生成深度学习一直是人工智能前沿的核心思想之一。我们将重点研究卷积神经网络是如何利用迁移学习来思考或对图像中的模式进行可视化的。它们可以生成前所未见的用于描绘卷积神经网络的思考甚至梦境中的图形模式。DeepDream网络于2015年由谷歌公司首次发布,由于深度网络能够从图像中生成有趣的模式,因此DeepDream引起了巨大的轰动。本章的主要内容包括:
- 动机——心理幻想性视错觉;
- 在计算机视觉中的算法幻想性视错觉;
- 通过对CNN的中间层进行可视化,了解CNN学到了什么;
- DeepDream算法以及如何创建自己的dream网络。
和前面几章一样,本章内容会将概念知识和直观的实践例子相结合。本章的代码可以从异步社区的网站获取。
9.1 介绍
在详细介绍神经DeepDream之前,我们先来看看相关的类似经历。你是否尝试过在云层中寻找某个物体的形状,在电视机显示的图像中寻找抖动和嘈杂的信号,甚至在吐司面包上看到一张脸?
幻想性视错觉是一种心理现象。它让我们在一种随机刺激中发现模式,就好像是一种我们感知一张实际上并不存在的脸或模式的倾向。这常常会让我们将人类特征分配给物体。需要注意的是,看到一个不存在的模式(假阳性)相较于看不到一个存在的模式(假阴性)的进化结果的重要性。例如:在没有狮子的地方恍惚间看到狮子并不危险;然而如果忽略了一头正在捕食的狮子,结果通常是致命的。
幻想性视错觉的神经基础主要位于大脑颞叶中一个被称为梭状回的区域。在这个区域中,人类和其他动物有专门用来识别人脸和其他物体的神经元。
9.1.1 计算机视觉中的算法幻想性视错觉
计算机视觉的主要任务之一是目标检测,尤其是人脸检测。现在已经有许多具有人脸检测功能的电子设备能够在后台运行这类算法并检测人脸。那么当我们把导致幻想性视错觉的物体的数据放在这些软件中时会发生什么呢?有时这些软件能用和我们一样的方式解读人脸,有时它可能与我们的想法一致,有时它会产生不一样的结果。
在使用人工神经网络构建的对象识别系统中,越高层次的特征或层对应于越容易识别的特征,如人脸。增强这些特征可以让计算机识别物体。这些特征反映了网络已经识别过的训练图像集合。以Inception网络为例,可以让它预测一些会引起幻想性视错觉的图像中的物体。以图9.1所示的三色堇花为例,这些花有时看起来像一只只蝴蝶,有时又看起来像一张张蓄着浓密胡须的愤怒男人的脸。

图9.1
让我们看看Inception网络模型从图9.1中看到了什么。这里我们使用基于ImageNet数据的预训练的Inception网络模型。为了加载该模型,可以使用代码片段9.1。
代码片段9.1
from keras.applications import inception_v3
from keras import backend as K
from keras.applications.imagenet_utils import decode_predictions
from keras.preprocessing import image
K.set_learning_phase(0)model = inception_v3.InceptionV3(weights='imagenet',include_top=True)为了读取图像文件并将其转换为一个图像的数据批次,即Inception网络模型预测函数的期望输入,我们可以使用以下函数,如代码片段9.2所示。
代码片段9.2
def preprocess_image(image_path):img = image.load_img(image_path)img = image.img_to_array(img)#convert single image to a batch with 1 imageimg = np.expand_dims(img, axis=0)img = inception_v3.preprocess_input(img)return img现在让我们使用前面的方法对输入图像进行预处理,并预测模型看到的对象。我们将使用model.predict()方法获得ImageNet中所有1000个类的预测类概率。为了将这个概率数组转换为真实类标签,并且按概率分数降序排列,我们可以使用Keras类库中的decode_ predict()方法,如代码片段9.3所示。所有1000个ImageNet类或同步集的列表可以在ImageNet网站中查询到。需要注意的是,三色堇花并不包含在已知的模型训练集中。
代码片段9.3
img = preprocess_image(base_image_path)
preds = model.predict(img)
for n, label, prob in decode_predictions(preds)[0]:print (label, prob)预测结果如下所示。所有顶部预测类的概率都不高,由于模型之前从未遇到过这种花,因此这样的结果是符合预期的。
bee 0.022255851
earthstar 0.018780833
sulphur_butterfly 0.015787734
daisy 0.013633176
cabbage_butterfly 0.012270376在图9.1中,模型识别出了一只蜜蜂。这并不是一个很坏的猜测,正如你所看到的,在黄色的花朵中,中间黑色或棕色阴影的下半部分看起来确实像一只蜜蜂。除此之外,它还识别出一些黄色和白色的蝴蝶,被称为黄粉蝶和菜粉蝶(又称菜白蝶),正如人类一眼就能看到的那样。图9.2显示了这些被识别出的对象或类的实际图像。很明显,这个网络中的一些特征检测隐藏层被这个输入激活了。也许是检测昆虫或鸟类翅膀的过滤器和一些颜色相关的过滤器被激活了,从而得出了上述结论。

图9.2
ImageNet架构和其中的特征映射数量非常庞大。假设我们知道检测这些翅膀的特征图层,现在给定一个输入图像,我们可以从这个层中提取特征。我们可以改变输入图像,使这一层的激活增加吗?这意味着我们必须修改输入图像,以便在输入图像中看到更多类似于翅膀的对象,即使它们并不存在。最终的图像将像一个梦境,到处都是蝴蝶,这正是DeepDream的作用。
现在让我们来查看Inception网络中的一些特征映射。为了理解卷积模型学到了什么,我们可以尝试将卷积过滤器可视化。
9.1.2 可视化特征图
对CNN模型进行可视化时,涉及在给定一个特定输入的情况下,查看由多个卷积和池化层输出的中间层特征图。这让我们可以了解网络是如何处理输入,以及如何分层提取各种图像特征的。所有特征图都有3个维度:宽度、高度和深度(通道)。我们将尝试在Inception V3模型中对它们进行可视化。
让我们以一张拉布拉多狗的图片为例,如图9.3所示,接着尝试可视化各种特征图。由于Inception V3模型具有巨大的深度,我们将只对其中的几个层进行可视化。

图9.3
首先,让我们创建一个模型来接收输入图像,并输出所有内部激活层。Inception V3模型中的激活层被命名为activation_i。因此,我们可以从加载的Inception模型中过滤出激活层,如代码片段9.4所示。
代码片段9.4
activation_layers = [ layer.output for layer in model.layers iflayer.name.startswith("activation_")]layer_names = [ layer.name for layer in model.layers iflayer.name.startswith("activation_")]我们来创建一个模型,该模型用于接收输入图像并输出上述所有激活层特征作为列表,如代码片段9.5所示。
代码片段9.5
from keras.models import Model
activation_model = Model(inputs=model.input, outputs=activation_layers)要获得输出激活,我们可以使用predict()函数。我们必须使用之前定义的相同预处理函数来对图像进行预处理,然后再将其输入Inception网络模型,如代码片段9.6所示。
代码片段9.6
img = preprocess_image(base_image_path)
activations = activation_model.predict(img)我们可以绘制前面的这些激活。一个激活层中的所有过滤器或特征图都可以在网格中绘制。因此根据一个层中过滤器的数量,我们可以将图像网格定义为一个NumPy数组,如代码片段9.7所示。
代码片段9.7
import matplotlib.pyplot as pltimages_per_row = 8
idx = 1 #activation layer indexlayer_activation=activations[idx]
# This is the number of features in the feature map
n_features = layer_activation.shape[-1]
# The feature map has shape (1, size1, size2, n_features)
r = layer_activation.shape[1]
c = layer_activation.shape[2]
# We will tile the activation channels in this matrix
n_cols = n_features // images_per_row
display_grid = np.zeros((r * n_cols, images_per_row * c))
print(display_grid.shape)我们在激活层中遍历所有的特征图,并将缩放后的输出置于网格中,如代码片段9.8所示。
代码片段9.8
# We'll tile each filter into this big horizontal gridfor col in range(n_cols):for row in range(images_per_row):channel_image = layer_activation[0,:, :, col *images_per_row + row]# Post-process the feature to make it visually palatablechannel_image -= channel_image.mean()channel_image /= channel_image.std()channel_image *= 64channel_image += 128channel_image = np.clip(channel_image, 0,255).astype('uint8')display_grid[col * r : (col + 1) * r,row * c : (row + 1) * c] = channel_image# Display the gridscale = 1. / rplt.figure(figsize=(scale * display_grid.shape[1],scale * display_grid.shape[0]))plt.title(layer_names[idx]+" #filters="+str(n_features))plt.grid(False)plt.imshow(display_grid, aspect='auto', cmap='viridis')图9.4所示的内容展示了不同层的输出。
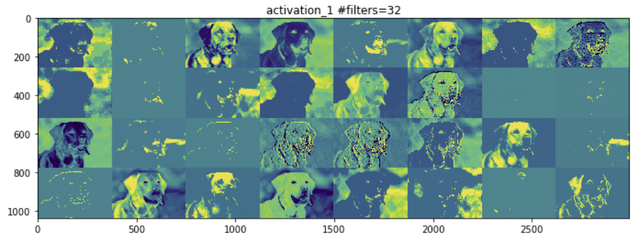
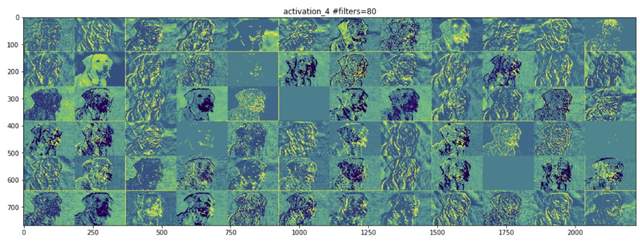
图9.4
图9.5所示的内容展示了网络中间的一个层。此处它开始识别更高层次的特征,如鼻子、眼睛、舌头、嘴巴等。
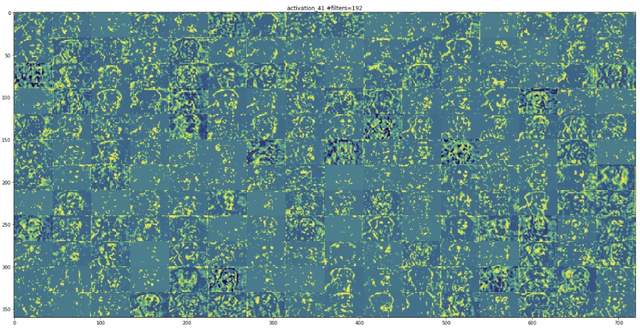
图9.5
越往上走,特征图的视觉解释能力就越差。高层次的激活只携带关于所看到的特定输入的最小信息,以及关于图像的目标类(在这个例子中是一条狗)的更多信息。
另一种对Inception V3模型学习到的过滤器进行可视化的方法是显示每个过滤器输出最大激活值的视觉模式,这可以通过输入空间中的梯度上升来实现。基本上来说就是通过在图像空间中使用梯度上升法进行优化,找到一个兴趣点(一个层中神经元的激活项)激活最大化的输入图像,所得到的输入图像将是选中的过滤器的有最大反应的图像。
每个激活层都有许多特征图。代码片段9.9展示了如何从最后一个激活层提取单个特征图。这个激活值实际上是我们想要最大化的损失值。
代码片段9.9
layer_name = 'activation_94'
filter_index = 0
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])要计算输入图像相对于代码片段9.9中loss函数的梯度,我们可以使用keras后端梯度函数,如代码片段9.10所示。
代码片段9.10
grads = K.gradients(loss, model.input)[0]
# We add 1e-5 before dividing so as to avoid accidentally dividing by
# 0.
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)因此给定一个激活层和一个可以是随机噪声的初始输入图像,我们可以使用上面的梯度计算来应用梯度上升以获得特征图所表示的模式。代码片段9.11中的generate_pattern()函数执行的是同样的操作。输出模式被进行了归一化,因此我们在图像矩阵中就有了可行的RGB值,这个步骤通过使用deprocess_image()方法实现。代码片段9.11是自解释的,同时还有内联注释对每一行进行注释。
代码片段9.11
def generate_pattern(layer_name, filter_index, size=150):# Build a loss function that maximizes the activation# of the nth filter of the layer considered.layer_output = model.get_layer(layer_name).outputloss = K.mean(layer_output[:, :, :, filter_index])# Compute the gradient of the input picture wrt this lossgrads = K.gradients(loss, model.input)[0]# Normalization trick: we normalize the gradientgrads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)# This function returns the loss and grads given the input pictureiterate = K.function([model.input], [loss, grads])# We start from a gray image with some noiseinput_img_data = np.random.random((1, size, size, 3)) * 20 + 128.# Run gradient ascent for 40 stepsstep = 1.for i in range(40):loss_value, grads_value = iterate([input_img_data])input_img_data += grads_value * stepimg = input_img_data[0]return deprocess_image(img)def deprocess_image(x):# normalize tensor: center on 0., ensure std is 0.1x -= x.mean()x /= (x.std() + 1e-5)x *= 0.1# clip to [0, 1]x += 0.5x = np.clip(x, 0, 1)# convert to RGB arrayx *= 255x = np.clip(x, 0, 255).astype('uint8')return x图9.6所示的内容是一些过滤器层的可视化,第一层有各种类型的点模式。

图9.6
本文摘自《Python迁移学习》

迁移学习是一项机器学习(Machine Learning,ML)技术,是指从一系列机器学习问题的训练中获得知识,并将该知识用于训练其他相似类型的问题。
本书有两个主要目的:第一个是我们会将重点集中在详细介绍深度学习和迁移学习,用易于理解的概念和例子将两者进行对比;第二个是利用TensorFlow、Keras和Python生态系统的真实世界案例和问题进行研究,并提供实际的示例。
本书首先介绍机器学习和深度学习的核心概念;接着介绍一些重要的深度学习架构,例如深度神经网络(Deep Neural Network,DNN)、卷积神经网络(Convolutional Neural Network,CNN)、递归神经网络(Recurrent Neural Network,RNN)、长短时记忆(Long Short Term Memory,LSTM)和胶囊网络;然后介绍迁移学习的概念和当前最新的预训练网络,如VGG、Inception和ResNet,我们还将学习如何利用这些系统来提升深度学习模型的性能;最后介绍不同领域(如计算机视觉、音频分析以及自然语言处理)的多个真实世界的案例研究和问题。
读完本书,读者将可以在自己的系统中实现深度学习和迁移学习。