例子。
7.3 联合使用 Combined Use
很多需求场景没有办法只使用单独的RabbitMQ或者Kafka, 因此需要二个系统同时使用。
一般有二种模式将二个系统串联起来:
-
模式一:RabbitMQ部署在Kafka上游。例如当RabbitMQ在系统架构中是一个好的选择,但是其中一些数据流需要被长时间保留的场景。先部署RabbitMQ,可以得到比较好的延迟时间保证。而且我们可以细粒度的去选择哪些数据需要被长时间存储,以便有一个更好的磁盘利用率。
-
模式二:Kafka部署在RabbitMQ上游。例如当整体系统架构吞吐量都比较大,但是每个topic的吞吐量有一定的上线可以被单独的RabbitMQ broker来处理的场景。把RabbitMQ 节点放在Kafka topic下游,可以利用RabbitMQ提供的复杂路由逻辑。
AMQP-Kafka Bridge [26] 为Kafka和RabbitMQ的交互提供了便利。
另外,Kafka和RabbitMQ也可以并行部署,用来同时处理同样的数据流。这种架构在合并2个使用不同消息队列系统的时候也以用到。
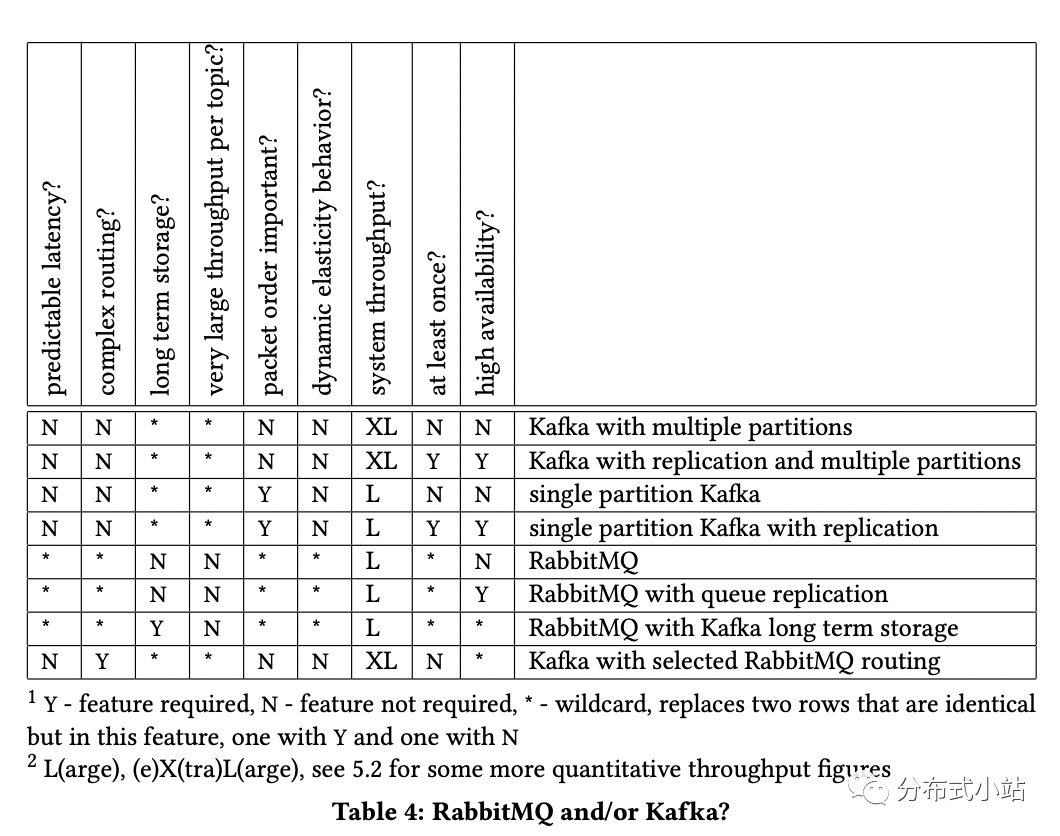
决策表。目前为止,我们讨论了二个系统的使用场景。为了让使用场景可以涵盖其他更多的场景,我们制作了一个决策表(Table 4)。表中每行都显示了一系列的功能来代表架构的选择。这个表很明显简化了很多,可参考4、5、6节中的讨论来综合决定。
8. 总结 CONCLUSION
这篇paper中我们定量定性的比较了Kafka和RabbitMQ。
延迟时间方面,二个系统都有比较低的延迟时间(例如中位数都在10ms左右)。对比最多一次(at most once)和最少一次(at least once)模式,RabbitMQ区别不大,Kafka延迟时间在最少一次模式下增长了一倍。此外,如果需要从磁盘读取数据,延迟时间最高增长了一个数量级。
吞吐量方面,在最基本的配置下(一个节点、一个生产者/channel,一个partition,没有备份),RabbitMQ的吞吐量要好于Kafka。然而,在同一个机器上如果增加Kafka的分区,则能极大的提高其吞吐量,这证明了Kafka优秀的横向扩展能力。RabbitMQ中增加生产者/channel的数量,吞吐量的提升没有Kafka增加partition明显。
二个系统都可以通过增加broker节点增加分区来进一步横向扩展。但是RabbitMQ需要额外的逻辑,比如使用一致性哈希exchange(Consistent Hash Exchange )[3],以及Sharding Exchange[27]。Kafka则是天然支持的。备份(Replication)会极大的影响二个系统的性能,性能分别降低了50%(RabbitMQ) 和 75%(Kafka)。
虽然性能效率很重要,但是在选型上面,我们强烈建议参考其他的维度来综合选型,例如第四节的定性分析以及第六节的不同的功能。[25]中的报告是一个生产环境的总结报告,也是一个很好的例子。
另外,第7节中我们讲到,不一定是2选1,也可以结合实际场景二个系统一起使用。
REFERENCES
[1] Apache Kafka. URL https://kafka.apache.org/.
[2] RabbitMQ: Protocol Extensions. URL https://www.rabbitmq.com/extensions.html.
[3] Consistent Hash Exchange, . URL https://github.com/rabbitmq/rabbitmq-consistent-hash-exchange.
[4] RabbitMQ, . URL https://www.rabbitmq.com/.
[5] Sizing your Rabbits, 2011. URL https://www.rabbitmq.com/blog/2011/09/24/sizing-your-rabbits/.
[6] T. Abarbanell. Benchmarking RabbitMQ on Raspberry Pi, 2015. URL http://blog.abarbanell.de/raspberry/2015/05/17/benchmarking-rabbitmq-on-raspberry/.
[7] S. Abiteboul, I. Manolescu, P. Rigaux, M.-C. Rousset, and P. Senellart. Web Data Management. Cambridge University Press, 2011.
[8] J. Alquiza. Load Testing Apache Kafka on AWS, 2014. URL https://grey-boundary.io/load- testing- apache- kafka- on- aws.
[9] P. Bellavista et al. Quality of Service in Wide Scale Publish-Subscribe Systems.IEEE Communications Surveys & Tutorials, 16(3):1591–1616, 2014.
[10] Y. Byzek. Optimizing Your Apache Kafka Deployment: Levers for Throughput, Latency, Durability, and Availability. Technical report, Confluent Inc, 2017. URL https://www.confluent.io/blog/optimizing-apache-kafka-deployment/.
[11] A. Corsaro et al. Quality of Service in Publish/Subscribe Middleware. Global Data Management, 19(20):1–22, 2006.
[12] P. Dobbelaere. How to Design and Deploy a World Scalable Geofence Service with Custom Exchanges in RabbitMQ, 2016. URL http://www.erlang-factory.com/brussels2016/philippe- dobbelaere.
[13] I. Downard. Kafka versus MapR Streams: Why MapR?, 2017. URL https://www.mapr.com/blog/kafka- vs- mapr- streams- why- mapr.
[14] P. T. Eugster, P. A. Felber, R. Guerraoui, and A.-M. Kermarrec. The Many Faces of Publish/Subscribe. ACM Computing Surveys (CSUR), 35(2):114–131, 2003.
[15] D. Gevorkyan. In Pursuit of Messaging Brokers, 2015. URL https://www.slideshare.net/slideshow/embed code/49881431inpursuitofmessaging.
[16] S. Gilbert and N. Lynch. Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-tolerant Web Services. Acm Sigact News, 33(2):51–59, 2002.
[17] K. Goodhope et al. Building LinkedIn’s Real-time Activity Data Pipeline. IEEE Data Eng. Bull., 35(2):33–45, 2012.
[18] P. Hunt et al. ZooKeeper: Wait-free Coordination for Internet-scale Systems. In USENIX Annual Technical Conference, volume 8, page 9, 2010.
[19] K. Kingsbury. Jepsen: Kafka, 2013. 293- jepsen- kafka. URL https://aphyr.com/posts/
[20] K. Kingsbury. Jepsen: RabbitMQ, 2014. 315- jepsen- rabbitmq. URL https://aphyr.com/posts/
[21] J. Kreps. Kafka Performance Testing, 2013. URL https://cwiki.apache.org/confluence/display/KAFKA/Performance+testing.
[22] J. Kreps. Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines), 2014. URL https://engineering.linkedin.com/kafka/benchmarking- apache-kafka-2-million-writes-second-three-cheap-machines.
[23] J. Kuch. RabbitMQ Hits One Million Messages Per Second on Google Compute Engine, 2014. URL https://blog.pivotal.io/pivotal/products/rabbitmq-hits-one-million-messages-per-second-on-google-compute-engine.
[24] S. MacMullen. RabbitMQ Performance Measurements, part 2, 2012. URL https://www.rabbitmq.com/blog/2012/04/25/rabbitmq- performance- measurements- part- 2/.
[25] N. Nannoni. Message-oriented Middleware for Scalable Data Analytics Architectures. Master’s thesis, KTH Royal Institute of Technology, Sweden, 2015.
[26] P. Patierno. AMQP-Apache Kafka Bridge, 2017. URL https://github.com/EnMasseProject/amqp- kafka- bridge.
[27] rabbitmq sharding. Sharding Exchange. URL https://github.com/rabbitmq/rabbitmq- sharding.
[28] K. Sheykh Esmaili et al. Changing Flights in Mid-air: A Model for Safely Modifying Continuous Queries. In Proceedings ACM SIGMOD, pages 613–624, 2011.
[29] T. Treat. Benchmarking Message Queue Latency, 2016. URL http://bravenewgeek.com/benchmarking- message- queue- latency/.
[30] C. Trieloff et al. A General Purpose Middleware Standard. Network Programming, SunOS, 4, 2006.
[31] S. Vinoski. Advanced Message Queuing Protocol. IEEE Internet Computing, 10 (6), 2006.
[32] G. Wang et al. Building a Replicated Logging System with Apache Kafka. Proceedings of the VLDB Endowment, 8(12):1654–1655, 2015.
[33] J. Wyngaard. High Throughput Kafka for Science, 2015. URL https://events.linuxfoundation.org/sites/events/files/slides/HTKafka2.pdf.