发布于IEEE Transactions on Information Forensics and Security 2020
论文链接:https://arxiv.org/pdf/1902.04684v2.pdf
代码链接:https://gitlab.com/MISLgit/forensic-similarity-for-digital-images
摘要
本文提出了一种新的数字图像取证相似度方法,该方法用于判断两个图像块是否包含相同或不同的取证痕迹。 这种方法的一个好处是,在将来对取证痕迹作出取证相似性决定时,不需要先验知识,例如训练样本。 为此,我们提出了一个由基于CNN的特征提取器和称为相似度网络的三层神经网络组成的两部分深度学习系统。 该系统将成对的图像patch映射到一个score,指示它们是否包含相同或不同的取证痕迹。
我们评估了确定两个图像块是否
- 由相同或不同的相机模型捕获,
- 由相同或不同的篡改操作所修改,
- 在给定特定编辑操作的情况下,由相同或不同操纵参数操纵的系统准确度。
实验证明了对各种取证痕迹的适用性,并且重要地示出了对未用于训练系统的“未知”取证痕迹的功效。实验还表明,所提出的系统显著地改进了现有技术,将错误率降低了一半以上。此外,我们在两个实际应用中证明了取证相似性方法的效用:伪造检测和定位以及数据库一致性验证。
引言
现有方法的两个主要缺点
- 许多深度学习系统假设了一组封闭的取证痕迹,即已知且封闭的一组可能的编辑操作或相机模型。也就是说,这些方法需要来自特定取证跟踪的先前训练示例,例如源相机模型或编辑操作,以便将来再次识别它。此要求对于取证分析人员来说是一个重大问题,因为他们经常会看到新的或以前未见过的取证痕迹。此外,扩展深度学习系统以包含取证调查员可能遇到的大量类别通常是不可行的。例如,识别图像源相机模型的系统通常需要每个相机模型使用数百张场景多样的图像进行训练。要扩展这样一个系统以包含成百上千个相机模型,需要进行大量的数据收集工作(用于训练)。
- 许多取证调查不需要明确识别特定的取证踪迹。例如,在分析由多个图像的内容合成的拼接伪造时,通常只需检测由不同来源相机型号拍摄的图像区域就足够了,而无需明确识别该来源。也就是说,调查人员不需要确定对图像应用的确切处理,或者粘贴内容的真实来源,只是图像中存在不一致。又例如,在验证图像数据库的一致性时,调查者不需要明确识别使用了哪些相机型号来捕获数据库,只需使用一种相机型号或多种相机型号即可。
主要贡献
- 提出了一种新的数字图像取证方法,该方法对一组开放的取证痕迹进行操作。这种我们称之为取证相似性的方法确定两个图像块是否包含相同或不同的取证痕迹。这种方法不同于其他取证方法,因为它不会明确识别图像块中包含的特定取证痕迹,只是确定它们是否包含相同或不同的取证痕迹。这种方法的好处是不需要事先了解特定的取证痕迹就可以对其做出相似性决定。
- 提出了一个由基于CNN的特征提取器和称为相似度网络的三层神经网络组成的两部分深度学习系统。特征提取器使用 CNN 从图像块中提取一般的低维取证特征,称为深度特征。用三层神经网络将这些深层特征对映射到相似度分数上,这表明两个图像块是否包含相同的取证痕迹或不同的取证痕迹。
- 评估了在训练期间未使用的相机模型、操作和操作参数的性能,证明了这种方法在 openset 场景中是有效的。
- 在两个实际应用中证明了取证相似性方法的效用:伪造检测和定位以及数据库一致性验证。
取证相似性
取证相似性是一种确定两个图像块是否具有相同或不同取证痕迹的方法。与之前的取证方法不同,它不会识别特定的痕迹,但仍会为调查人员提供重要的取证信息。这种方法的主要好处是它能够在开放集场景中实际实施。也就是说,基于取证相似性的系统本身并不需要来自取证痕迹的训练样本来做出取证相似性决定。
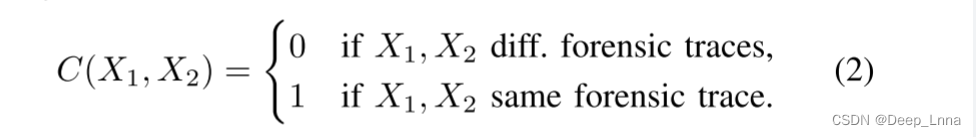
得分为0表示两个图像补丁包含不同的取证轨迹,得分为1表示它们包含相同的取证轨迹。图1是取证相似系统概述。
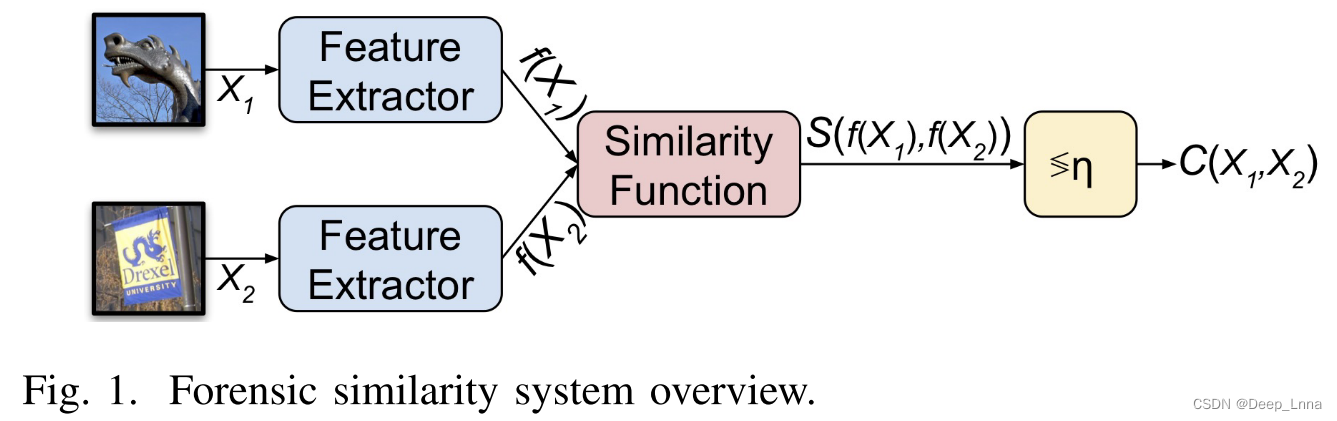
第一部分:特征提取器。
第二部分:相似性函数。它将取证特征向量对映射到取值从0到1的相似性得分。 低相似度分数表示两个图像贴片X1和X2具有不同的取证轨迹,高相似度分数表示两个取证轨迹高度相似。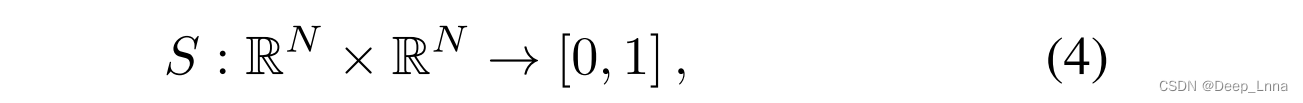
最后,将两个图像块X1和X2的相似度得分S(f(x1),f(x2))与阈值η进行比较,使得
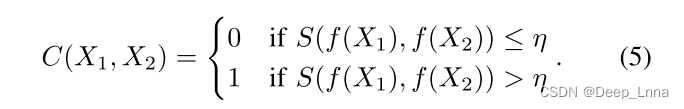
换句话说,所提出的取证相似度系统以两个图像贴片X1和X2作为输入。 特征提取器将这两个输入图像贴片映射到一对特征向量F(x1)和F(x2),它们编码关于图像贴片的高级取证信息。 然后,相似度函数将这两个特征向量映射到相似度得分,然后将相似度得分与阈值进行比较。 高于阈值的相似性分数表示X1和X2具有相同的取证轨迹(例如处理历史或源相机型号),低于阈值的相似性分数表示它们具有不同的取证轨迹。
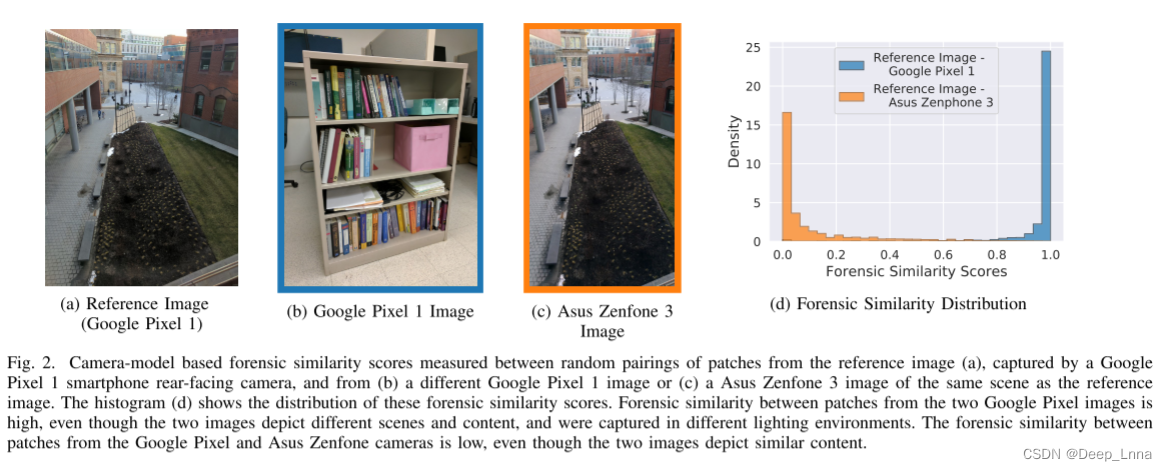
一个例子,见图2。计算了从三个不同图像中随机选择的小补丁之间的取证相似度得分:两个由谷歌Pixel 1捕获,一个由华硕ZenFone 3捕获。 这两个摄像机模型都没有用来训练系统。 当两个补丁被相同的相机模型捕获时,取证相似度得分很高,接近1,如图的蓝色分布所示 2(d)。当两个补丁被不同的相机模型捕获时,取证相似度得分很低,接近于0,如橙色曲线所示。 需要注意的一个重要性质是,取证相似度对图像中描述的语义内容是不变的。 例如,即使图像(A)和图像©描述了非常相似的场景,但由于它们是由不同的相机模型捕获的,它们的取证相似度很低。 这与目标检测和场景识别等计算机视觉方法是一个重要的区别,这些方法对任何非内容相关的质量(如源摄像机模型)都是不变的。
提出的方法
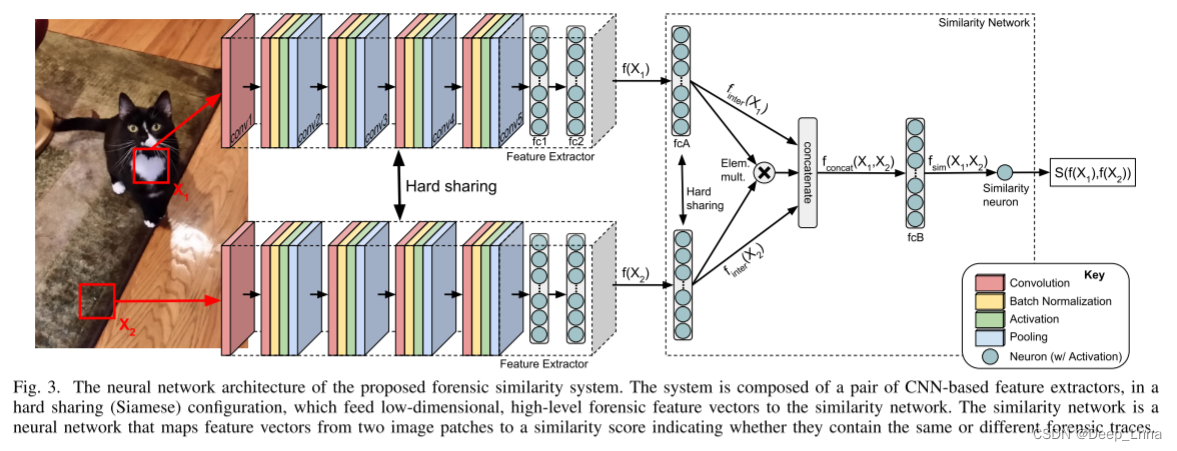
我们提出的取证相似性系统包括两个概念元素,如图3所示:1)基于CNN的特征提取器,它将输入图像映射到编码高级取证信息的低维特征空间,该特征空间编码关于patch的取证信息;2)三层神经网络,我们称之为相似性网络,它将这些特征对映射到指示两个图像patch是否包含相同取证轨迹的分数。 该系统分两个连续阶段进行训练。
在第一阶段,称为学习阶段A,训练特征提取器。
特征提取模块作者使用的是之前ON THE ROBUSTNESS OF CONSTRAINED CONVOLUTIONAL NEURAL NETWORKS TO JPEG POST-COMPRESSION FOR IMAGE RESAMPLING DETECTION2017中的方法。不同之处在于,这里作者使用了两个不同参的并行分支,一个用来处理256256的patch,一个用来处理128128的patch;还有一点就是之前只使用了RGB通道中的绿色通道,在这里作者使用了三个通道。此外,作者也放宽了第一层卷积中预测constrain卷积的限制,为了使网络可以学习更多的prediction error residual。第一层卷积核也从3变为6。FC2的输出为一个可以表示高级篡改信息的特征向量 。
在第二阶段,即学习阶段B中,训练相似度网络。

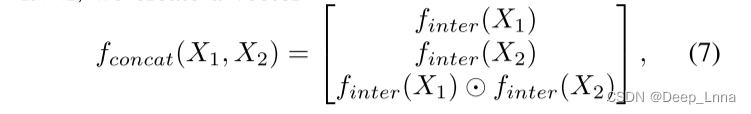

用基于熵的patch选择方法来过滤不适合取证分析的patch。
过滤器只在评估时使用,而不是在训练时使用。
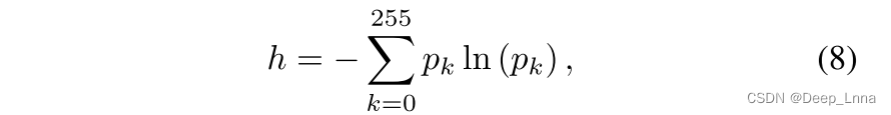
其中pk是像素在图像patch中具有亮度值k的概率。 熵h是用nats测量的。 我们通过测量图像patch中具有亮度值k的像素的比例来估计pk。
实验评价
我们进行了一系列实验测试了我们的系统的准确性,以确定两个图像补丁是1)由相同或不同的相机模型捕获,2)由相同或不同的编辑操作操纵,3)由相同或不同的操作参数操纵,给定一个特定的编辑操作。 此外,我们还进行了实验来检验取证相似系统的特性,包括:补丁大小和后压缩的影响,与其他相似度量的比较,以及网络设计和训练程序选择的影响。
实验结果表明,我们提出的取证相似度系统对于比较两个图像片上的各种类型的取证轨迹具有很高的准确性。 重要的是,这些实验表明,即使在没有用于训练系统的“未知”取证痕迹上,该系统也是准确的。 此外,实验表明,我们提出的系统比现有技术有了显著的改进,错误率降低了50%以上。
训练(A组和B组)和测试(C组)使用的照相机模型如表1所示。将摄像机模型分成A、B、C三个互不相交的集合,在学习阶段A用来自A的图像训练特征提取器,在学习阶段B用来自A和B的图像训练相似度网络,而来自C的图像只用于评价。
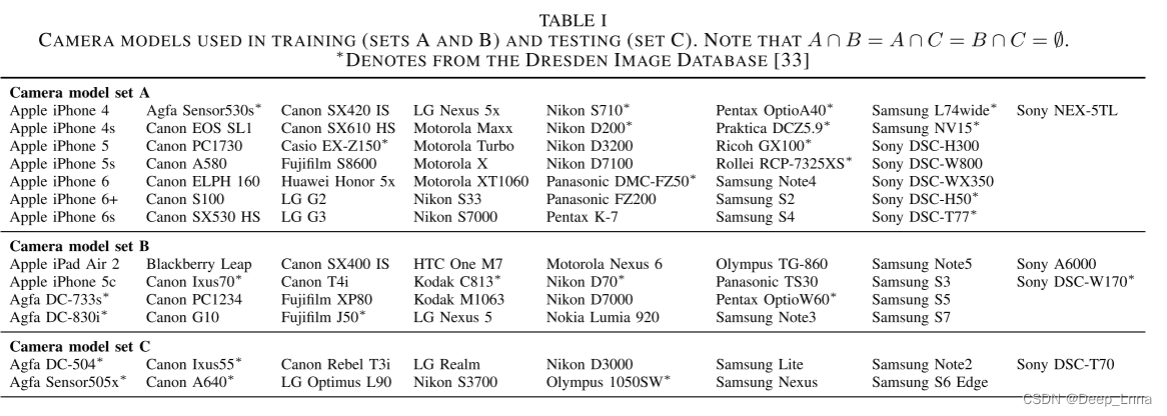
源相机型号比较
图 4 是25 种不同相机型号的相机型号正确率比较,它显示了提出的取证相似性系统按相机模型配对分类的准确性。矩阵的对角线条目显示了当两个图像块被同一相机型号捕获时的正确分类率。矩阵的非对角线项显示了不同相机型号捕获两个图像块时的正确分类率。训练中使用了 10 个相机模型,即“已知”相机模型,15 个相机模型未用于训练,即相对于分类器为“未知”。背景颜色随分类率变化。
例如,当两个图像块均由 Canon Rebel T3i 拍摄时,我们的系统在 98% 的情况下正确地将它们的源相机型号识别为“相同”。当一个图像块由佳能 PowerShot A640 拍摄,另一个图像块由尼康 CoolPix S710 拍摄时,我们的系统 100% 正确地识别出它们是由不同的相机型号拍摄的。
所有情况的总体分类准确率为 94.00%。左上区域显示了当两个图像块被已知相机型号(卡西欧 EX-Z150 到 iPhone 6s)捕获时的分类准确度。已知与已知案例的总准确率为 95.93%。右上角区域显示了当一个补丁由未知相机型号 Agfa DC-504 到 Sony Cybershot DSC-T70 捕获,而另一个补丁由已知相机型号捕获时的分类准确度。已知与未知案例的总准确率为 93.72%。右下区域显示了两个图像块均由未知相机型号捕获时的分类准确度。对于未知与未知案例,总准确率为 92.41%。这一结果表明,虽然所提出的取证相似性系统在已知相机模型上表现更好,但该系统在未知相机模型捕获的图像块上是准确的。
当两个图像块被同一制造商的类似相机型号捕获时,配对系统可能就会达不到很高的比较精度。例如,当一个相机型号是 iPhone 6 而另一个是 iPhone 6s 时,系统只能达到 26% 的正确分类率。这可能是由于这两款手机在硬件和处理管道方面的相似性,导致了非常相似的取证痕迹。在佳能 Powershot A640 与佳能 Ixus 55、LG 手机的任意组合、三星 Galaxy S6 Edge 与三星 Galaxy Lite 以及尼康 Coolpix S3700 与尼康 D3000 的对比中也观察到了这种现象。只有在少数情况下,相机品牌之间的比较率较低,例如三星 Galaxy Nexus 和摩托罗拉 X。这种混淆的潜在来源有很多,例如类似技术的许可,这是进一步研究的主题。尽管如此,在大多数相机模型配对中都实现了高相似性性能。
该实验的结果表明,我们提出的取证相似性系统可以有效地确定两个图像块是否由相同或不同的相机模型捕获,即使相机模型未知,即不用于训练系统。该实验还表明,虽然系统在大多数情况下都能实现高精度,但在某些相机模型对中,系统无法实现高精度,这通常是由于相机模型系统本身的潜在相似性。
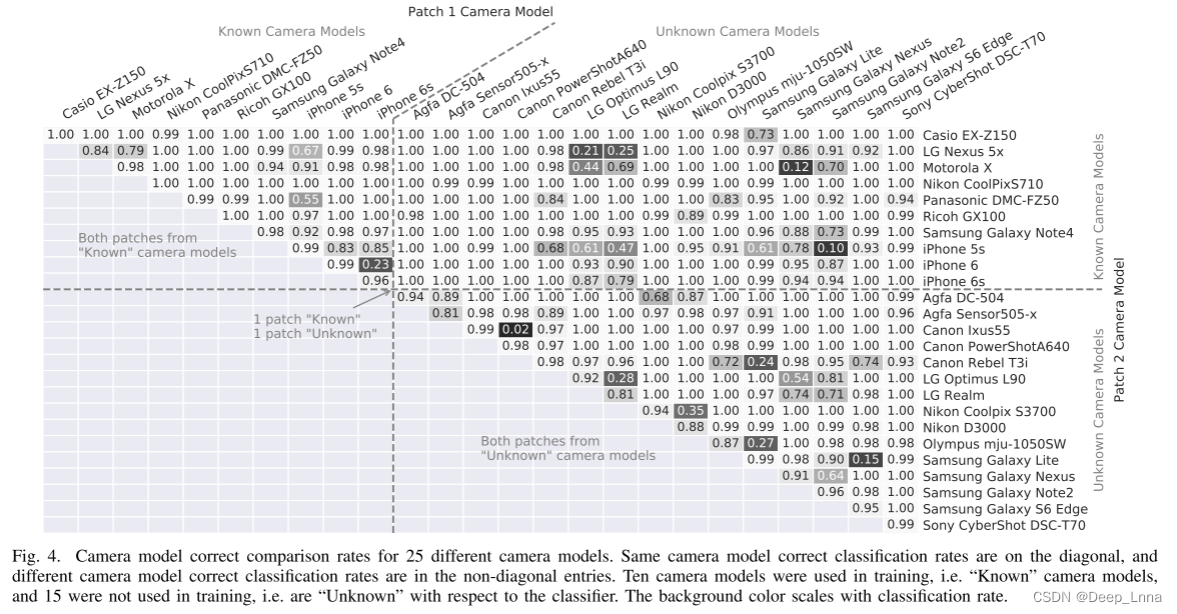
1) 补丁大小和再压缩效果:
在这个实验中,我们检查了我们提出的系统当输入图像经过第二次 JPEG 压缩并且补丁大小减小到 128×128 的大小时的性能。
图 5 显示了两种补丁大小在不同再压缩质量因子下的比较精度。这种准确性包括“已知与已知”、“已知与未知”和“未知与未知”的情况。在每个压缩质量因子下,使用 256×256 补丁大小训练的网络优于 128×128 补丁大小。这种影响在较低压缩质量因子时更为明显。该实验的结果表明,补丁大小和 JPEG 重新压缩都会影响整体系统性能。尽管如此,即使在适度的再压缩条件下,我们的系统也能够准确地比较取证痕迹。
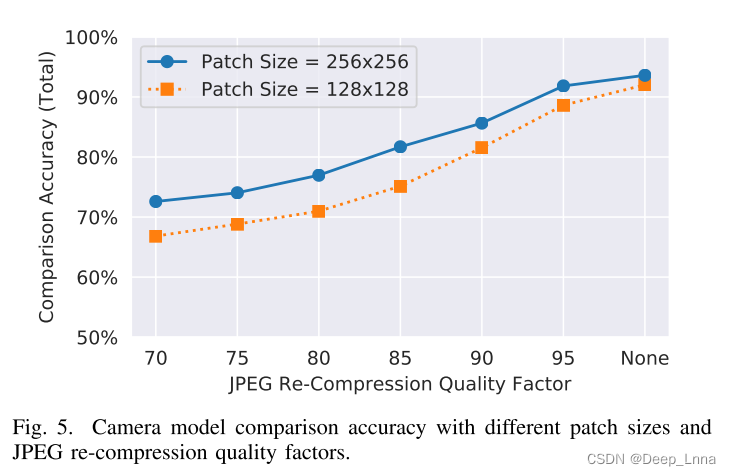
2)其他方法:
在学习阶段A,根据特征提取器提取的训练数据集的深度特征对每种方法进行训练,在学习阶段B中使用机器学习方法来代替提出的相似性网络。表2是基于标准距离和学习相似度量的摄像机模型精度比较。
结果表明,在标准距离范围内,相似度网络提高了相似度性能。 结果还表明,学习阶段B提高了提取特征的标准距离的准确性。
3)训练程序的影响:
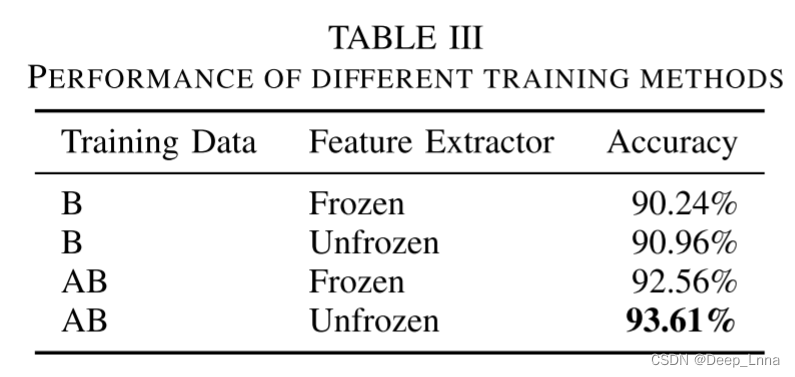
- 允许特征提取器更新,即在训练期间解冻;
- 使用不同的训练数据集。
表三显示了四种情况中每一种情况所达到的总体准确性。
4)架构变体:
表四显示了使用不同架构变体的总体相机模型比较精度。
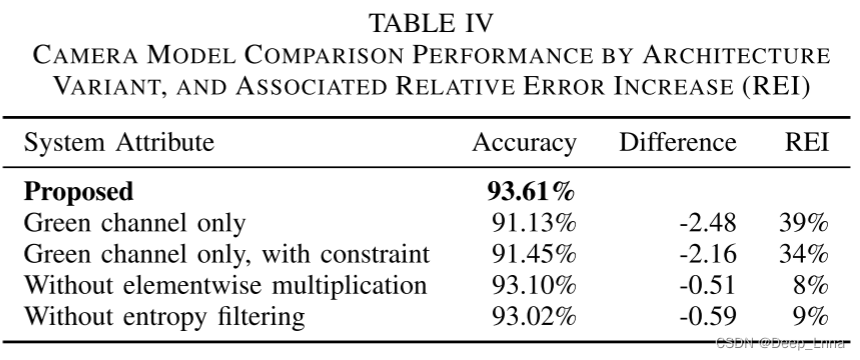
在第一种情况下,我们只使用绿色通道作为输入。 在这种情况下,实现了91.13%的准确率,增加了2.48个百分点的错误率。 这相当于从所提出的系统达到的93.61%的准确度相对增加了39%的误差。 相对误差增加(REI)由公式REI=(ACC1-ACC2)(100-ACC1)计算,其中ACC1是所提出的系统实现的精度,而ACC2是通过所建议的体系结构的变化实现的精度。 REI通过使用所提出的体系结构的一个变体来捕获错误率的百分比变化。
在第二种情况下,我们也使用绿色通道作为输入,并对第一层进行卷积约束。准确率的下降表明,所提出的全颜色信息对于相机模型的比较是重要的。
在第三种情况下,我们删除了相似网络中的元素乘结构。在最后的情况下,我们删除了基于熵的补丁滤波器。
5)熵阈值的影响:
图 6(a)显示了在不同熵阈值下的总体正确率比较。 图 6(b)给出了从我们的测试数据集中按熵分布的patch。
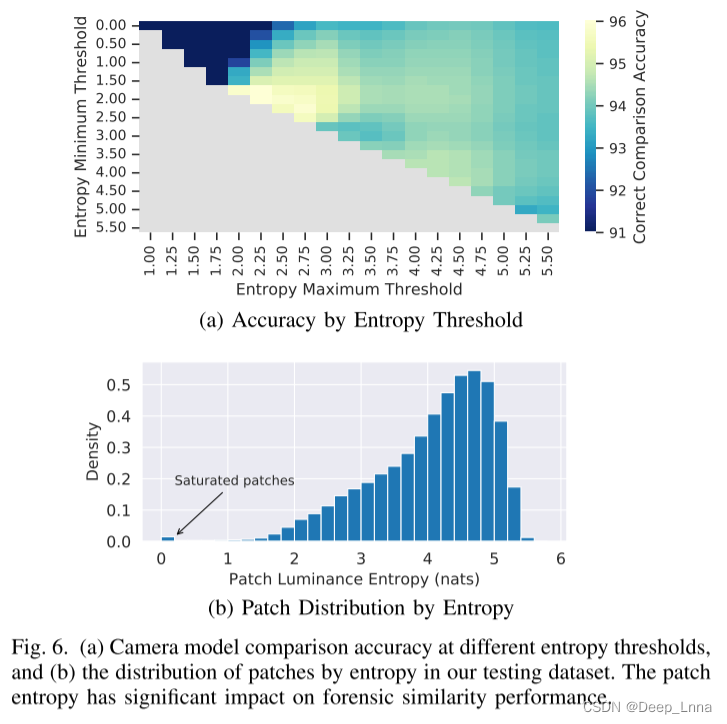
当两个patch均为0~1.75之间的低熵时,比较正确率为78.71%。 这些patch通常是饱和的,在那里很难提取有意义的取证信息。
当patch熵在2~2.75之间时,总体比对准确率显著提高,为95.73%。 这些贴片在外观上通常是“平坦的”,但不饱和。 我们对这些patch工作良好的原因是,该系统能够更有效地将取证痕迹从相对统一的场景内容中分离出来。
当patch的熵在5~5.4之间时,总体比对精度较低,为93.45%。 为什么这些patch稍微难以比较,因为它们包含高度变化的场景内容,这混淆了取证的痕迹(具有高语义内容的patch对于取证目的来说往往不那么可靠)。
对于图6(b),我们选择了最小熵1.8和最大熵5.2,因为它们是相对允许的,允许95%的补丁被分析,同时最大化性能。 在补丁选择性更强的应用程序中,补丁选择性更强可以实现更高的性能。
6)未知品牌:
测试未知相机模型上的取证相似度表现,图 7是未知品牌的正确率比较。
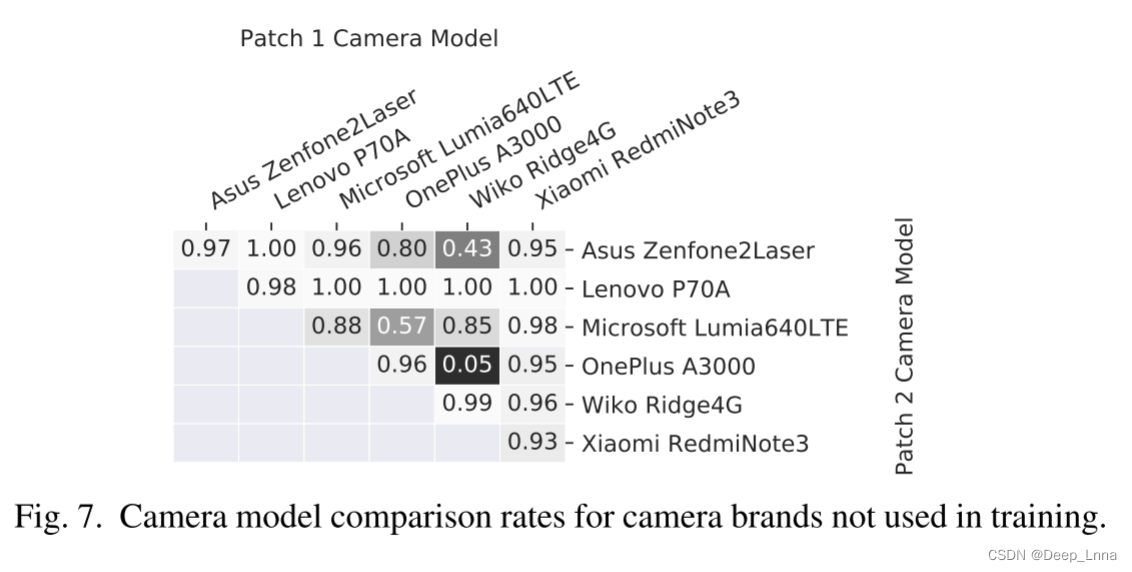
实验结果表明,即使在没有用于训练系统的相机模型的品牌上,取证相似度比较也是有效的。 在大多数摄像机模型配对中都实现了较高的比较精度。
编辑操作比较
在这个实验中,我们研究了我们提出的方法的有效性,以确定两个图像补丁是否被相同或不同的编辑操作操纵,包括不用于训练系统的“未知”编辑操作。使用表 V 中的八种“已知”操作之一修改每个补丁,并使用随机选择的编辑参数。
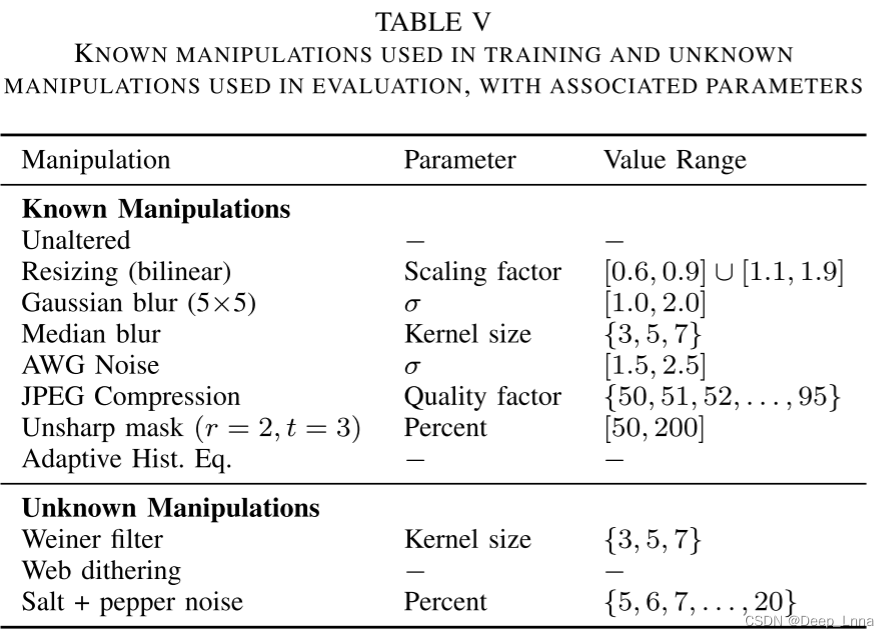
图 8 显示了我们提出的取证相似性系统按操作配对分解的正确分类率,前八列和行对应于已知操作,最后三列对应于未知操作。
该系统在绝大多数情况下都实现了较高的比较精度。然而,在许多情况下,双重 JPEG 压缩无法与单一 JPEG 压缩区分开来,包括当原始 JPEG 质量因子类似于或大于第二个 JPEG 质量因子时。锐化和直方图均衡化只会在不存在边缘内容或直方图已经均衡化的块中产生轻微的取证痕迹。
该实验的结果表明,我们提出的取证相似性系统在比较图像块的处理历史方面是有效的,即使图像块经历了未知的编辑操作,即在训练期间未使用。
编辑参数比较
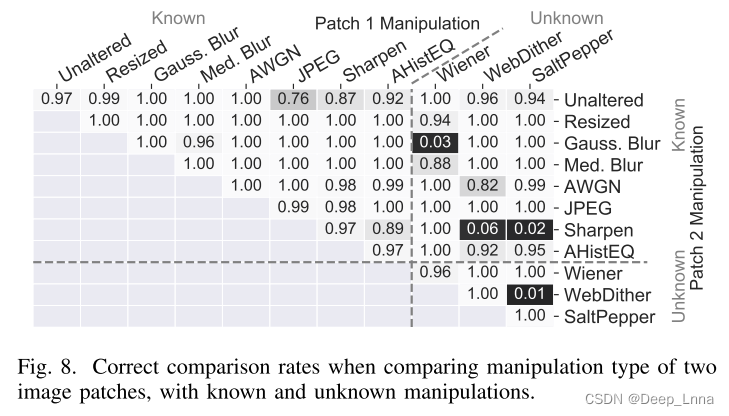
在这个实验中,我们研究了我们提出的方法的有效性,以确定两个图像块是否已被相同或不同的操作参数操作。具体来说,我们检查了按相同比例因子调整大小或按不同比例因子调整大小的图像块对,包括训练期间未使用的“未知”比例因子。这种类型的分析在分析拼接图像时很重要,其中主图像和外来内容都已调整大小,但外来内容已按不同因素调整大小。
我们提出的方法按测试的调整大小因子对进行分解的正确分类率如图 9 所示,未知比例因子为{0.8,1.2,1.4}。 蓝色高亮显示一个具有未知缩放因子的贴片,红色高亮显示两个贴片都具有未知缩放因子。
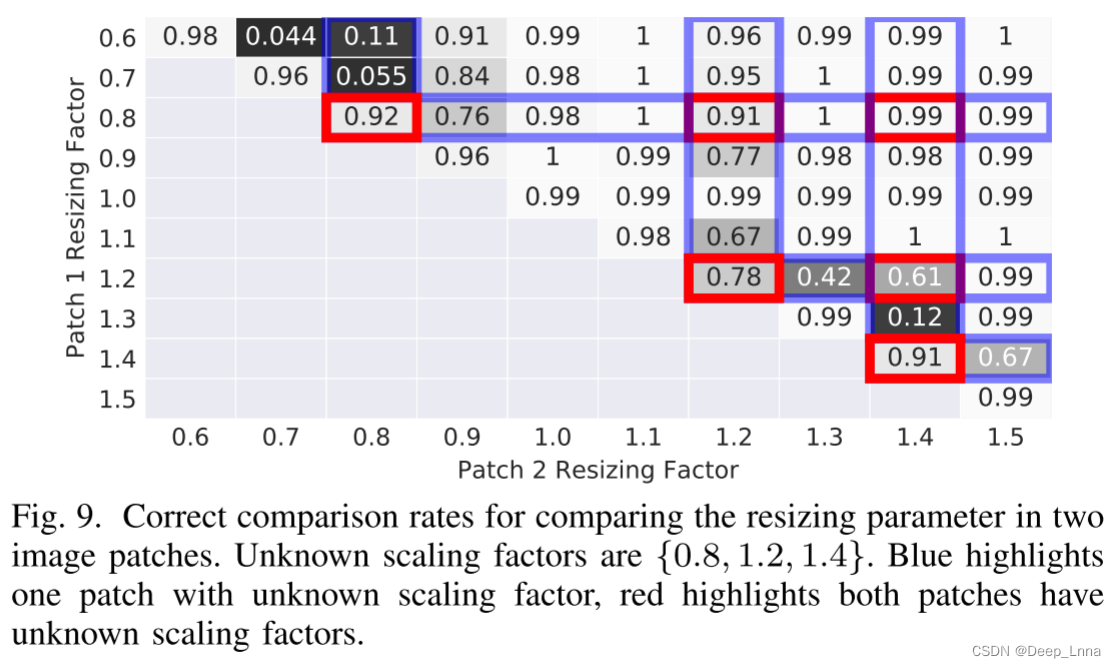
也有一些情况下,我们提出的系统没有达到很高的准确性。 这些情况往往发生在图像补丁已经调整大小与不同但相似的大小因素。
实验结果表明,本文提出的方法能够有效地比较两种图像片(第三种取证轨迹)中的操作参数。 实验表明,即使在一个或两个图像片被一个未知的编辑操作参数操纵的情况下,我们提出的方法仍然是有效的,而不是在训练中使用的。
实际应用
在两种类型的取证调查中使用取证相似度:图像伪造检测和定位,以及图像数据库一致性验证。
伪造检测与定位
所提出的相似系统通过暴露图像的伪造区域具有不同于图像其余部分的取证轨迹来检测和定位图像的伪造区域。 在第一个实验中,我们提出了一个简单的伪造检测准则,评估了它在三个公开数据集上的性能,并与现有的伪造检测方法进行了比较。 在第二个实验中,我们证明了我们提出的取证系统对于从一个流行的社交媒体网站下载的未知的伪造图像的局部篡改是有效的。
三个公开可用的数据集:Columbia,Carvalho和Korus。 对于一幅有N个块的图像,我们计算了N²个块对之间基于摄像机模型的取证相似度。 然后我们计算了平均相似度,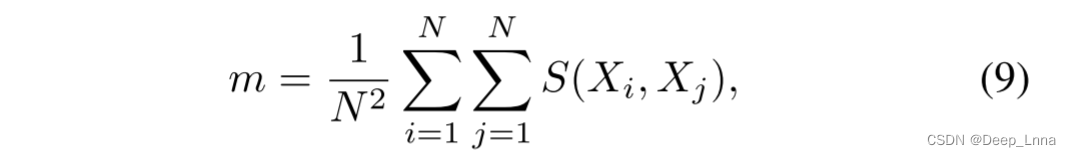
其中Xi是图像中的第i个采样块,s(·,·)是来自公式4的基于摄像机模型的相似度得分。 然后将该平均相似度得分与阈值进行比较,高值表示没有发生篡改,因为所有补丁预计彼此具有高相似度。
表VI显示了每个数据集的伪造检测的平均精度,并与一些先进的方法进行比较。

在第二个实验中,我们在三个从www.reddit.com下载的伪造图像上展示了伪造定位的潜力,我们也可以访问这些图像的原始版本。图 10是拼接检测和定位实例。 绿色方框勾勒出一个参考补丁,在图像上有50%重叠的补丁,如果检测到与参考补丁在取证上不同,则用红色突出显示。

图 11是又一个拼接检测和定位实例(一套玩具被拼接成政府官员会议的图像)。图11b看到的256×256和图11c的128×128,128×128例显示拼接区域的定位性较好,并进一步识别出与宿主图像不同的黄色飞机,而使用较大的块大小的相似性系统无法识别这些黄色飞机。

图12男子衬衫上的雨滴污渍被伪造者用刷子工具编辑掉了图像。

图12的图像已经被刷操作修改了,但是它正在被一个为源相机模型的比较而训练的网络检测。结果表明,由源相机模型引起的取证迹和由操纵引起的取证迹是相关的,这与我们在图的结果是一致的。
数据库一致性验证
在一些社交网站上,一些账户非法窃取来自许多不同来源的受版权保护的内容。 我们把这些账户称为“内容聚合器”,他们上传许多不同相机型号拍摄的图像。 这种类型的帐户与“内容生成器”帐户形成鲜明对比,后者上传由一个相机模型拍摄的图像。这个取证相似度系统应用于区分这些类型的帐户。
总结
本文提出了一种新的数字图像的取证相似度技术,它可以判断两个图像片是否包含相同或不同的取证轨迹。 这种方法的主要好处是,对取证痕迹作出取证相似性决定不需要先验知识,例如训练样本。 为此,我们提出了一个两部分的深度学习系统,该系统由基于CNN的特征提取器和三层神经网络组成,称为相似性网络,该网络将图像片对映射到一个分数上,指示它们是否包含相同或不同的取证轨迹。 我们在三种常见的取证场景中实验评估了我们的方法的性能,结果表明我们提出的系统在各种设置中都是准确的。 重要的是,实验表明,即使在未用于训练系统的“未知”取证轨迹上,该系统也是准确的,并且我们提出的系统在文献[22]中的现有技术的基础上有了显著的改进,将错误率降低了50%以上。 此外,我们在两个实际应用中证明了取证相似度方法在伪造检测与定位和图像数据库一致性验证中的实用性 。



