最近很多私信都在问机器学习的问题,感觉很多都是刚入门的新手,有些概念和问题也相对比较基础,空余时间里我在不断整理一些常用的基础算法模型,写成文章后面有需要的话可以直接阅读即可,有些问题可能直接就迎刃而解了吧。
这里主要是基于经典的鸢尾花iris数据集来开发构建各种类型的聚类算法模型,首先看下效果图:
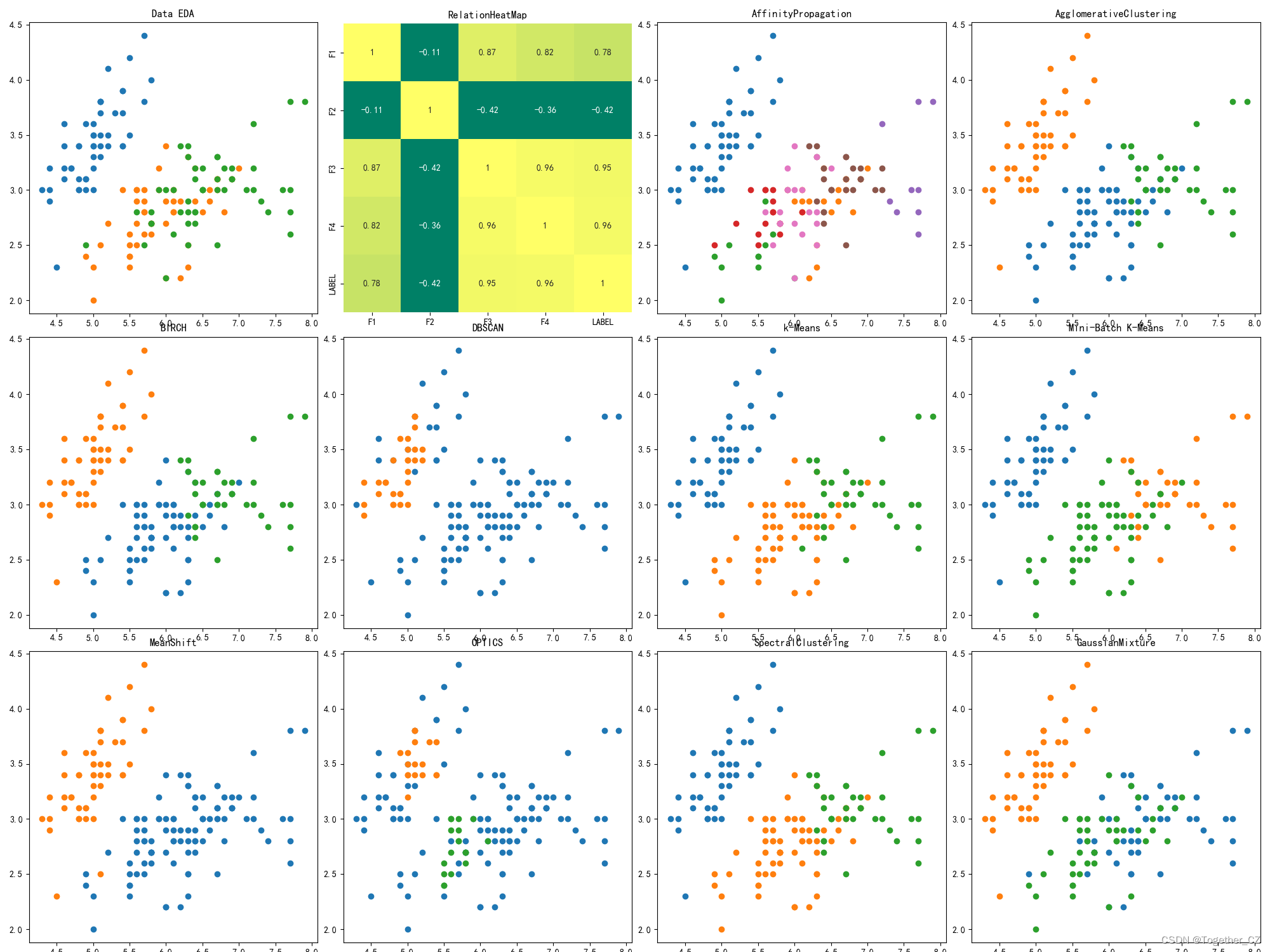
这里汇总了十余种的聚类算法模型,均基于著名的机器学习库slearn完成。
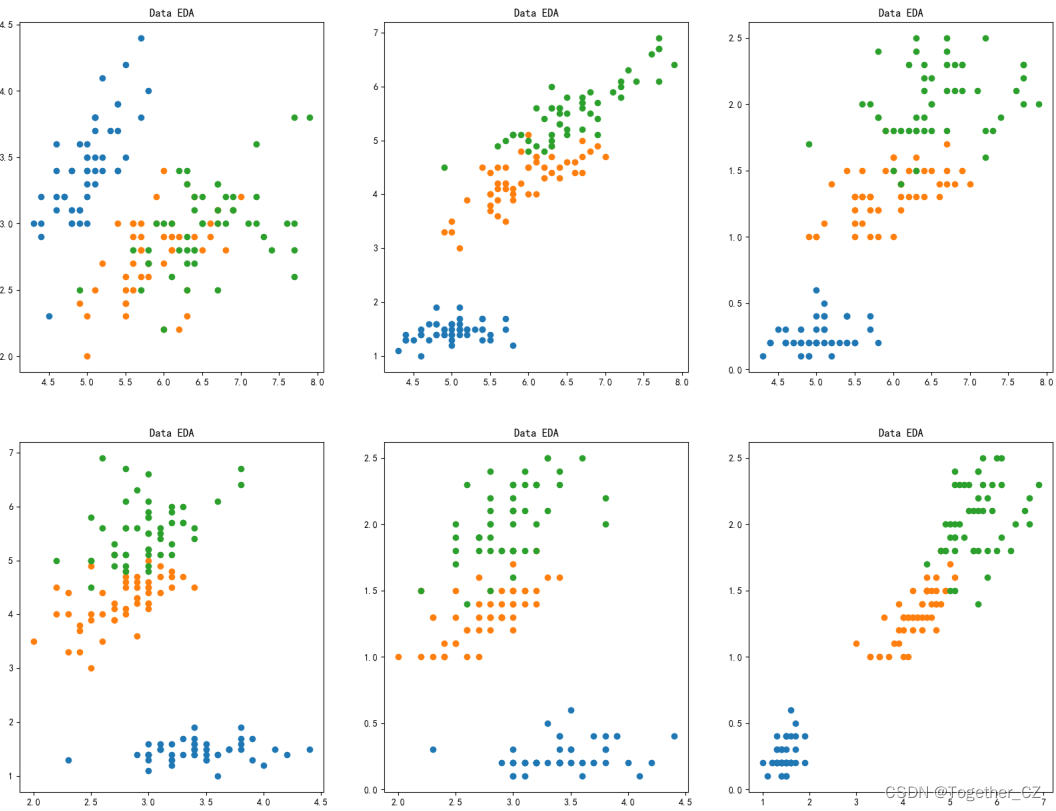
这里首先对数据进行了简单的可视化分析,如下:
【相关性分析热力图】
接下来对数据进行简单的EDA可视化探索如下:
因为鸢尾花数据集太过于知名,所以这里我也就不再赘述了,直接贴出来原始数据内容,有需要的可以直接拿去存储下来做实验用都行,当然了sklearn的dataset模块也内置了iris数据集,我只是习惯了从文件读取数据集而已,可以根据自己需要来就行了。
一共150条数据,每个类别均包含50个样本数据。
接下来进入正文,开始依次构建不同的聚类分析模型。
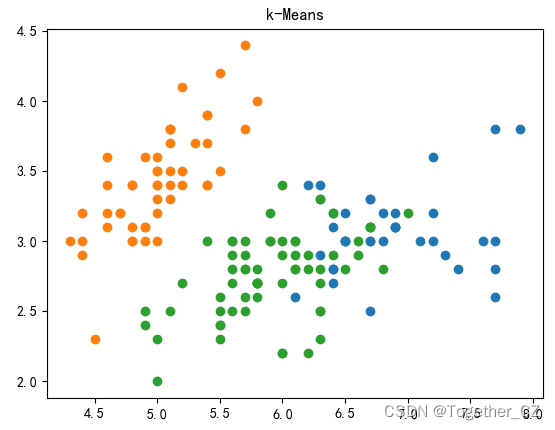
一、KMeans聚类模型
with open("data.json") as f:dataset=json.load(f)
X,y=[],[]
for one_list in dataset:X.append(one_list[:-1])y.append(int(one_list[-1]))
X=np.array(X)
y=np.array(y)
print(y)model = KMeans(n_clusters=3)
model.fit(X)
yhat = model.predict(X)
clusters = unique(yhat)
for cluster in clusters:row_ix = where(yhat == cluster)plt.scatter(X[row_ix, 0], X[row_ix, 1])
plt.title("k-Means")
plt.show()结果如下:
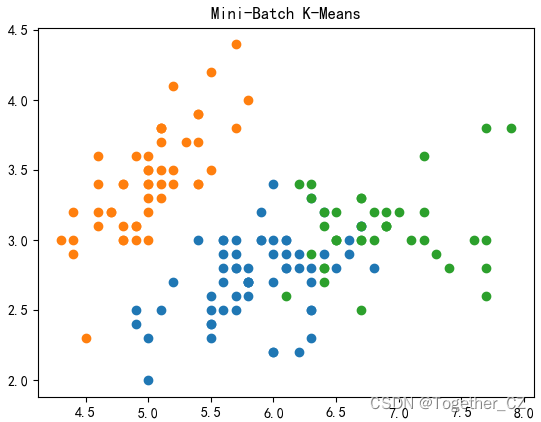
二、Mini-Batch K-Means聚类算法
with open("data.json") as f:dataset=json.load(f)
X,y=[],[]
for one_list in dataset:X.append(one_list[:-1])y.append(int(one_list[-1]))
X=np.array(X)
y=np.array(y)
print(y)model = MiniBatchKMeans(n_clusters=3)
model.fit(X)
yhat = model.predict(X)
clusters = unique(yhat)
for cluster in clusters:row_ix = where(yhat == cluster)plt.scatter(X[row_ix, 0], X[row_ix, 1])
plt.title("Mini-Batch K-Means")
plt.show()结果如下:
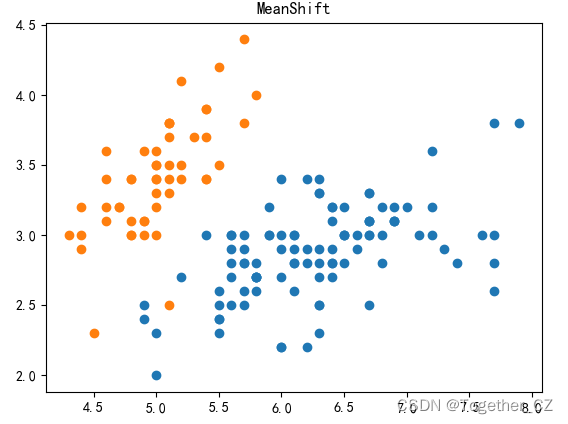
三、MeanShitf均值漂移聚类算法
with open("data.json") as f:dataset=json.load(f)
X,y=[],[]
for one_list in dataset:X.append(one_list[:-1])y.append(int(one_list[-1]))
X=np.array(X)
y=np.array(y)
print(y)model = MeanShift()
yhat = model.fit_predict(X)
clusters = unique(yhat)
for cluster in clusters:row_ix = where(yhat == cluster)plt.scatter(X[row_ix, 0], X[row_ix, 1])
plt.title("MeanShift")
plt.show()结果如下:
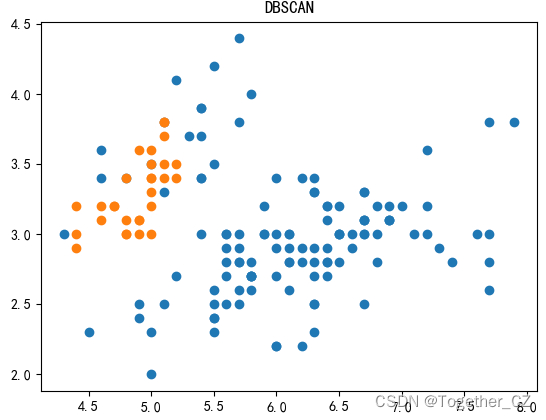
四、DBSCAN 聚类算法
with open("data.json") as f:dataset=json.load(f)
X,y=[],[]
for one_list in dataset:X.append(one_list[:-1])y.append(int(one_list[-1]))
X=np.array(X)
y=np.array(y)
print(y)model = DBSCAN(eps=0.30, min_samples=9)
yhat = model.fit_predict(X)
clusters = unique(yhat)
for cluster in clusters:row_ix = where(yhat == cluster)plt.scatter(X[row_ix, 0], X[row_ix, 1])
plt.title("DBSCAN")
plt.show()结果如下:
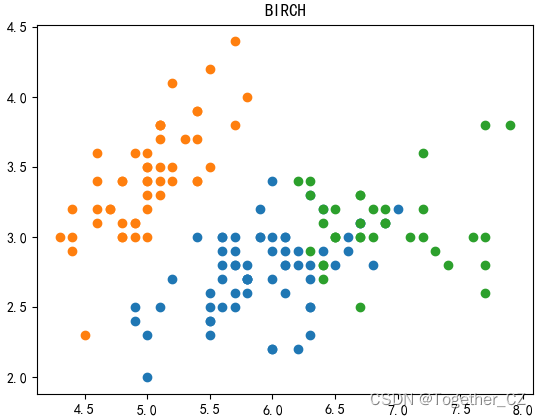
五、BIRCH 聚类算法
with open("data.json") as f:dataset=json.load(f)
X,y=[],[]
for one_list in dataset:X.append(one_list[:-1])y.append(int(one_list[-1]))
X=np.array(X)
y=np.array(y)
print(y)model = Birch(threshold=0.01, n_clusters=3)
model.fit(X)
yhat = model.predict(X)
clusters = unique(yhat)
for cluster in clusters:row_ix = where(yhat == cluster)plt.scatter(X[row_ix, 0], X[row_ix, 1])
plt.title("BIRCH")
plt.show()结果如下:
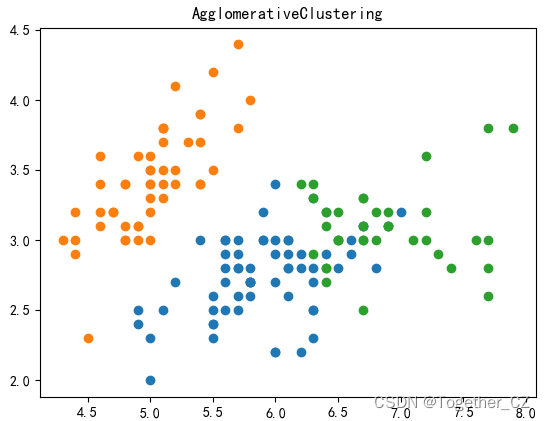
六、聚合聚类算法
with open("data.json") as f:dataset=json.load(f)
X,y=[],[]
for one_list in dataset:X.append(one_list[:-1])y.append(int(one_list[-1]))
X=np.array(X)
y=np.array(y)
print(y)model = AgglomerativeClustering(n_clusters=3)
yhat = model.fit_predict(X)
clusters = unique(yhat)
for cluster in clusters:row_ix = where(yhat == cluster)plt.scatter(X[row_ix, 0], X[row_ix, 1])
plt.title("AgglomerativeClustering")
plt.show()结果如下:
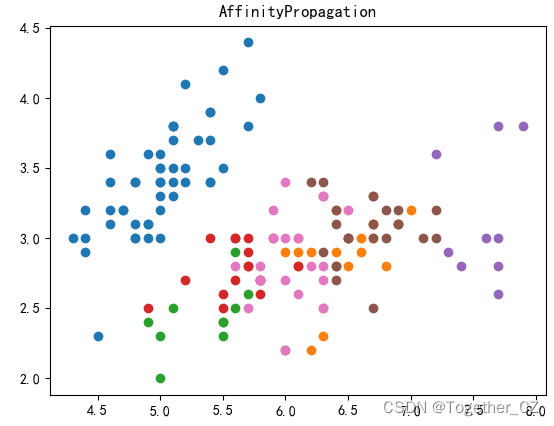
七、亲和力传播聚类算法
with open("data.json") as f:dataset=json.load(f)
X,y=[],[]
for one_list in dataset:X.append(one_list[:-1])y.append(int(one_list[-1]))
X=np.array(X)
y=np.array(y)
print(y)model = AffinityPropagation(damping=0.9)
model.fit(X)
yhat = model.predict(X)
clusters = unique(yhat)
for cluster in clusters:row_ix = where(yhat == cluster)plt.scatter(X[row_ix, 0], X[row_ix, 1])
plt.title("AffinityPropagation")
plt.show()结果如下:
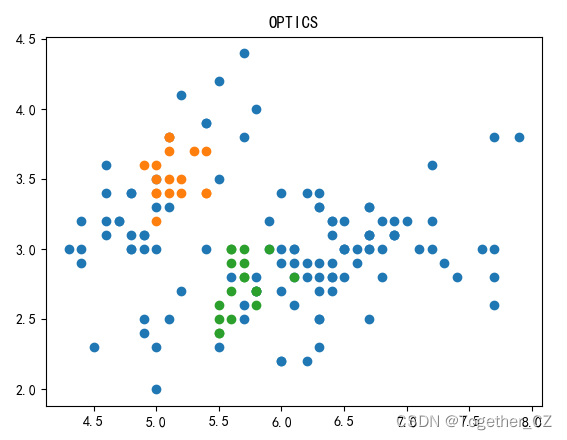
八、OPTICS 聚类算法
with open("data.json") as f:dataset=json.load(f)
X,y=[],[]
for one_list in dataset:X.append(one_list[:-1])y.append(int(one_list[-1]))
X=np.array(X)
y=np.array(y)
print(y)model = OPTICS(eps=0.8, min_samples=10)
yhat = model.fit_predict(X)
clusters = unique(yhat)
for cluster in clusters:row_ix = where(yhat == cluster)plt.scatter(X[row_ix, 0], X[row_ix, 1])
plt.title("OPTICS")
plt.show()结果如下:
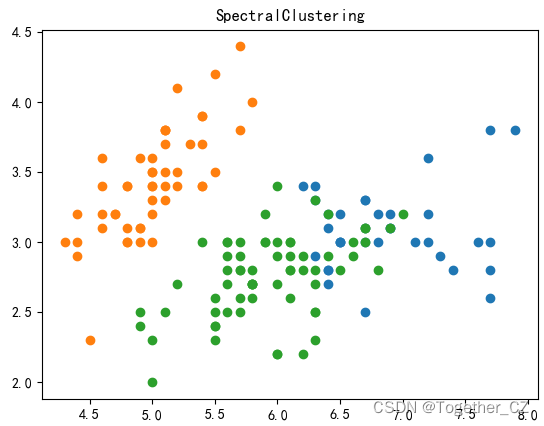
九、光谱聚类算法
with open("data.json") as f:dataset=json.load(f)
X,y=[],[]
for one_list in dataset:X.append(one_list[:-1])y.append(int(one_list[-1]))
X=np.array(X)
y=np.array(y)
print(y)model = SpectralClustering(n_clusters=3)
yhat = model.fit_predict(X)
clusters = unique(yhat)
for cluster in clusters:row_ix = where(yhat == cluster)plt.scatter(X[row_ix, 0], X[row_ix, 1])
plt.title("SpectralClustering")
plt.show()结果如下:
十、高斯混合聚类算法
with open("data.json") as f:dataset=json.load(f)
X,y=[],[]
for one_list in dataset:X.append(one_list[:-1])y.append(int(one_list[-1]))
X=np.array(X)
y=np.array(y)
print(y)model = GaussianMixture(n_components=3)
model.fit(X)
yhat = model.predict(X)
clusters = unique(yhat)
for cluster in clusters:row_ix = where(yhat == cluster)plt.scatter(X[row_ix, 0], X[row_ix, 1])
plt.title("GaussianMixture")
plt.show()结果如下:
感兴趣的话可以很方便地替换成自己的数据集即可构建自己的聚类分析模型了
实际开发实践过程中发现,不同模型的表现差异还是很大,有的需要预设类别数目比如:K-Means算法、光谱聚类、Mini-Batch K-Means算法、BIRCH 聚类算法、聚合聚类算法,其余的则不需要,实际预测出来的效果也是差异挺大的,主要是跟模型的构建原理有关,这里没有过多去涉及原理相关的内容,感兴趣的话可以自行查阅相关的资料即可。