最近人工神经网络期末期末小作业需要浅浅地写一下自己对BP网络的理解(比较基础型的),希望能对大家有所帮助。
(由于文档复制过来有的公式变形,有的被加上水印,导致公式看不清或者看不懂的,可以私信我或留言,我把原文档分享给你们)
1.人工神经网络(ANN)概述
1.1人工神经网络(ANN)的定义:
人工神经网络ANN,简称神经网络,是指由大量的 处理单元(神经元)互相连接而形成的复杂网络结构,是对人脑组织结构和运行机制的某种抽象、简化和模拟。人工神经网络(简称ANN ),以数学模型模拟神经元活动,是基于模仿大脑神经网络结构和功能而建立的一种信息处理系统。它有多层和单层之分,每一层包含若干神经元,不同的神经元与相应的权重连接从而组成的线性或非线性的分类。
2.人工神经网络(ANN)的基本原理
2.1神经元模型:
神经元是神经网络的基本组成,也被称为“激活单元”,每一个神经元都可以是一个独立的学习模型。
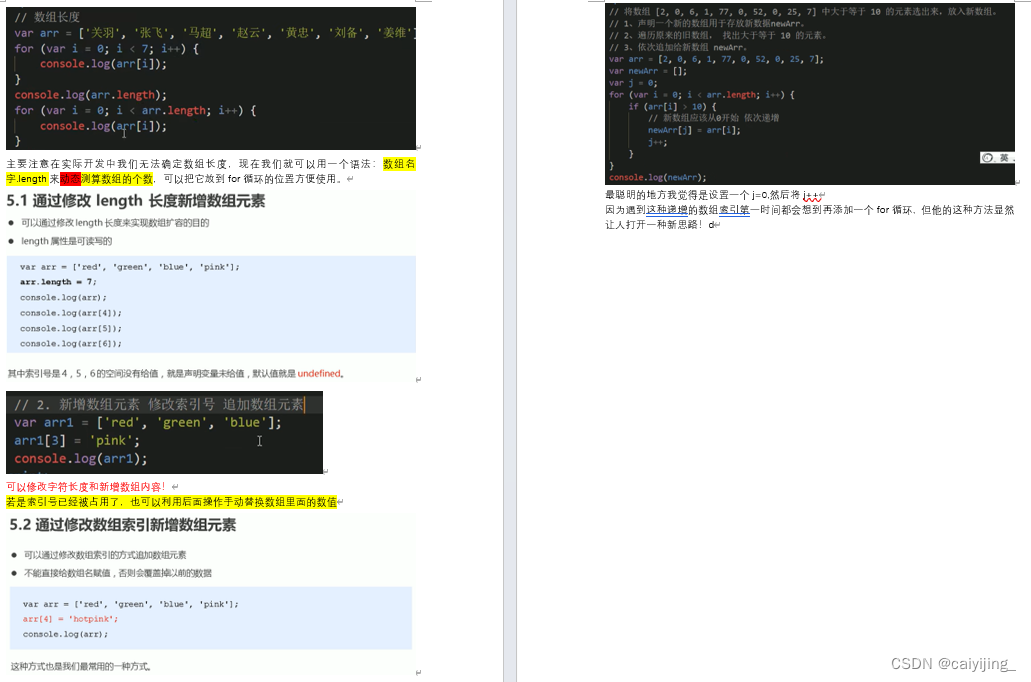
如下图,一个模拟神经元最简单的形式是有一个或多个输入值xi和一个值恒为1的截距项,偏置单元(一般不画出该神经元)和一个输出值y ,其中每个xi 都有一个权重wi。
最简单的来说,输出值就是输入值乘以权重之后的总和,即y=
2.2神经元模型的种类:
2.2.1单层感知机神经元(单层神经网络):
单层感知器只有一个输入层,一个输出层,隐层为0。有多个二进制(值只能是或1)输入xi,每个输入有对应的权值wi,每个输入值乘以对应的权值的累加和,然后经过激活函数“激活”得到输出值。这里的激活函数是符号函数,即
与一个阈值比较,大于阈值则输出1、小于阈值则输出0或-1。从而很好地实现了二分类。
2.2.2 Sigmoid神经元:
Sigmoid神经元中,输入的值不再是二进制,而是0到1之间的任意值。即xi取值是0到1之间的任意实数,而且Sigmoid神经元的输出也不再是0或1,输出值为h(x;θ)=sigmoid(w0+w1x1+w2x2+…+wnxn);当wixi趋向于正无穷时,其输出的值趋向于1,当
wixi趋向于负无穷时,其输出值趋向于0,其具有将小信号放大、大信号缩小的特征,从而把较大范围变化的连续值映射到区间[0,1]。
Sigmoid函数:
f(z)=sigmoid(z)=
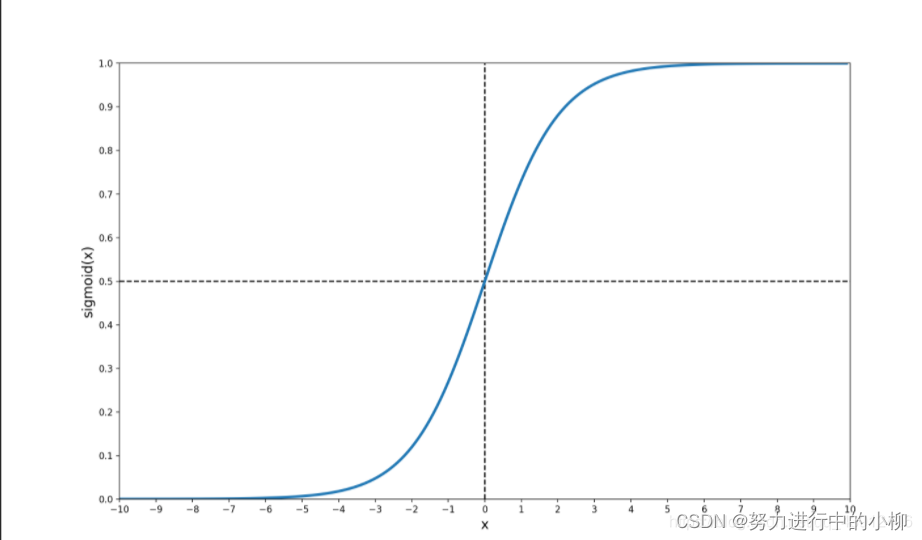
Sigmoid函数图像
2.3激活函数:
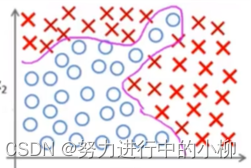
激活函数,也称为激励、活化函数,实现神经元的输入和输出之间非线性化。简单的神经元模型,和单层感知机模型都是线性可分模型。如果遇到分布较复杂的数据集,线性模型是无法实现完美的拟合。所以必须加入非线性因素(激活函数),实现神经元的输入和输出之间非线性化,增强神经网络的表达的能力。
我们可以简单理解为,如果没有激活函数,那么神经网络就没有了非线性变换,也就只能做线性变换。如下图:

3. 前馈神经网络
3.1 什么是前馈神经网络:
一个经典的神经网络是一个包含三个层次的。输入层、输出层和中间层(隐层)。多层前馈神经网络有一个输入层、多个中间层(隐层)和一个输出层,前馈神经网络的信号从输入层向输出层单向非线性映射,各层之间没有反馈,每一层神经元的输出可以理都作为下一层的输入,与下一层的神经元相连。前馈神经网络可以简单地理解为是感知机的集合。
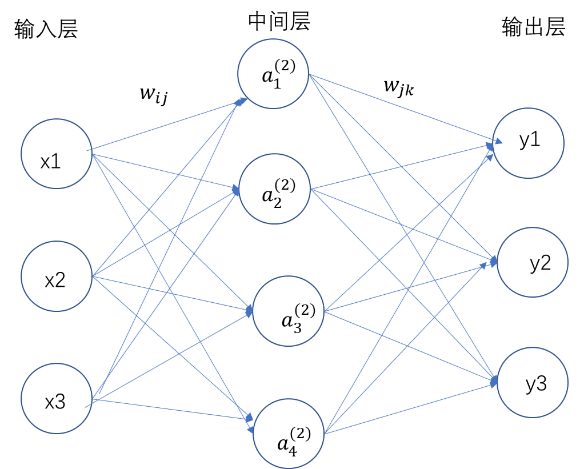
三层神经网络结构图
3.2前馈神经网络的算法步骤:
(假设输入层只有3个神经元,隐层有4个神经元,输出层只有3个神经元
(1)第一层直接接受原始数据输入,称为输入层,故计算第一层输出为:x1,x2,x3
(2)如果已知神经网络的参数θ={W1,W2,W(3)}计算第二层的输出:
(激活函数f(z)均为单极性Sigmoid函数:f(z)=sigmoid(z)=
且f(z)具有连续可导的特点,有 f(z)'=f(z)[1-f(z)])
a1(2)=f(W10(1)+W11(1)x1+W12(1)x2+W13(1)x3) = f(Wij(1)xj)
a2(2)=f(W20(1)+W21(1)x1+W22(1)x2+W23(1)x3)
a3(2)=f(W30(1)+W31(1)x1+W32(1)x2+W33(1)x3)
a4(2)=f(W40(1)+W41(1)x1+W42(1)x2+W43(1)x3)
(3)最后计算输出层的输出:
y1=g(W10(2)+W11(2)a1(2)+W12(2)a2(2)+W13(2)a3(2)+W14(2)a4(2)) =g(Wij(2)aj(2))
y2=g(W20(2)+W21(2)a1(2)+W22(2)a2(2)+W23(2)a3(2)+W24(2)a4(2))
y3=g(W30(2)+W31(2)a1(2)+W32(2)a2(2)+W33(2)a3(2)+W34(2)a4(2))
(注:ai(t):表示第t层的第i个激活单元(神经元)的输出。
Wij(t):表示第t层到t+1层的权重矩阵的第i行第j列,也就是第t层的第j个单元与第t+1层的第i个单元之间连线的权重。)
4.BP神经网络的基本原理:
4.1 什么是BP神经网络
BP神经网络是多层神经网络(前馈神经网络)与最优化方法(如梯度下降法)的结合使用,即BP神经网络=多层感知机+误差反向传播学习(训练)算法。
BP(误差反向传播)算法,它首先计算输出层的误差,然后一次一次地反向求出各层的误差,直到倒数第二层。它是在前馈神经网络的基础上增加了反馈机制,即通过迭代处理方式,不断地调整更新链接神经元的网络连接权值,使网络输出不断地接近期望输出,即输出误差最小。
4.2 BP神经网络算法步骤:(3层神经网络为例)
(1)首先前向传播算法计算出各层的输入、输出值:
第一层的输入和输出均为:x1,x2,x3…;
第二层的输入为:
W10(1)+W11(1)x1+W12(1)x2+W13(1)x3+…
W20(1)+W21(1)x1+W22(1)x2+W23(1)x3+…
W30(1)+W31(1)x1+W32(1)x2+W33(1)x3+…
W40(1)+W41(1)x1+W42(1)x2+W43(1)x3+…
…
第二层的输出为:
(激活函数f(z)为单极性Sigmoid函数:f(z)=sigmoid(z)= )
a1(2)=f(W10(1)+W11(1)x1+W12(1)x2+W13(1)x3+…) = ![]() f(j=
f(j=Wij(1)xj)
a2(2)=f(W20(1)+W21(1)x1+W22(1)x2+W23(1)x3+…)
a3(2)=f(W30(1)+W31(1)x1+W32(1)x2+W33(1)x3+…)
a4(2)=f(W40(1)+W41(1)x1+W42(1)x2+W43(1)x3+…)
…
输出层输入为
W10(2)+W11(2)a1(2)+W12(2)a2(2)+W13(2)a3(2)+W14(2)a4(2)+…
W20(2)+W21(2)a1(2)+W22(2)a2(2)+W23(2)a3(2)+W24(2)a4(2)+…
W30(2)+W31(2)a1(2)+W32(2)a2(2)+W33(2)a3(2)+W34(2)a4(2)+…
…
输出层输出为:
y1=g(W10(2)+W11(2)a1(2)+W12(2)a2(2)+W13(2)a3(2)+W14(2)a4(2)) = ![]() g(j=0nWjk(2)aj(2))
g(j=0nWjk(2)aj(2))
y2=g(W20(2)+W21(2)a1(2)+W22(2)a2(2)+W23(2)a3(2)+W24(2)a4(2))
y3=g(W30(2)+W31(2)a1(2)+W32(2)a2(2)+W33(2)a3(2)+W34(2)a4(2))
…
(2)计算网络输出值与期望值的误差:(设期望输出为d1、d2、d3…)
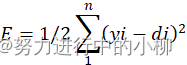
将以上的误差公式展开至隐层:
E=1/21ng(j=0nWjk(2)aj(2))-di2
再进一步展开至输入层:
E=1/21ng(j=0nWij(2)f(j=0nWij(1)xj))-di2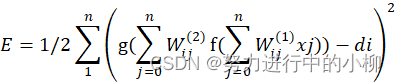
(3)计算梯度:
由上式可以看出,网络输出误差就是,各层权值Wij(1)、Wij(2)的函数,因此可以通过调整权值不断减小误差E,因此应使权值的调整量与误差的梯度下降成正比,方向与梯度相反的方向,即误差的梯度下降法。梯度,即指误差E对权值W求偏导。
对于输出层的梯度:
∂E∂Wjk(2)![]() (j=0,1,2…,n; k=0,1,2…,l )
(j=0,1,2…,n; k=0,1,2…,l ) 
令  ,
,
则梯度 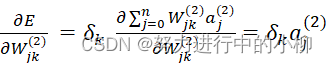
对于隐层的梯度:
![]() (i=0,1,2…,m; j=0,1,2…,n)
(i=0,1,2…,m; j=0,1,2…,n)
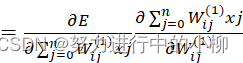
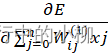 =δj
=δj![]() ,
,
则梯度 
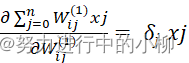
对于隐层的梯度:
![]() (i=0,1,2…,m; j=0,1,2…,n)
(i=0,1,2…,m; j=0,1,2…,n)

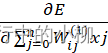 =δj
=δj![]() ,
,
则梯度 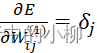
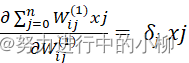
(4)调整权值:
对于输出层的权值调整式:
![]()
![]()
![]()
对于隐层的权值调整式:

=μ*δj*xj
常数μ∈![]() (0,1)表示比例系数,也叫作学习率,反应了学习速率。
(0,1)表示比例系数,也叫作学习率,反应了学习速率。
(5)计算新的权值:
对于输出层的新的权值:
Wjk(2)=Wjk(2)-∆Wjk(2)
=Wjk(2)- μ*δk*aj(2)
对与隐层的新的权值:
Wij(1)=Wij(1)-∆Wij(1)
=Wij(1)- μ*δj*xj
(6)计算新的网络输出值
根据上式计算得到的各层神经网络的新的权值W计算新的网络输出值yi
(7)迭代
再次计算新的网络输出值yi与期望输出值di的误差。如果还有误差较大,则重复(1)~(5)步骤迭代更新权值。
(8)终止条件:
当网络输出误差减小到最小或学习次数为0时,终止迭代。
4.3 3层神经网络实例
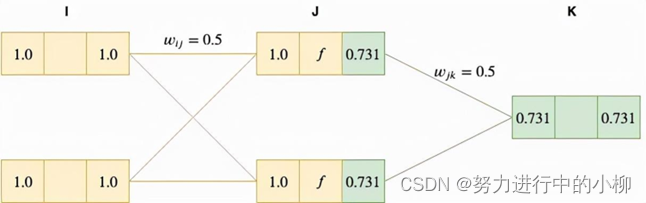
我们假设输入层的节点输入值设为x1=1.0,x2=1.0,输入层与隐层,隐层与输出层之间的网络权值初值wij、wjk都设为0.5,期望输出值为 0.5
(1)计算输入层(I层)的输入值、输出值:
输入层采用的是恒等函数作为激活函数,因此有yi=xi=1.0
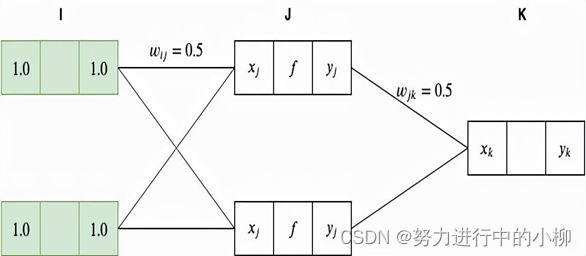
(2)计算隐层(J层)的输入值:
我们通过对I层(输入层)的输出值yi加权总和 向前传递到 J 层,作为J层的输入xj:
xj1=yi*wij=1.0∗0.5+1.0∗0.5=1.0
xj2=yi*wij=1.0∗0.5+1.0∗0.5=1.0

(3)计算隐层(J层)的输出值:
将 J 层节点的输入值xj由激活函数(sigmoid 函数f(z)=sigmoid(z)= )激活,得 yj=f(xj)=
≈0.732

4)计算输出层(K)层的输入值:
把J层(隐层)的输出值yj加权总和向前传递给k层,作为K层的输入xk
xk=yj*wjk=0.731*0.5+0.73*0.5 = 0.731
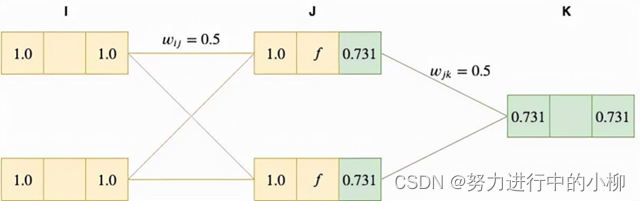
5)计算输出层(K)层的网络输出值:
需要保障输出端能接收到输出层输出的任何值,故K层(输出层)的激活函数是恒等函数(线性函数),故 yk=xk=0.731
(6)计算网络输出值与期望输出值的误差:(期望输出值为0.5)
∆yk= yk-yk'=0.731-0.5 = 0.231
误差较大,需要使用梯度下降法不断迭代调整各网络权值,降低误差。
(7)计算梯度:
损失函数:

对于输出层的梯度,即E对wjk的偏导数:
![]() (yj*wjk-yk')*yj
(yj*wjk-yk')*yj
=(yk-yk')*yj
=∆yk*yj
代入Δyk=0.231、yj= 0.731,得δk=∆yk*yj=0.168861

对于隐层,损失函数可变换为:

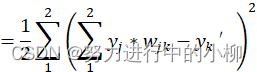
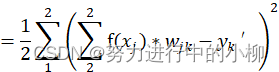

(Sigmoid函数:f(z)=sigmoid(z)=
且f(z)具有连续可导的特点,有 f(z)'=f(z)[1-f(z)])
隐层的梯度,即E对wij的偏导数:

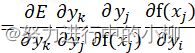
![]()
![]()
把Δyk=0.231、wjk=0.5、yj= fxj=0.731、yi=1代入,
得∆yk*wjk*fxj1-fxj*yi= 0.022796
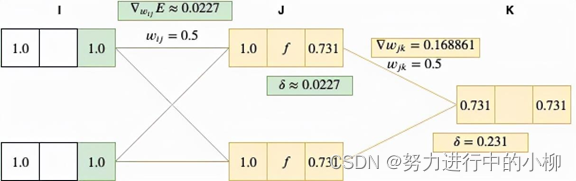
(8)计算权重调整值:(学习率μ设为0.01)
对于输出层:
∆wjk=μ*δk=0.01*0.0168866=0.00016886
对于隐层:
∆wij=μ*δj=0.01*0.022796=0.00022796
(9)计算新的各层新的网络权值:
对于输出层:
wjk=wjk-∆wjk=0.5-0.00016886=0.49983
对于隐层:
wij=wij-∆wij=0.5-0.00022796=0.49977
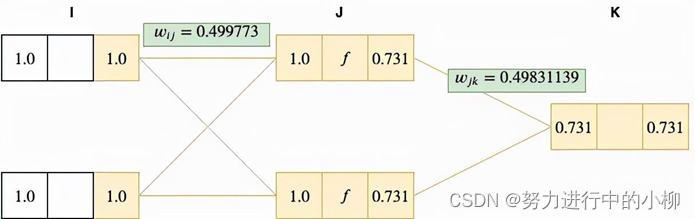
(10)计算新的网络输出值、误差:
可以看到这个权重值变化很小,一般来说将会得到一个比之前更小的误差。
第一遍我们得到的预测值
y1=0.731
采用新的权重值计算得到
y2≈0.7285
由此误差
y1−y1′=0.231
而 y2−y2′=0.2285
可见,误差得到了减小,按照该算法重复迭代运行,就可以将误差最终减小到0,或趋向于0。