字符串的定义
- 字符串是一个有序的字符集合,用来存储和表现基于文本的信息。
- python 中字符串需要使用成对的单引号或双引号括起来,单引号和双引号的字符串是等效的;python 中还允许使用三引号(“”" 或者 ‘’’ )或双引号创建跨越多行的字符串,这种字符串中可以包含换行符、制表符及其他特殊字符。
# 例如,我们分别创建一个单引号字符串和双引号字符串,内容一样,通过函数 id()返回两个字符串常量的地址,会发现结果是相同的,即:结果会返回yes
a = 'python'
b = "python"
if id(a) == id(b):print("yes")
else:print("no")
>yes# 字符串输出时会去掉最外面一层引号,所以若想在输出的字符串中包含某个引号,则:# 输出语句包含单引号,最外层则使用双引号;其他情况则类似
print("我的名字叫'小明'吗")
> 我的名字叫'小明'吗print('我的名字叫"小明"吗')
> 我的名字叫"小明"吗print('''我的名字叫"""小明"""吗''')
> 我的名字叫"""小明"""吗# 如果一个三引号字符串没有被赋值给变量,则它会被python解释器默认为注释,否则,则会被当做字符串常量
a = '''
大家好:我是\n小明\t的大舅哥的姐姐\n的妹妹!
'''
print(a)
> 大家好:我是
小明 的大舅哥的姐姐
的妹妹!
- 在 python 中,不支持字符类型,单个字符也是字符串。
- 字符串是序列数据类型,可以为每个字符分配一个数字来指代这个元素的位置,即可以使用索引和切片。同样的也支持双向索引。
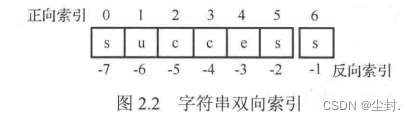
str = 'pyhon is a wonderful language!'# 正向索引(从0开始)、反向索引(从-1开始)
a, b, c = str[0], str[10], str[-1]
print(a, '-', b, '-', c) # 此时意外发现b的位置是一个空格,别以为是bug# 切片[start:end:step]
str_1, str_2, str_3 = str[1:5], str[-5:-1], str[3:-9]
print(str_1, '-', str_2, '-', str_3)# 带有步长的切片(省略start意味着从0开始,省略end则到末尾结束,省略step则步长默认为1)
str_4 = str[1::-1] # 步长为-1则默认倒着往前跳
str_5 = str[::-2] # 步长的大小决定由哪些字符被切片
print(str_4, '-', str_5)-
python 中的字符串支持以下几种类型:
-
Unicode字符串:不以u/U、r/R、b/B 开头的字符串(看这句就行),或以 u 或 U 开头的字符串。
-
非转义的原始字符串:以 r 或 R 开头
-
bytes 字符串:以 b 或 B 开头
可以使用 encode() 和 decode() 函数进行编码和解码,同样也可以使用 str() 和 bytes() 函数进行相同的操作。
-
# 字符串编码和解码print("Are you happy?") # 普通字符串,本质是 Unicode 字符串
print(u"yes,i am") # Unicode 字符串
print(r"d:\friends.txt") # 非转义字符串的原始字符串
print(b"rejoice") # bytes 字节串str = '中国'
print(bytes(str, "GBK")) # 编译成字节串,采用 GBK 编码形式
print(bytes(str, 'utf-8')) # 编译成字节串,采用 utf-8 编码形式# str(以 b 开头的字节流, 该字节流的编码方式) # 还原为 Unicode 编码
字符串的创建
- 使用赋值运算符(=)创建字符串
其一般格式为:变量 = 字符串
language = 'python'
- 使用 str() 或 repr() 函数创建字符串
str() 或 repr() 函数的功能是将一个给定对象转换为字符串,其一般格式为:
'''其一般格式为:str(obj) 或 repr(obj)obj:要转换为字符串的对象,可以是数字,列表等各种对象repr()函数的用途更广泛,可以将任何 Python 对象转换为字符串对象
'''
>>> str(8.42)
'8.42'
>>> str(True)
'True'
>>> str([4,9,1,8])
'[4, 9, 1, 8]'>>> repr((32,5,4000,('Geogle','Runoob')))
"(32, 5, 4000, ('Geogle', 'Runoob'))"
字符串访问
三种方式:
- 字符串名。访问字符串名就是访问整个字符串。
- 字符串名[ index ]。访问字符串索引为 index 的字符。
- 切片访问。访问指定索引范围的字符序列。
str = 'sophiscated'>>> str # 整个字符串
'sophiscated'
>>> str[1] # 字符串索引为 1 的字符
'o'
>>> str[:4] # 索引为 4 之前的所有字符
'soph'
字符串运算
| 操作符 | 描述 |
|---|---|
| + | 字符串连接 |
| * | 重复输出字符串 |
| 关系运算符(<, >, =, <=, >=) | 按两个字符串的索引位置依次比较 |
| in | 如果字符串中包含给定的字符,则返回 True,否则返回 False |
| not in | 如果字符串中不包含给定的字符,则返回 True,否则返回 False |
# 字符串运算
str_1 = "my name is : " + "mark" # + 运算符两边必须都是字符串,否则报错
str_2 = "love " * 3
str_3 = 'c' in 'cat'
str_4 = 'quite' > 'quiet'
print(str_1, str_2, str_3, str_4)- 在 Python 中,除了可以使用关系运算比较两个字符串外,也可以使用标准库模块 Operator 中的函数比较字符串的大小。
| 函数 | 相当于 |
|---|---|
| lt(a, b) | a < b |
| le(a, b) | a <= b |
| eq(a, b) | a == b |
| ne(a, b) | a != b |
| gt(a, b) | a > b |
| ge(a, b) | a >= b |
其中,a、b 为要比较的两个对象,可以是字符串类型,也可以是其他对象类型
import operator
str1 = 'superman'
str2 = 'monster'
print("'superman' < 'monster':", operator.lt(str1, str2))
print("'superman' <= 'monster':", operator.le(str1, str2))
print("'superman' == 'monster':", operator.eq(str1, str2))
print("'superman' != 'monster':", operator.ne(str1, str2))
print("'superman' > 'monster':", operator.ge(str1, str2))
print("'superman' >= 'monster':", operator.gt(str1, str2))'''
如果只是需要比较两个字符串是否相等,则也可以使用字符串的内置函数 __eq__(),注意是上下画线。
其一般形式为: str1.__eq__(str)
如果字符串 str1 和 str2 相等,则返回True, 否则返回 False
'''
print(str1.__eq__(str2))
字符串函数
- 字符串查找函数
| 函数 | 功能说明 |
|---|---|
| str.find(subStr[, beg[, end] ] ) | 查找字符串 str 中是否包含子字符串 subStr,如果包含则返回 subStr 在 str 中第一次出现的位置索引值,否则返回 -1。beg 为查找开始位置, end 为查找结束位置 |
| str.rfind(subStr[,beg[,end ] ]) | 功能同 str.find(),不同的是从右边开始查找 |
| str.index(subStr[,beg[,end ] ]) | 查找字符串 str 中是否包含子字符串 subStr,如果包含则返回 subStr 在 str 中第一次出现的索引值,否则返回 -1。但是如果 subStr 不在 str 中则会报错 |
| str.startwith(subStr) | 检查 str 是否以指定字符串 subStr 开头,如果是则返回 True,否则返回 False |
| str.endwith(subStr) | 检查 str 是否以指定字符串 subStr 结尾,如果是则返回 True,否则返回 False |
str = '时间是一切财富中最宝贵的财富'
print("子字符串的位置: ", str.find("财富")) # 从字符串左边开始查找
print("子字符串的位置: ", str.find("财富", 6)) # 从字符串左边索引为 6 的字符开始查找
print("子字符串的位置: ", str.rfind("财富")) # 从字符串右边开始查找
print("子字符串的位置: ", str.rfind("财富", 4, 10)) # 从右边索引4~10的字符开始查找
print("字符串位置: ", str.rfind("成功")) # 从字符串左边开始查找
print(str.startswith("时间"))
print(str.endswith("财富"))
- 字符串替换函数
| 函数 | 功能 | 参数说明 |
|---|---|---|
| str.replace(oldStr, newStr [, max ] ) | 把字符串中的旧字符串替换成新字符串 | oldStr 为将被替换的子字符串, newStr 为新字符串, max为替换最大次数 |
str = "贝多芬是世界闻名的航海家"
print(str.replace("贝多芬", "哥伦布"))'''
哥伦布是世界闻名的航海家
'''
- 字符串拆分函数
| 函数 | 功能 | 参数说明 |
|---|---|---|
| str.split(sep=" ", num=string.count(str)) | 通过指定分隔符对字符串进行切片,返回一个字符串列表 | sep 为分隔符,默认为空字符,包含空格、换行(\n)、制表符(\t)等。num 为分割次数 |
str = "Every cloud has a silver lining"
print(str.split()) # 使用默认分隔符拆分字符串
print(str.split(" ", 3)) # 使用默认分隔符拆分字符串为 4 个子字符串'''
['Every', 'cloud', 'has', 'a', 'silver', 'lining']
['Every', 'cloud', 'has', 'a silver lining']
'''
- 字符串转换函数
| 函数 | 功能说明 |
|---|---|
| ord ( c) | 与 chr() 函数一对与编码相关而功能相反的函数。返回单个字符的 Unicode 编码 |
| chr(u) | 返回 Unicode 编码对应的字符。如果所给的 Unicode 字符超出了 Python 定义范围,则会引发一个 TypeError 的异常 |
两个字符串之间的比较一般遵循如下规则:
- 如果都是西文字符串,则按照字符串每个字符的 ASCLL 编码逐个进行比较
- 如果都是中文字符串,则按照汉字的 Unicode 编码逐个进行比较
- 如果分别是汉字字符串和英文字符串,则统一按照它们的 Unicode 编码逐个进行比较,汉字字符串大于英文字符串
>>> print(ord('c'))
99
>>> print(ord('金'))
37329
>>> print(ord('输')>ord('赢'))
True
>>> print(chr(2345))
ऩ # 这里显示有问题,应该是一个正方形,即方框
- 字符串格式化函数
| 一般格式 | 说明 |
|---|---|
| 格式化字符串.format(参数列表) | 格式化字符串:包括参数序号和格式控制信息的字符串。 |
格式化控制信息可以是数据类型等,参数序号和格式控制信息包含在 { } 中。

# 字符串format 格式化
print("{:.2f}".format(3.1415926)) # 2 位小数
print("{:+.2f}".format(3.1415926)) # 带符号
print("{:0>2d}".format(6)) # 填充0,右对齐# 字符串format方式的使用,字符串里使用 {} 作为占位符
x = '我的名字是{},我今年{}岁了'.format('小明',29)
print(x)# 使用 {整数} 作为占位符
print('我的名字是{1},我今年{0}岁了'.format(10,'jerry'))# 使用 {变量名} 作为占位符
print('我的名字是{name},我今年{age}岁了'.format(89,'xiaoming',name='jerry',age=45))# 使用 {整数} 和 {变量名}混合使用,在传递参数时,变量名必须要放在最后
print('我的名字是{1},我今年{age}岁了。他是{name},他今年{0}岁了'.format(12,'merry',name='jerry',age=15))# 使用 {} 和 {变量名} 混合使用
print('我的名字是{},我今年{age}岁了。他是{name},他今年{}岁了'.format('chris',18,name='tony',age=20))- 其他常用字符串函数
| 函数 | 描述 | 符号 | 返回结果 |
|---|---|---|---|
| capitalize() | 将字符串的第一个字符转换为大写 | “python”.capitalize() | Python |
| count(str, beg=0,end=len(str)) | 返回子字符串在 str 中出现的次数 | “This is an apple”.count(“is”) | 2 |
| len(string) | 返回字符串长度 | len(“python”) | 6 |
| isdecimal() | 检查字符串是否值包含十进制字符,如果是则返回True,否则返回 False | “128”.isdecimal() “12.8”.isdecimal() | True False |
| isdigit() | 如果字符串只包含数字则返回 True,否则返回 False | “32”.isdigit() “32.3”.isdigit() | True False |
| upper() | 将字符串中的小写字母转换为大写 | “hello”.upper() | HELLO |
| lower() | 将字符串中的大写字母转为小写 | “HELLO”.lower() | hello |
| swapcase() | 将字符串中的大、小写字符互换(大写变小写,小写变大写) | “Hello”.swapcase() | hELLO |
| strip() | 删除字符串两端的空格 | " python ".strip() | python(前后无空格) |
| rstrip() | 删除字符串末尾的空格 | " python ".rstrip() | python(前有空格后无) |
| lstrip() | 删除字符串开头的空格 | " python ".lstrip() | python(后有空格前无) |
| title() | 返回"标题化"字符串,即首字母大写 | “python”.title() | Python |
| Islower() | 如果所有字符都是小写则返回 True,否则返回 False | “Scientist”.islower() “科学家”.islower() | False False |
| isupper() | 如果所有字符都是大写则返回 True,否则返回 False | “Scientist”.islower() “科学家”.islower() | False False |
转义字符
当需要在字符串中使用特殊字符时,Python 使用反斜杠(\)转义字符。
| 转义字符 | 描述 | 转义字符 | 描述 |
|---|---|---|---|
| \ | 续行符(在行尾时) | \n | 换行 |
| | 反斜杠符号 | \v | 纵向制表符 | |
| \’ | 单引号 | \t | 横向制表符 |
| \" | 双引号 | \r | 回车 |
| \a | 响铃 | \f | 换页 |
| \ (空格) | 退格(BackSpace) | \oyy | 八进制数,yy代表的字符 |
| \e | 转义 | \xyy | 十六进制数,yy代表的字符 |
| \000 | 空 | \other | 其他字符以普通格式输出 |
# 转义双引号可以 使:在双引号字符串输出中包含双引号
print("很多观众喜欢\"汉武大帝\"这部电视剧。")print("a = \t108")
print("d:\\b.py")
常量和变量
常量
常量一般指不需要改变也不能改变的常数或常量,如一个数字 3、一个字符串"中国",一个元组(3,4,5)等。
Python 中没有专门定义常量的方式,通常使用大写变量名表示。但是,这仅仅是一种提示和约定,并不是强制语法要求。
PI = 3.14
E = 2.7
变量
1. 变量概述
在 Python 中,变量的是可以变化的。不仅值可以变,其类型也会随着值的不同而变化。(Python 是一种强制型语言,也是一种动态类型语言。Python 解释器会根据赋值或运算来推断变量类型,变量类型是随着其值随时变化的。)
在使用变量时,不需要提前声明,只需要给这个变量赋值即可。当给一个变量赋值时即创建对应类型的变量。当用变量时,必须要给这个变量赋值。如果只声明一个变量而没有赋值,则Python 认为这个变量没有定义。
m = 120
print("m 的数据类型:", type(m))
m = "大数据"
print("m 的数据类型:", type(m))
2、变量命名
可以参考该文章中的 Python 编码规范之标识符规则。
3. 变量赋值
变量只有在赋值之后才能在内存中被创建。Python 使用赋值运算符(=)给变量赋值,一般格式为:
变量1,变量2,变量3,… = 表达式1,表达式2,表达式3,…
表达式可以是常量、已赋值的变量或表达式,也可以是一个序列对象。
如果多个变量的值相同,也可以使用如下格式:
变量1 = 变量2 = 变量3 = … = 变量n = 表达式
counter = 68 # 赋值常量
counter_1 = counter # 赋值变量
counter_2 = lambda x:x[1] # 赋值表达式
x = y = z = 120# 交换两个变量的值
a = 50; b = 60
print("交换前:a = %d, b = %d " % (a, b))
a, b = b, a
print("交换后:a = %d, b = %d " % (a, b))
4. Python 内存和变量管理
在 Python 中,采用的是基于值的内存管理方式,每个值在内存中只有一份存储。如果给多个变量赋相同的值,那么多个变量存储的都是指向这个值的内存地址,即 id,也就说,Python 中的变量并没有存储变量的值,而是存储指向这个值的地址或引用。
a = 16.8
b = 16.8
print("a的id为: ", id(a)) # 输出变量a 的引用
print("b的id为: ", id(b)) # 输出变量b 的引用a的id为: 2698593166416
b的id为: 2698593166416
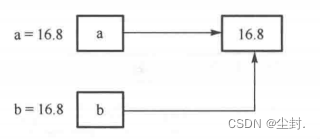
在本例中,a 与 b 均相当于存储 16.8 数值地址的引用,指向同一地址。
但是,对于组合数据(如列表、元组等)而言,每次创建一个组合数据对象,都会重新给其分配内存。因此,给具有相同内容的组合数据类型分配的内存地址不同。
x = [1, 2, 3, 4]
y = [1, 2, 3, 4]
print("id(x) = ", id(x))
print("id(y) = ", id(y))id(x) = 2225831982528
id(y) = 2225831945792
在 Python 中,给变量赋值实际上是对象的引用。当创建一个对象,然后把它赋给另一个变量的时候,Python 并没有复制这个对象,而只是复制了这个对象的引用。这对于所有数据类型(包括组合数据类型)是一样的。
a = 100
b = a # 本质是 a 把指向 100 的地址复制给变量b
print("id(a): ", id(a))
print("id(b): ", id(b))id(a): 2744494329168
id(b): 2744494329168
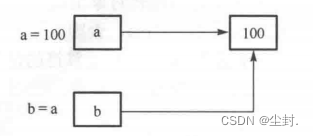
由上图可见,执行 b = a 语句时复制给变量 b 的其实是 a 的地址,而不是 100 这个值。
Python具有自动内存管理功能,会跟踪所有的值,自动删除不再有变量指向的值。因此,Python 程序员一般不考虑内存管理的问题。
写在最后:
首先,如果本篇文章有任何错误,烦请读者告知!不胜感激!
其次,本篇文章仅用于日常学习以及学业复习,如需转载等操作请告知作者(我)一声!
最后,本文会持续修改和更新,如果对本分栏的其他知识也感兴趣,可以移步目录导航专栏,查看本分栏的目录结构,也更方便对于知识的系统总结!
兄弟姐妹们,点个赞呗!
感谢!笔芯!