写在前面:
本篇文章基于linux系统Centos7环境下进行搭建、操作
仅作为学习参考借鉴,欢迎大家交流学习!
一、 HDFS安装搭建
1.1 关闭虚拟机防火墙
在之后的学习、操作中,经常会遇到在宿主机中通过程序去访问虚拟机中的相关软件,但是默认情况下,虚拟机的防火墙是不允许访问,这是需要开启一个一个的端口号,比较麻烦,所以在教学过程中,为了提高教学、学习的效率,直接关闭虚拟机的防火墙。(注意在实际的生产环境中不可以,在生产环境中通常是通过关闭端口实现的)
防火墙相关指令:
启动:systemctl start firewalld
关闭:systemctl stop firewalld
重启:systemctl restart firewalld
查看防火墙状态:systemctl status firewalld / firewall-cmd --state
在开机时启用防火墙:systemctl enable firewalld
在开机时禁用防火墙:systemctl disable firewalld
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VLo0DZ3f-1686196488445)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608113951632.png)]](https://img-blog.csdnimg.cn/d9fcc5f2a7e64c71b59c07d73f35cfd3.png)
1.2 配置hosts文件
命令:vi /etc/hosts
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J4768PaG-1686196284765)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608113959404.png)]](https://img-blog.csdnimg.cn/4fb4b8da615b41cca885ac7774d2b553.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dqNkAG8I-1686196284765)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114004123.png)]](https://img-blog.csdnimg.cn/f75b492d9d434459a40a4f6bdda7c946.png)
注:配置文件中的“hadoop”根据实际用户填写
1.3 配置免密登陆
命令:ssh-keygen -t rsa
然后一直回车,直到出现:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lv9ekx48-1686196284765)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114009160.png)]](https://img-blog.csdnimg.cn/b7acf778d8394eed89362abaf24a9af3.png)
注:(方框中的图案每个虚拟机都不相同)
此时,会产生两个文件 id_rsa(私钥) id_rsa.pub(公钥),生成节点的公钥和私钥,生成的文件会自动放在/root/.ssh目录下
第二步:执行:ssh-copy-id root@hadoop
此处hadoop其实就是hosts文件中ip的映射,这一步实际上是将公钥拷贝到
/root/.ssh/authorized_keys 这个文件里(等同于cp id_rsa.pub authorized_keys #拷贝公钥到ssh文件)
格式化成功截图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XuoGBC2N-1686196284766)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114019422.png)]](https://img-blog.csdnimg.cn/55cf7223ebbb4519b728b041822157e2.png)
1.4 上传jdk和hadoop安装包
将jdk和hadoop的安装包上传到虚拟机
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7tDX7f7G-1686196284766)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114028771.png)]](https://img-blog.csdnimg.cn/ae7be409d6a74f228bd692c167dfdbe9.png)
方式一(有网络连接):
直接使用yum源安装rz
命令: yum install lrzsz
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RjbWhshb-1686196284766)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114033924.png)]](https://img-blog.csdnimg.cn/d544fc722dfc425393807a5cabee3e32.png)
方式二:使用filezilla上传安装包
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K8iThXac-1686196284767)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114038441.png)]](https://img-blog.csdnimg.cn/4cc4e4b7a36344ea862ffaa2aae62255.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ho6YFT0F-1686196284767)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114111289.png)]](https://img-blog.csdnimg.cn/df7d6949c7644c9e8fb45bbf9ac10759.png)
1.5 安装配置JDK
1 解压安装包
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ANqjfVJO-1686196284767)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114116320.png)]](https://img-blog.csdnimg.cn/31bf44fc481041d48f369105dee5f64b.png)
注:这里输入方式为tar -xvf jdk “tab”,会自动补全
2 重命名目录(可选操作)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jN6FrVYj-1686196284767)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114120911.png)]](https://img-blog.csdnimg.cn/7de51572dff549358ba81dafeed97d69.png)
3 设置环境变量
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fsy8KMqO-1686196284768)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114124166.png)]](https://img-blog.csdnimg.cn/463e7a60a97c4e85b33297f0ae1c5aea.png)
在文件尾添加:
export JAVA_HOME=/software/jdk1.8
export PATH= J A V A H O M E / b i n : JAVA_HOME/bin: JAVAHOME/bin:PATH:$HOME/bin
export CLASSPATH=.: J A V A H O M E / l i b / d t . j a r : JAVA_HOME/lib/dt.jar: JAVAHOME/lib/dt.jar:JAVA_HOME/lib/tools.jar

注:该截图Java_home文件目录多/home
保存退出,利用命令使配置立即生效 source /etc/profile

利用命令查看jdk版本信息,检验jdk的安装配置是否成功

1.6 安装配置hadoop
1.解压安装包
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zxF6d47q-1686196284769)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114142324.png)]](https://img-blog.csdnimg.cn/de087a0ee63e4d14a30eaf7850d668de.png)
2.配置环境变量
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IcDtpfYg-1686196284769)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114203824.png)]](https://img-blog.csdnimg.cn/0f8a8daff1f440ec91ddf1c34a20aa1c.png)
export HADOOP_HOME=/software/hadoop2.6
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH:$HOME/bin
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IpYsp69N-1686196284769)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114223595.png)]](https://img-blog.csdnimg.cn/ee7add62074a41caae2302f979f0fc61.png)
该截图hadoop_home文件目录多/home
source /etc/profile 使其立即生效
3. 配置hadoop-env.sh
vim /software /Hadoop-2.7.3/etc/hadoop /hadoop-env.sh
export JAVA_HOME=/software/jdk1.8 #必须配置(25行)
export HADOOP_CONF_DIR=/software/hadoop2.6/etc/hadoop (33行)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b0rCl8hq-1686196284769)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114238168.png)]](https://img-blog.csdnimg.cn/ca967bd38a5d4785ab6467ed2d620b3b.png)
(之所以配置路径是因为自带的往往定位不到,会发生某些错误)
注:该截图文件目录多/home
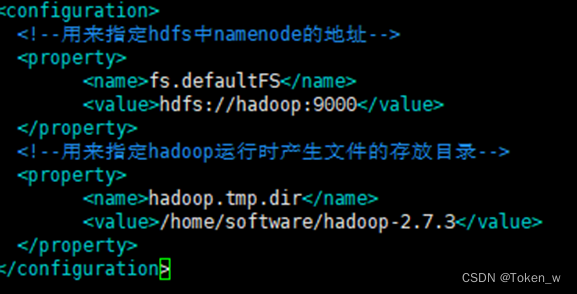
4.配置core-site.xml
vim /software /Hadoop-2.7.3/etc/hadoop/core-site.xml
在<configuration>标签添加:
<configuration>
<!--用来指定hdfs的namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/software/hadoop-2.7.3/tmp</value>
</property>
</configuration>
5. 配置hdfs-site.xml
vim /software /Hadoop-2.7.3/etc/hadoop/hdfs-site.xml
在**<configuration>**标签添加:
<configuration>
<!-- 指定hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 关闭hdfs权限检查 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rZ5gjaU0-1686196284770)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114340004.png)]](https://img-blog.csdnimg.cn/473926ab9d884969a0729f9d84419db0.png)
【注】:
dfs.replication默认是3,此处我们只需要伪分布式,所以设置为1即可;
dfs.permissions 设置为false代表所有用户都可以在hdfs上操作文件,这只是为了以后利用eclipse的hadoop插件上传下载文件方便
6. 配置mapred-site.xml
此文件原本不存在,只有一个模板文件mapred-site.xml.template
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0hxItGuQ-1686196284770)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114347260.png)]](https://img-blog.csdnimg.cn/b21934b469a54d7c868d4e817dff0fcb.png)
将其复制一份并改名为mapred-site.xml(注意路径为hadoop2.7.3/etc/hadoop)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5PBLJ9jF-1686196284771)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114350965.png)]](https://img-blog.csdnimg.cn/dba105d525164cfaab71ca092f4e509a.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TIXNmLa9-1686196284771)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114356004.png)]](https://img-blog.csdnimg.cn/e52959afc3084c9293bf662a9efcd6df.png)
vim /software /Hadoop-2.7.3/etc/hadoop/mapred-site.xml
在**<configuration>**标签添加:
<configuration>
<!-- 配置mapreduce作业运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dNHkqJ8X-1686196284771)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114418895.png)]](https://img-blog.csdnimg.cn/843592f96e534a25873854e602e1a9a7.png)
7. 配置yarn-site.xml
vim /software /Hadoop-2.7.3/etc/hadoop/yarn-site.xml
在**<configuration>**标签添加:
<configuration>
<!-- 指定resourceManager的主机 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<!-- reduce任务的数据来源 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YzSMZKhS-1686196284771)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114426771.png)]](https://img-blog.csdnimg.cn/1c9ebfef74c1457f9f2d5b8444cc3c8b.png)
1.7 启动hadoop
此时hadoop已经成功安装配置,在首次启动之前,需要对namenode进行格式化(类似于新买的硬盘需要格式化一样,因为hdfs本身就是一个文件系统)
命令: hdfs namenode -format
以下3个部分一致即格式化成功
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J6FN4ATk-1686196284772)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114438441.png)]](https://img-blog.csdnimg.cn/98e1dcce0f184bbf93c41d9257af3f92.png)
启动hadoop的hdfs:
命令:start-dfs.sh
输入jps,只要出现以下进程即启动成功:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FM4swAC1-1686196284772)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114445011.png)]](https://img-blog.csdnimg.cn/6b26a4ec417b4037b05b48abdf5bb5e7.png)
启动mapreduce:(需要先启动hdfs):
命令:start-yarn.sh
利用jps命令查看进程:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t5lgBF6A-1686196284772)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114450684.png)]](https://img-blog.csdnimg.cn/81f1d5104b91408bb80e51b3923ebd4b.png)
除了jps命令,还可以通过web界面来查看(建议使用google浏览器,同时注意关闭防火墙)
hdfs web界面:
ip地址:50070
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1Rhl2vmF-1686196284772)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114457483.png)]](https://img-blog.csdnimg.cn/20560befbf674ab79672f0bd4b1fd618.png)
mapreduce web界面:
ip地址:8088
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F3ISZGuA-1686196284772)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114502409.png)]](https://img-blog.csdnimg.cn/be9220a48fdf4a6193955b2e291bcceb.png)
以上就是hadoop环境搭建教程,下面如果退出请先stop-all.sh 关闭进程。
二、 Mysql安装,调试
2.1 安装包下载
切换到/software目录(基于本次教程)cd /software
执行下面命令:
wget https://cdn.mysql.com/archives/mysql-5.7/mysql-community-client-5.7.35-1.el7.x86_64.rpm
wget https://cdn.mysql.com/archives/mysql-5.7/mysql-community-common-5.7.35-1.el7.x86_64.rpm
wget https://cdn.mysql.com/archives/mysql-5.7/mysql-community-libs-5.7.35-1.el7.x86_64.rpm
wget https://cdn.mysql.com/archives/mysql-5.7/mysql-community-libs-compat-5.7.35-1.el7.x86_64.rpm
wget https://cdn.mysql.com/archives/mysql-5.7/mysql-community-server-5.7.35-1.el7.x86_64.rpm
下载安装包(直接复制所有命令,输入即可,部分时候可能因为网络问题,多次尝试)
2.2 安装mysql
执行该命令需要联网,注意虚拟机网络连接
yum install -y mysql-community-*-5.7.35-1.el7.x86_64.rpm
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h0Ih0ZfD-1686196284773)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114517931.png)]](https://img-blog.csdnimg.cn/1ecca1c5977e4c46ab61e3a1fd8c11b6.png)
2.3 修改密码
开始mysql服务器并初始化密码
命令:systemctl start mysqld # 开启MySQL服务器
cat /var/log/mysqld.log | grep password # 查看默认初始生成的密码
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FpRyE5qq-1686196284773)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114525175.png)]](https://img-blog.csdnimg.cn/bee172e03fd04b5bb39de568516e8d34.png)
以root用户登陆Mysql
命令:mysql -u root -p
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5CwVVRiz-1686196284773)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114530280.png)]](https://img-blog.csdnimg.cn/466ece2acec6475eb9d24fd645460e74.png)
设置密码等级并修改密码
set global validate_password_length=4;
set global validate_password_policy=0; # 设置密码等级
ALTER USER ‘root’@‘localhost’ IDENTIFIED WITH mysql_native_password BY ‘您的密码’; # 修改默认密码,注意替换后面的密码
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OmPMlYGW-1686196284773)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114537540.png)]](https://img-blog.csdnimg.cn/31060dc9e7a84b24b9fc52c3db2826b8.png)
2.4 创建用户并赋予权限
CREATE USER ‘test’@‘%’ IDENTIFIED BY ‘123456’; #创建“test”用户,设置为允许远程登录
grant all on . to ‘test’@‘%’; #赋予此用户所有数据库的所有权限(增删改查)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IQoMslYg-1686196284774)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114544199.png)]](https://img-blog.csdnimg.cn/423f83f3c9de4b849850deef952f8475.png)
2.5 连接navicat软件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FqPf5Nzk-1686196284774)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114549881.png)]](https://img-blog.csdnimg.cn/de1ccc5e11f34a7eabba86264756f9a6.png)
报错分析:防火墙未关闭
查看防火墙状态:systemctl status firewalld
关闭防火墙:systemctl stop firewalld
永久禁用:systemclt disable firewalld
三、 hive安装,数据筛选
3.1 解压数据包,配置环境变量
tar -xzvf hive-1.1.0-cdh5.4.5.tar.gz -C /opt/ #解压文件
mv hive-1.1.0-cdh5.4.5.tar.gz hive #修改名称vi /etc/profile #修改环境变量
将hive的bin目录,添加到环境变量PATH中,保存退出。
export HIVE_HOME=/opt/hive
export PATH=$HIVE_HOME/bin:$PATH
执行source命令,使Hive环境变量生效。
source /etc/profile
3.2 由于hive 需要将元数据,存储到MySQL中。所以需要拷贝/opt/software目录下的 mysql-connector-java-5.1.26-bin.jar 到 hive 的 lib 目录下。
3.3 下面配置Hive,切换到/opt/hive/conf目录下,创建hive的配置文件hive-site.xml。
cd /software/hive/conf
touch hive-site.xml
使用 vi 打开 hive-site.xml 文件。
vi hive-site.xml
将下列配置添加到 hive-site.xml 中。
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name><value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name><value>123456</value> </property> </configuration>
由于Hive的元数据会存储在Mysql数据库中,所以需要在Hive的配置文件中,指定mysql的相关信息。
javax.jdo.option.ConnectionURL:数据库链接字符串。
此处的主机名,需要设置为自身系统的主机名。这里的主机名为:hadoop
javax.jdo.option.ConnectionDriverName:连接数据库的驱动包。
javax.jdo.option.ConnectionUserName:数据库用户名。
javax.jdo.option.ConnectionPassword:连接数据库的密码。
此处的数据库的用户名及密码,需要设置为自身系统的数据库用户名及密码。
3.4 另外,还需要告诉Hive,Hadoop的环境配置。所以我们需要修改 hive-env.sh 文件。
首先我们将 hive-env.sh.template 重命名为 hive-env.sh。
mv /opt/hive/conf/hive-env.sh.template /opt/hive/conf/hive-env.sh
使用 vi 打开hive-env.sh文件。
vi hive-env.sh
追加 Hadoop的路径,以及 Hive配置文件的路径到文件中。
# Set HADOOP_HOME to point to a specific hadoop install directory # HADOOP_HOME=${bin}/../../hadoop
HADOOP_HOME=/opt/hadoop # Hive Configuration Directory can be controlled by: # export HIVE_CONF_DIR=export HIVE_CONF_DIR=/opt/hive/conf
3.5 下一步是配置MySQL,用于存储Hive的元数据。
schematool -initSchema -dbType mysql
如果出现1045错误或者视频里最后的错误,多半删除数据库再创建就行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-geMSJfwR-1686196284774)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114648939.png)]](https://img-blog.csdnimg.cn/062cf6faeb9c49a98b03e5f4b7ed9332.png)
首先,需要保证 MySQL 已经启动。执行以下命令,查看MySQL的运行状态。
service mysqld status
若没有启动,执行启动命令。
service mysqld start
或者systemctl restart mysqld
3.6 开启MySQL数据库。
mysql -u root -p
输入密码进入数据库
创建名为 hive 的数据库,编码格式为 latin1,用于存储元数据。
mysql> create database hive CHARACTER SET latin1;
查看数据库 hive是否创建成功。
mysql> show databases;
输入exit 退出 MySQL
mysql> exit;
3.7 执行测试。由于Hive对数据的处理,依赖MapReduce计算模型,所以需要保证Hadoop相关进程已经启动。( /opt/hadoop/sbin/start-all.sh )
启动Hadoop后,在终端命令行界面,直接输入hive便可启动Hive命令行模式。
输入HQL语句查询数据库,测试Hive是否可以正常使用。
hive> show databases;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rOllQfcC-1686196284774)(C:\Users\Local\AppData\Roaming\Typora\typora-user-images\image-20230608114658667.png)]](https://img-blog.csdnimg.cn/6c509fd2df4647c09d4b169221766a44.png)
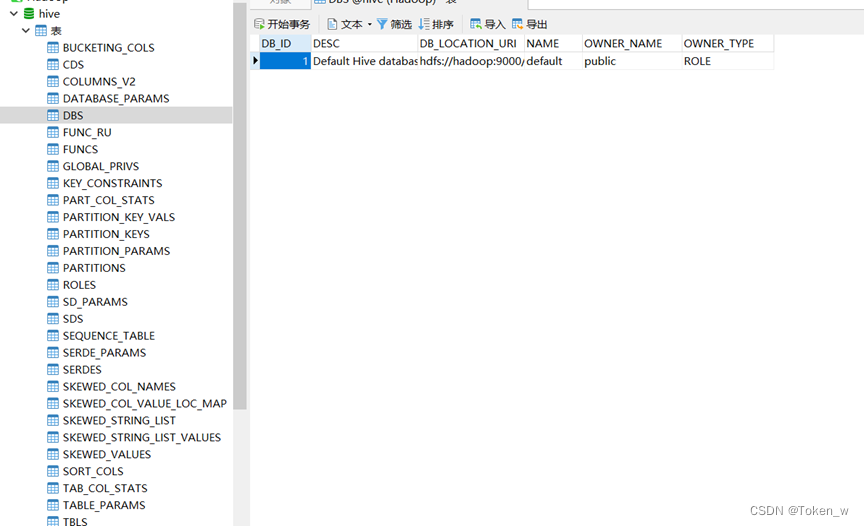
最后全部搭建成功,是左栏的hive库里有如下数据表才可,否则在mysql安装成功和hive失败的情况下,下面左栏是没有数据的。