文章目录
- 01:其他维度:组织机构
- 02:其他维度:仓库、物流
- 附录一:常见问题
- 1.错误:没有开启Cross Join
- 2.错误:Unable to move source
01:其他维度:组织机构
-
目标:实现组织机构维度的设计及构建
-
路径
- step1:需求
- step2:设计
- step3:实现
-
实施
-
需求:实现组织机构维度表的构建,得到每个工程师对应的组织机构信息
- 统计不同服务人员的工单数、核销数等
-
设计
-
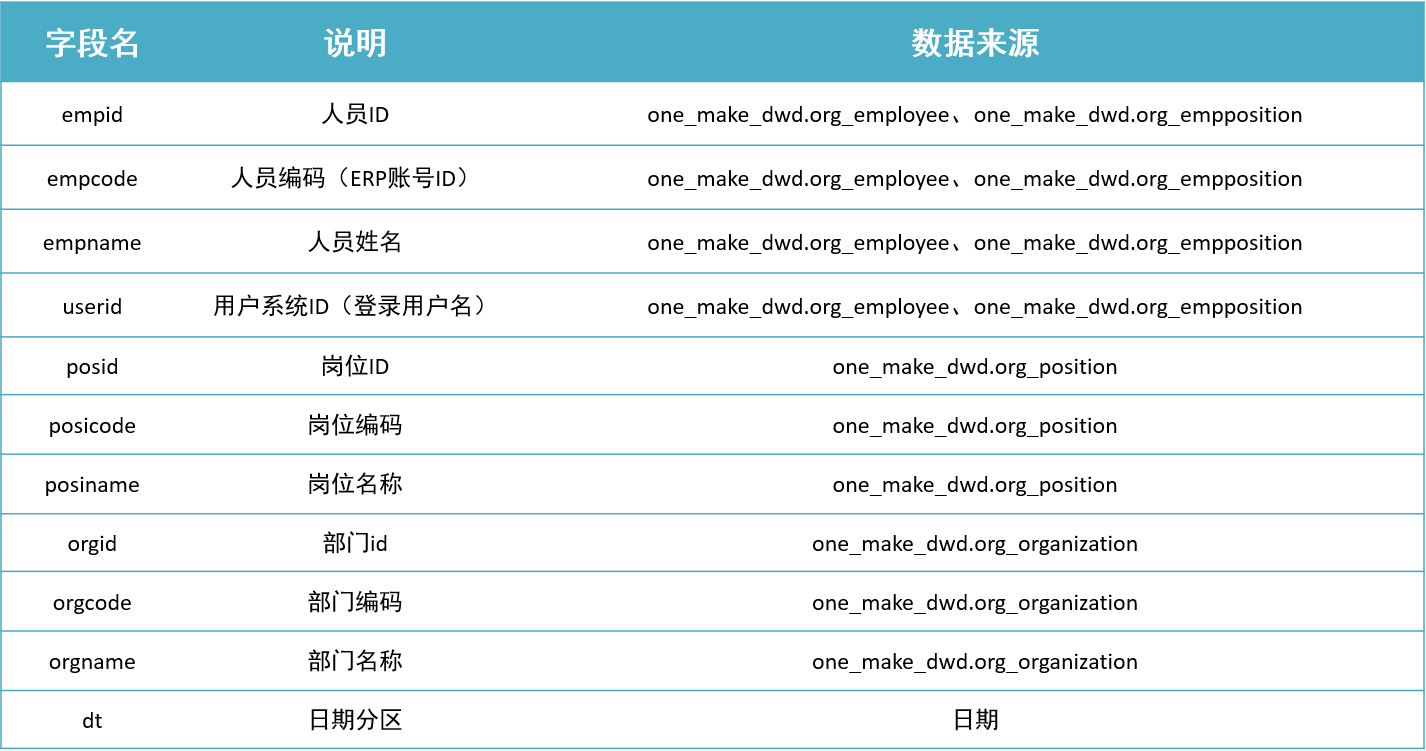
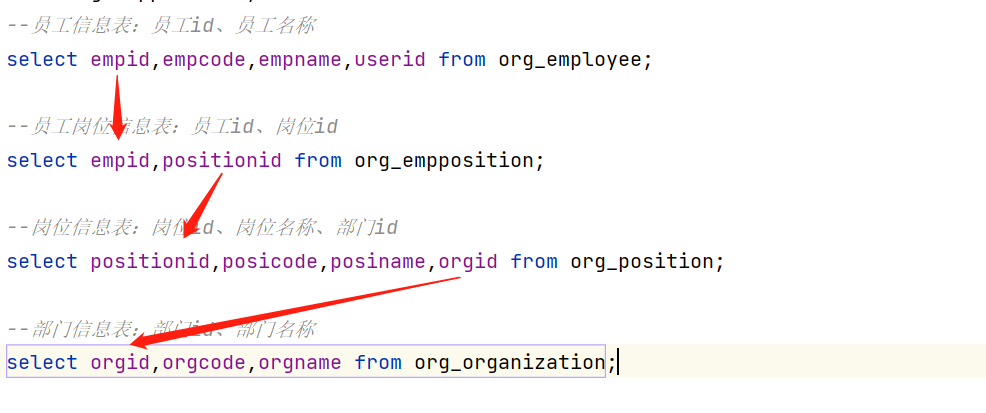
org_employee:员工信息表【员工id、员工编码、员工名称、用户系统id】
select empid,empcode,empname,userid from org_employee; -
org_empposition:员工岗位信息表【员工id、岗位id】
select empid,positionid from org_empposition; -
org_position:岗位信息表【岗位id、岗位编码、岗位名称、部门id】
select positionid,posicode,posiname,orgid from org_position; -
org_organization:部门信息表【部门id、部门编码、部门名称】
select orgid,orgcode,orgname from org_organization;
-
-
实现
-
建维度表
-- 创建组织机构维度表,组织机构人员是经常变动的,所以按照日期分区 create external table if not exists one_make_dws.dim_emporg(empid string comment '人员id' , empcode string comment '人员编码(erp对应的账号id)', empname string comment '人员姓名', userid string comment '用户系统id(登录用户名)', posid string comment '岗位id', posicode string comment '岗位编码', posiname string comment '岗位名称', orgid string comment '部门id', orgcode string comment '部门编码', orgname string comment '部门名称' ) comment '组织机构维度表' partitioned by (dt string) stored as orc location '/data/dw/dws/one_make/dim_emporg'; -
抽取数据
-- 先根据dwd层的表进行关联,然后分别把数据取出来 insert overwrite table one_make_dws.dim_emporg partition(dt='20210101') selectemp.empid as empid, emp.empcode as empcode, emp.empname as empname, emp.userid as userid, pos.positionid as posid, pos.posicode as posicode, pos.posiname as posiname, org.orgid as orgid, org.orgcode as orgcode, org.orgname as orgname from one_make_dwd.org_employee emp left join one_make_dwd.org_empposition empposon emp.empid = emppos.empid and emp.dt = '20210101' and emppos.dt = '20210101' left join one_make_dwd.org_position poson emppos.positionid = pos.positionid and pos.dt = '20210101' left join one_make_dwd.org_organization orgon pos.orgid = org.orgid and org.dt = '20210101';
-
-
-
小结**
- 实现组织机构维度的设计及构建
02:其他维度:仓库、物流
-
目标:实现仓库维度、物流维度的构建
-
路径
- step1:仓库维度
- step2:物流维度
-
实施
-
仓库维度
-
建表
-- 仓库维度表 create external table if not exists one_make_dws.dim_warehouse(code string comment '仓库编码', name string comment '仓库名称', company_id string comment '所属公司', company string comment '公司名称', srv_station_id string comment '所属服务网点ID', srv_station_name string comment '所属服务网点名称' )comment '仓库维度表' partitioned by (dt string) stored as orc location '/data/dw/dws/one_make/dim_warehouse'; -
加载
insert overwrite table one_make_dws.dim_warehouse partition(dt='20210101') selectwarehouse.code as code, warehouse.name as name, warehouse.company as company_id, cmp.compmay as compmay, station.id as srv_station_id, station.name as srv_station_name fromone_make_dwd.ciss_base_warehouse warehouse -- 关联公司信息表 left join (selectygcode as company_id, max(companyname) as compmayfrom one_make_dwd.ciss_base_baseinfo where dt='20210101'-- 需要对company信息进行分组去重,里面有一些重复数据 group by ygcode) cmpon warehouse.dt = '20210101' and cmp.company_id = warehouse.company -- 关联服务网点和仓库关系表 left join one_make_dwd.ciss_r_serstation_warehouse station_r_warehouseon station_r_warehouse.dt = '20210101' and station_r_warehouse.warehouse_code = warehouse.code -- 关联服务网点表 left join one_make_dwd.ciss_base_servicestation stationon station.dt = '20210101' and station.id = station_r_warehouse.service_station_id;
-
-
物流维度
-
建表
-- 物流维度表(和服务属性表类似) create external table if not exists one_make_dws.dim_logistics(prop_name string comment '字典名称', type_id string comment '属性id', type_name string comment '属性名称' )comment '物流维度表' partitioned by (dt string) stored as orc location '/data/dw/dws/one_make/dim_logistics'; -
加载
insert overwrite table one_make_dws.dim_logistics partition(dt = '20210101') selectdict_t.dicttypename as prop_name, dict_e.dictid as type_id, dict_e.dictname as type_name from one_make_dwd.eos_dict_type dict_t inner join one_make_dwd.eos_dict_entry dict_eon dict_t.dt = '20210101'and dict_e.dt = '20210101'and dict_t.dicttypeid = dict_e.dicttypeidand dict_t.dicttypename in ('物流公司', '物流类型') order by dict_t.dicttypename, dict_e.dictid; -
使用如下写法会好一些
insert overwrite table one_make_dws.dim_logistics partition (dt = '20210101') select dict_t.dicttypename as prop_name, dict_e.dictid as type_id, dict_e.dictname as type_name from one_make_dwd.eos_dict_type dict_tinner join one_make_dwd.eos_dict_entry dict_e on dict_t.dt = '20210101'and dict_e.dt = '20210101'and dict_t.dicttypeid = dict_e.dicttypeid -- 通过状态字符串进行关联and dict_t.dicttypename in ('物流公司', '物流类型') -- 通过和物流相关的字样进行过滤 order by prop_name, type_id;
-
-
-
小结**
- 实现仓库维度、物流维度的构建
附录一:常见问题
1.错误:没有开启Cross Join
Exception in thread "main" org.apache.spark.sql.AnalysisException: Detected implicit cartesian product for INNER join between logical plans.Use the CROSS JOIN syntax to allow cartesian products between these relations
- Spark2.x默认不允许执行笛卡尔积,除非显示申明cross join或者开启属性:
spark.sql.crossJoin.enabled true
2.错误:Unable to move source
Error: org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to move source hdfs://hadoop.bigdata.cn:9000/data/dw/dws/one_make/dim_warehouse/.hive-staging_hive_2020-12-23_04-26-01_363_5663538019799519260-16/-ext-10000/part-00000-63069107-6405-4e31-a55a-6bdeefcd7d9b-c000 to destination hdfs://hadoop.bigdata.cn:9000/data/dw/dws/one_make/dim_warehouse/dt=20210101/part-00000-63069107-6405-4e31-a55a-6bdeefcd7d9b-c000; (state=,code=0)
- 重启SparkSQL的ThriftServer,与MetaStore构建新的会话连接



![2021年中国餐厨垃圾产量、厨余垃圾处理器及发展趋势分析[图]](https://img-blog.csdnimg.cn/img_convert/6a4783db171e79115443f8aba7509375.png)
