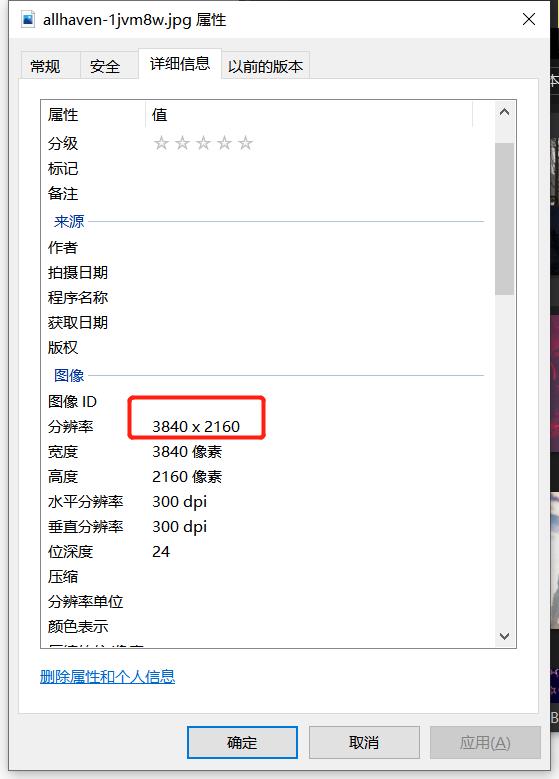
首先上关键功能
1、获取网页源代码
#获取Html
def GetHtmlCode(url,try_num=0):headers = {"user-agent": "Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1"}#"Content-Type": "application/x-www-form-urlencoded"}try:req = requests.get(url, headers=headers)except Exception as e:print("error2: 网络连接超时",e)return Noneif req.status_code != 200:if try_num < 10: #如果网络错误,重试3次time.sleep(2)return GetHtmlCode(url, try_num + 1)print(req.status_code, "error1: 打开网页失败,请检查您的网络!")return Nonecontent_html = req.textreturn content_html#使用示例
content_html = GetHtmlCode(url)2、下载图片到本地
#保存网络图片到本地
def Save_img(img_url,name="test.jpg"):pic = requests.get(img_url, timeout=7)# 将获取的内容保存为后缀为jpg的图片fp = open(name, "wb")fp.write(pic.content)fp.close()#使用示例
Save_img(pic,file_name)3、解析网页获取图片链接等
soup = BeautifulSoup(content_html, "html.parser")pages = soup.find("div",class_="pages") #找单个元素pages = pages.find_all("a") #找全部元素4、全部代码
import requests
from bs4 import BeautifulSoup
import time#获取Html
def GetHtmlCode(url,try_num=0):headers = {"user-agent": "Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1"}#"Content-Type": "application/x-www-form-urlencoded"}try:req = requests.get(url, headers=headers)except Exception as e:print("error2: 网络连接超时",e)return Noneif req.status_code != 200:if try_num < 10: #如果网络错误,重试3次time.sleep(2)return GetHtmlCode(url, try_num + 1)print(req.status_code, "error1: 打开网页失败,请检查您的网络!")return Nonecontent_html = req.textreturn content_html#保存网络图片到本地
def Save_img(img_url,name="test.jpg"):pic = requests.get(img_url, timeout=7)# 将获取的内容保存为后缀为jpg的图片fp = open(name, "wb")fp.write(pic.content)fp.close()if __name__ == '__main__':#为防止代码被滥用,对原网站造成伤害,这里隐去了网址,此代码仅供学习使用url = "https://www.*******.com/donman/index.html" #4K动漫domain = "https://www.*******.com"#获取网页源代码content_html = GetHtmlCode(url)soup = BeautifulSoup(content_html, "html.parser")#查看当前页数pages = soup.find("div",class_="pages")pages = pages.find_all("a")[10].textpages = int(pages)print(pages)start_num = 1 #开始num#循环每一页for page in range(1,pages+1):print("当前页数:",page)if page == 1:cur_html = content_htmlsoup = soupelse:cur_url = url.replace(".html","")cur_url = cur_url+"_"+str(page)+".html"print("当前页面:",cur_url)cur_html = GetHtmlCode(cur_url)soup = BeautifulSoup(cur_html, "html.parser")#获取当前页的图片地址pics = soup.find("ul",class_="item")pics = pics.find_all("li")for pic in pics:pic = pic.find("img")["src"]pic = domain + pic#获取 1920*1080 图片pic = pic.replace("small","")pic = pic[:-14] + ".jpg"print(pic)# 下载图片链接到本地file_name = "./动漫/"+str(start_num)+".jpg"start_num += 1Save_img(pic,file_name)time.sleep(2)time.sleep(5)