本文介绍基于Python语言,读取Excel表格文件,基于我们给定的规则,对其中的数据加以筛选,将不在指定数据范围内的数据剔除,保留符合我们需要的数据的方法。
首先,我们来明确一下本文的具体需求。现有一个Excel表格文件(在本文中我们就以.csv格式的文件为例),如下图所示。
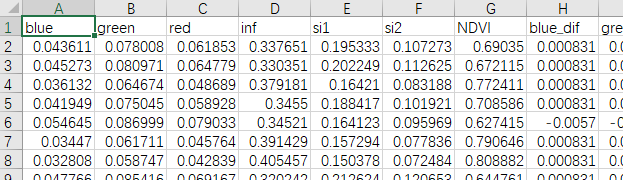
其中,Excel表格文件具有大量的数据,每一列表示某一种属性,每一行表示某一个样本;我们需要做的,就是对于其中的部分属性加以数据筛选——例如,我们希望对上图中第一列的数据进行筛选,将其中大于2或小于-1的部分选出来,并将每一个所选出的单元格对应的行直接删除;同时,我们还希望对其他的属性同样加以筛选,不同属性筛选的条件也各不相同,但都是需要将不符合条件的单元格所在的整行都删除。最终,我们保留下来的数据,就是符合我们需要的数据,此时我们需要将其保存为一个新的Excel表格文件。
明白了需求,我们即可开始代码的撰写;本文用到的具体代码如下所示。
# -*- coding: utf-8 -*-
"""
Created on Wed Jun 7 15:40:50 2023@author: fkxxgis
"""import pandas as pdoriginal_file = "E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/23_Train_model_NoH/Train_Model_1_NoH.csv"
result_file = "E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/23_Train_model_NoH/Train_Model_1_NoH_New.csv"df = pd.read_csv(original_file)df = df[(df["inf"] >= -0.2) & (df["inf"] <= 18)]
df = df[(df["NDVI"] >= -1) & (df["NDVI"] <= 1)]
df = df[(df["inf_dif"] >= -0.2) & (df["inf_dif"] <= 18)]
df = df[(df["NDVI_dif"] >= -2) & (df["NDVI_dif"] <= 2)]
df = df[(df["soil"] >= 0)]
df = df[(df["inf_h"] >= -0.2) & (df["inf_h"] <= 18)]
df = df[(df["ndvi_h"] >= -1) & (df["ndvi_h"] <= 1)]
df = df[(df["inf_h_dif"] >= -0.2) & (df["inf_h_dif"] <= 18)]
df = df[(df["ndvi_h_dif"] >= -1) & (df["ndvi_h_dif"] <= 1)]df.to_csv(result_file, index = False)
下面是对上述代码每个步骤的解释:
- 导入必要的库:导入了
pandas库,用于数据处理和操作。 - 定义文件路径:定义了原始文件路径
original_file和结果文件路径result_file。 - 读取原始数据:使用
pd.read_csv()函数读取原始文件数据,并将其存储在DataFrame对象df中。 - 数据筛选:对DataFrame对象
df进行多个条件的筛选操作,使用了逻辑运算符&和比较运算符进行条件组合。例如,其中的第一行df["inf"] >= -0.2和df["inf"] <= 18就表示筛选出"inf"列的值在-0.2到18之间的数据;第二行df["NDVI"] >= -1和df["NDVI"] <= 1则表示筛选出"NDVI"列的值在-1到1之间的数据,以此类推。 - 保存结果数据:使用
to_csv()函数将筛选后的DataFrame对象df保存为新的.csv文件,保存路径为result_file,并设置index=False以避免保存索引列。
当然,如果我们需要对多个属性(也就是多个列)的数据加以筛选,除了上述代码中的方法,我们还可以用如下所示的代码,较之前述代码会更方便一些。
result_df = result_df[(result_df["blue"] > 0) & (result_df["blue"] <= 1) &(result_df["green"] > 0) & (result_df["green"] <= 1) &(result_df["red"] > 0) & (result_df["red"] <= 1) &(result_df["inf"] > 0) & (result_df["inf"] <= 1) &(result_df["NDVI"] > -1) & (result_df["NDVI"] < 1) &(result_df["inf_dif"] > -1) & (result_df["inf_dif"] < 1) &(result_df["NDVI_dif"] > -2) & (result_df["NDVI_dif"] < 2) &(result_df["soil"] >= 0) &(result_df["NDVI_dif"] > -2) & (result_df["NDVI_dif"] < 2) &(result_df["inf_h_dif"] > -1) & (result_df["inf_h_dif"] < 1) &(result_df["ndvi_h_dif"] > -1) & (result_df["ndvi_h_dif"] < 1)]
上述代码可以直接对DataFrame对象加以一次性的筛选,不用每筛选一次就保存一次了。
运行本文提及的代码,我们即可在指定的结果文件夹下获得数据筛选后的文件了。
至此,大功告成。
欢迎关注:疯狂学习GIS