文本压缩有很多种方法,这里我们只考虑最简单的一种:把由相同字符组成的一个连续的片段用这个字符和片段中含有这个字符的个数来表示。例如 ccccc 就用 5c 来表示。如果字符没有重复,就原样输出。例如 aba 压缩后仍然是 aba。
解压方法就是反过来,把形如 5c 这样的表示恢复为 ccccc。
本题需要你根据压缩或解压的要求,对给定字符串进行处理。这里我们简单地假设原始字符串是完全由英文字母和空格组成的非空字符串。
输入格式:
输入第一行给出一个字符,如果是 C 就表示下面的字符串需要被压缩;如果是 D 就表示下面的字符串需要被解压。第二行给出需要被压缩或解压的不超过 1000 个字符的字符串,以回车结尾。题目保证字符重复个数在整型范围内,且输出文件不超过 1MB。
输出格式:
根据要求压缩或解压字符串,并在一行中输出结果。
输入样例 1:
C
TTTTThhiiiis isssss a tesssst CAaaa as
输出样例 1:
5T2h4is i5s a3 te4st CA3a as
输入样例 2:
D
5T2h4is i5s a3 te4st CA3a as10Z
输出样例 2:
TTTTThhiiiis isssss a tesssst CAaaa asZZZZZZZZZZ提交结果:
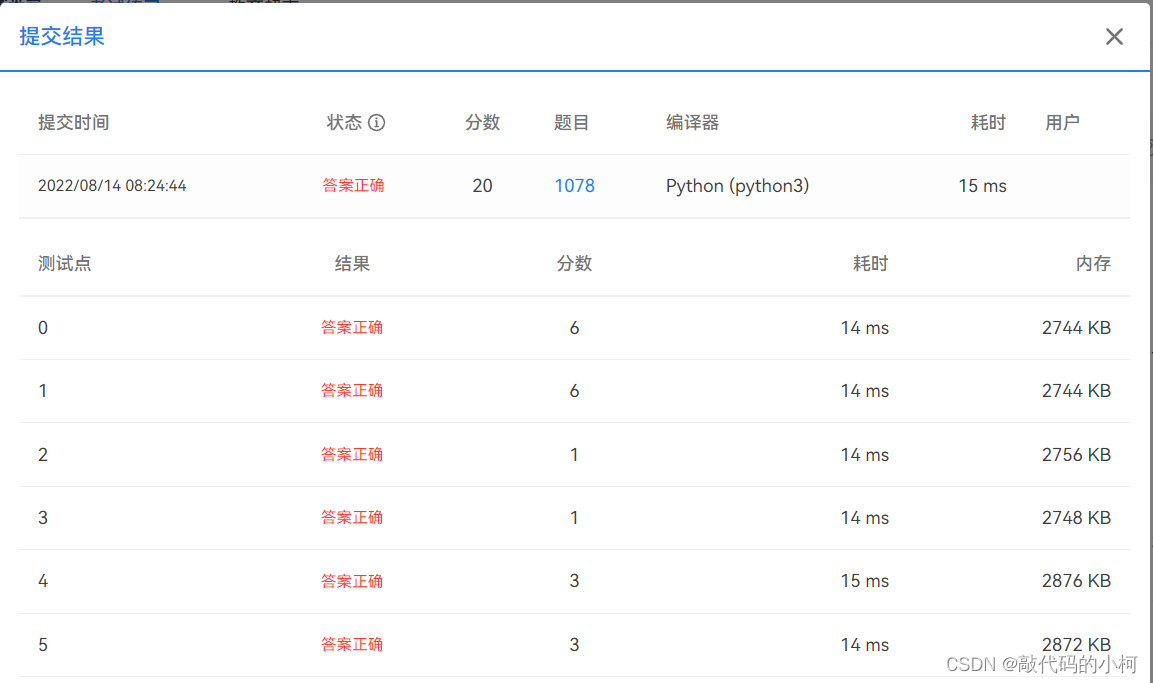
代码:
data1 = input()
data2 = input()
s = ''
if data1 == 'C':i = 0while i < len(data2):j = i + 1count = 1while j < len(data2) and data2[j] == data2[i]:count += 1j += 1if count == 1:s += data2[i]else:s += str(count) + data2[i]i = j
else:i = 0while i < len(data2):j = i + 1if data2[i].isdigit():while data2[j].isdigit():j += 1num = int(data2[i:j])s += data2[j] * numi = j + 1else:s += data2[i]i = j
print(s)