为什么用
分布式系统庞大而复杂,服务众多,调用关系网也非常复杂,
- 服务上线以后如果出现了某些错误,错误的异常就很难定位。
- 一个请求可能调用了非常多的链路,我们需要知道到底哪一块儿出现了错误。
最终希望有一个链路追踪系统,我们从每一个请求进来,到它最终的结束,他们中间都调用了多少的微服务,包括每一个服务调用花费了多长时间。
只有最终结合了链路追踪系统,才可以做好熔断降级,通过链路追踪系统发现,某个服务特别慢,但是它还正常运行着,我们就直接给它降级使用,预防我们整个系统的雪崩问题。
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。
主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。
所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
所以就非常有必要在分布式系统中,构建一个服务链路追踪系统。
链路追踪组件有 Google 的 Dapper,Twitter 的 Zipkin,以及阿里的 Eagleeye (鹰眼)等,它们都是非常优秀的链路追踪开源组件。
基本术语和流程
-
Span(跨度):基本工作单元,发送一个远程调度任务就会产生一个 Span,Span 是一个 64 位 ID 唯一标识的,Trace 是用另一个 64 位 ID 唯一标识的,Span 还有其他数据信息,比如摘要、时间戳事件、Span 的 ID、以及进度 ID。
-
Trace(跟踪):一系列 Span 组成的一个树状结构。请求一个微服务系统的 API 接口,这个 API 接口,需要调用多个微服务,调用每个微服务都会产生一个新的 Span,所有由这个请求产生的 Span 组成了这个 Trace。
-
Annotation(标注):用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束 。这些注解包括以下:
- cs - Client Sent -客户端发送一个请求,这个注解描述了这个 Span 的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其 sr 减去 cs 时间戳便可得到网络传输的时间。
- ss - Server Sent (服务端发送响应)–该注解表明请求处理的完成(当请求返回客户端),如果 ss 的时间戳减去 sr 时间戳,就可以得到服务器请求的时间。
- cr - Client Received (客户端接收响应)-此时 Span 的结束,如果 cr 的时间戳减去cs 时间戳便可以得到整个请求所消耗的时间。
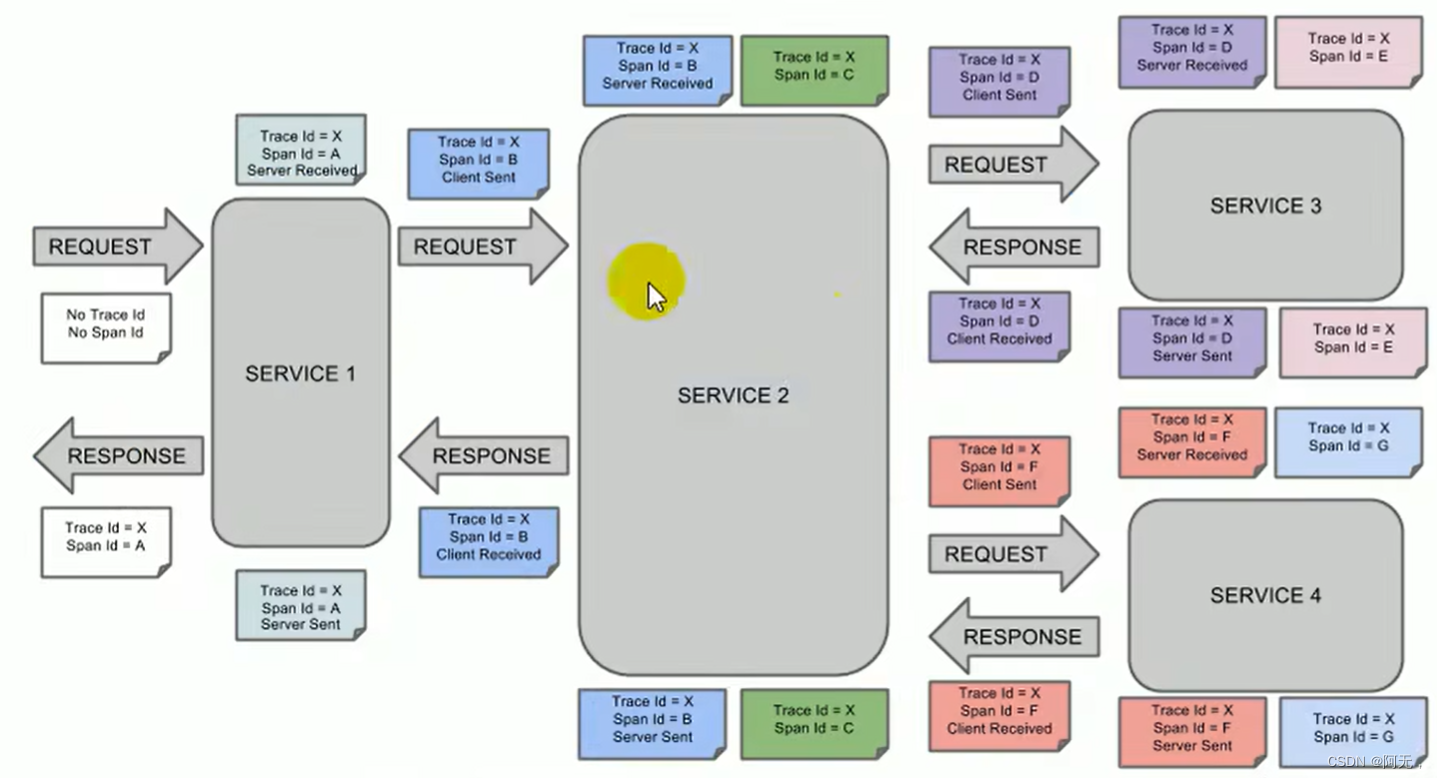
-
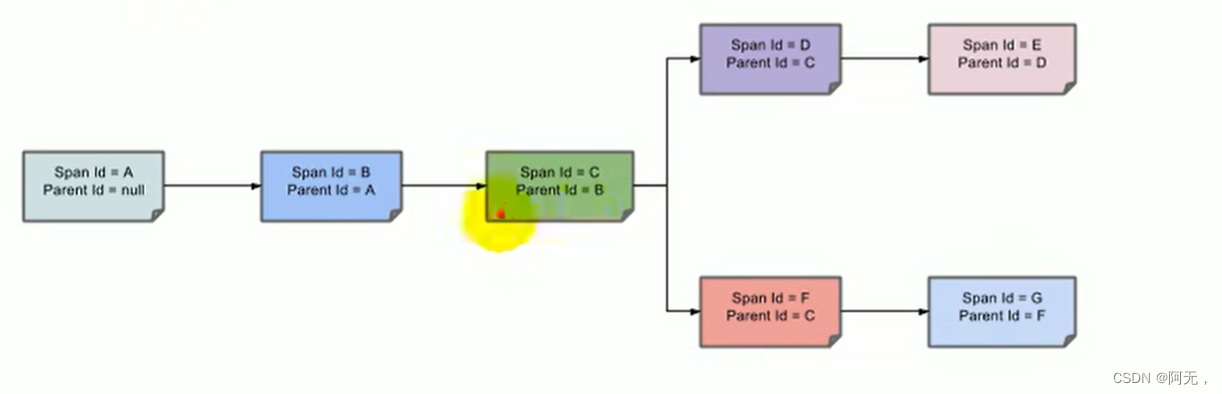
浏览器发送request请求到service1,产生span A,记录trace id,span id,并标识Server Received(代表这个请求是什么时候收到的),service1进行处理。
因为该请求是浏览器发的,所以不会记录Client Sent。 -
接着远程调用service2,将请求发出去,又会产生一个spanB,记录 client sent(发送请求的时间)和Server Received,两者相减就是我们能的传输时间。
-
service2处理完成后产生spanC(这代表着下一个请求)并并发发出去,就会产生两个不同的span,产生SpanD和spanF,分别记录了client sent。
-
service3接收到请求记录Server Received,处理完成后又产生spanE,但是我们不再调用远程方法,spanE就可以被舍弃了。
service3处理完成spanD后记录serverSent,serverSent与serverRecived相减,就是service3处理请求的时间。 -
在返回的响应中,记录Client Received,也就是客户端,service2收到的响应时间。
-
此时的链路可以追踪到,spanA - spanB - spanD(spanC不算,只是一个业务处理产生的span),然后spanD返回响应。
-
service4的链路同service3。
判断是网络故障还是服务故障,拿spanF举例,
- serverSent减serverRecived如果时间超长,那么就是服务出现了问题
- serverRecived减clientSent如果时间超长,那么就是网络出现了问题
链路中间的传输时间,每一个服务的处理时间,都打了标签,所以我们都能得到这些数据。
标签是有父子关系的,每一个下级标签的父标签都是上级标签。
有父子关系后,就能画出整个调用链的树形结构了,包括它的链路结构。
springboot整合Sleuth和zipkin
# 服务提供者与消费者导入依赖
# 所以我们直接把依赖导入到common模块中
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId></dependency>
通过 Sleuth 产生的调用链监控信息,可以得知微服务之间的调用链路,但监控信息只输出
到控制台不方便查看。我们需要一个图形化的工具-zipkin。Zipkin 是 Twitter 开源的分布式跟
踪系统,主要用来收集系统的时序数据,从而追踪系统的调用问题。
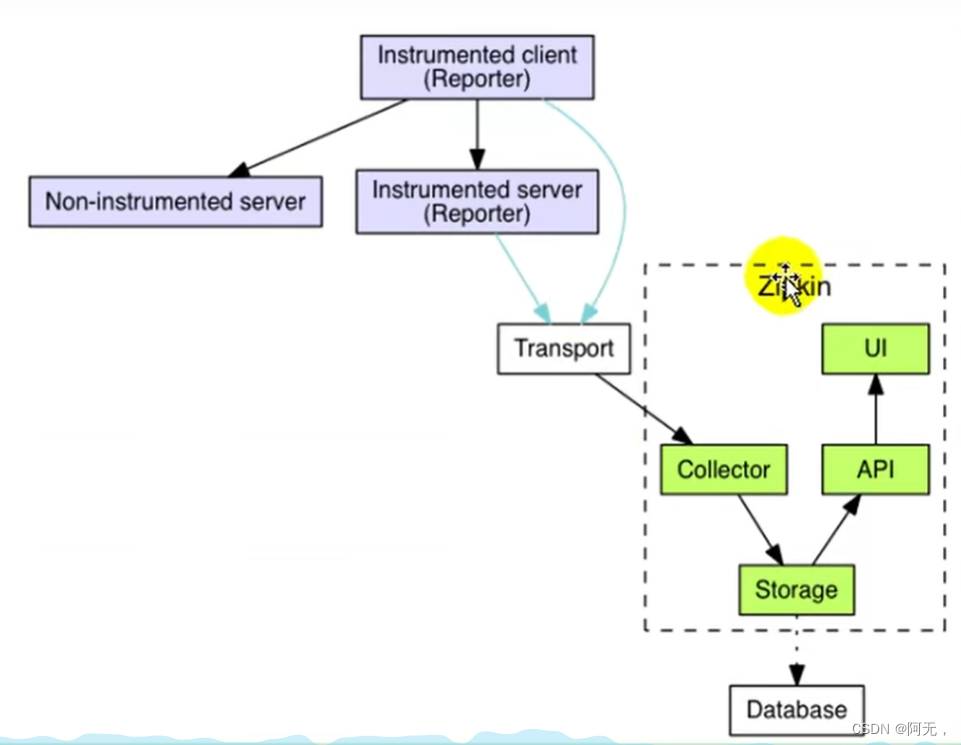
zipkin有ui界面,也有相关的api操作,也能把数据存储到一个地方,同时也能收集数据。
zipkin可以把我们服务的数据收集过来,我们服务的客户端就要给它汇报数据,所以我们需要导入zipkin的依赖,我们的客户端就能汇报数据了,汇报来的数据收集到zipkin的服务器里面来做可视化展示。
Zipkin 默认是将监控数据存储在内存的,如果 Zipkin 挂掉或重启的话,那么监控数据就会丢失。所以如果想要搭建生产可用的 Zipkin,就需要实现监控数据的持久化。
而想要实现数据持久化,自然就是得将数据存储至数据库。zipkin支持将数据存储在
- 内存(默认)
- MySQL
- Elasticsearch(我们用这个)
- Cassandra
docker run -d -p 9411:9411 openzipkin/zipkin# 启动zipkin,将数据保存至es中
docker run --env STORAGE_TYPE=elasticsearch --env ES_HOSTS=192.168.56.10:9200
openzipkin/zipkin-dependencies# 也是导入到common中
# zipkin中已经导入了sleuth,所以之前的sleuth依赖可以去掉
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
application.properties
spring.cache.type=redis
spring.cache.redis.time-to-live=3600000
spring.cache.redis.use-key-prefix=true
spring.cache.redis.cache-null-values=truegulimall.thread.core-size=20
gulimall.thread.keep-alive-time=10
gulimall.thread.max-size=200spring.session.store-type=redis# actuator 暴露所有资源
management.endpoints.web.exposure.include=*
# sentinel dashboard 地址
spring.cloud.sentinel.transport.dashboard=localhost:8333
# 限流成功指定返回的内容类型
spring.cloud.sentinel.scg.fallback.content-type=application/json
spring.cloud.sentinel.scg.fallback.response-status=400# 开启feign的sentinel远程保护
feign.sentinel.enabled=true# 开启debug日志
logging.level.org.springframework.cloud.openfeign=debug
logging.level.org.springframework.cloud.sleuth=debug# zipkin服务器地址
spring.zipkin.base-url=http://192.168.56.10:9411/
# 关闭服务发现,否则spring cloud会把zipkin的url当作服务名称
spring.zipkin.discovery-client-enabled=false
# zipkin以web http的方式发送数据
spring.zipkin.sender.type=web
# 采样器,默认为0.1,即百分之十,只采样百分之十的请求数据
spring.sleuth.sampler.probability=1
企业的需求是现实性的,因为我们必须要解决现实问题,但教育不应该集中在现实需求上,要面向未来。
https://baijiahao.baidu.com/s?id=1760664270073856317&wfr=spider&for=pc
擦亮花火、共创未来——任正非在“难题揭榜”花火奖座谈会上的讲话
任正非