相关文章

【计算机网络】网络层
文章目录网络层概述网络层提供的两种服务IPv4地址IPv4地址概述分类编址的IPv4地址划分子网的IPv4地址无分类编址的IPv4地址IPv4地址的应用规划IP数据报的发送和转发过程静态路由配置及其可能产生的路由环路问题路由选择路由选择协议概述路由信息协议RIP的基本工作原理开放最短路…

Qt COM组件导出源文件
文章目录摘要dumpcpp.exe注册COM组件COM 组件转CPP参考关键字:
Qt、
COM、
组件、
源文件、
dumpcpp摘要
由于厂家提供的库不是纯净C库,是基于COM组件开的库,在和厂家友好交流无果下,只能研究下Qt 如何调用,好在Qt 的…
【数据结构与算法】时间复杂度与空间复杂度
目录
一.前言
二.时间复杂度
1.概念
二.大O的渐进表示法
概念:
总结:
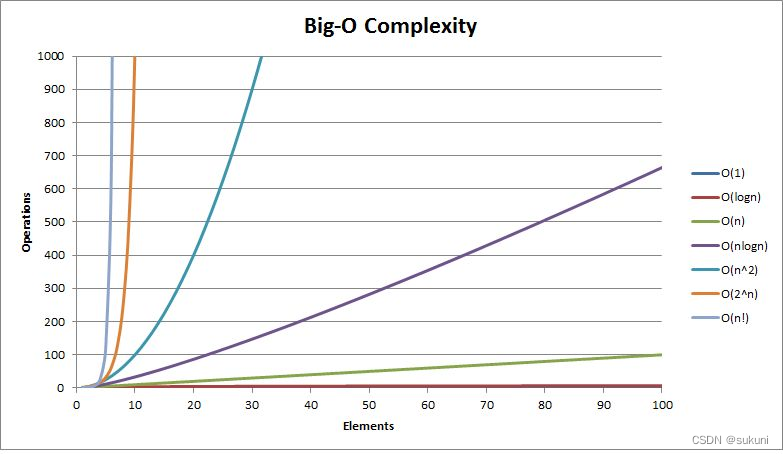
三.常见时间复杂度计算举例
例1
例2
例3
例4
例5.计算冒泡排序的时间复杂度
例6.二分算法的时间复杂度
例7.阶乘递归Fac的时间复杂度
例8.斐波那契递归的时间复杂度
…

第63章 SQL 快速参考教程
第63章 SQL 快速参考教程 SQL 语句语法AND / ORSELECT column_name(s) FROM table_name WHERE condition AND|OR conditionALTER TABLEALTER TABLE table_name ADD column_name datatypeor ALTER TABLE table_name DROP COLUMN column_name AS (alias)SELECT column_name AS …

C++ STL 学习之【string】
✨个人主页: Yohifo 🎉所属专栏: C修行之路 🎊每篇一句: 图片来源 The key is to keep company only with people who uplift you, whose presence calls forth your best. 关键是只与那些提升你的人在一起,…
yum/vim工具的使用
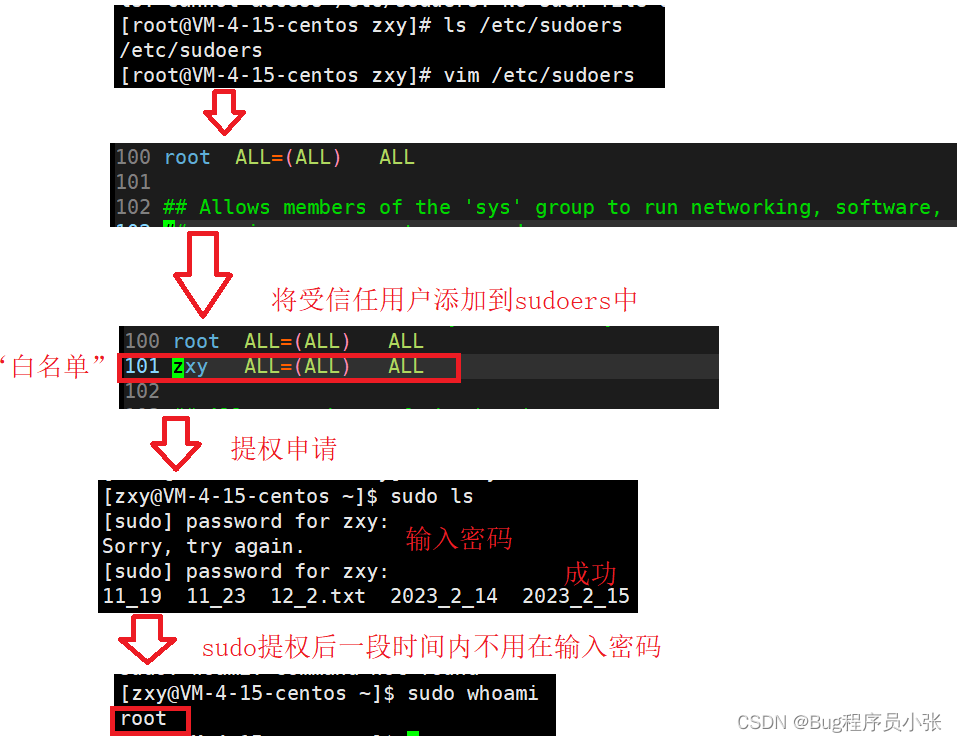
yum
我们生活在互联网发达的时代,手机电脑也成为了我们生活的必须品,在你的脑海中是否有着这样的记忆碎片,在一个明媚的早上你下定决心准备发奋学习,“卸载”了你手机上的所有娱乐软件,一心向学!可是到了下…
一问学习StreamAPI终端操作
Java Stream管道流是用于简化集合类元素处理的java API。 在使用的过程中分为三个阶段:
将集合、数组、或行文本文件转换为java Stream管道流管道流式数据处理操作,处理管道中的每一个元素。上一个管道中的输出元素作为下一个管道的输入元素。管道流结果…
自抗扰控制ADRC之微分器TD
目录 前言
1 全程快速微分器
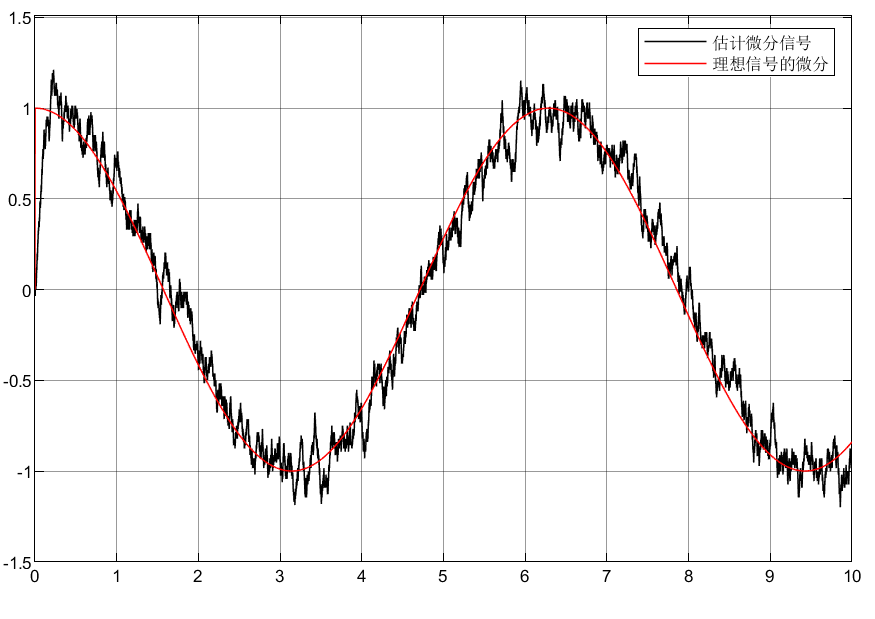
1.1仿真分析
1.2仿真模型
1.3仿真结果
1.4结论
2 Levant微分器
2.1仿真分析
2.2仿真模型
2.3仿真结果
3.总结 前言
工程上信号的微分是难以得到的,所以本文采用微分器实现带有噪声的信号及其微分信号提取,从而实现…