大数据面试之HDFS常见题目
HDFS常见题目
1 HDFS读流程和写流程
1.1 读流程(下载)
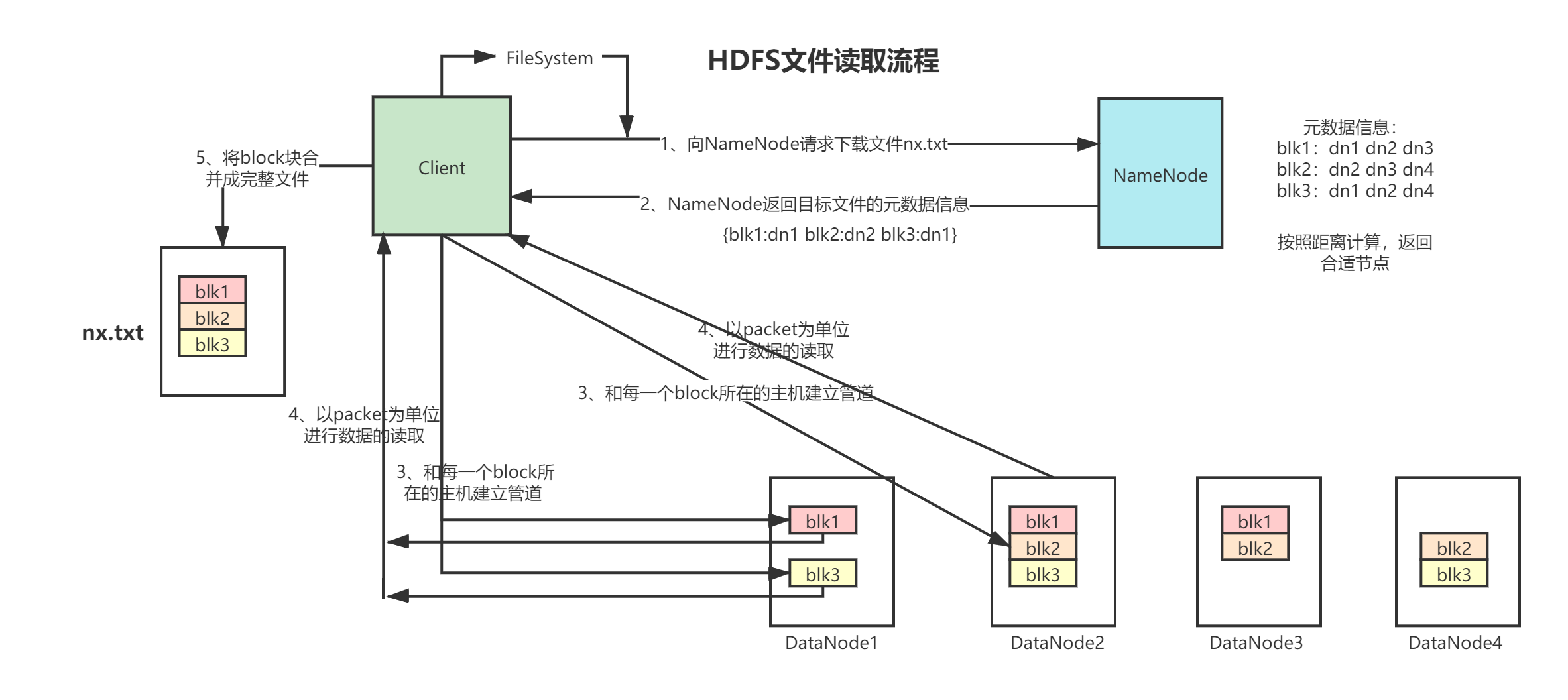
文字描述:
客户端将要读取的文件路径发送给 NameNode,NameNode 获取文件的元信息(主要是 block 的存放位置信息)返回给客户端,客户端根据返回的信息找到相应 DataNode 逐个获取文件的 block 块 ,并在客户端本地进行数据追加合并,从而获得整个文件。
1.2 写流程(上传)
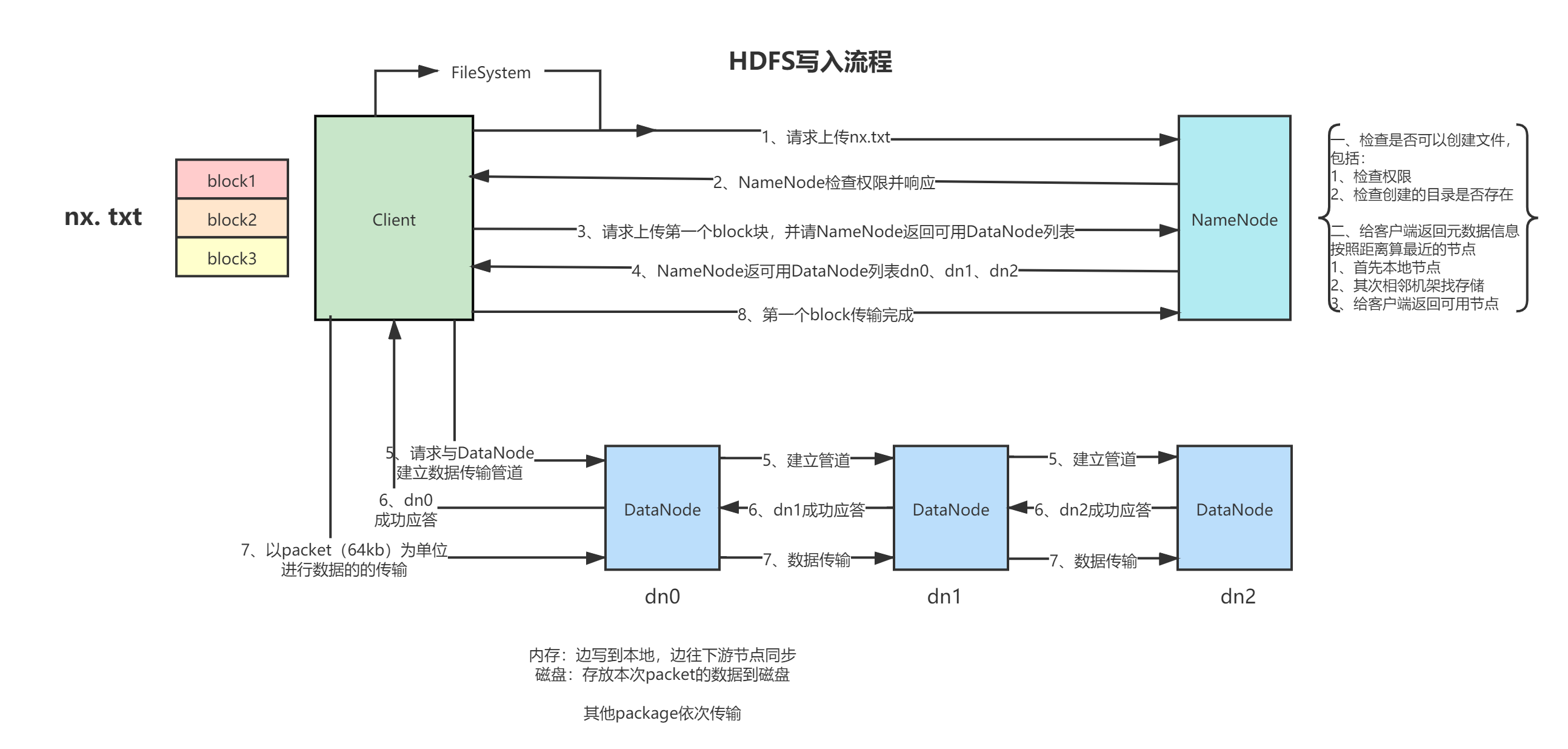
文字描述:
客户端要向 HDFS 写数据,首先要跟 NameNode 通信以确认可以写文件,并获得接收文件 block 的 DataNode ,然后客户端按顺序将文件逐个 block 传递给相应 DataNode ,并由接收到 block 的 DataNode 负责向其他 DataNode 复制 block 的副本
1、 Client 发写数据请求
2、 NameNode 响应请求,然后做校验工作,如果能上传该数据,则返回该文件的所有切块信息应该被存在哪些 DataNode 上的 DataNodes列表,例如下面的情况:
blk-001:hadoop02 hadoop03
blk-002:hadoop03 hadoop04
3、 Client 拿到 DataNode 列表之后,开始传数据
4、 首先传第一块 blk-001,DataNode 列表就是 hadoop02 hadoop03,client 就把 blk-001 传到 hadoop02 和 hadoop03 上
5、 以此类推,用传第一个数据块同样的方式传递其他的数据块
6、 当所有的数据块都传完之后,Client 会给 NameNode 返回一个状态信息,表示数据已全部写入成功,或者是写入失败的信息。
7、 NameNode 接收到 Client 返回的状态信息来判断当次写入数据的请求是否成功,如果成功,就需要更新元数据信息。
2 HDFS小文件处理
1、小文件有什么影响?
在大数据的场景下,从海量数据的存储和计算两方面来分析:
其实还有数据传输层面。
(1)存储层面:
主要是耗费NameNode的内存存储,因为不论你存储的文件多小,都会在NameNode中占用150 byte 左右的元数据存储空间,那这样的话,如果大量的小文件会消耗掉NameNode的内存空间。例如下面的计算示例:
1个文件块,占用NameNode内存150字节
那么128G能存储多少文件块?计算公式:128 * 1024 * 1024 * 1024 byte / 150 byte = 9亿文件块左右
上面算出来的是理论上,128G的内存可以管理的数据的大小为:128m * 9亿
但是如果是大批量的小文件,而且没有进行优化处理的话,一个小文件也是占用 150 字节的元数据信息存储空间,那么也就意味着NameNode的128G的内存实际管理的数据大小会严重的缩减 。
(2)计算层面:
默认切片规则是每个文件单独切片,所以每个小文件哪怕是1字节都会起到一个MapTask,而每个MapTask占用的内存是1G,这样就占用了大量计算资源。
2、小文件怎么解决?
(1)har归档方式
将小文件归档。就是给多个小文件打包放到一起统一进行处理,这样的话在元数据存储和计算方面都能得到优化。
举个生活中的例子:大家在电商网站购物,在同一家店铺购买了10个商品,你觉得店家会给发10个快递吗?基本上不会发10个快递,会给10个商品进行打包合并,最后可能是一两个快递过来。
(2)采用CombineTextInputFormat
帮所有的文件放到一起统一进行切片。
别管多少个文件,都放到一起,这样就避免了一个字节开启一个MapTask了。
(3)开启JVM重用
有小文件场景开启JVM重用;如果没有小文件,不要开启JVM重用,因为开启之后会一直占用使用到的task slot卡槽,直到任务完成才释放。
JVM重用可以使JVM实例在同一个job中重新使用N次,N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间
<property><name>mapreduce.job.jvm.numtasks</name><value>10</value><description>How many tasks to run per jvm,if set to -1,there is no limit</description>
</property>
3 HDFS副本数
默认是3个,可以根据数据的重要度进行设置
4 HDFS默认块大小
| 场景 | 大小 |
|---|---|
| 1.x | 64M |
| 2.x、3.x | 128M |
| 本地模式调试 | 32M |
| 企业 | 128M/256M/512M |
那么怎么选择块大小?取决于硬盘的读写速度
普通机械硬盘,假设读写速度是 100m/s ,选择块大小是128M即可
普通固态硬盘,假设读写速度是 300m/s ,选择块大小是256M即可
高级固态硬盘,假设读写速度是 600m/s ,选择块大小是512M即可
更多题目后续会随着时间陆续补充
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博: http://weibo.com/luoyepiaoxue2014 点击打开链接





![[附源码]Python计算机毕业设计SSM基于社区人员管理系统(程序+LW)](https://img-blog.csdnimg.cn/2c924641d0814e8297191bb0c381c22e.png)