目录
- 高精度自动标注工具简介及其特性
- 标注工具的安装
- 开启自动标注
简介

X-AnyLabeling 是一款全新的交互式自动标注工具,其基于AnyLabeling进行构建和二次开发,在此基础上扩展并支持了许多的模型和功能,并借助Segment Anything和YOLO等主流模型提供强大的 AI 支持。无须任何复杂配置,下载即用,支持自定义模型,极大提升用户标注效率!
AnyLabeling = LabelImg + Labelme + Improved UI + Auto-labeling
特性
目前第一版提供以下功能,后期计划加入多模态大模型,满足更广泛的需求:
- 支持多边形、矩形、圆形、直线和点的图像标注。
- 支持文本检测、识别和KIE(关键信息提取)标注。
- 支持检测-分类级联模型进行细粒度分类。 支持一键人脸和关键点检测功能。
- 支持PaddlePaddle、OpenMMLab、Pytorch-TIMM等主流深度学习框架。
- 支持转换成标准的COCO-JSON、VOC-XML以及YOLOv5-TXT文件格式。
- 提供先进的检测器,包括YOLOv5、YOLOv6、YOLOv7、YOLOv8、YOLOX以及DETR系列模型。

安装
下载和运行可执行文件
整个安装及使用教程都很简单,目前已在Windows系统上编译成可执行软件,可直接在release页面直接下载使用。其他平台可根据以下指令自行打包即可:
- 安装 PyInstaller
pip install -r requirements-dev.txt
- 构建
bash build_executable.sh
请注意,在运行之前,请根据本地conda环境在anylabeling.spec文件中替换’pathex’。
- 移步至目录 dist/ 下检查输出。源码编译安装依赖包
pip install -r requirements.txt
// 生成资源
pyrcc5 -o anylabeling/resources/resources.py anylabeling/resources/resources.qrc
// 运行应用程序
python anylabeling/app.py
SAM的使用
SAM 是 Meta 的新细分模型。使用 11M 图像和 1B 分割掩码进行训练,它可以在不针对特定对象进行训练的情况下分割图像中的对象。出于这个原因,Segment Anything 是自动标记的一个很好的候选框,即使是从未见过的新对象。
使用步骤
- 选择左侧的Brain按钮以激活自动标记。
- 从下拉菜单Model中选择Segment Anything Models类型的模型。模型精度和速度因模型而异。其中,Segment Anything Model (ViT-B)是最快的但精度不高。Segment Anything Model (ViT-H)是最慢和最准确的。Quant表示量化过的模型。
- 使用自动分割标记工具标记对象。
– +Point:添加一个属于对象的点。
– -Point:移除一个你想从对象中排除的点。
– +Rect:绘制一个包含对象的矩形。Segment Anything 将自动分割对象。
– 清除:清除所有自动分段标记。
– 完成对象(f):当完成当前标记后,我们可以及时按下快捷键f,输入标签名称并保存对象。
注意事项
– X-AnyLabeling 在第一次运行任何模型时,需要从服务器下载模型。因此,可能需要一段时间,这具体取决于本地的网络速度。
– 第一次 AI 推理也需要时间。请耐心等待。
后台任务正在运行以缓存 Segment Anything 模型的“编码器”。因此,在接下来的图像中自动分割工作需要时间会缩短,无须担心。
第一个版本支持以下标签工具:
-
图像文本标签
用户可以切换到编辑模式并更新图像的文本——可以是图像名称或图像描述。 -
文本检测标签
当用户创建新对象并切换到编辑模式时,可以更新对象的文本。 -
文本分组
想象一下,当使用 KIE(键信息提取)时,需要将文本分组到不同的字段中,包含标题和值。在这种情况下,你可以使用文本分组功能。当创建一个新对象时,我们同样可以通过选择它们并按G将其与其他对象组合在一起。分组的对象将用相同的颜色标记。当然,也可以按快捷键U取消组合。 -
检测分类模型
这一块相比比较简单。我们主要讲解下如何加载自定义模型,这将使你能够使用自己的模型进行自动标记。如果你有一个已根据自己的数据训练过的自定义模型并希望将其用于自动标记,这将非常有用。此外,还可以创建一个标签 - 训练循环来逐步改进私有模型。通常来说,笔者建议在项目初期阶段可以基于 SAM 利用点或矩阵提示快速完成数据标注,等后期达到一定数据量训练完一个初版模型后再基于检测或检测+分类模型进行一键自动标注。 -
准备模型文件
通常来说,我们首先需要将训练好的模型统一转换成onnx文件格式,以下是第一版支持的版本分支:
yolov5-v6.0+
yolov6-v0.4.0
yolov6Face-v0.4.0
yolov7-main
yolov8-main
yolox-main
如果你是基于以上分支训练并转换得到的onnx文件,可以直接进行后续步骤,否则可能需要修改源码以进行相应的适配。
开启自动标注
-
新建一个文件夹,将上述转换好的onnx权重和对应的配置文件存放到同一目录下。(非必须,但方便管理)
2、 将 yaml 文件中 model_path 字段设置为 onnx 模型所在的绝对路径。 -
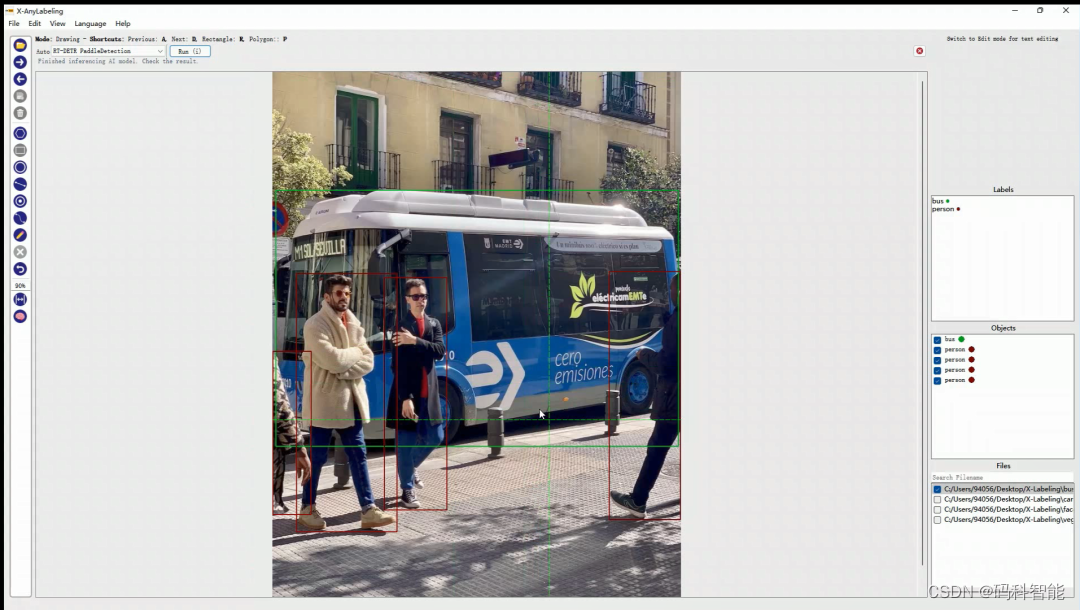
在自动标记模式下,从自动下拉列表中选择加载自定义模型,如图所示:

-
选择相应的配置文件。
-
点击“运行”或按下快捷键i是实现一键标注功能。

源码链接:https://github.com/CVHub520/X-AnyLabeling