侯圣文大数据体验课笔记
一、玩转大数据和互联网大厂大数据解析
大数据职位有广袤的海洋:
未来比较吃香的ABC
A:AI人工智能
B:Big Date大数据
C:云计算
| 人 | 工 | 智 | 能 | |
| 算 | 逛吃看买 | 肉眼检索 | 数据库查询 | 智能推荐 |
| 存 | 脑袋 | 海报 | 数据库DB | 大数据BD |
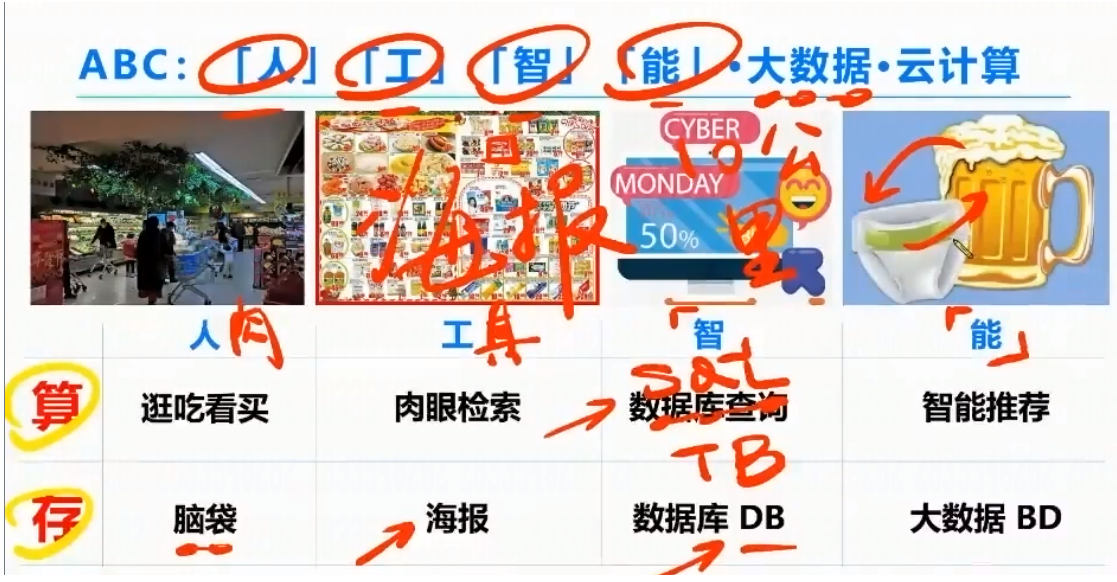
客户买东西的演进过程:
- 超市买物品,寻找商品只能靠人走看买,有哪些商品在大脑里存储
- 海报:寻找商品在海报上肉眼检索,物品在海报上记录
- 比较先进:自己家附近3公里内,有点像早期的外卖,买什么在在线购物平台上,寻找:直接搜索,数据存储在数据库中
- 智能推荐:基于大数据统计,发现人们买东西的时候,出现捆绑消费的习惯,把捆绑消费的东西提前放在一起,有点像现在网购,你买个手机,给你推荐同手机型号的的手机壳。寻找商品智能推荐,数据存储在大数据BD.
智能:对用户来说,体验比较好。对老板来说赚钱比较多。
阶段1:价格
阶段2:价值
阶段3:爽,价值观
分布式
分布式系统,可以类比显示生活中的牛拉物,我们不可能创造出无穷无尽的牛,来拉取比较大的东西。计算机我们不能期望制造一台无穷大的机器,要留多少个卡槽合适呢,插硬盘,显卡,这种怎么设计呢。显然不太现实。牛,我们用多个牛。不能指望一头牛变得无穷大。不能指望一个机器无穷大。
大数据分布式存储,分布式计算的演进过程。

从DB到BD
数据库(DB)技术发展的三个时代
-
数据库发展的三个时代,成就了三种商业形态
-
商业数据库时代:成就了商业软件行业;
-
开源数据库时代:成就了互联网
-
新(开)数据库时代:是商业和开源、SQL和NewSQL交融的时代,成就了云和数字化时代

-
| Database | BigData |
|---|---|
| OLTP交易 | OLAP分析 |
| ACID事务 TB | CAP BASE PB |
| 业务系统 | 洞察 |
大数据的3v特征–多块好省
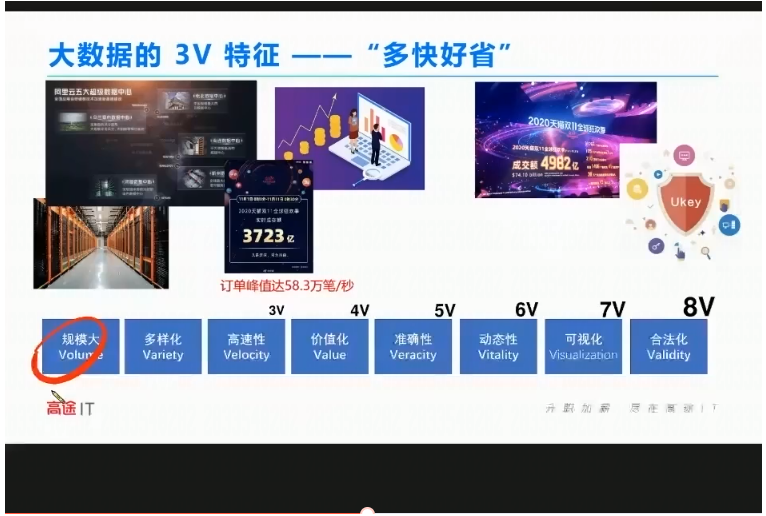
多:规模大、多样性
快:高速性
好
省
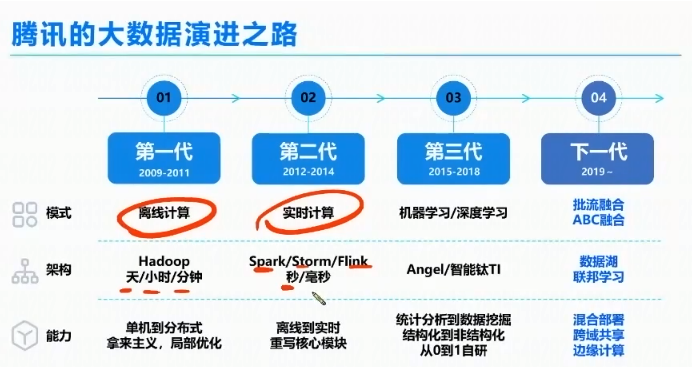
腾讯的大数据演进之路
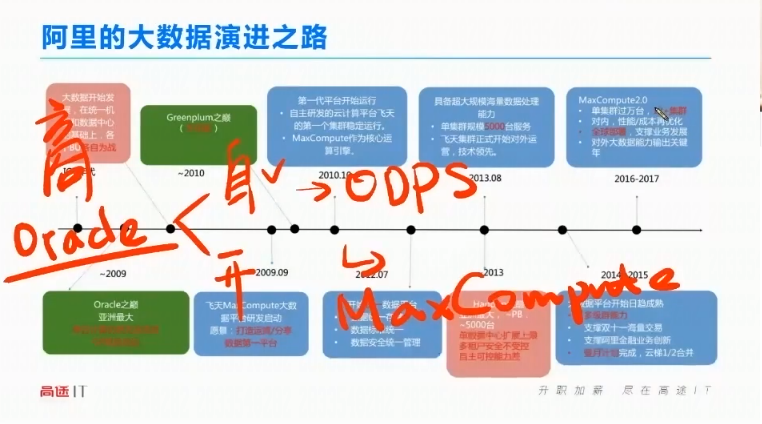
阿里的数据演进之路
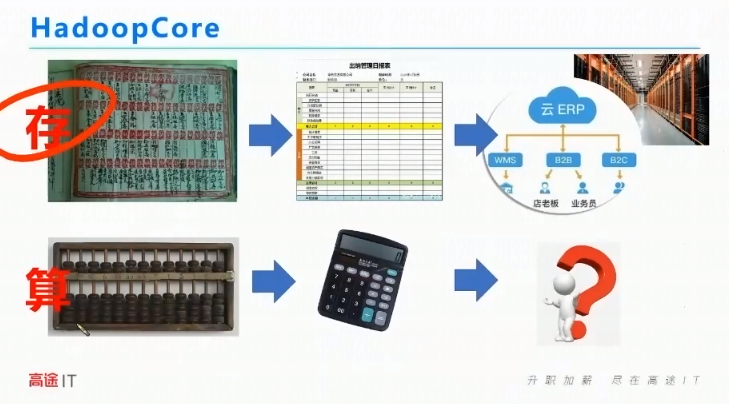
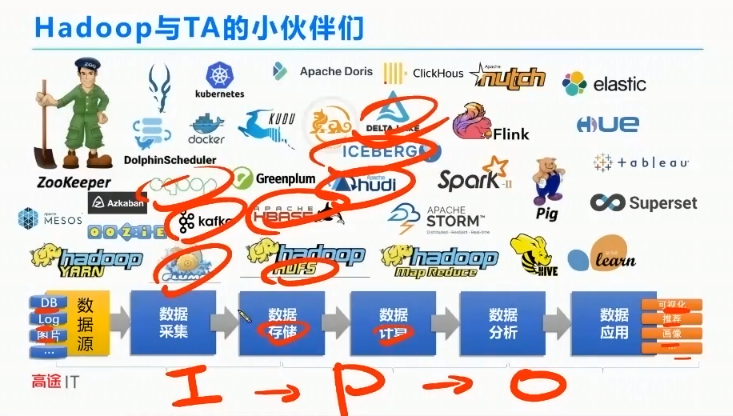
Hadoop Core
| 存 | 账本 | 表格 | 云ERP |
|---|---|---|---|
| 算 | 算盘 | 计算器 | ? |
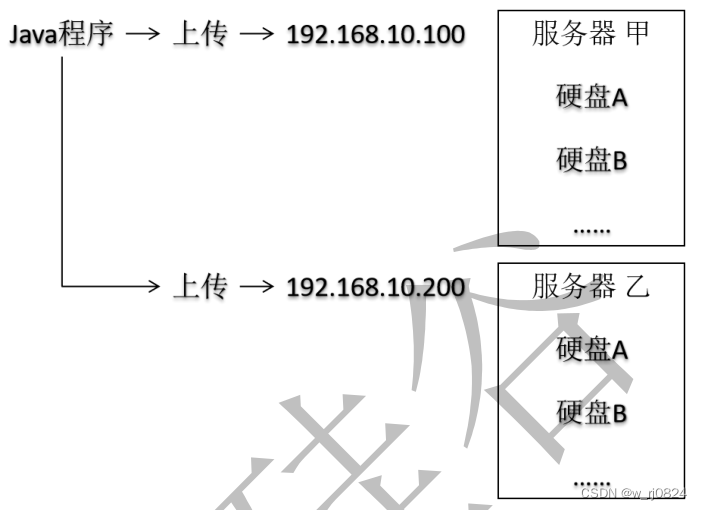
房子丢失,每份数据存三份
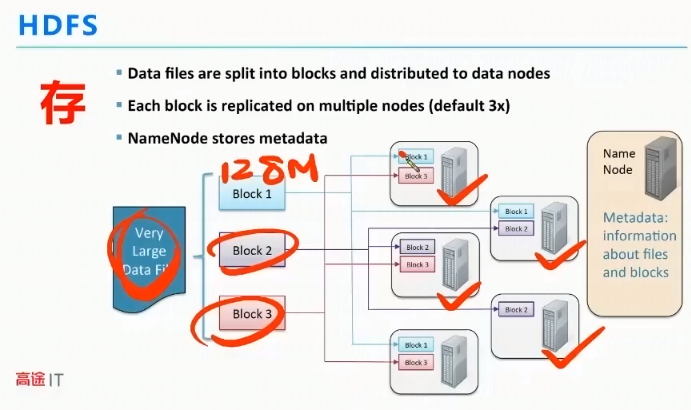
多副本还有一个好处就是可以分布式计算
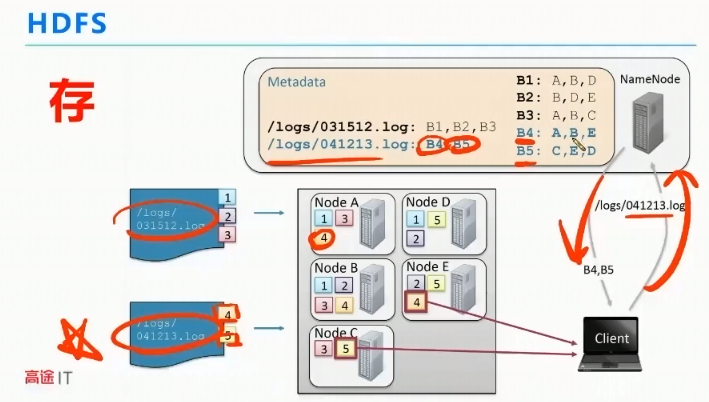
副本是怎么放的:
首先,客户端会挑选一个离客户端近的节点,然后再选一个跟第一个节点不同的服务器下的空闲节点(发起挑选第二个节点的是第一个副本的集群),第二个副本为了效率,会找一个同一机架下的另外一个空闲节点。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DJ8ettH7-1652168221131)(C:/Users/MSI-NB/AppData/Roaming/Typora/typora-user-images/image-20220508223259757.png?lastModify=1652154537)]
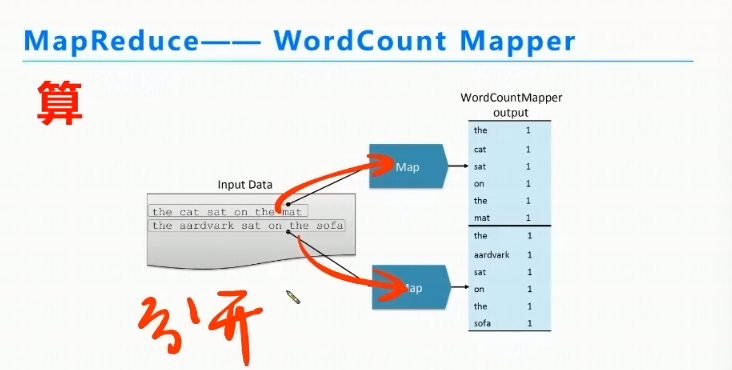
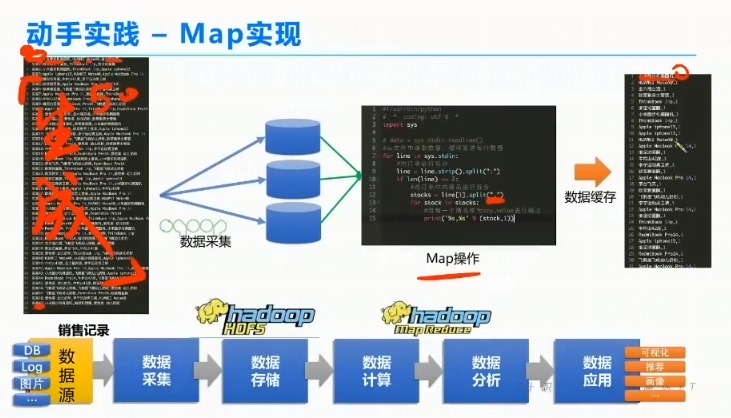
MapReduce的Map阶段
计算的时候一个数据量过大及会通过map分给不同的节点。并把数据变成(the,1)二元组的格式
MapReduce的shuffle&sort
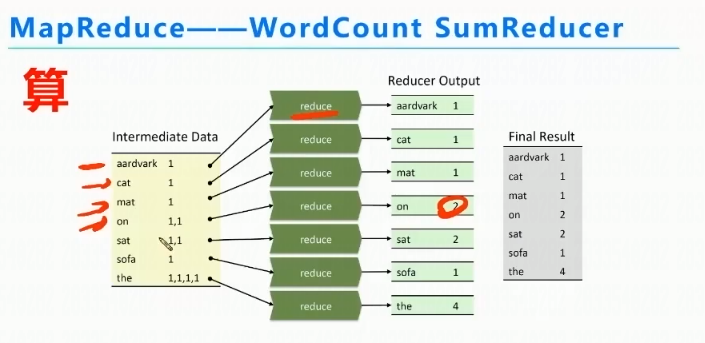
将相同的key分成相同的组,

MapReduce的Reduce阶段
相同的key,合并对应的value
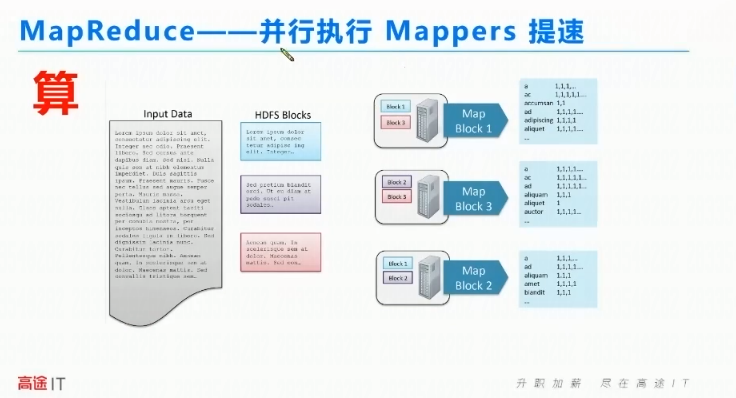
MapReduce 的并行执行,Mappers提速
MapReduce—应用案例:网页访问延迟分析
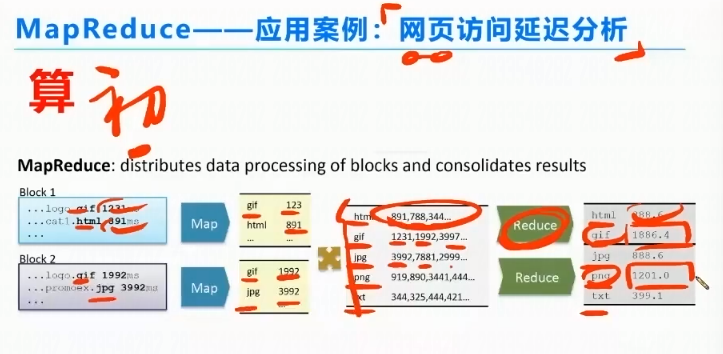
统计网页中部分访问的时长;
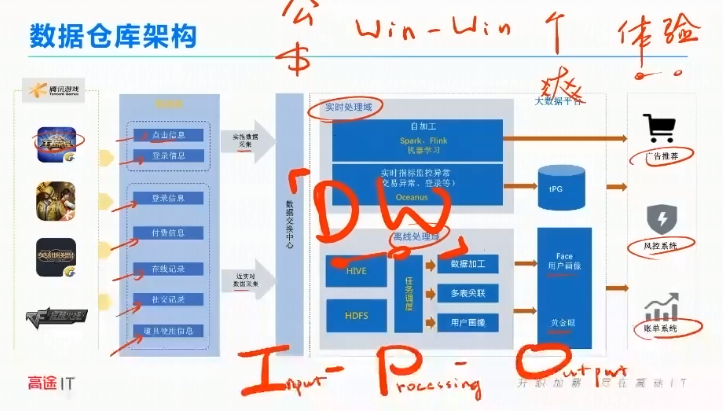
大数据的架构模型永远遵循I-P-O模型
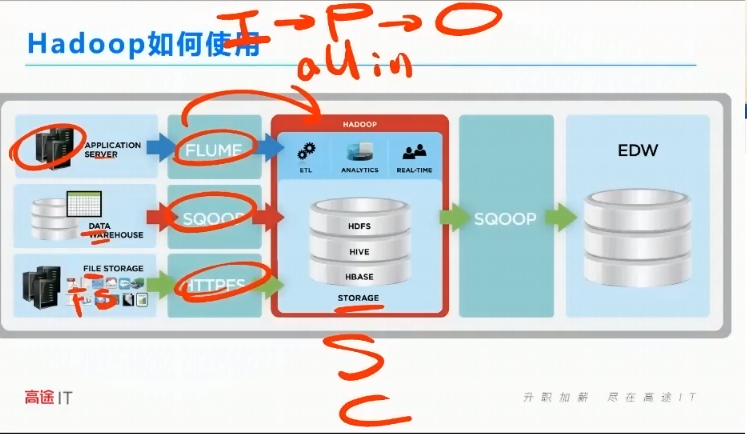
输入-计算-输出
技术:是一个习得的东西,自行车,一样,一旦学会终生受益。

二、离线数仓搭建哪些你不知道的点
1、数据仓库定义及演进史
2、数据仓库及核心概念
3、数据仓库建模流程讲解
4、走进大厂数据仓库搭建案例
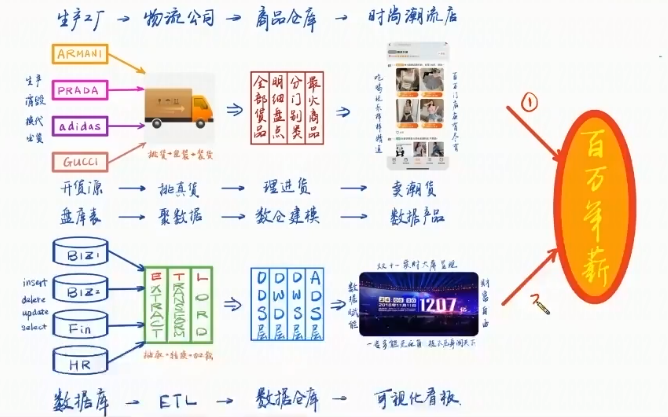
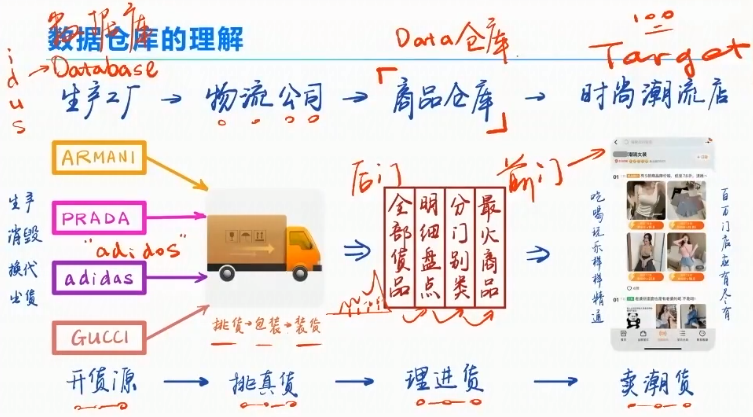
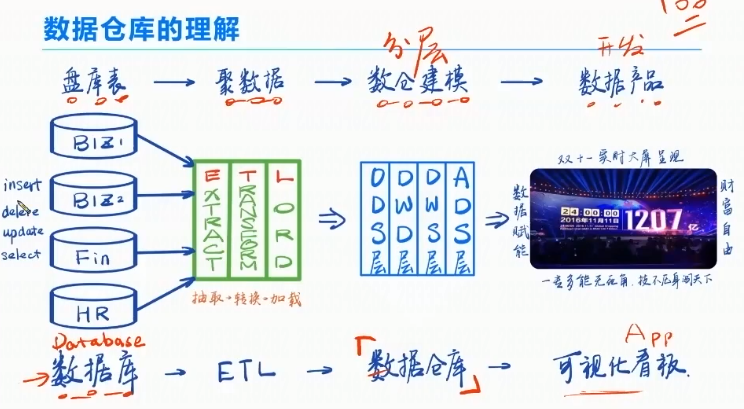
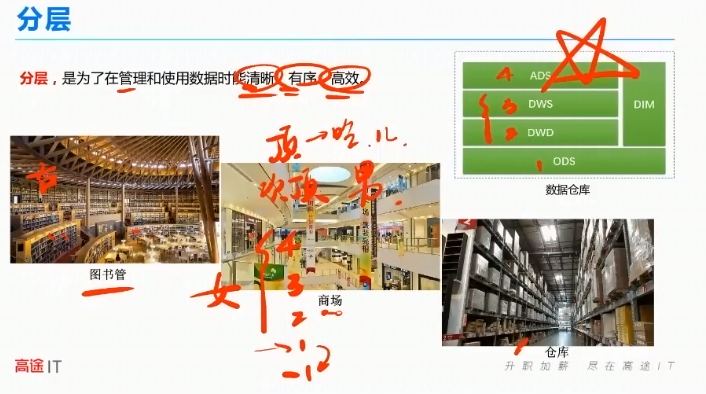
数据仓库类似于:
淘宝开时尚潮流店,流程:生产工厂、物流公司、商品仓库、时尚潮流店。
数仓的流程:数据库、ETL、数据仓库、可视化看板。
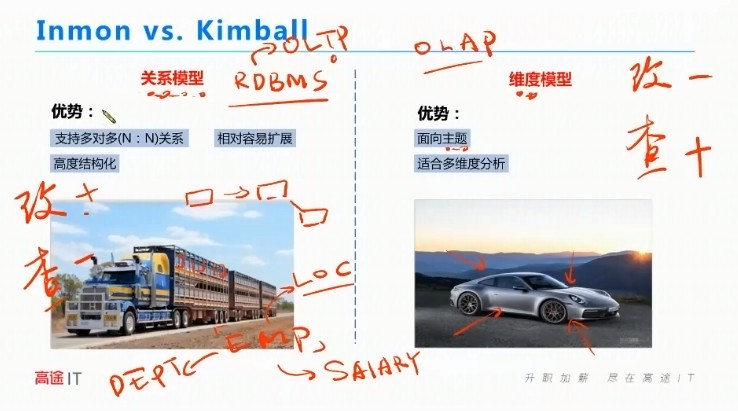
模型:E-R、维度
E-R:支持多对多(N:N)关系 相对容易扩展 高度结构化
维度模型:面向主题、适合多维度分析。
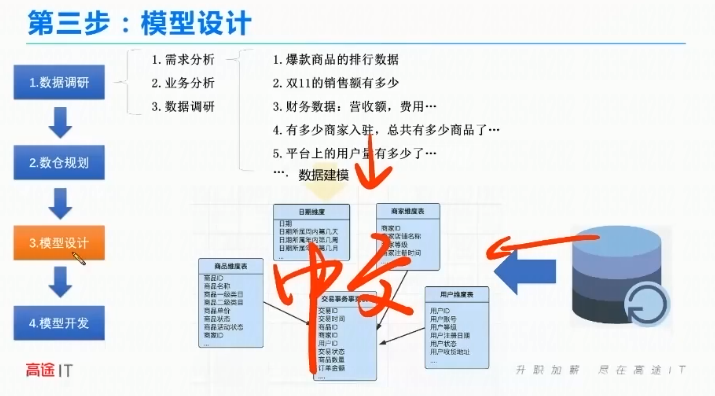
概念模型、逻辑模型、物理模型
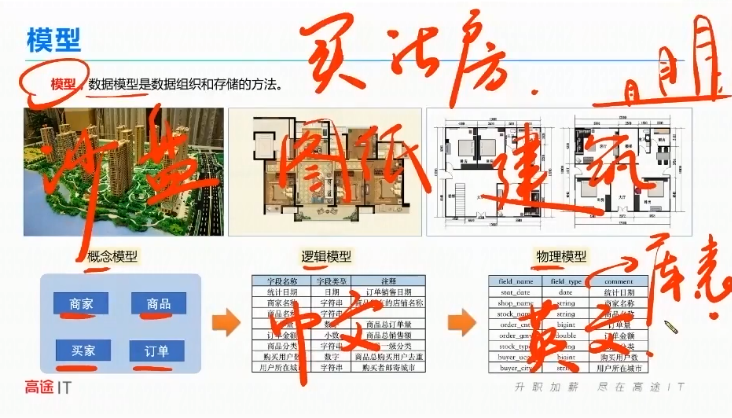
概念模型:可以看到整体规划小区有哪些功能区:商家、商品、买家、订单
逻辑模型:类似于图纸,显示生活中卖房子的户型图,对应中文字段信息
物理模型:煤火电是怎么走的。对应,英文库表
分层
分层:是为了在管理和使用数据时能清洗、有序、高效。
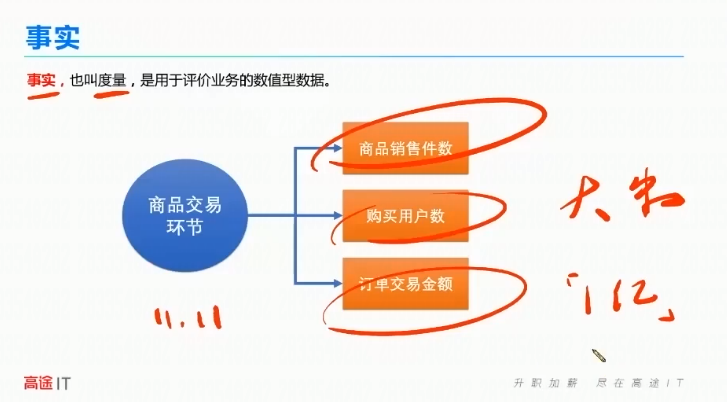
事实表:
也叫度量,使用户评价业务的数据值型数据。是原子指标,不能再分的。
维度:
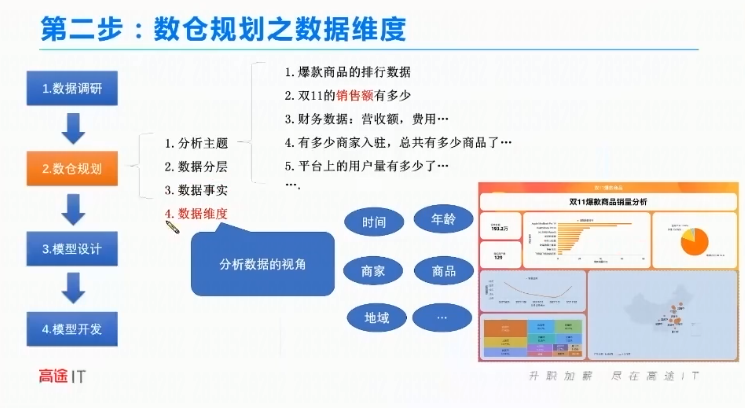
数据观察的角度,验证指标。

事实,我想找个女朋友是一个实时。维度,我想找个什么样的,身高,体重,年龄等


数据调研
需求调研
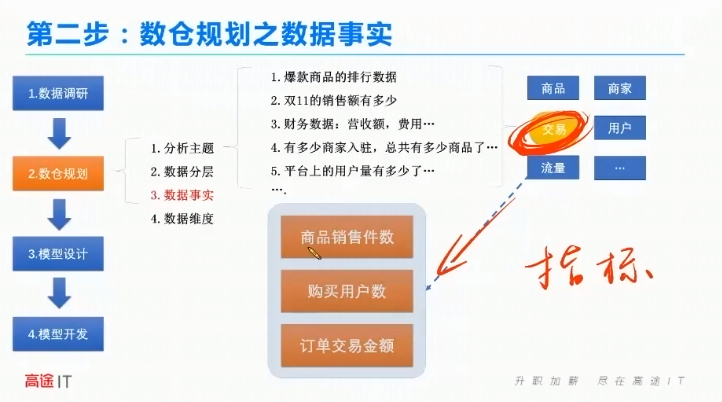
数据产品经理做的。1、爆款商品的排行数据。2、双11的销售额有哪些。3财务数据:营收额,费用。4有多少商家入驻,总共有多少商品了。5平台上的用户量有多少。
数仓建模:慢就是快。
业务调研:
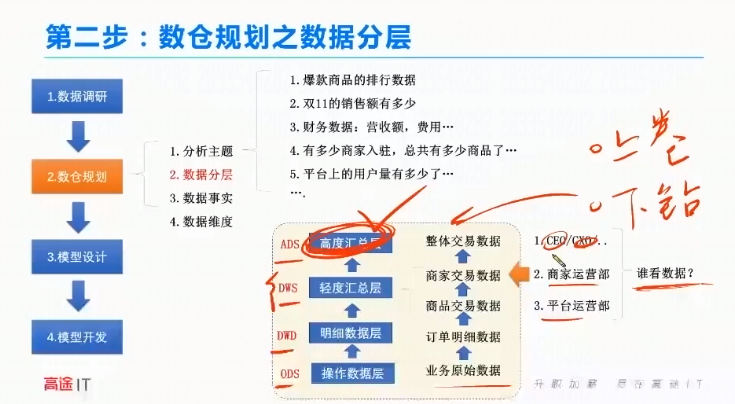
看数据都有谁看,商家产品部,平台运营部,CEO…。
数据调研:
数据是怎么产生的:1.商品购买流程。2.线上活动流程。3.客服售后流程
数据长什么样?1、有哪些数据库,数据表。2、有哪些字段,字段含义,字段类型。3.数据的更新方式,更新时间。
数仓规划
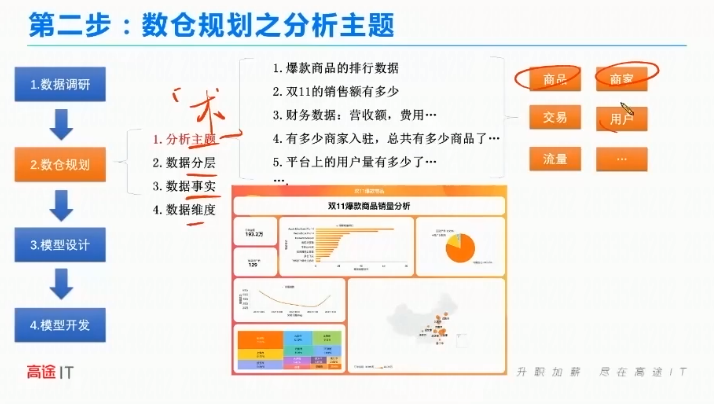
分析主题
数据分层
数据事实
数据维度
第三步:模型设计
星型模型,雪花模型
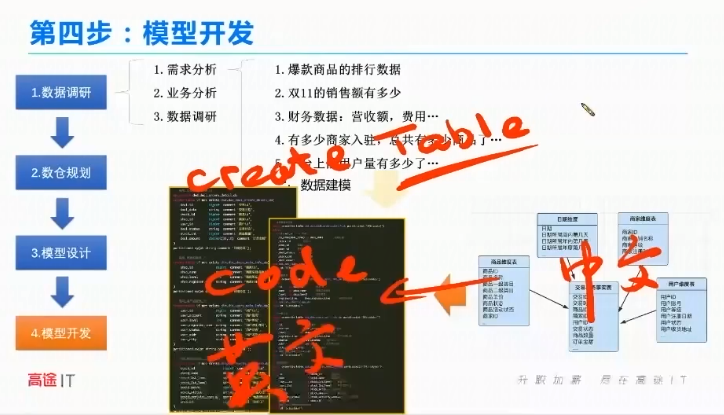
第四步:模型开发
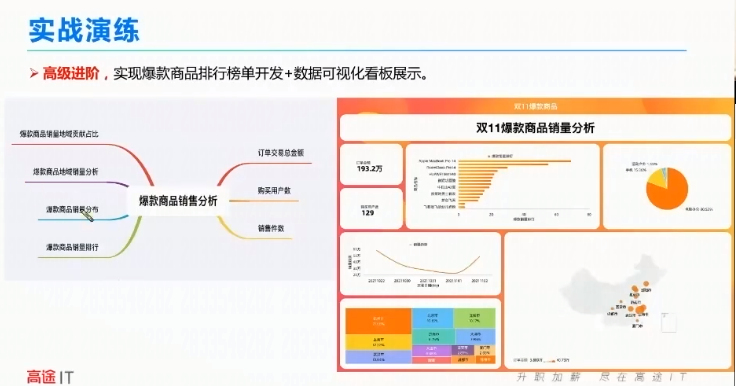
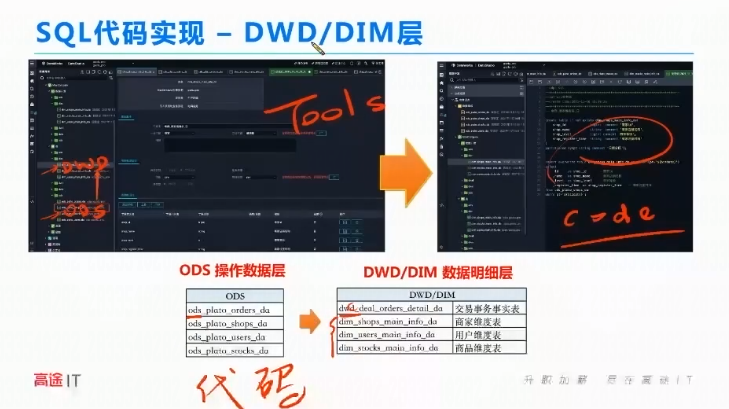



三、带你走出实时数据计算的坑
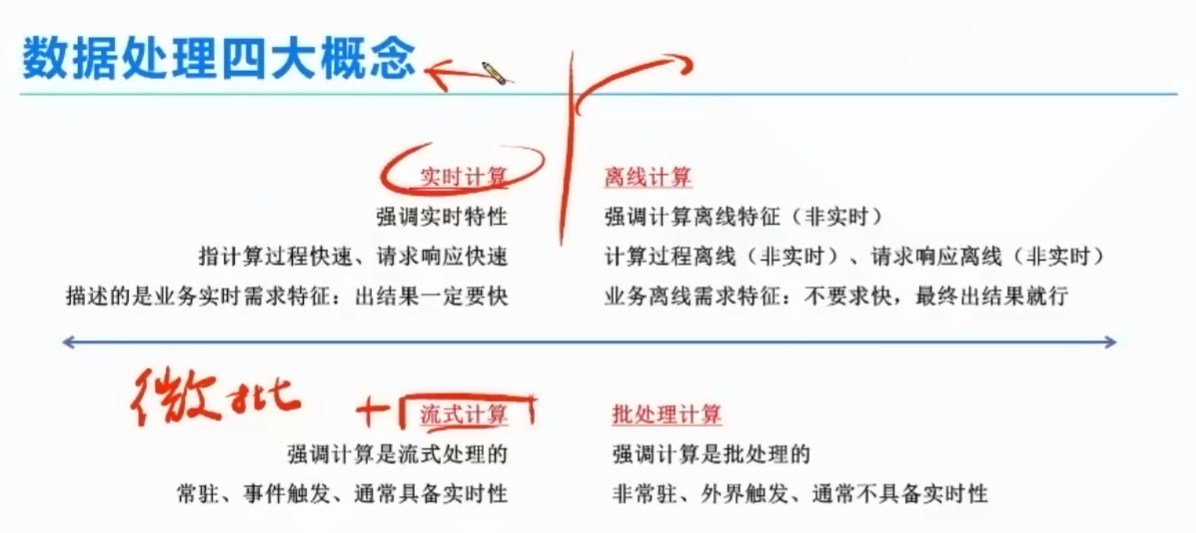
实时计算:
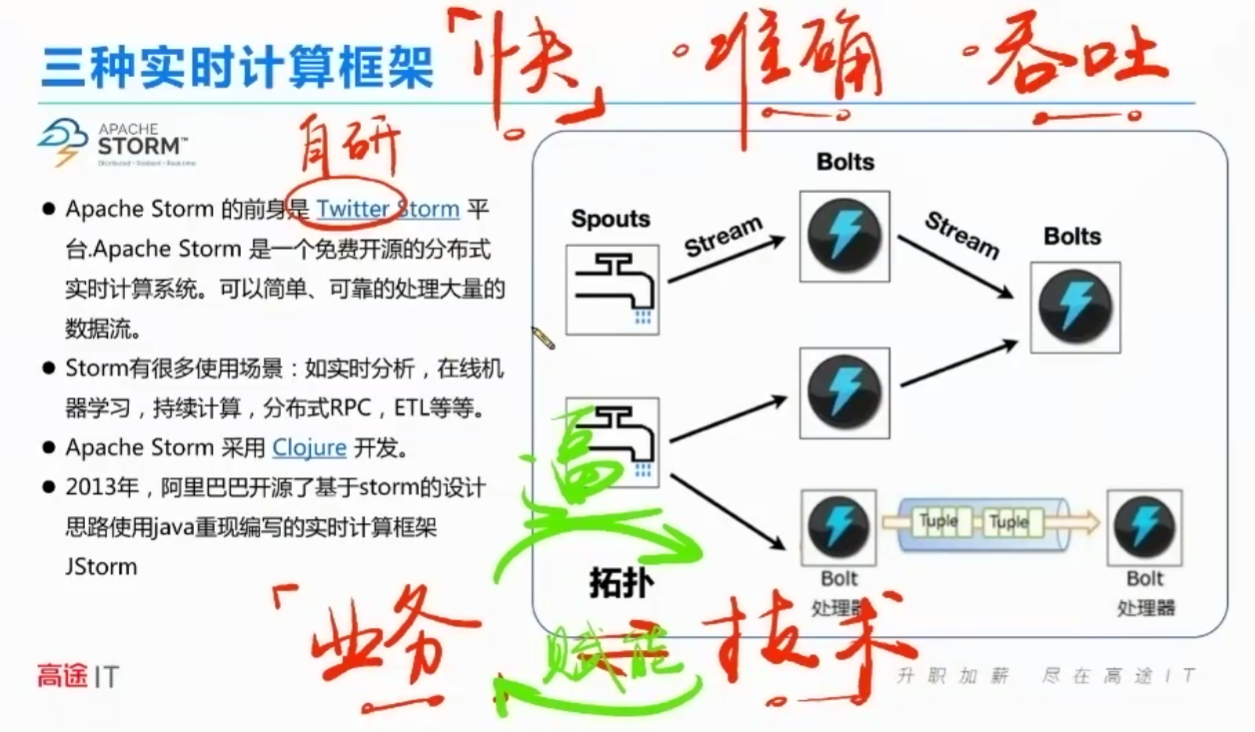
STORM
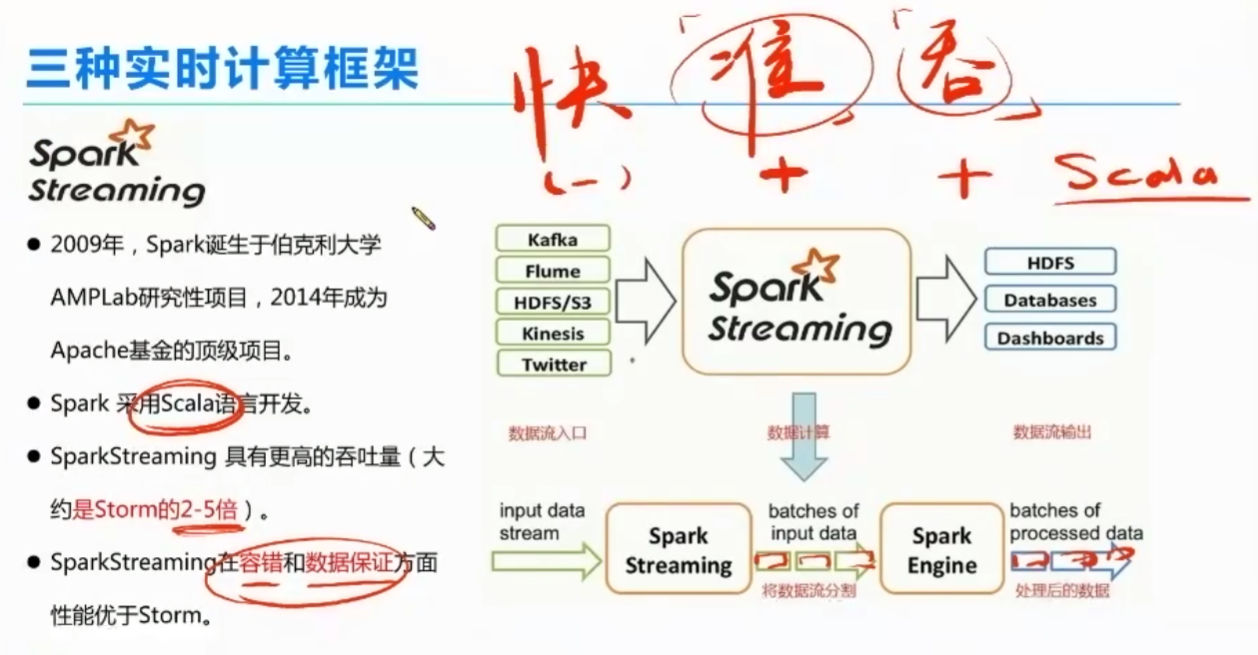
SPARK STREAME
FLINK
实时大屏;

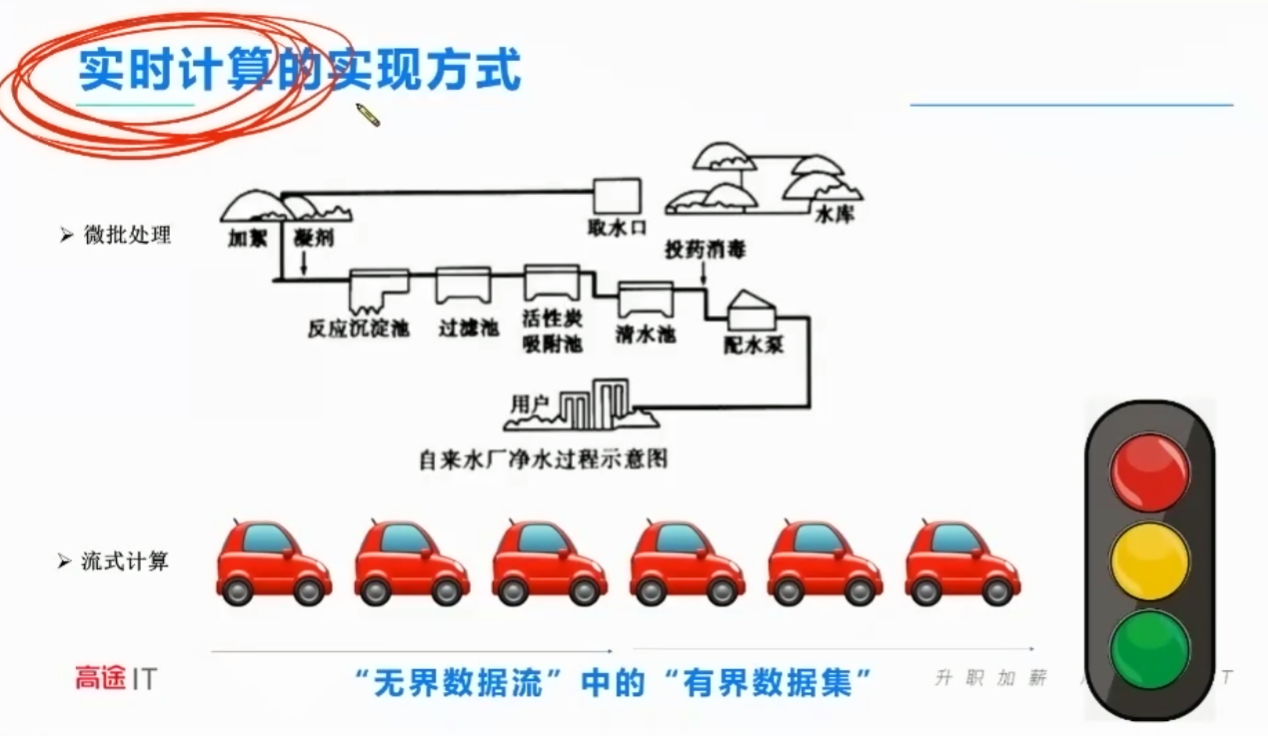
小汽车绿灯状态下,就是流式,源源不断的进去。
直饮机。直接来了过滤,没有等一等。
车流的例子也能
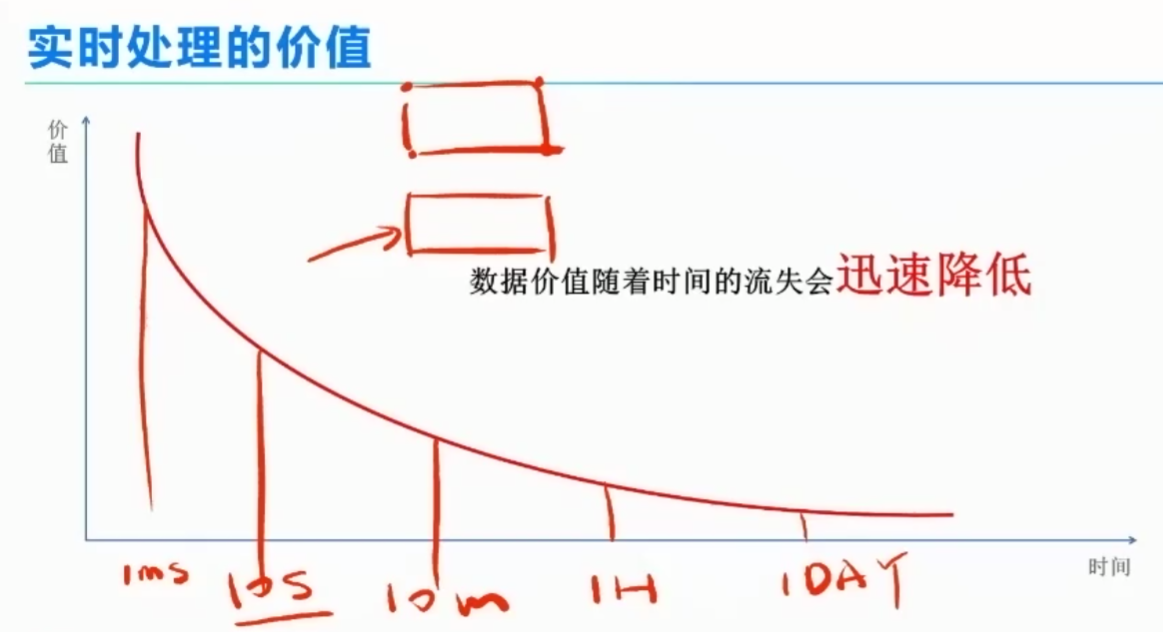
当接到电话的时候同时收到防诈骗的短息。

车路协同
机场高速,实时技术,摄像头,实现快速扣费,极大的提升了通信效率,无感通行。提升出行体验。
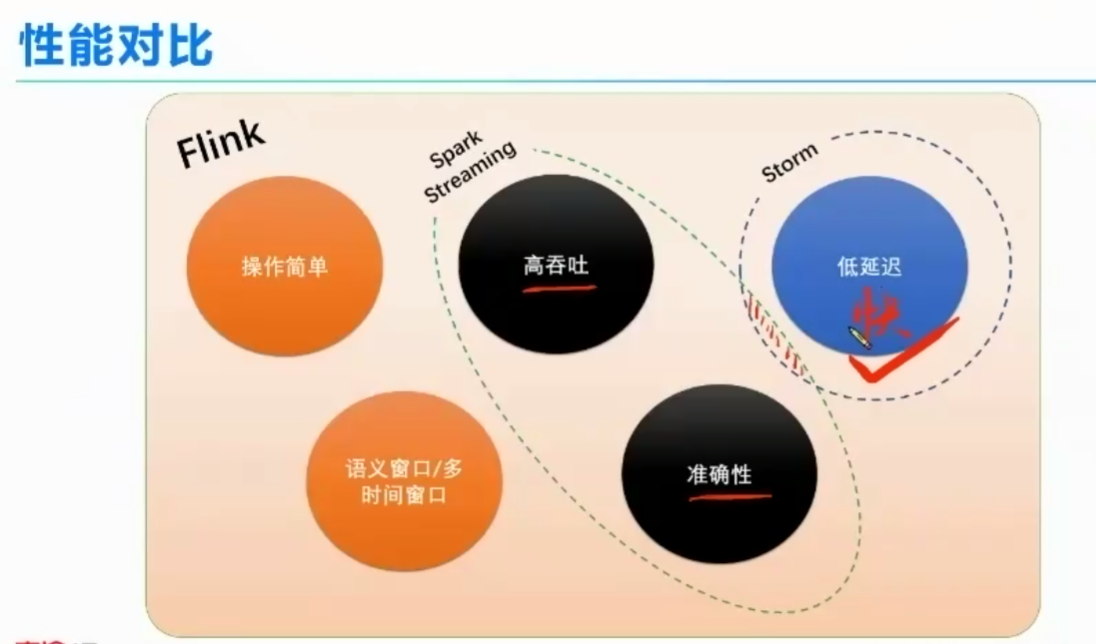
2、三大实时计算框架比较。
spark streaming :
storm 快、准确不强,吞吐能力有限。Twitter 自研的
flink
flink:
快速灵动;
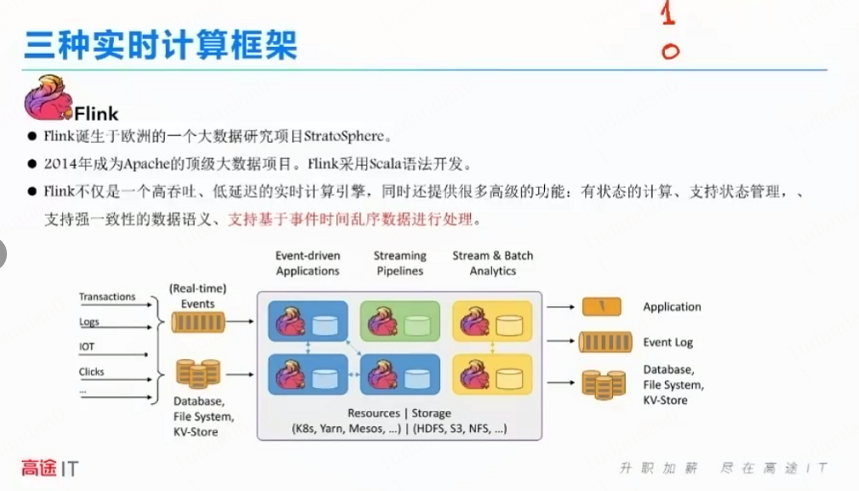
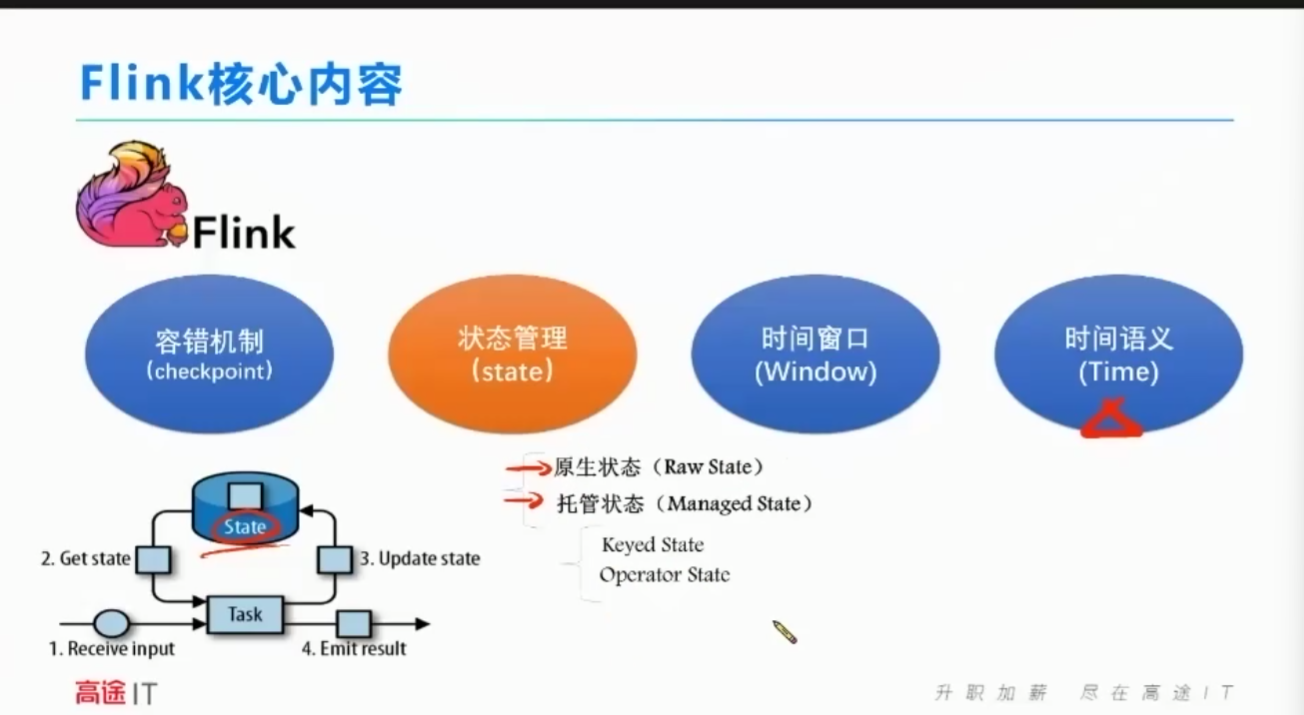
4大根技术
容错机制:一个一个栅栏分一段一段的。
状态管理
时间窗口
时间语义
2
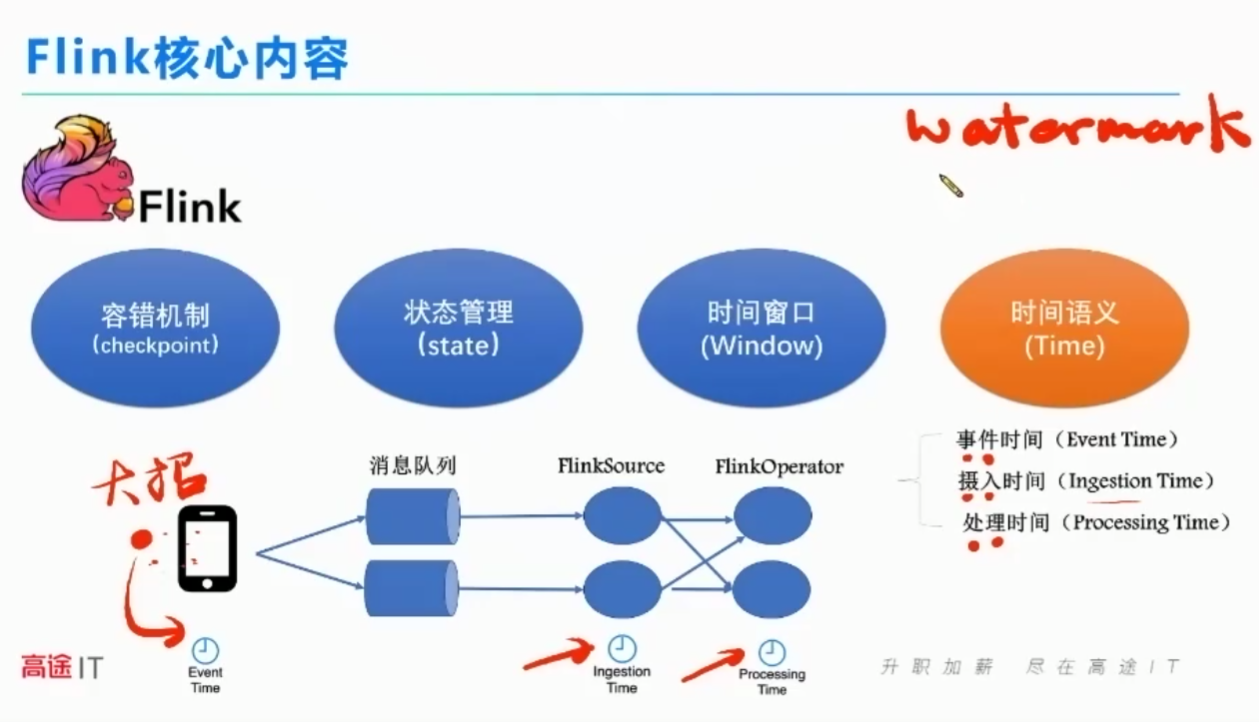
等等我让我数清楚:
核酸检测:等等我,可能比我早捅,但是检测时间比较晚
“无界数据流”中的“有界数据集”:
数车流:不管是按照时间3秒数、还是三辆数。分段数的对象就是有界数据集